Agent开发01-概述
本文概述了基于大语言模型(LLM)的智能体开发框架,重点分析了规划、记忆和工具使用等核心组件。在规划部分,详细介绍了任务分解方法和反思机制,提出通过层次化任务网络和思维链等技术实现复杂任务求解,并阐述了Reflexion框架如何通过执行者、评估者和自我反思模型的协作实现迭代优化。评估部分区分了动态和静态两种评测方式,涵盖理解能力、知识准确性、工具使用效率等维度,建议采用准确率、延迟等量化指标进行全
总述
当前基于LLM的智能体开发逻辑,一般是由LLM 充当智能体的大脑,并由几个关键组件进行补充:规划(Planning)、内存(Memory)、工具使用(Tool Use):
● 规划:包括子任务分解、思维链、反思、自我批评等;
● 记忆:短期记忆、长期记忆;
● 工具:获取外部信息和能力,包括搜索、外部服务、功能函数、知识库等;
● 行为:根据上下文和工具信息执行相应的行为。
整体的参考架构和流程图如下: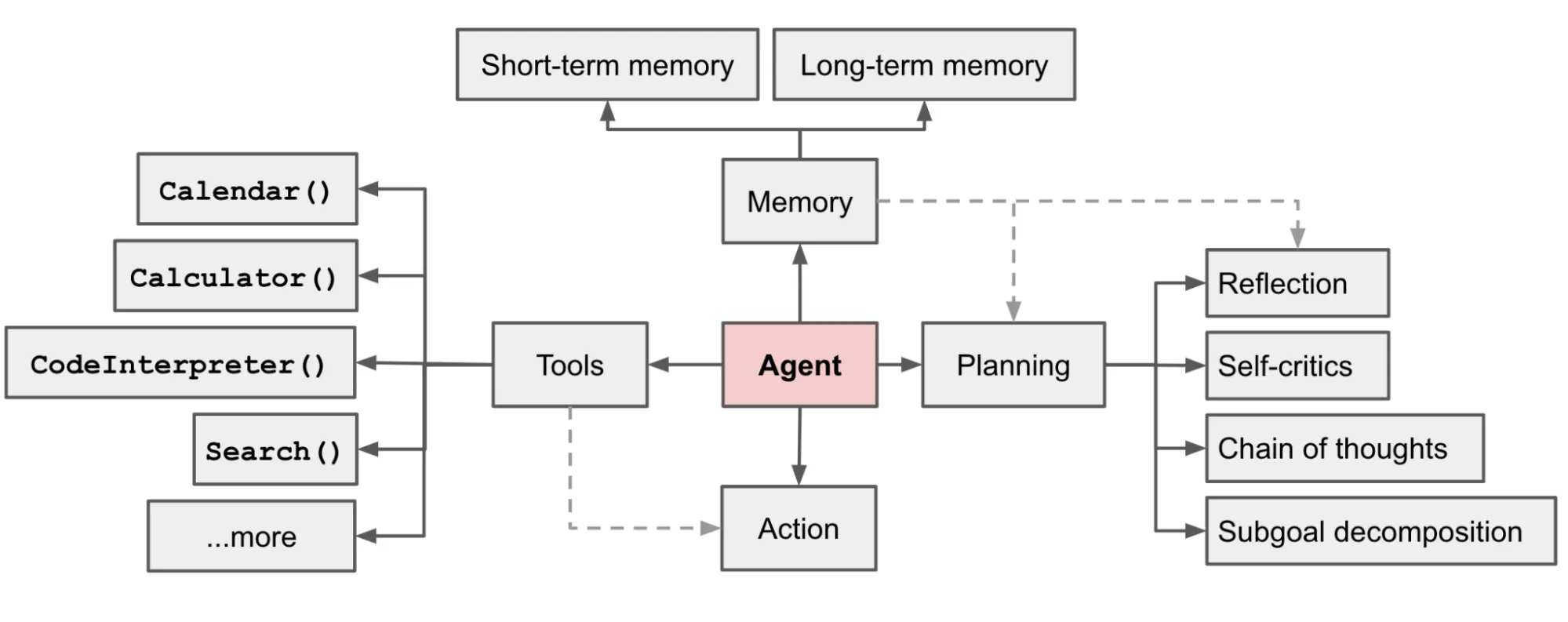
1.规划
● 无反馈规划:大语言模型在做推理的过程中无需外界环境的反馈。这类规划进一步细分为三种类型:
○ 单路推理,仅一次大语言模型调用就输出完整的推理步骤;
○ 多路推理,借鉴众包思想,让大语言模型生成多个推理路径,进而确定最佳路径;
○ 借用外部的规划器。
● 有反馈规划:外界环境提供反馈,而大语言模型需要基于环境的反馈进行下一步以及后续的规划。这类规划反馈的提供者来自三个方面:环境反馈、人类反馈和模型反馈
1.1 任务分解
复杂任务不是一次性就能解决的,需要拆分成多个并行或串行的子任务来进行求解,任务规划的目标是找到一条最优的、能够解决问题的路线。
任务规划通常包含以下几个步骤:
- 任务理解
理解用户目标,分析任务需求,可以使用自然语言处理模块提取关键意图。 - 任务分解(Task Decomposition)
将大任务拆分为一系列可管理的子任务。常见方式有:
○ 层次任务网络(HTN,Hierarchical Task Network)
○ 规则驱动的拆分(如 if-then 规则)
