AI-03a2.Python深度学习-神经网络入门-二分类问题示例
·
分类和回归术语表
- 样本(sample)或输入(input):进入模型的数据点。
- 预测(prediction)或输出(output):模型的输出结果。
- 目标(target):真实值。对于外部数据源,理想情况下模型应该能够预测出目标。
- 预测误差(prediction error)或损失值(loss value):模型预测与目标之间的差距。
- 类别(class):分类问题中可供选择的一组标签。举例来说,对猫狗图片进行分类时,“猫”和“狗”就是两个类别。
- 标签(label):分类问题中类别标注的具体实例。如果 1234 号图片被标注为包含类别“狗”,那么“狗”就是 1234 号图片的标签。
- 真实值(ground-truth)或标注(annotation):数据集的所有目标,通常由人工收集。
- 二分类(binary classification):一项分类任务,每个输入样本都应被划分到两个互斥的类别中。
- 多分类(multiclass classification):一项分类任务,每个输入样本都应被划分到两个以上的类别中,比如手写数字分类。
- 多标签分类(multilabel classification):一项分类任务,每个输入样本都可以被分配多个标签。举个例子,一张图片中可能既有猫又有狗,那么应该同时被标注“猫”标签和“狗”标签。每张图片的标签个数通常是可变的。
- 标量回归(scalar regression):目标是一个连续标量值的任务。预测房价就是一个很好的例子,不同的目标价格形成一个连续空间。
- 向量回归(vector regression):目标是一组连续值(比如一个连续向量)的任务。如果对多个值(比如图像边界框的坐标)进行回归,那就是向量回归。
- 小批量(mini-batch)或批量(batch):模型同时处理的一小部分样本(样本数通常在 8 和 128 之间)。样本数通常取 2 的幂,这样便于在 GPU 上分配内存。训练时,小批量用于计算一次梯度下降,以更新模型权重。
影评分类:二分类问题示例
我们将使用 IMDB 数据集,它包含来自互联网电影数据库(IMDB)的 50 000 条严重两极化的评论。数据集被分为 25 000 条用于训练的评论与 25 000 条用于测试的评论,训练集和测试集都包含 50% 的正面评论与 50% 的负面评论。
与 MNIST 数据集一样,IMDB 数据集也内置于 Keras 库中。它已经过预处理:评论(单词序列)已被转换为整数序列,其中每个整数对应字典中的某个单词。这样一来,我们就可以专注于模型的构建、训练与评估。
加载 IMDB 数据集
from tensorflow import keras
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from keras.datasets import imdb
print("\ntensorflow version:", tf.__version__)
# 运行: python 影评分类_二分类问题示例.py
#
# 加载 IMDB 数据集,约 80 MB 的数据,
## num_words=10000 的意思是仅保留训练数据中前 10 000 个最常出现的单词。低频词将被舍弃。
## 这样一来,我们得到的向量数据不会太大,便于处理。如果没有这个限制,那么我们需要处理训练数据中的 88 585 个单词。
## 这个数字太大,且没有必要。许多单词只出现在一个样本中,它们对于分类是没有意义的。
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
## train_data 和 test_data 这两个变量都是由评论组成的列表,每条评论又是由单词索引组成的列表(表示单词序列)。
## train_labels 和 test_labels 都是由 0 和 1 组成的列表,其中 0 代表负面(negative),1 代表正面(positive)。
print("\ntrain_data[0] = ", train_data[0])
print("\ntrain_labels[0] = ", train_labels[0])
## 由于限定为前 10 000 个最常出现的单词,因此单词索引都不会超过 10 000。
print(max([max(sequence) for sequence in train_data]))
## word_index 是一个将单词映射为整数索引的字典,格式:{"fawn": 34701, "tsukino": 52006, "nunnery": 52007, ...}
word_index = imdb.get_word_index()
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
