AI画图越来越逼真,却当不好图像质检员|AGI-Eval独家托管A-Bench
当下,文生图 AI 正处于"能用"与"好用"的过渡地带。指令遵循能力与画质表现,将是其向工业化应用迈进过程中的两大核心命题。例如下图测试案例进一步印证了这一研究的必要性:左侧图像在处理"秋日小镇里,复古马车行驶在铺满落叶的街道上"时出现建筑比例失调、空间构图混乱等明显缺陷;右侧的"波普风女性肖像"则暴露出五官比例异常、色彩搭配杂乱等质量问题。业界虽然开始广泛采用多模态大模型作为 AI 图像的自动化

当下,文生图 AI 正处于"能用"与"好用"的过渡地带。指令遵循能力与画质表现,将是其向工业化应用迈进过程中的两大核心命题。然而,一个更为关键的问题正逐渐浮出水面:当 AI 生成的图像质量参差不齐时,谁来充当可靠的"质检员"?
例如下图测试案例进一步印证了这一研究的必要性:左侧图像在处理"秋日小镇里,复古马车行驶在铺满落叶的街道上"时出现建筑比例失调、空间构图混乱等明显缺陷;右侧的"波普风女性肖像"则暴露出五官比例异常、色彩搭配杂乱等质量问题。面对这些显而易见的生成缺陷,多模态大模型能否准确识别并给出合理评估?这正是 A-Bench 要深入探究的核心问题。

业界虽然开始广泛采用多模态大模型作为 AI 图像的自动化评估工具,但这些"智能裁判"的判断准确性却鲜有人深究。试想,如果多模态大模型连基本的语义错误都识别不出,连明显的质量缺陷都视而不见,那么基于它们构建的评估体系岂不是"盲人领盲人"?
面对这一迫切的技术需求,来自上海交通大学和南洋理工大学的团队引入了 A-Bench,这是一个具有里程碑意义的研究成果。作为首个专门评估多模态大模型在 AI 图像质量检测能力的"诊断性"基准测试,A-Bench 专注于系统化检验多模态大模型在语义理解和质量评估方面的真实表现。这项突破性研究填补了该领域长期存在的评估空白,首次为我们揭开了多模态大模型作为" AI 图像质检员"的真实面纱。
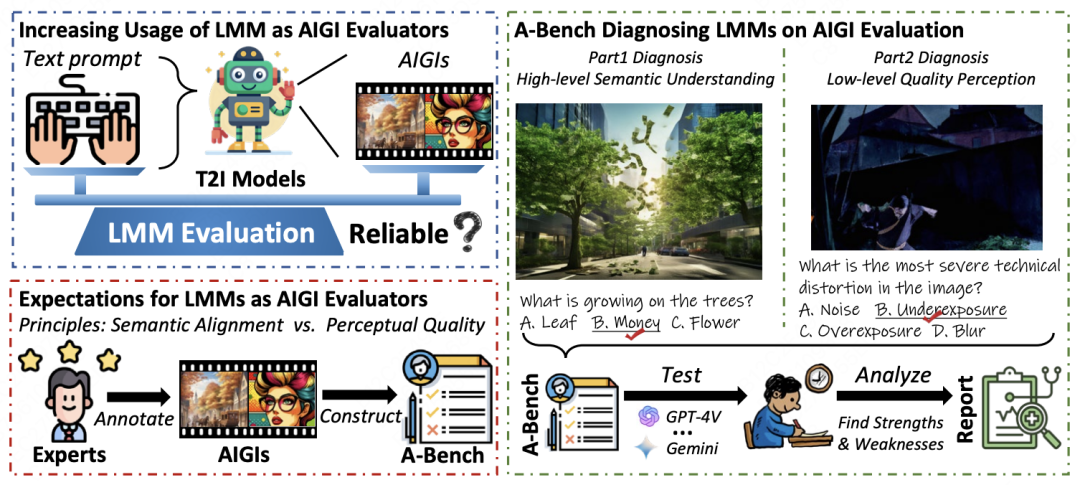
△ A-Bench 旨在查明多模态大模型对于文生图 AI 生成图像评估的可靠性
如上图所示,作为 AI 图像评估领域的首个系统性“能力体检报告”,A-Bench 通过严格的测试流程,先由专家对 AI 生成图像( AIGIs)进行标注,构建形成 A-Bench 基准测试,再通过GPT-4V、Gemini等多模态大模型(LMMs)执行测试,最后经人工分析多模态大模型在语义对齐和感知质量评估方面的表现,全面检验多模态大模型在面对真实 AI 生成图像时的实际表现,总结优势与不足并生成报告,客观揭示这些“智能审查员”的真实能力边界。
本文数据均引用自 A-Benc 论文(arXiv:2406.03070v2 [cs.CV] ),该论文已被 ICLR 2025 录用。

-
论文地址:
https://arxiv.org/pdf/2406.03070
该基准测试已与 AGI-Eval 大模型评测社区达成合作,后续将由 AGI-Eval 评测社区负责长期维护与更新。欢迎大家持续关注,可前往社区查看 A-Bench 的所有子集!