○ LLM驱动的链式思维(Chain-of-Thought Prompting),即思维链,类似的还有思维树(Tree of thoughts)等 - 任务依赖建模
确定子任务间的顺序与依赖关系,构建任务图(DAG结构或任务树)。 - 资源与能力匹配
判断每个子任务是否可以由当前Agent执行,或需要调用外部工具/接口。 - 执行与监控
调度任务执行,并监控状态;支持错误恢复、重试、条件跳转等控制逻辑。 - 结果整合与回报
将子任务的结果聚合,反馈给用户或用于后续步骤。
1.2 反思和提炼
自我反思是一个重要的方面,它允许Agent通过完善过去的行动决策和纠正以前的错误来迭代改进。它在不可避免地会出现试错的现实任务中发挥着至关重要的作用。ReAct (Yao et al. 2023) 发现让Agents执行下一步action的时候,加上LLM自己的思考过程,并将思考过程、执行的工具及参数、执行的结果放到prompt中,就能使得模型对当前和先前的任务完成度有更好的反思能力,从而提升模型的问题解决能力。
Thought: …
Action: …
Observation: …
…(重复以上过程)
与人类一样,大型语言模型(LLM)在第一次尝试时并不总是能生成最佳输出。受到人类如何完善其书面文本的启发,Agent因此引入了Reflection反思过程,通过迭代反馈和完善来提高LLM的初始输出质量。主要思想是使用LLM生成一个初步输出;然后,同一个LLM为其输出提供反馈,并使用这个反馈进行迭代自我完善。Reflection本身不需要任何监督学习的训练数据、额外的训练或强化学习,而是使用单一的LLM作为生成器、完善者和反馈提供者。
一种反思的实现策略
Noah Shinn等人为Reflexion开发了一种模块化的表述方式,利用三个不同的模型:一个执行者(Actor),标记为Mₐ,用于生成文本和动作;一个评估模型(Evaluator model),表示为Mₑ,用来对Mₐ产生的输出进行评分(确认输出内容是否达标,以及是否需要继续迭代);以及一个自我反思模型(Self-Reflection model),标记为Mₛᵣ,它生成文字化加强提示以协助Actor进行自我提升(告诉Actor,针对上一轮生成的内容哪里需要改进、哪里有错误等具体的文字性描述)。其整体工作流程与算法如下图所示: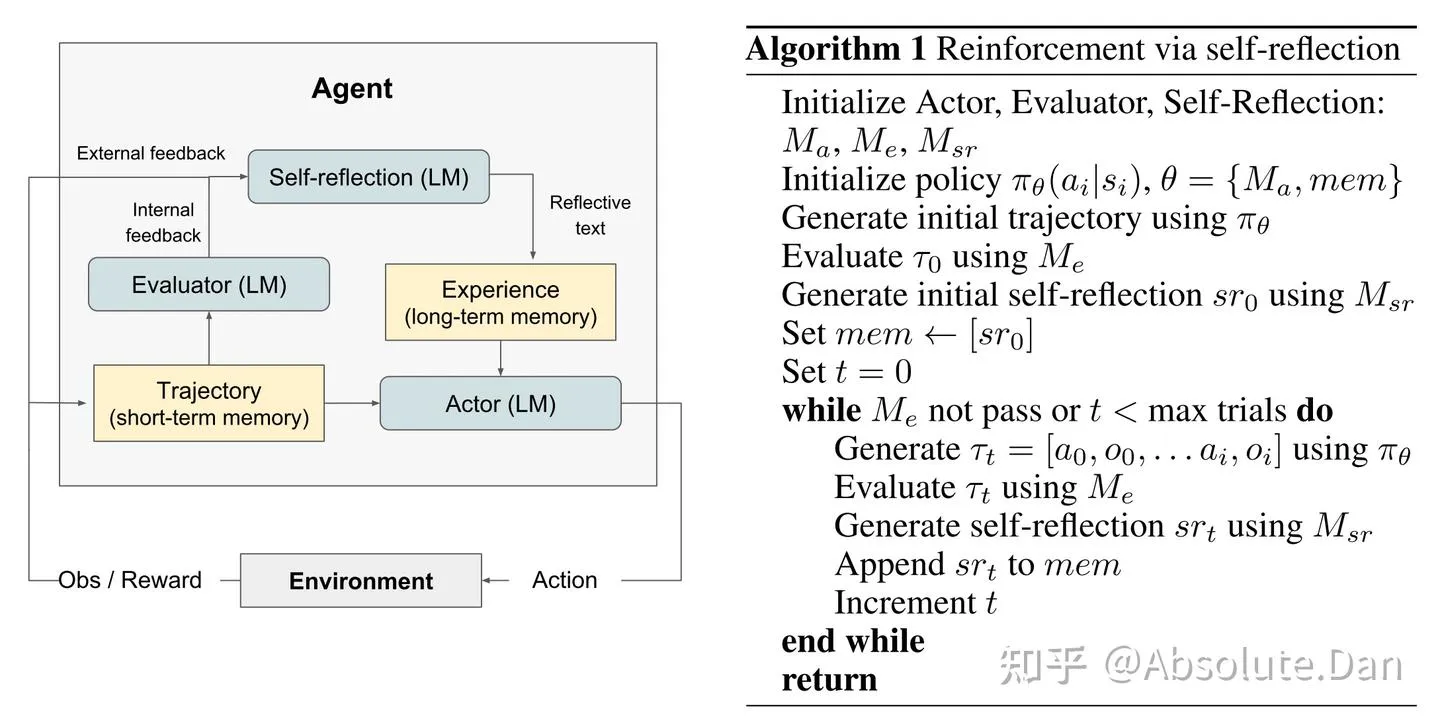
