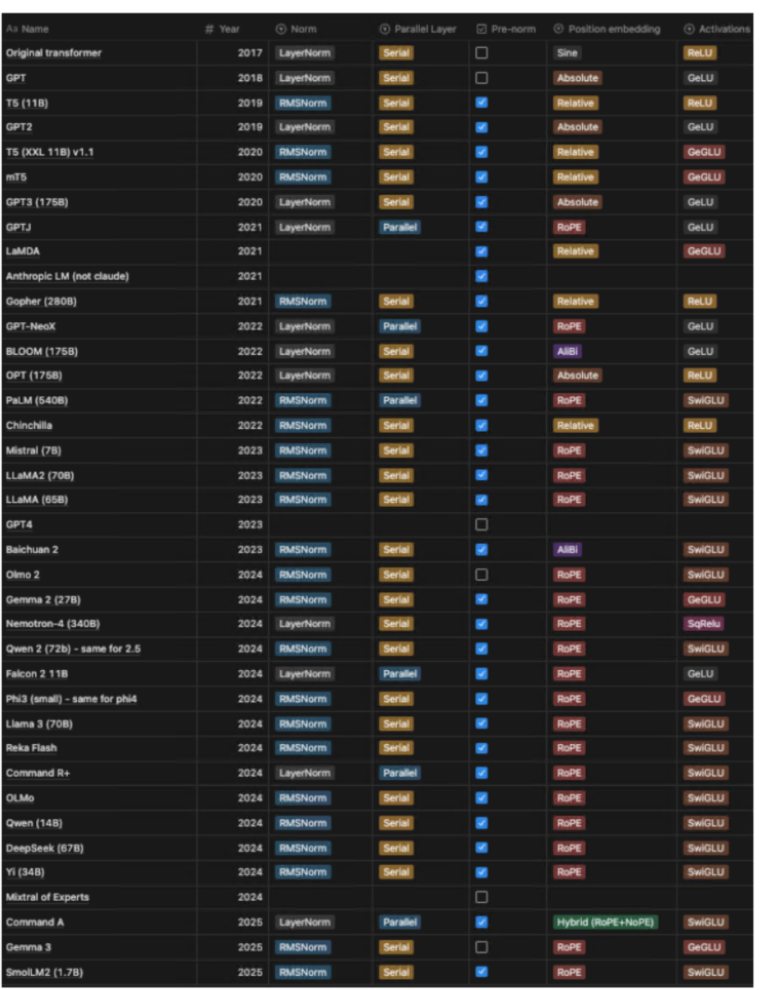
大模型设计
后训练阶段的数据如果超出了模型pre-training阶段达到的能力, 可能会让模型去做一些它根本做不到的事情。如果模型在预训练阶段没有接触到相关数据, 那模型可能就会迫使模型"一本正经的胡说八道"。但是在post-training阶段, 对于一些高质量得数据, 尽管出现多次, 但是我们仍然想要多次使用。