-
A-Bench 榜单地址:
https://agi-eval.cn/evaluation/det AI l?id=15
-
微信小程序:AGI-Eval模型评测
接下来,让我们深入探讨 A-Bench 的核心设计理念——通过高层语义理解和低层质量感知两大维度,全面诊断多模态大模型的 AI 图像评估能力,并揭示这些"智能审查员"的真实表现。
01. A-Bench 中的两个
关键诊断子集
为了确定多模态大模型是否能有效评估 AI 生成图像是否满足这些标准,必须评估它们在高层语义理解和低层质量感知方面的能力,这两者是其作为 AI 生成图像评估器的核心。A-Bench 基准测试包含 2864 个来自各种顶级文本生成图像模型(T2I)的 AI 生成图像综合数据集,其中 1408 个 AI 生成图像用于 A-Bench P1,1456 个 AI 生成图像用于 A-Bench P2,每张图附带由人类专家标注的问答集,覆盖高层语义理解和低层质量感知两大核心维度。
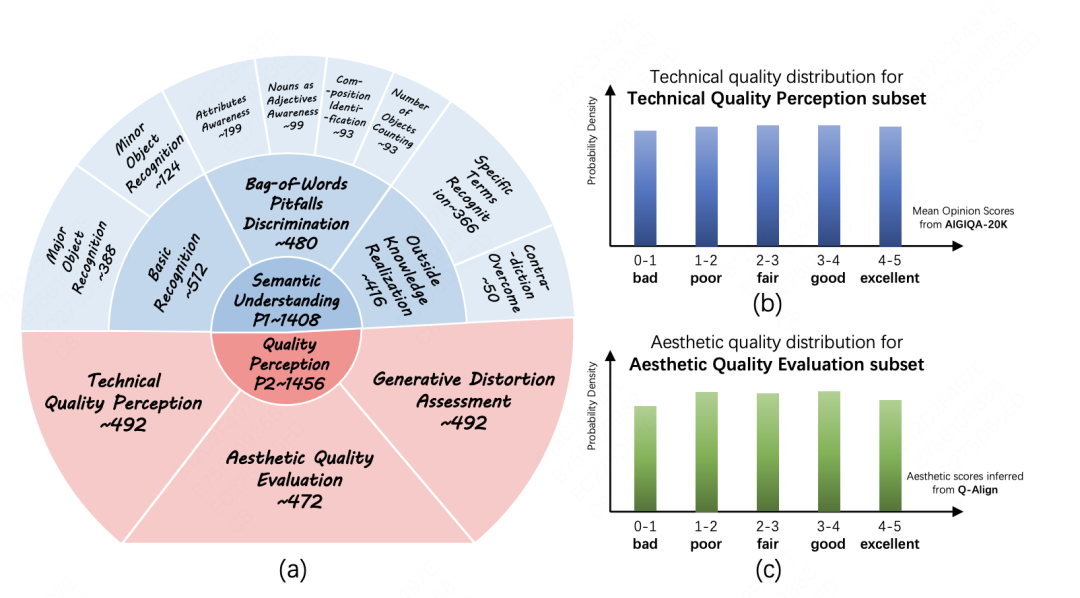
△ A-Bench 聚焦方面及相应质量分布图。
1.1 高层语义理解
A-Bench P1:高层语义理解(High-level Semantic Understanding)其中包含 1408 个具有挑战性的多模态问题答案对。A-Bench P1 针对三个关键领域:基本识别、词汇陷阱辨别和外部知识实现,旨在从简单到复杂逐步测试多模态大模型在 AI 生成图像语义理解方面的能力。
-
