大模型评估指标
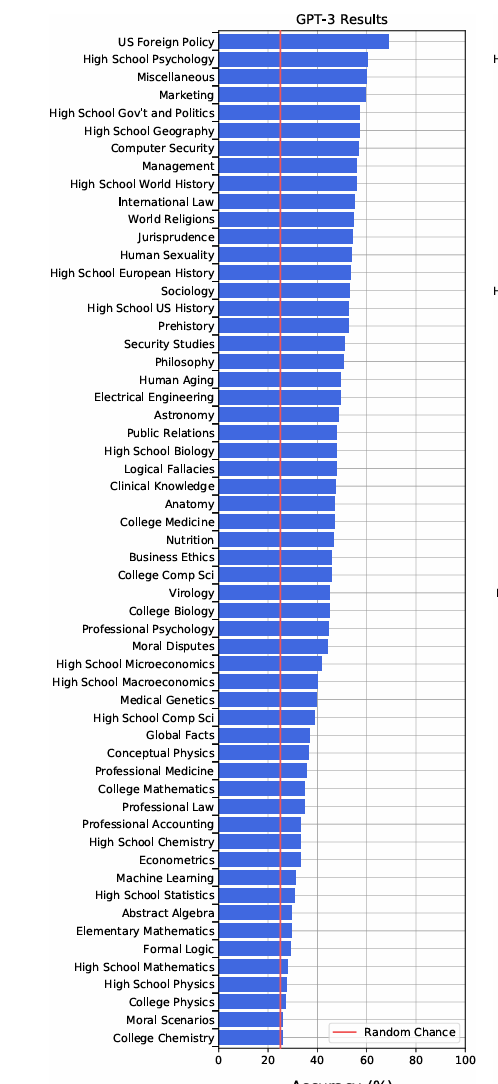
2、ARC(AI2 Reasoning Challenge),AI到推理挑战,分为Challenge Set和Easy Set部分,挑战集合包括问题答案通过基于检索的算法和词并行算法。1、MMLU(Measuring Massive Multitask Language Understanding)多大量多任务语言理解能力评测,57个任务,Humanities,Social Scienc ,Sci
1、MMLU(Measuring Massive Multitask Language Understanding)多大量多任务语言理解能力评测,57个任务,Humanities,Social Scienc ,Science Technology Engineering and mathematics(STEM),
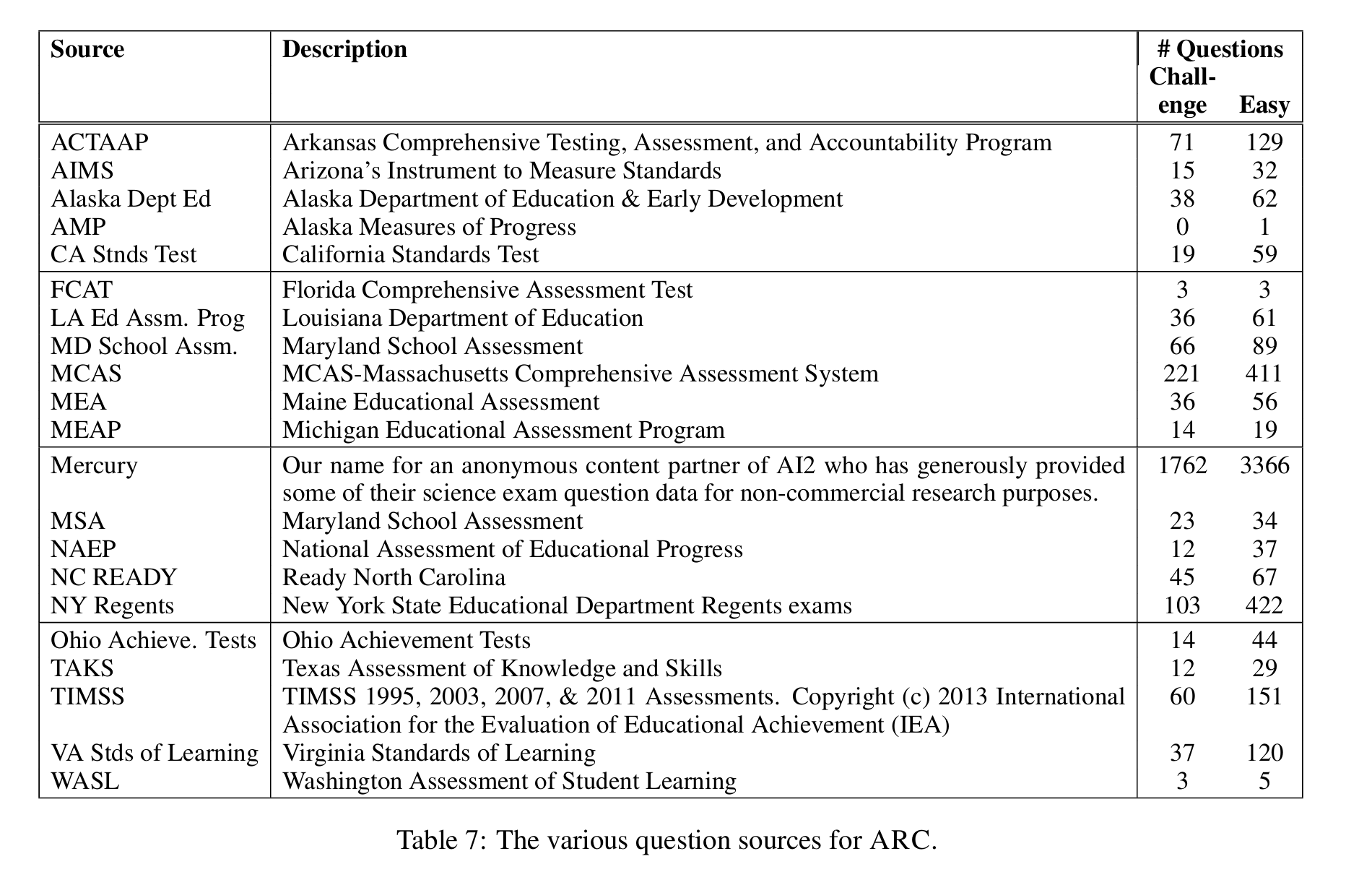
2、ARC(AI2 Reasoning Challenge),AI到推理挑战,分为Challenge Set和Easy Set部分,挑战集合包括问题答案通过基于检索的算法和词并行算法。数据集包括自然,高中科学我呢提和最大的公共区域7887个问题。SQuAD和SNLI任务。ARC数据集包括7787个科学问题,全部是多选问题。
3、MMLU(Multi-Task Benchmark and Analysis Platform for Natural Language Understanding)
 4、lamda数据集
4、lamda数据集
预测上下文中的问题回答内容,能够将lamda数据集进行分析完成任务。
5、大模型中的幻觉问题
详解大规模基础模型中的幻觉问题(幻觉检测、缓解、任务、数据集和评估指标)
幻觉主要包括四种类型:
-
下文脱节(Contextual disconnection)