## 将评论解码为文本
## 为什么要 i-3 ?因为 0、1、2 分别是为“padding”(填充)、“start of sequence”(序列开始)、“unknown”(未知词)保留的索引
decoded_review = ' '.join([reverse_word_index.get(i-3, "?") for i in train_data[0]])
print("\ndecoded_review = ", decoded_review)
## 验证 i-3
print("\ntrain_data.shape = ", train_data.shape)
print(f"train_data[0][0] = {train_data[0][0]}, word = {reverse_word_index.get(train_data[0][0] - 3, "?")}")
print(f"train_data[0][1] = {train_data[0][1]}, word = {reverse_word_index.get(train_data[0][1] - 3, "?")}")
print(f"train_data[0][2] = {train_data[0][2]}, word = {reverse_word_index.get(train_data[0][2] - 3, "?")}")
print(f"train_data[0][3] = {train_data[0][3]}, word = {reverse_word_index.get(train_data[0][3] - 3, "?")}")
准备数据
你不能将整数列表直接传入神经网络。整数列表的长度各不相同,但神经网络处理的是大小相同的数据批量。你需要将列表转换为张量,转换方法有以下两种。
- 填充列表,使其长度相等,再将列表转换成形状为 (samples, max_length) 的整数张量,然后在模型第一层使用能处理这种整数张量的层(也就是 Embedding 层)。
- 对列表进行 multi-hot 编码,将其转换为由 0 和 1 组成的向量。举个例子,将序列 [8, 5] 转换成一个 10 000 维向量,只有索引 8 和 5 对应的元素是 1,其余元素都是 0。然后,模型第一层可以用 Dense 层,它能够处理浮点数向量数据。
我们将使用第二种方法,将列表进行 multi-hot 编码。
import numpy as np
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension), dtype=np.int32)
for i, sequence in enumerate(sequences):
for j in sequence:
results[i, j] = 1
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
## 将标签向量化
y_train = np.asarray(train_labels).astype("float32")
y_test = np.asarray(test_labels).astype("float32")
构建模型
如果面对的是一个二分类问题,模型输出是一个概率值(模型最后一层只有一个单元并使用 sigmoid 激活函数),所以最好使用 binary_crossentropy(二元交叉熵)损失函数。
至于优化器,我们将使用 rmsprop。对于几乎所有问题,它通常都是很好的默认选择。
model = keras.Sequential([
layers.Dense(16, activation="relu"),
layers.Dense(16, activation="relu"),
layers.Dense(1, activation="sigmoid")
])
编译模型
model.compile(optimizer="rmsprop", loss="binary_crossentropy", metrics=["accuracy"])
验证集
深度学习模型不应该在训练数据上进行评估;标准做法是使用验证集来监控训练过程中的模型精度。
从原始训练数据中留出 10 000 个样本作为验证集。
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]
训练模型
history = model.fit(partial_x_train, partial_y_train, epochs=20, batch_size=512, validation_data=(x_val, y_val))
history_dict = history.history
## 这个字典包含 4 个条目,分别对应训练过程和验证过程中监控的指标。
print("\nhistory.history.keys = ", history_dict.keys())
