方言距离数据.岭南学院产业与区域经济研究中心
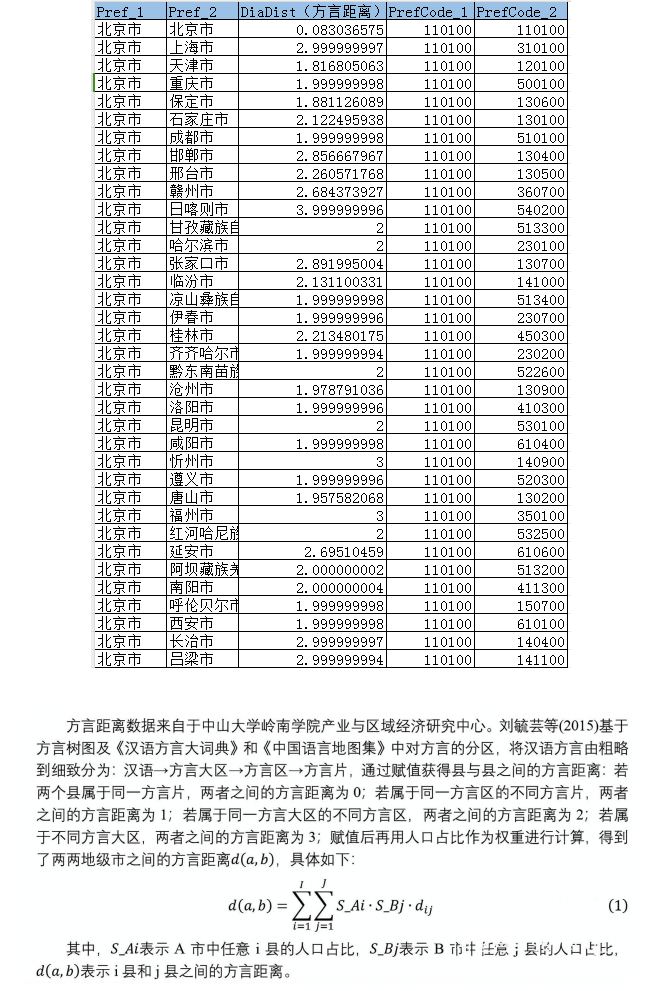
中山大学岭南学院构建的337个地级市方言距离数据集,基于《汉语方言大词典》等权威资料,采用0-3分级量化方言差异,涵盖11.35万组样本。该数据通过方言树状分类(大区/区/片)和人口加权计算,如京沪方言距离2.99(不同大区)、京津1.82(同大区不同区)。包含行政区划代码、方言层级等字段,延伸出分化指数等分析维度。该数据集为经济学(劳动力流动)、语言学(文化保护)及AI语音识别(方言ASR优化)
方言距离数据.岭南学院产业与区域经济研究中心![]() https://download.csdn.net/download/2401_84585615/90469559https://download.csdn.net/download/2401_84585615/90469559
https://download.csdn.net/download/2401_84585615/90469559https://download.csdn.net/download/2401_84585615/90469559
该数据由中山大学岭南学院产业与区域经济研究中心刘毓芸等学者基于《汉语方言大词典》和《中国语言地图集》构建,量化了全国337个地级市之间的方言差异,覆盖11.35万组样本。通过方言树图层级划分(汉语→方言大区→方言区→方言片),采用0-3的赋值规则:同方言片距离为0,同方言区不同片为1,同大区不同区为2,不同大区为3,并结合县级人口权重加权计算地级市间的方言距离。例如,北京与上海方言距离为2.99(分属不同大区),而与天津为1.82(同属北方官话大区但不同方言区)。
数据包含Pref_1(城市1)、Pref_2(城市2)、DiaDist(方言距离值)、PrefCode(行政区划代码)等字段,并细分至语系、方言大区、方言片等语言学分类指标。原始数据源自权威的《中国语言地图集》和《汉语方言大词典》,经研究团队匹配1986年行政区划后,通过人口加权整合为地级市层面数据。部分字段如方言分化指数和方言片个数进一步扩展了区域语言多样性分析维度。
该数据为语言学、经济学及人工智能领域提供重要支撑。在学术研究中,可用于分析方言差异对劳动力流动、区域经济联系的影响;在技术层面,为语音识别模型优化提供依据,例如通过核心方言距离度量提升方言ASR(自动语音识别)的跨区域适用性。此外,数据中的层级划分和量化方法为文化保护、方言演化研究提供了标准化工具。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 10
10 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)