3.3 Decoder-Only PLM
datawhale ai 共学。
第三章 预训练语言模型 datawhale ai 共学
3.3 Decoder-Only PLM
3 . 3 Decoder-Only PLM —— LLM 现实形态
为什么单用 Decoder?
掩码式 MLM 的理解能力与 自回归 CLM 的生成能力,二选一时——对于期望“问即答”“随写随算”的应用,时间因果一致的自回归更符合推理流程,也最易扩张到超长上下文和多轮交互。因此,大模型时代几乎清一色采用 Decoder-Only。
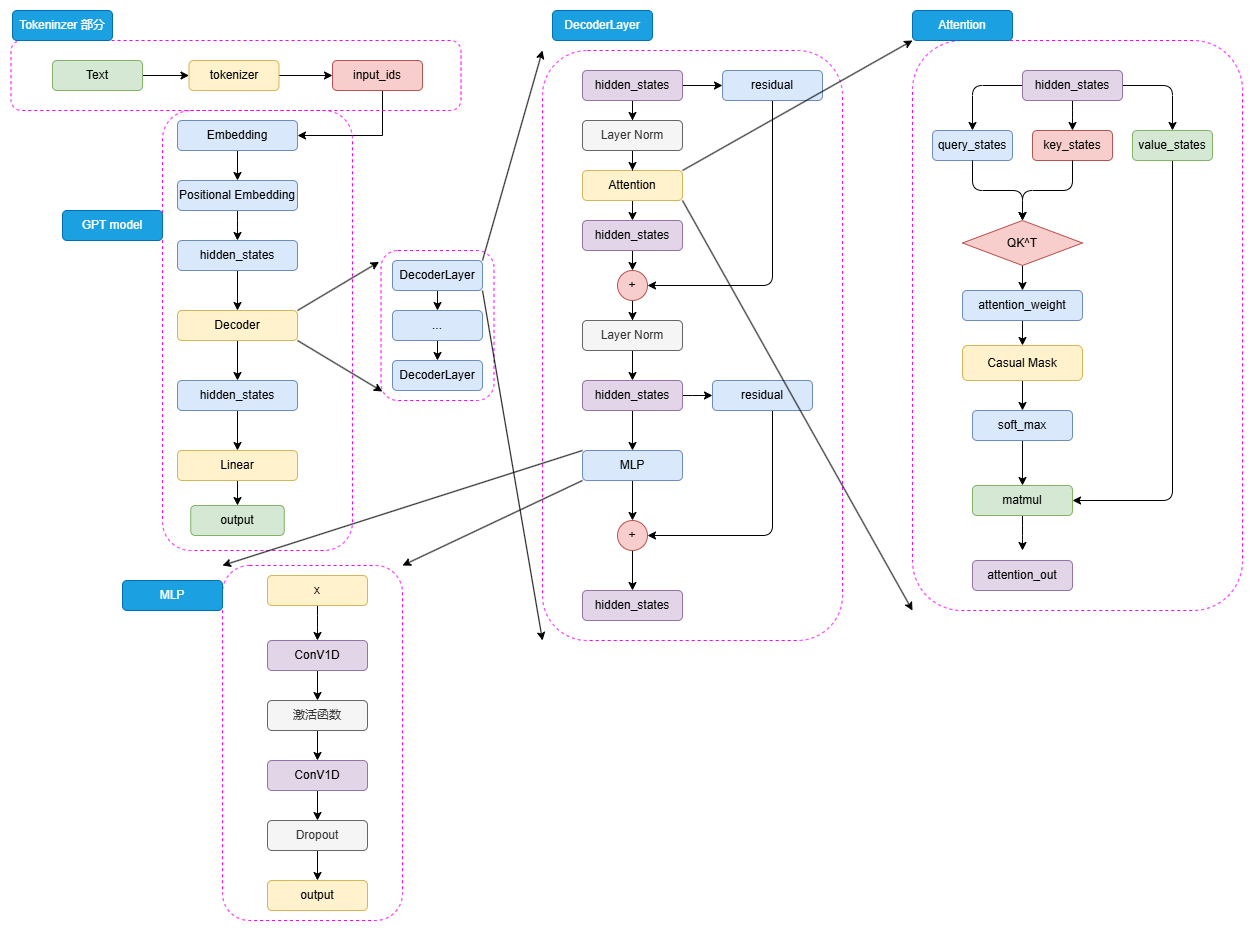
3 . 3 . 1 共通结构模板 GPT → LLaMA → GLM
| 组件 | 设计要点 | 理解 |
|---|---|---|
| Tokenizer |
BPE/RomanBPE → 更大词表(128 K); 重排高频 token |
词表越大,上下文等效 token 数越少,GPU 记忆占用直接降低 |
| Embedding | 权重与 LM-Head 同权共享(tie-weight) |
减 1/2 参数; 生成质量不受损 |
| Positional Encoding | Sinusoidal → RoPE → NTK/Scaled RoPE |
旋转式 RoPE 本质是 加法→旋转矩阵,无限外推更稳定 |
| Decoder Block × N | Pre-Norm + Masked Self-Attn(GQA/MQA) + SwiGLU-MLP + 残差 |
Pre-Norm 确保梯度; GQA=头分簇,推理显存线性减半 |
| 全部因果 Mask | Aij = - |
训练与推理保持完全对齐 |
| 优化 trick |
FP16 → BF16,ZeRO3,NVTP; Sliding KV-cache |
“算得起+推得动” 首要可落地条件 |
3 . 3 . 2 GPT 系列(架构基线)
| 版本 | Block/Hidden | 参量 | 训练数据 | 突破 |
|---|---|---|---|---|
| GPT-1 (2018) | 12 / 768 | 0.12 B | Books 5 GB | 首次提出 Generative-Pre-Training + Task-specific Fine-Tuning |
| GPT-2 (2019) | 48 / 1600 | 1.5 B | WebText 40 GB |
Zero-shot prompt 能力显性化; 安全争议 |
| GPT-3 (2020) | 96 / 12 288 | 175 B | 570 GB 清洗语料 |
Few-shot / In-Context Learning 涌现; LLM 时代 |
-
Block 细节:Pre-Norm + Masked-Self-Attn,MLP 用 1D Conv(ℓ=1)。
-
预任务 CLM:严格自回归;天然对齐推理阶段
-
Decoder-Only 堆叠:每层=Pre-Norm → Masked Self-Attn → MLP(SwiGLU/Conv1D) → Residual
-
严格因果 Mask:只看历史 token,天然对齐生成推理流程
-
位置编码:从绝对 Sinusoidal → Rope(GPT-J/-Neo)→ NTK/Scaled Rope(GPT-4o)
-
“规模线性外推”:OpenAI 实验表明,损失近似随 log参数/数据线性下降 → 直接堆算力最稳
GPT 系列用“规模线性外推”证明了 CLM 的潜能——
当参数 ≫ 语义熵时,生成模型的理解能力自然涌现
当参数量跨过 100 B、token 数跨过 1 T 后,损失随 log(规模) 的线性下降曲线突然转好,由此出现推理、数学、编排等涌现能力。GPT-3 之后,“加宽、加深、加数据”成为产业最朴素但最有效的路线。
3 . 3 . 3 LLaMA 系列(开源基准)
| 版本 | 规模 | 训练 token | 长度 | 关键创新 | |
|---|---|---|---|---|---|
| LLaMA-1 (2023 Q1) | 7–65 B | 1 T | 2 K | SwiGLU + RMSNorm |
LoRA 微调 24 G 显存即可跑 社区友好,轻量开源起点 |