MQA和GQA等, 对训练阶段影像不大, 但是对推理阶段模型的cost和behavior影响很
目录
1. pre-norm还是post-norm
一般我们把norm操作放到支路里, 让模型能够有shortcut从第一层直达最后一层, 这样能保持训练的稳定性。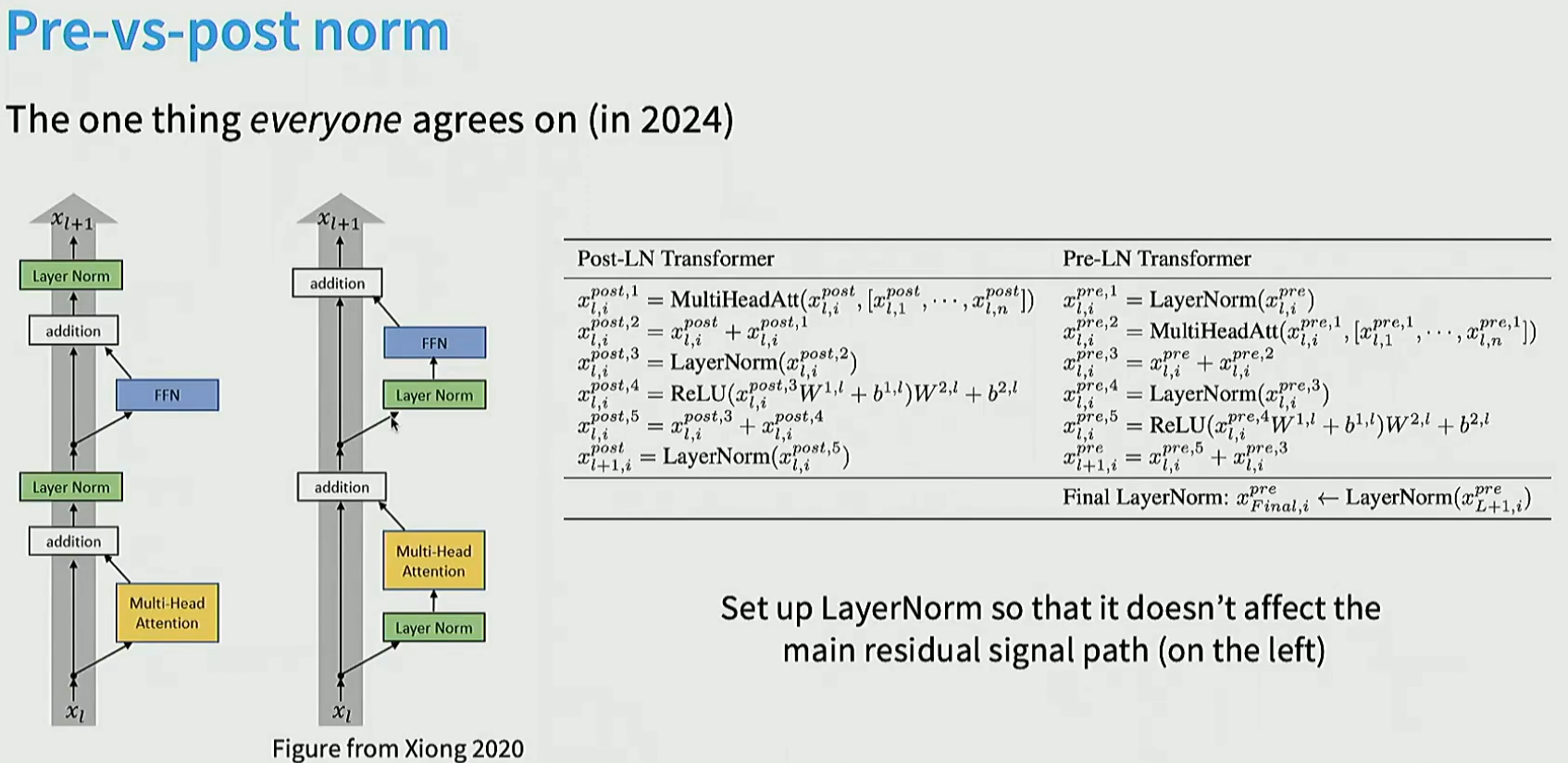