根据上图可以了解到Reflexion流程是一个自我迭代的优化过程。在第一轮中,执行者(Actor)与环境互动产生初始轨迹(内容生成)τ₀。随后,评估者(Evaluator)根据评估模型Mₑ对τ₀进行评分,得出分数r₀。完成第一轮后,为了将分数r₀转化为大型语言模型可以用来提高输出质量的反馈,自我反思模型Mₛᵣ(Self-Reflection model)分析数据集{τ₀, r₀},生成总结sr₀并将其存入记忆(mem)中。执行者、评估者和自我反思模型将继续进行多轮尝试,通过不断的循环直到评估者确认τₜ达到了预期的正确性(或迭代轮次t达到上限)。如文献中所述,记忆部分(mem)是Reflexion有效性的关键。在每一轮迭代结束后,srₜ被追加到mem,为下一轮的输入提供反馈。为了适应LLM的上下文token长度限制,在实际操作中,作者将mem的大小限制在一个最大经验值Ω内,这个值通常设置在1到3之间(即记录前几次的迭代反馈信息)。
通过实证研究表明,利用自我反思,类似Reflexion这种具备Reflection能力的Agent显著优于目前广泛使用的决策方法。最重要的是这种反馈反思方法不需要额外的训练、不需要更高级的LLM,而是使用单一的LLM来扮演不同的角色,即作为生成器、完善者和反馈提供者。
2. 评估
动态评测:实际使用反馈
静态评测:使用固定数据集评估模型的性能指标(大模型自动评估/人为评估)
文本和对话方面的能力:理解能力、对话内容的可行度、回答的风格
知识方面的能力:准确性、相关性
技能:工具的类别和使用、上下文长度
个性和认知的特征
安全性
指标:
基准评测:准确率、召回率
效率测试:吞吐量、延迟、token使用量
安全性测试

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)