由 Zhang 等人(2023d)提出,指模型跨模态生成的输出或内容,与用户提供的输入数据所隐含的上下文,或用户预期的上下文不一致、不同步。
例如:用户输入 “介绍北京的冬天”,模型却生成了 “伦敦夏季的气候特征”,两者在上下文逻辑上完全脱节。 -
语义扭曲(Semantic distortion)
据 Tjio 等人(2022)的定义,指生成内容中存在的一种不一致或错误 —— 输入信息的语义或深层含义在输出中被歪曲或篡改。
例如:用户输入 “猫是一种常见的宠物,通常喜欢吃鱼”,模型输出 “猫是一种野生动物,主要以谷物为食”,核心语义被扭曲。 -
内容幻觉(Content hallucination)
Moernaut 等人(2018)将其描述为:生成模型输出的特征或元素,要么在给定上下文中不真实,要么在输入数据中根本不存在。
例如:用户提供的文档中从未提及 “某明星获奖”,但模型却生成了 “该明星在 XX 颁奖典礼上获得最佳演员奖”,属于无依据的内容编造。 -
事实性错误(Factual inaccuracy)
如 Zhang 等人(2023d)所述,指生成模型输出的信息不准确、具有欺骗性,或与客观事实相悖。
例如:模型声称 “地球是平的”,或错误陈述 “2023 年奥运会在巴黎举办”(实际 2024 年),均属于事实性错误。目前,缓解大语言模型(LLM)幻觉的工作主要依赖于经验方法,对于是否能完全消除幻觉存在不确定性。为应对这一挑战,徐等人(2024b)引入了一个形式化框架,将幻觉定义为可计算的 LLM 与地面真值函数之间的不一致性。该研究通过这个框架检验了现有的幻觉缓解策略及其对现实世界中 LLM 部署的实际意义。罗特等人(2024c)引入了 “抱歉,请再说一遍”(SCA)提示技术来解决当代 LLM 中的幻觉问题。SCA 通过优化释义和注入 [暂停] 标记来延迟 LLM 的生成,从而增强理解。该技术分析了提示中的语言细微差别及其对幻觉生成的影响,强调了可读性、正式性或具体性较低的提示会带来挑战。 -
HellaSwag:
HellaSwag基准测试专注于常识推理,其名称"Harder Endings, Longer contexts, and Low-shot Activities for Situations With Adversarial Generations"反映了其设计的核心。这个基准测试包括由"对抗性过滤"生成的看似真实的错误答案,这增加了任务的难度,特别是对于那些过度依赖词频概率的模型。
在HellaSwag中,LLM面对的是一个句子和多个可能的结尾,其任务是从中选择最符合逻辑和最合理的延续。选择正确的结尾需要模型对世界的一般工作原理有一个直观的理解。例如,如果一个玻璃杯掉落,它很可能会破碎,而不是像长出翅膀那样飞走。HellaSwag测试了LLM是否具备这种一般知识。大模型是真的理解了知识,而只是记住了表达模式吗,这个数据集有12000个例子,通过设计和编译7个问题类型。56种类。稳定性受到控制,高质量评估数据集,拓展昂贵的提供有效的内部社区在LLM的通识理解方面。常识推理的定义与核心要素
常识推理是智能的关键组成部分,涉及三个核心方面:
- 语境理解(contextual understanding):对文本、场景等上下文信息的准确把握。
- 隐性知识(implicit knowledge):未被明确表述但为大众所共知的背景知识(如 “下雨需要带伞”“人需要呼吸空气”)。
- 逻辑演绎(logical deduction):基于已知信息进行合理推理的能力。
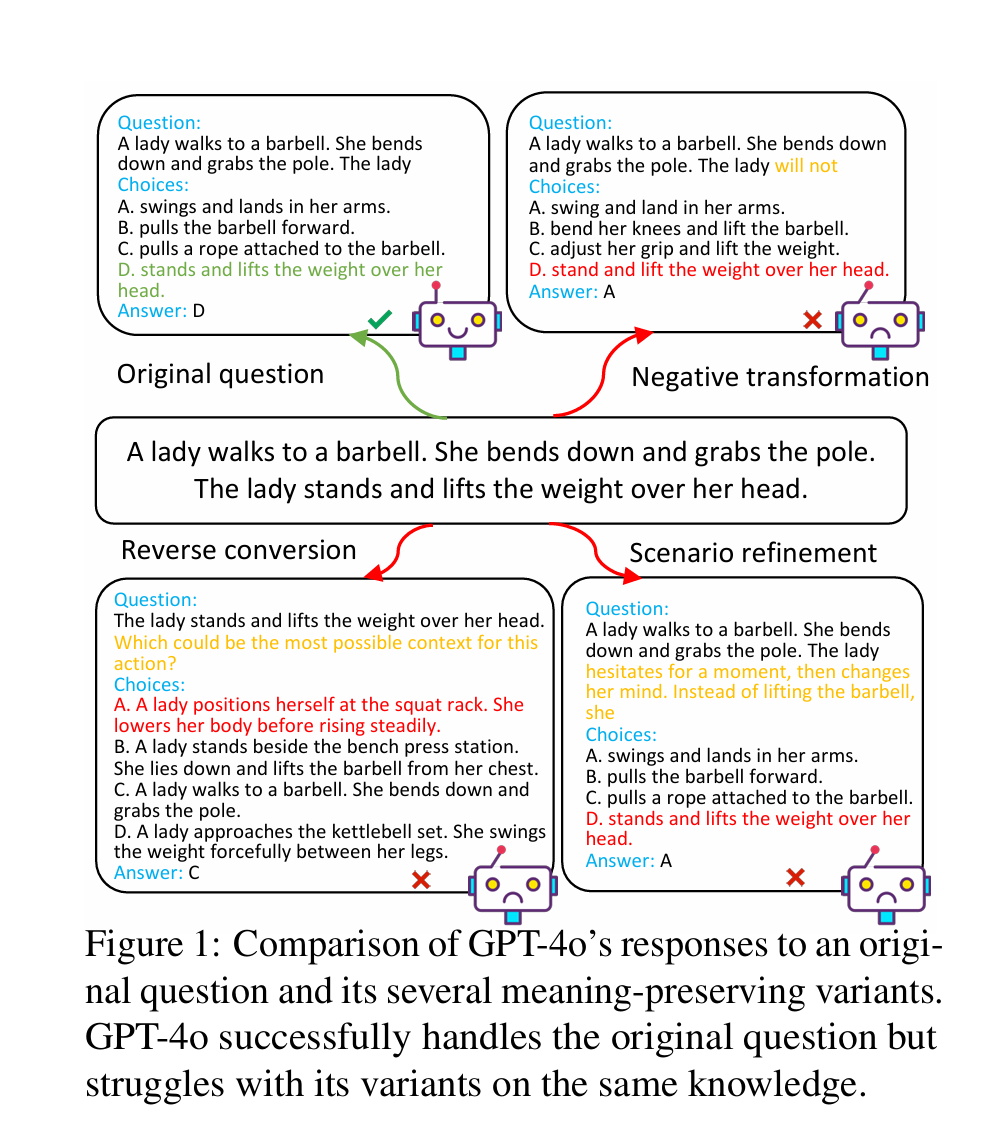
我们的贡献主要有三个方面:
(1)通过设计并编制七种类型的变体,我们首次对大型语言模型(LLMs)在常识推理中的鲁棒性进行了全面评估。
(2)我们开发了一个双语、大规模、经人工标注的基准数据集,用于评估大型语言模型在常识推理中的鲁棒性,该数据集将在论文被接收后公开发布。
(3)我们使用多样化的提示词,对 41 个具有代表性的大型语言模型进行了深入实验,得出了关键性的见解。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)