IPLC: Iterative Pseudo Label Correction Guided by SAM for Source-Free Domain Adaptation in Medical I
本文提出了一种基于SAM(Segment Anything Model)的IPLC框架,用于解决医学图像分割中的无源域适应(SFDA)问题。针对现有SFDA方法存在监督不足和伪标签噪声的挑战,IPLC框架通过多次随机采样和熵权重估计生成鲁棒伪标签,结合平均负曲率最小化实现平滑分割,并采用迭代修正学习策略逐步优化模型。在M&MS心脏MRI数据集上的实验表明,该方法在四个不同扫描仪域上均显著优
·
2024 MICCAI 基于SAM的IPLC框架
📌一、 背景
- 背景:
- 深度学习在医学图像分割中取得了巨大成功,但其依赖于训练和测试数据分布一致的假设。然而,实际临床场景中,由于扫描设备、成像协议、图像质量等因素,训练数据集(即源域)和测试数据集(即目标域)之间普遍存在分布差距,导致模型在目标域上的性能大幅下降。
- 域适应方法应运而生,但大多数方法需要同时访问源域和目标域图像,这在医学图像领域受限于隐私和传输问题。因此,无源域适应(SFDA)方法成为研究热点,即在没有源数据的情况下,将预训练模型适应到目标域。
📌二、 研究动机与挑战
- 现有方法的局限性:
- 现有的 SFDA 方法由于监督不足和伪标签(pseudo labels)不可靠,性能受限。例如,仅更新批量归一化层或使用熵最小化作为监督的方法,无法提供足够的约束,容易导致过度自信但错误的预测。
- 一些方法虽然使用伪标签,但没有考虑伪标签中的噪声,从而误导模型适应。
- 本文的动机:为了解决现有 SFDA 方法中监督不足和伪标签质量差的问题,提出一种新的框架,利用SAM来生成高质量的伪标签,并通过迭代修正伪标签来提升模型在目标域上的性能。
📌三、方法
✅1. IPLC 框架:
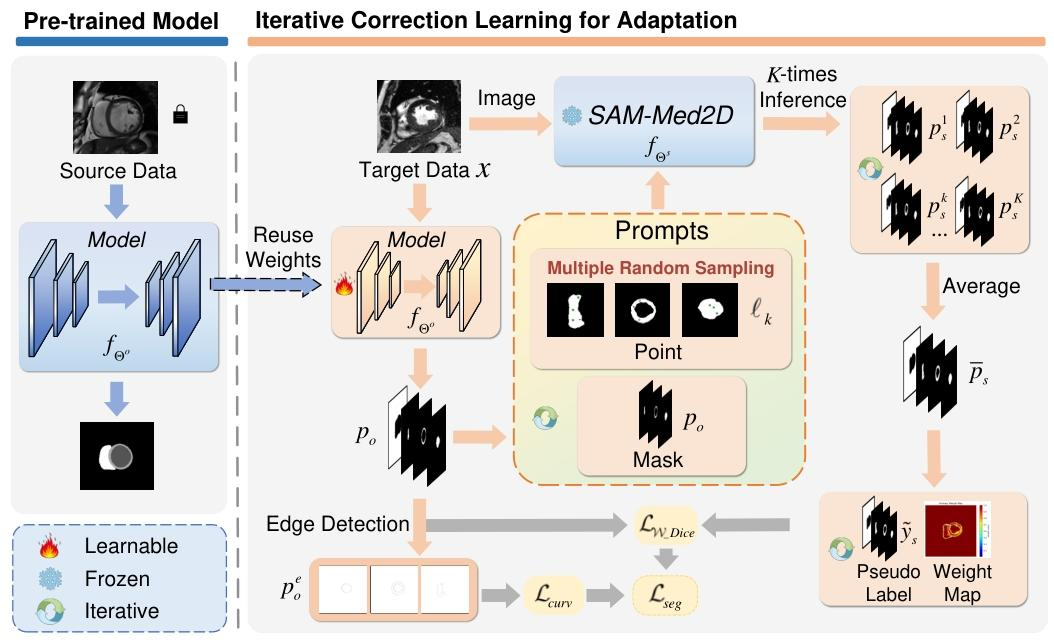
- 输入:预训练的源模型fTheta_o和SAM-Med2D模型fTheta_s,以及目标域的未标记图像。
- 核心流程:通过多次随机采样(MRS)和熵权重估计(EWE)生成鲁棒的伪标签;引入平均负曲率最小化来提供更充分的约束并实现更平滑的分割;提出迭代修正学习(ICL)策略,通过迭代更新提示(prompts)来优化模型。
✅2.关键模块:
1.多次随机采样(MRS)和熵权重估计(EWE)
获取鲁棒的伪标签并减轻伪标签的噪声
- 为了解决伪标签噪声问题,通过 MRS 生成多个点提示(point prompts),结合模型输出的掩码提示(mask prompts),通过 SAM-Med2D 进行多次推理,然后对结果取平均,生成更鲁棒的伪标签。
MRS:
SAM-Med2D会基于点提示和掩码提示为每个类别单独生成对应类别的概率图,将这C个单通道的类别概率图组合成一个多通道概率图p_sk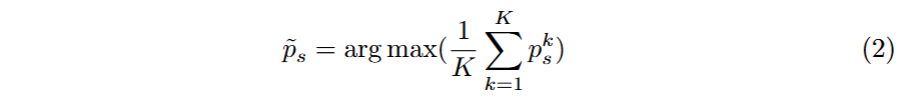
EWE
通过公式(3),权重图被归一化到 [0, 1] 区间,较高的熵值会被转换为较低的权重。log2C就是具有C类分割ps杠的最大熵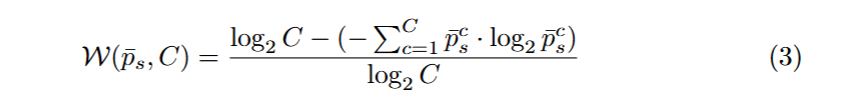
基于权重的 Dice 损失定义如下: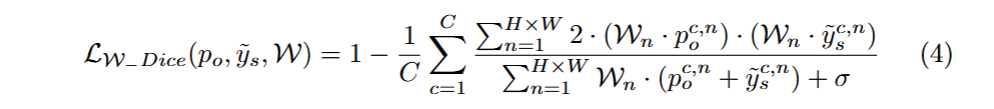
注意:
2. 基于平均负曲率的正则化:
提供更充分的约束并实现更平滑的分割效果
