Megatron-LM学习笔记(2)检查点checkpoint
Megatron中检查点会有普通的检查点和release检查点的区别。里面首先保存全部的args,然后是iteration,模型的state dict,optimizer里的state dict,scheduler的state dict等等。Megatron中,检查点的保存发生在train的主循环中每一个train step之后,根据args.save保存的路径以及args.save_interv
保存和加载检查点非常重要。但凡是个正经框架,都需要定期保存检查点增强容错,随时中断任务而不丢失进度,等等。如果你有一个很好的模型,也可以放出中间的检查点来刷跑分。
Megatron中检查点会有普通的检查点和release检查点的区别。后者会在保存的时候通过在检查点元数据文件中写入"release"字符串来标识,而不是迭代次数。在功能测试中,release检查点有专门的测试类型 run_ci_test.sh:58,测试系统会根据TEST_TYPE为"release"来执行特殊的测试流程 run_ci_test.sh:140-143。检测到检查点时,系统也会进入微调模型,不加载优化器、RNG,迭代次数为0.
1、检查点的读取
Megatron中检查点的读取在pretrain函数的setup_model_and_optimizer中,先初始化模型和优化器,然后使用training/checkpointing中的load_checkpoint函数进行加载。
load_checkpoint会读取传入的参数,然后进入load base checkpoint,通常只加载rank 0上的检查点。这个函数挺长的,有200+行。包含了所有可能的分支
- Base主要加载torch.load能加载的内容,以及根据是否是远程检查点加载对应的逻辑。这个函数返回加载的一部分state dict,检查点名字以及是否是release
继续加载checkpoint。如果是分布式检查点,需要判断TP和PP,加载随机数,加载分布式优化器相关的参数。然后对于非rank 0的部分开始再一次load base checkpoint。所有读入的内容都会保存在state dict变量中,接下来才会正式进行设置。
先设置好iteration和版本等。如果使用了英伟达的modelOpt则加载,之后是把state dict中的东西真正赋给各个组分。例如model load state dict,optimizer load state dict,scheduler load state dict,加载随机数,完成
iterations会保存在args.iteration中,然后用在build train valid test data loaders中重建训练数据的开始索引

2、检查点的保存
Megatron中,检查点的保存发生在train的主循环中每一个train step之后,根据args.save保存的路径以及args.save_interval保存的检查点间隔,调用save_checkpoint_and_time函数保存检查点。如果退出前一次都没有保存过检查点,则保存检查点;在pretrain函数中完成train之后,也会保存一次检查点
- save checkpoint and time函数会保存时间,并且会从interval time中剔除掉保存检查点花费的时间;真正的检查点保存发生在save_checkpoint之中
- save checkpoint也包含在checkpointing.py之中。先确定保存的格式(torch_dist和torch两种),然后确定检查点文件的名字,如果是分布式优化器则save_parameter_state来保存其特有状态。
-
DistributedOptimizer 的save_parameter_state只是用来保存分布式检查点的特有状态的,收集各个GPU上的状态到DP0上保存;
-
之后开始收集各种参数、模型、随机数。三个条件任意满足就会进入下面的保存状态。注意第二个条件就是保证DP或者CP rank=0的时候才保存,最后一个条件就是使用torch_dist格式的时候才保存