基本识别:能否认出画面主体,如人物头发颜色。
-
这一方面集中于对 AI 生成图像的基本语义理解,分为主要对象识别(前景中描绘的人类或物体)与次要对象识别(如背景元素或次要角色)两个角度。

词汇陷阱辨别:能否识破复杂描述的误导,如“鲨鱼般流畅的潜艇”、“五只猫 VS 五只猫头鹰”。
这一维度侧重于对使用词汇袋提示创建的 AI 生成图像的辨别性语义理解,分为四个领域:
-
属性意识:定义为准确识别 AI 生成图像中对象属性的能力。
-
名词作为形容词意识:鉴于 T2I 模型可能错误地将名词解释为形容词,导致生成不需要的对象而不是预期的属性。
-
构图识别:定义为正确理解方向、遮挡、大小比较和空间排列等构图关系的能力。
-
物体数量计数:被认为是准确计算图像中指定物体的能力,这对于评估 AI 生成图像是否与提示的数值规范一致至关重要。

在外部知识实现方面,能否突破图像限制关联外部知识?
这一方面强调利用图像中未直接描绘的外部知识的推理能力,可分为以下两个维度:
-
特定术语识别:涉及识别与地理、体育、科学、材料、食品、日常生活、生物、品牌和风格等不同领域相关的特定场景和物体。
-
矛盾克服:定义为即使在 AI 生成图像内容与既定世界知识相矛盾时也能正确解释 AI 生成图像的能力,这对于评估从有争议的提示生成的 AI 生成图像尤为重要。

多模态大模型在 A-Bench P1 子集上的性能结果揭示了几个关键见解:
基本识别能力:表现优异
-
平均准确率达 85%+,接近人类水平。
-
在简单提示场景下,能够准确评估 AI 生成图像的文本对齐情况。