- 由于伪标签的准确性有限,直接使用伪标签监督会限制模型性能。通过最小化模型预测边缘的平均负曲率,使相邻像素之间的曲率更接近,从而实现更平滑的分割结果。

3. 迭代修正学习(ICL):
优化模型
- 通过迭代更新提示(prompts),利用 SAM-Med2D 生成更可靠的伪标签,并结合加权 Dice 损失和曲率损失来优化模型,从而逐步提升伪标签的质量和模型的适应性。总损失函数如下:
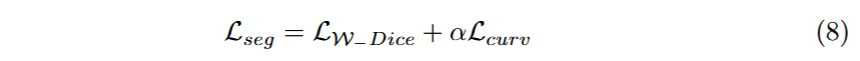
📌四、实验
- 数据集与评估指标:
- 使用公开的多中心、多厂商、多疾病心脏图像分割(M&MS)数据集,包含来自 4 个不同厂商扫描仪的 192、252、150 和 100 个心脏 MRI 体积图像,分别作为源域(A)和目标域(B、C、D)。
- 评估指标包括 Dice 分数(越高越好)和平均对称表面距离(ASSD,越低越好)。
- 实现细节: 基于 2D UNet backbone,图像归一化至 [-1, 1] 并裁剪为 256×256;优化 20 个 epoch,学习率 1e-4,K=10,曲率损失权重 α=0.01
- 实验结果:
- 与其他方法对比:IPLC 方法在所有目标域上均显著优于现有的几种先进 SFDA 方法(如 PTBN、TENT、EATA、SAR),在 Dice 分数和 ASSD 上均取得了最佳性能。例如,在目标域 C 上,与“源域模型直接使用”相比,IPLC 方法将 LV、MYO 和 RV 的平均 Dice 分数分别提高了 3.10%、5.06% 和 3.41%,并且在所有组织上均实现了最低的 ASSD。
- 消融研究:验证了 IPLC 方法中各个组件(MRS、EWE、平均负曲率最小化、ICL)的有效性。实验结果表明,每个组件都对性能提升有显著贡献,结合所有组件的 IPLC 方法取得了最高的 Dice 分数(85.10%)。
- 超参数分析:研究了随机采样次数 ( K ) 和曲率损失权重α对性能的影响,发现 ( K=10 ) 和 ( α=0.01 ) 时性能最佳。
📌五、结论
本文提出的 IPLC 框架通过多次随机采样和熵权重估计生成鲁棒的伪标签,引入平均负曲率最小化提供更充分的约束,并通过迭代修正学习策略逐步提升伪标签质量,从而有效解决了现有 SFDA 方法中监督不足和伪标签不可靠的问题。在 M&MS 数据集上的实验结果表明,该方法在多个目标域上均取得了优异的性能,优于现有的先进方法。
📌六、总结与启发
- 核心贡献:本文的核心贡献在于提出了一种新的 SFDA 框架 IPLC,通过生成高质量的伪标签和迭代优化策略,显著提升了医学图像分割模型在目标域上的适应性。
- 研究思路启发:
- 在处理域偏移问题时,可以考虑从生成更可靠监督信号(如高质量伪标签)和引入额外约束(如曲率最小化)两个角度入手。
- 迭代优化的思想在模型适应过程中非常有效,通过逐步改进伪标签和模型参数,可以实现更好的性能。
- 可能的拓展方向:
- 探索其他生成高质量伪标签的方法,如结合生成对抗网络(GAN)或利用多模态信息。
- 将该框架应用于其他类型的医学图像分割任务或更广泛的计算机视觉任务中,验证其普适性。
原文题目:IPLC: iterative pseudo label correction guided by SAM for source-free domain adaptation in medical image segmentation 有代码

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)