-
这段保存里会调用generate_state_dict来把内容保存到state_dict中,以及当前经过了多少浮点计算等等。里面首先保存全部的args,然后是iteration,模型的state dict,optimizer里的state dict,scheduler的state dict等等。注意grad scaler的state dict保存在optimizer里毕竟是一个Megatron Optimizer
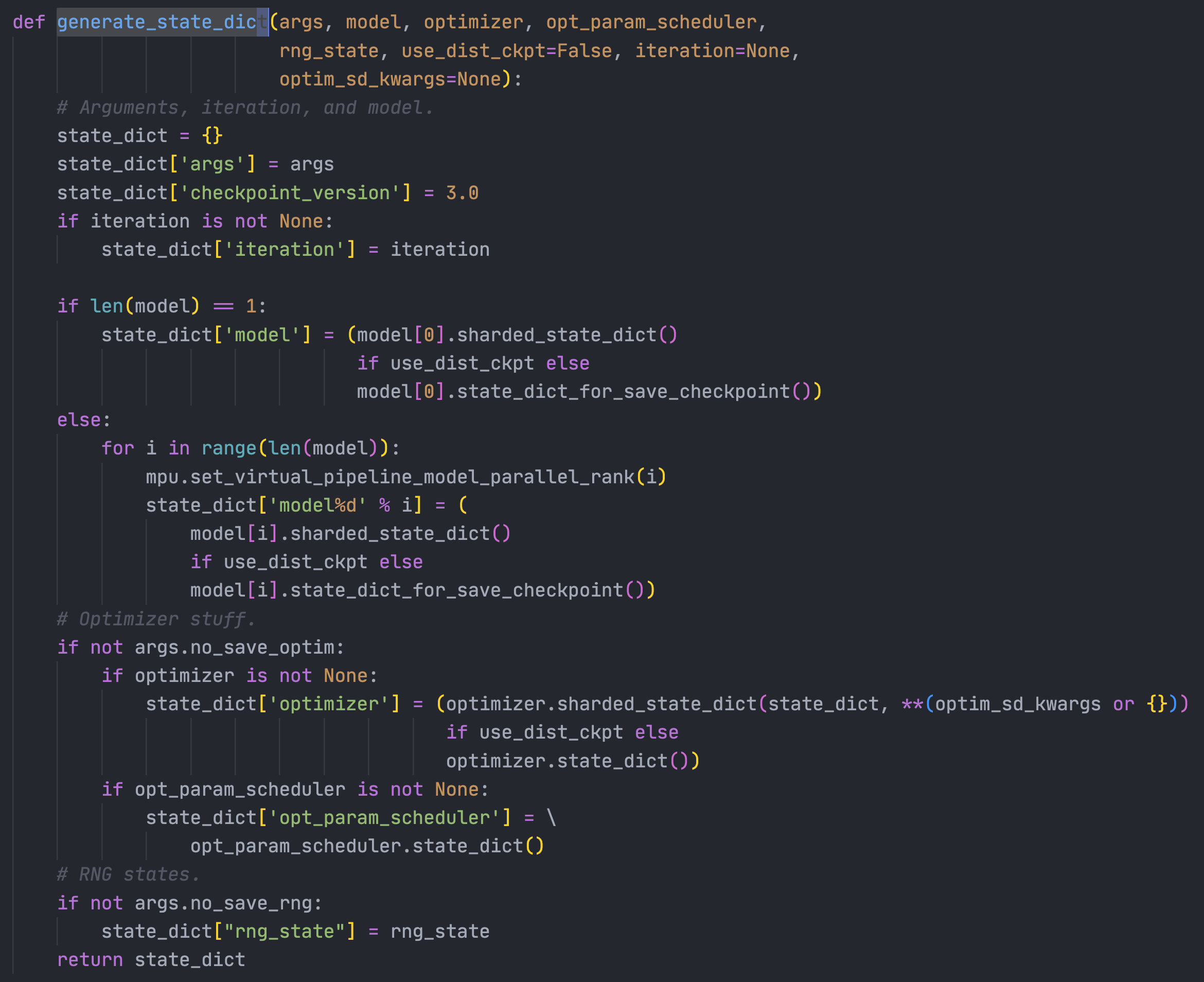

-
针对dist格式的检查点,有更复杂的保存值等等。如果不是,则使用传统的torch.save。
-
支持异步保存,防止保存检查点时间过长
-
3、检查点目录长什么样:
通常只有DP rank 0的会保存,因此最上层是 iter_{iteration}/ dist_optim 和 model_optim_rng两个文件。如果不使用distributed optimizer,则只有后面这个文件。还会有一个txt文件告诉你最新的检查点是哪个 latest checkpoint

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 23
23 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)