词汇陷阱辨别:存在明显短板
-
整体表现不佳,错误率超 40%。
-
在复杂语义理解上存在潜在挑战。
-
经常出现将名词误解为实体对象的错误。
外部知识整合:能力分化严重
-
特定术语识别表现良好,显示出全面的先验知识储备。
-
但在识别反常识内容方面明显落后(如"轮船在云端航行"等场景)。
-
人类能够轻松识别的逻辑矛盾,多模态大模型却频频失手。
-
由于过度依赖预训练知识,反而在处理违背常识的内容时受限。
-
此类任务的正确识别率普遍不足 65%。
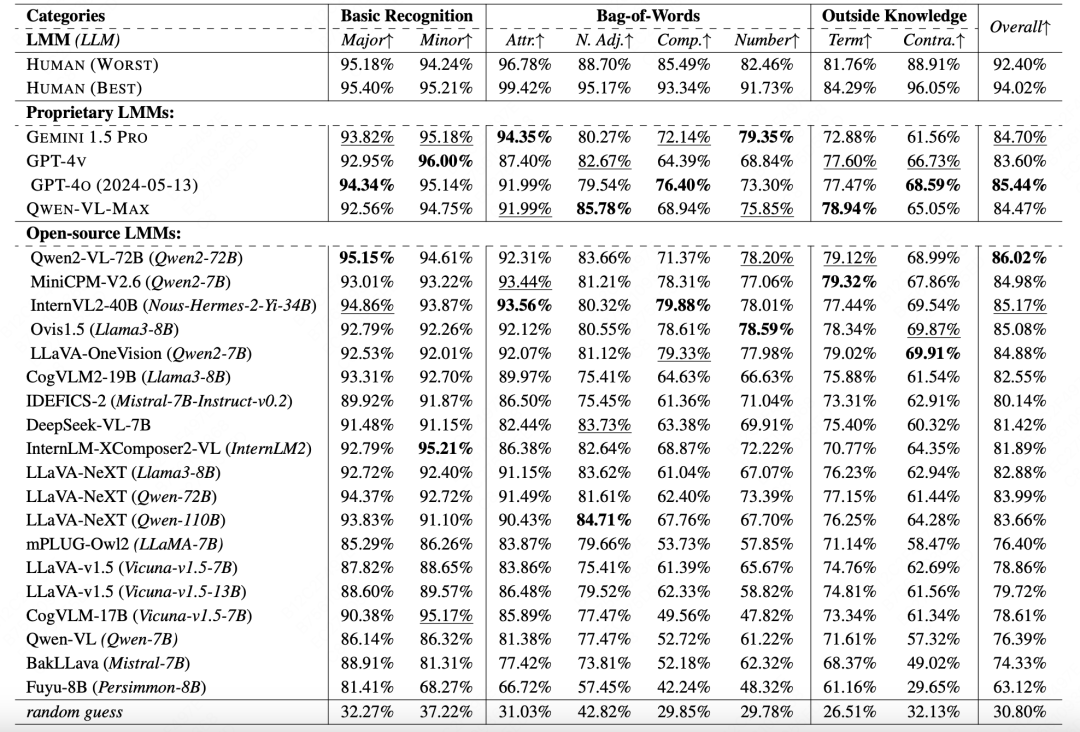
△ A-Bench 1子集上的基准测试结果,专有和开源大型语言模型(LMMs)的最佳性能以粗体标记,第二好的性能分别以下划线标记。
1.2 低层质量感知
A-Bench P2:低层质量感知(Low-level Quality Perception),对于低层质量感知,包含 1456 个具有挑战性的多模态问题答案对。A-Bench P2 集中在技术质量感知、美学质量评估和生成失真评估,旨在涵盖常见的和 AI 生成图像特有的质量问题。
-
技术质量:指示直接降低图像质量的低级特征,如模糊、噪声、曝光等。
-
美学质量:指示影响 AI 生成图像美学吸引力的属性,包括配色、照明等。
-
生成失真:指示 AI 生成图像特有的意外失真,如低完成度导致的生成模糊、几何结构混乱、物体消失、人脸结构错位等异常。