# 使用 Matplotlib 在同一张图上绘制训练损失和验证损失
history_dict = history.history
loss_values = history_dict["loss"]
val_loss_values = history_dict["val_loss"]
epochs = range(1, len(loss_values) + 1)
plt.plot(epochs, loss_values, "bo", label="Training loss")
plt.plot(epochs, val_loss_values, "b", label="Validation loss")
plt.title("Training and validation loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.show()
## 绘制训练精度和验证精度
plt.clf()
acc = history_dict["accuracy"]
val_acc = history_dict["val_accuracy"]
plt.plot(epochs, acc, "ro", label="Training acc")
plt.plot(epochs, val_acc, "r", label="Validation acc")
plt.title("Training and validation accuracy")
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend()
plt.show()
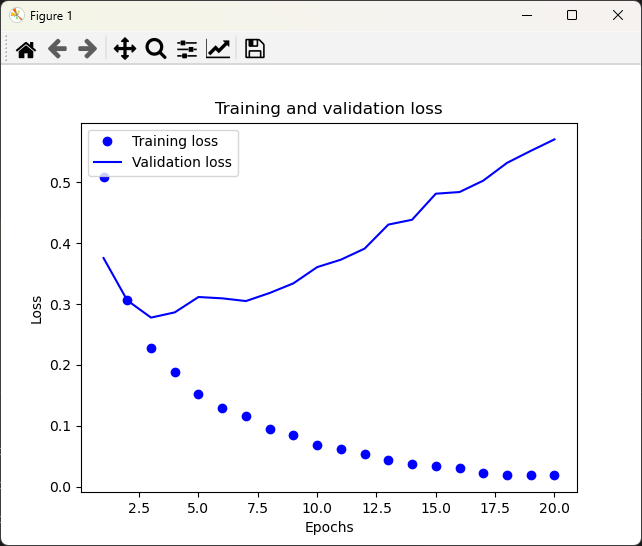
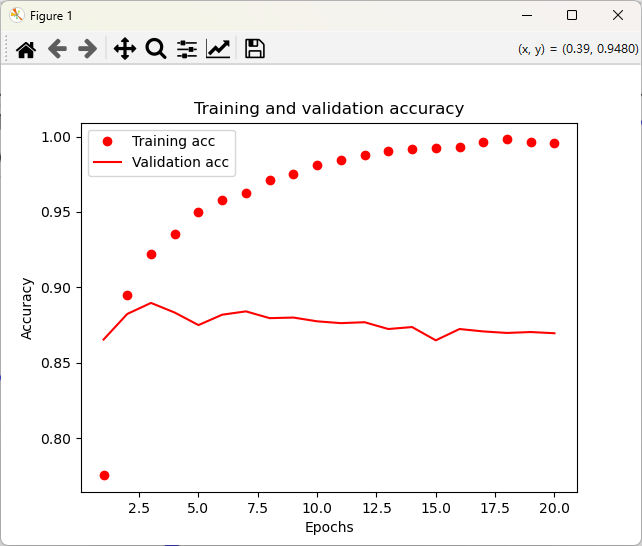
查看结果,可以发现 训练损失每轮都在减小,训练精度每轮都在提高。但验证损失和验证精度并非如此,它们似乎在第 5 轮达到峰值。
但随后,模型在训练数据上的表现越来越好,但在前所未见的数据上不一定表现得越来越好。准确地说,这种现象叫作过拟合。
在这种情况下,为防止过拟合,你可以在 4 轮之后停止训练。
从头训练
model = keras.Sequential([
layers.Dense(16, activation="relu"),
layers.Dense(16, activation="relu"),
layers.Dense(1, activation="sigmoid")
])
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy"])
model.fit(x_train, y_train, epochs=5, batch_size=512)
results = model.evaluate(x_test, y_test)
print("\nresults = ", results)
predictions = model.predict(x_test)
print("\npredictions = ", predictions)
这种相当简单的方法得到了约 88% 的精度
results = [0.285185843706131, 0.8861600160598755]
782/782 ━━━━━━━━━━━━━━━━━━━━ 1s 742us/step
模型对某些样本的结果非常确信(大于等于 0.99,或小于等于 0.09),但对其他样本不那么确信(0.7 或 0.6)
predictions = [[0.2236085 ]
[0.9989852 ]
[0.76511455]
...
[0.09326533]
[0.06604985]
[0.6980431 ]]
小结
- 通常需要对原始数据进行大量预处理,以便将其转换为张量输入到神经网络中。单词序列可以被编码为二进制向量,但也有其他编码方式。
- 带有 relu 激活函数的 Dense 层堆叠,可以解决很多问题(包括情感分类)。你可能会经常用到这种模型。
- 对于二分类问题(两个输出类别),模型的最后一层应该是只有一个单元并使用 sigmoid 激活函数的 Dense 层,模型输出应该是一个 0 到 1 的标量,表示概率值。
- 对于二分类问题的 sigmoid 标量输出,应该使用 binary_crossentropy 损失函数。
- 无论你的问题是什么,rmsprop 优化器通常都是一个足够好的选择。你无须为此费神。
- 随着神经网络在训练数据上的表现越来越好,模型最终会过拟合,并在前所未见的数据上得到越来越差的结果。一定要一直监控模型在训练集之外的数据上的性能。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 28
28 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)