| LLaMA-2 (2023 Q3) | 7–70 B | 2 T | 4 K | GQA,改进 Rope |
商用友好 license 国产派生模型母体 |
| LLaMA-3 (2024 Q2) | 8 B / 70 B | 15 T | 8 K |
128 K BPE;Scaled RoPE; 长上下文调制 |
8 B 版已追平 13 B~34 B 参数效率惊人 对标 GPT-4 的开源路线图 |
工程亮点
-
Grouped-Query Attention:只给少数 Query 分完整 K/V,显存/速度对大 batch 友好
-
持续开源:配套推理、量化、QLoRA、RAG Pipeline,一站式低门槛
-
LLaMA 关注 吞吐/延迟/易微调,成为学术-工业的“乐高件
为什么火?
-
吞吐 / 显存友好:GQA & Rope 让 8 K context 成本仍可控
-
授权清晰:研究 & 商用双许可,催生千余微调分支
-
社区生态:从 LoRA、QLoRA 到 MoE、Agent 工具链的事实标准
3 . 3 . 4 GLM & ChatGLM(中文路线)
早期 GLM 预任务(“先删一块再自回归”)意在统一理解+生成,但在算力面前被纯 CLM 碾压,后续迭代回到主流架构
中文社区的优势在 人力指令对齐 + 开源热情,小体量也能给出良好体验
| 代际 | 体量 | 预任务 | 架构差异 | |
|---|---|---|---|---|
| GLM (2021) | 110 M–515 M | Span-MLM+CLM (双向+单向) | Post-Norm;LM-Head 单线性 | 理论优雅,实践落后于纯 CLM |
| ChatGLM-6B (2023 03) | 6 B | CLM + SFT + RLHF | MQA + Rotary | 首个可桌面推理中文对话 LLM |
| ChatGLM-2/3 | 6 B | 加长 32 K,工具调用 | Λ Rope,函数执行 | 中文微调数据精细,QA/逻辑显著提升 |
| GLM-4-9B (2024 06) | 9 B | 同 GLM-4 | 128 K Rope,解码器门控 MLP | 9 B 体量打平 34–70 B,参数效率大幅跃迁 |
3 . 3 . 5 Decoder-Only 小结
| 维度 | 现状 | 实战 |
|---|---|---|
| 训练目标 |
统一使用 Causal LM; 大数据 + 长 context |
语料 ≧ 10 T、参数 ≧ 100 B 时出现跨任务涌现 |
| 结构演进 |
Pre-Norm → RMSNorm; 绝对位置 → Rope/NTK; QKV 收敛到 GQA/MQA |
8 K 以上上下文建议 Rope; 消费级推理用 GQA |
| 能力 | 基座预训练 ⟶ 指令微调 (SFT) ⟶ RLHF / DPO ⟶ 工具调用 | 中文场景:保留千条高质量指令 ≫ 万条机翻指令 |
| 应用 | Zero-shot / Few-shot / RAG / Agent | 先检索再生成(RAG)可大幅减轻 hallucination |
| 挑战 | 1) 长文本稳定性 2) 知识时效性 3) 计算/版权成本 | 层叠 KV-Cache、增量训练、版权过滤 pipeline |
Decoder-Only 本质=递归下一 token。规模够大,这一简单目标足以蕴含推理、检索、规划等复杂行为
Prompt Engineering 与 In-Context Learning :把问题拆解为模型能够自回归解答的“诉说过程”
面向落地,“RAG + 轻量微调 + 工具调用”正在成为真正可交付的 LLM Stack
小结
Encoder-Only (BERT) 可复用的「阅读理解」骨架Encoder-Decoder (T5) 统一任务表述
真正走进大众视野,Decoder-Only:写作、对话、代码、推理……几乎所有交互最终都是 生成连续 token。
数据足够、算力充沛, 单向自回归 + 合理工程 trick 是当前 LLM 的最短路径

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 30
30 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)