A-Bench P2 研究结果显示,在技术质量方面,人类通常比美学质量评估表现更好,但大语言多模态模型在这两个子类别中的表现水平相似(Qwen2-VL-72B 和 MiniCPM-V2.6 除外)。在生成失真方面,大多数大语言多模态模型在该类别中表现最差,人类评委对生成畸变的识别率超 90%,而最强的多模态大模型(Qwen2-VL-72B)仅 70.23%,这表明它们对 AI 生图特有的几何畸变不敏感。
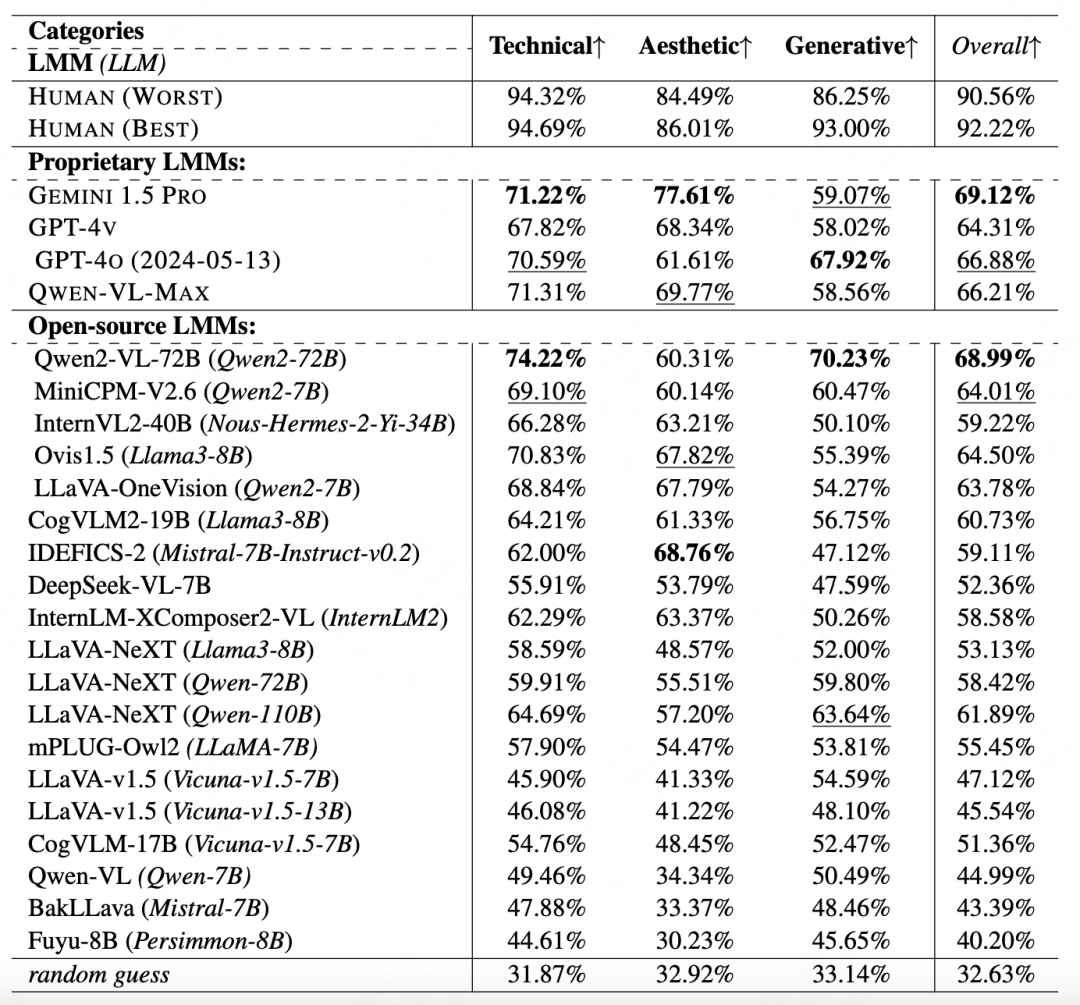
△ A-Bench 2子集上的基准测试结果,对于专有和开源大语言模型,最佳性能以粗体标记,次佳性能分别以下划线标记。
02. A-Bench 实验与发现
2.1 实验阶段
在 A-Bench 中,使用了两种类型的问题格式,包括是非题和 What 问题。是非题(占25.9%)用于评估多模态大模型的基本判断能力,而 What 问题(占74.1%)更复杂,要求多模态大模型对 AI 生成图像进行更全面的理解。
研究人员组建了一支由 15 名具有人工智能图像评估经验的人类标注者组成的团队,在受控实验室环境中进行问题标注。标注过程在受控实验室环境中进行,以确保一致性和可靠性。测试了 23 款主流多模态大模型(含 GPT-4o、Gemini 1.5 Pro 等闭源模型及 Qwen-VL-Max 等开源模型)。然后,我们在 A-Bench 上测试了 23 个突出的多模态大模型,包括开源和闭源模型。从结果中可以看出,即使最好的多模态大模型也远远落后于人类。
2.2 A-Bench 的发现
开源、闭源存在差距:
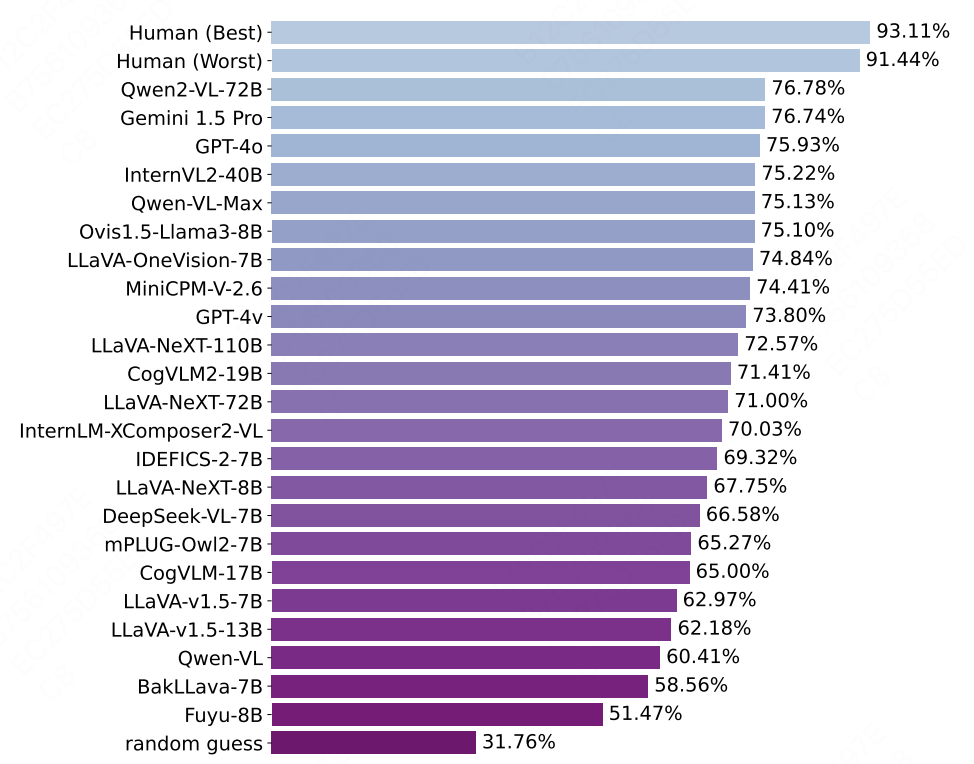
△ A-Bench 结果:人类 23 个选定的大语言模型以及随机猜测之间总体准确率的对比
所有多模态大模型都显著优于随机猜测(准确率 31.76%),表明它们在处理 AI 生成图像评估方面的能力,其中 Qwen2-VL-72B 领先(准确率 76.78%),紧随其后的是 Gemini 1.5 Pro(准确率76.74%)和 GPT-4o(准确率 75.93%)。
在开源多模态大模型中,由于其可访问性和可修改性,它们是 AI 生成图像评估的首选,Qwen2-VL-72B 脱颖而出,甚至优于最好的闭源竞争对手。
多模态大模型在 AI 生成图像评估方面仍远未达到人类的水平:
尽管多模态大模型在某些方面表现出潜力,但在理解和评估 AI 生成图像的质量方面仍远不及人类。
在准确率方面:即便表现最差的真人评测者,其准确率也超出最佳多模态大模型(Qwen2-VL-72B)14.66%。
专有大模型仅在基本识别方面达到了初具人类水平的性能,大语言模型在词汇陷阱辨别方面存在困难,特别是在识别组成和计算物体数量上,这凸显了它们在处理复杂的组合关系和特定物体数量时的局限性。在外部知识方面,专有大语言模型与人类相比,在特定术语上仅表现出轻微的性能差距,但在识别有争议的内容方面明显落后。
与人类相比,大语言模型在技术质量、美学质量、生成失真感知方面存在显著缺陷,在不同质量维度上表现参差不齐。
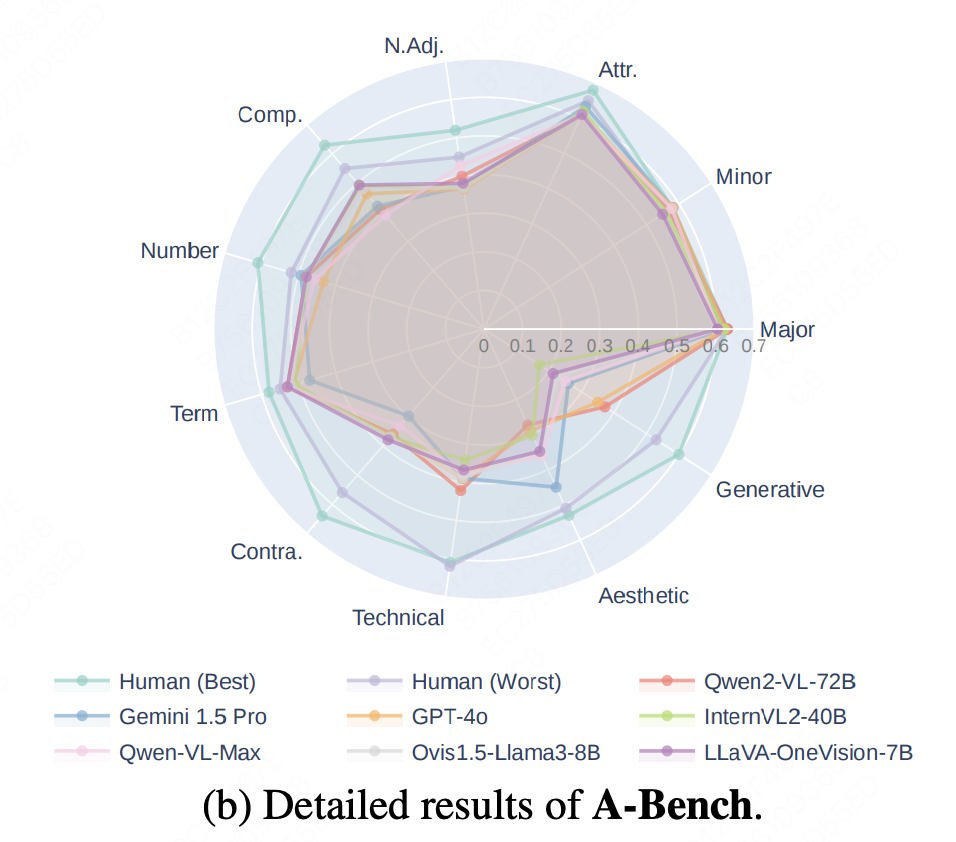
△ 顶级多模态大模型在不同子类别中表现出不同的性能
在稳健性方面:顶级多模态大模型在不同子类别中的表现各不相同,表明其缺乏稳健性,而人类在这些类别中表现出更一致和平衡的表现。
03.未来展望
当前文生图模型在创意产业中的应用越来越多,当前的多模态大模型在评估 AI 生成图像时,还远未“毕业”。它们能看清简单的“主体头发颜色”,却频频掉入“鲨鱼般潜艇”的词汇陷阱;能评判基础曝光,却对 AI 特有的“人脸错位”等怪诞畸变近乎“视觉文盲”,当 AI 开始接管创意产业,我们需要确保它的“审美”不是下一个失控的潘多拉魔盒,而是照亮创意边界的明灯。
A-Bench 就像是一面镜子,照出多模态大模型的 “视力缺陷”。我们引以为傲的 AI 视觉系统,或许连最基础的“图像品控”都尚未掌握。这或许预示着下一波 AI 浪潮的关键——不是创造更逼真的图像,而是培养能真正理解图像的智能体。通过构建针对性的对抗训练集、注入结构化多模态知识、开发动态评估框架……我们有望让多模态大模型从“视觉文盲”蜕变为具备艺术眼光和常识判断的“ AI 策展人”。或许未来的 AI 需要先通过图像“入学考试”,学会用逻辑丈量像素,用知识解构色彩,才能真正从“画匠”蜕变为“艺术评论家”.
A-Bench 已开源评估代码和数据集,期待学界利用这一工具,推动模态大模型艺术鉴赏能力的提高!
最后,如果你也喜欢这篇文章,那就点赞转发收藏吧~下一期继续为你带来使用干货,别忘了关注我们!
— 完 —

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)