发现doublenorm效果更好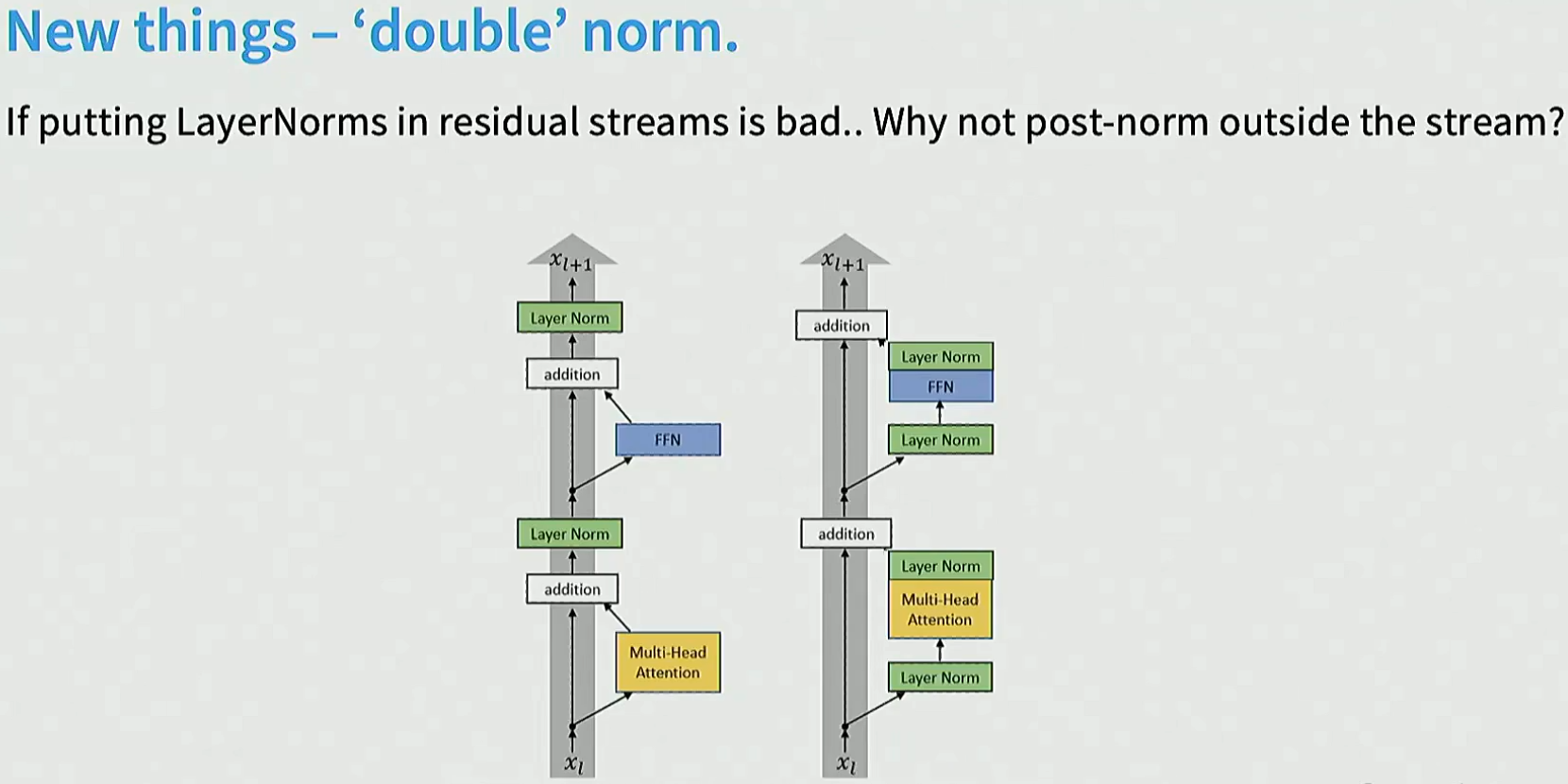
2. LayerNorm还是RMSNorm
实验发现减去均值没必要, 因此只需要除以方差, 然后用 γ \gamma γ缩放即可:
减均值虽然计算量不大, 但是对时间影响大。因为GPU很大一部分时间是消耗在数据从HBM运送到DRAM计算里面, 因此去掉均值部分能够优化时间:

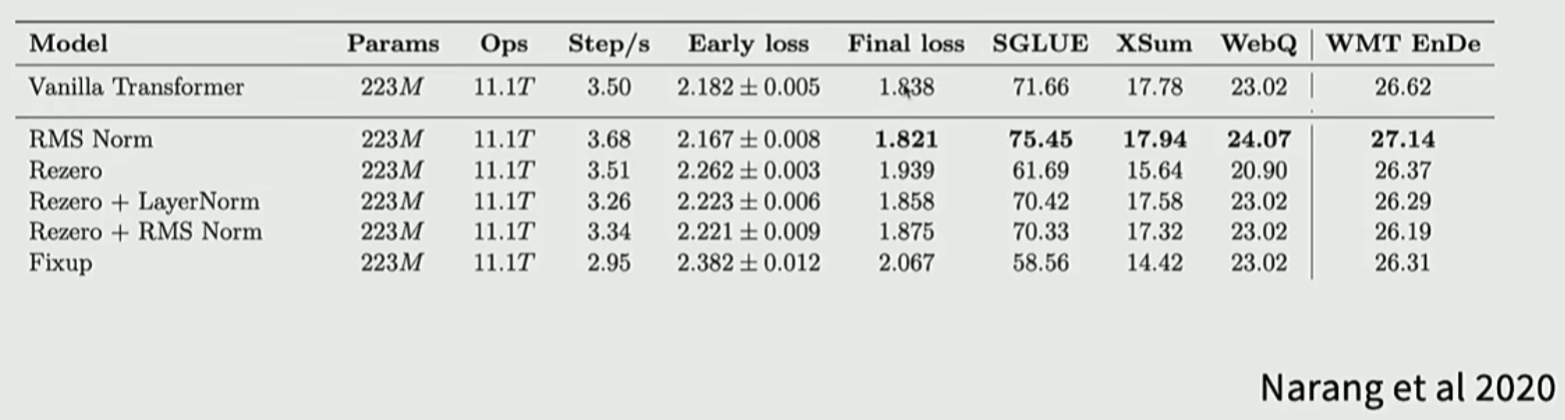
现代的Transformer基本都去掉了bias, 主要是内存, 时间效率和训练稳定性:

3. SwiGLU
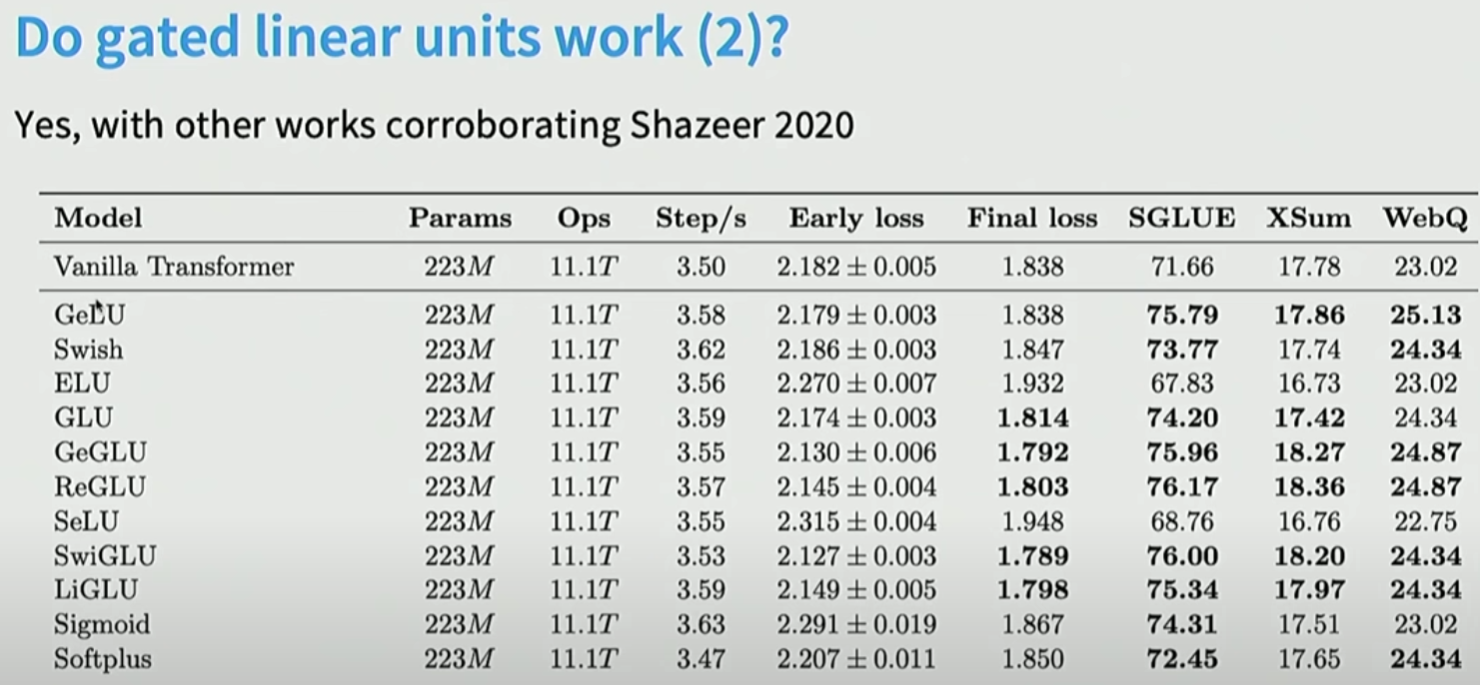
4. RoPE
我们希望不同的位置有相对位置不变性:
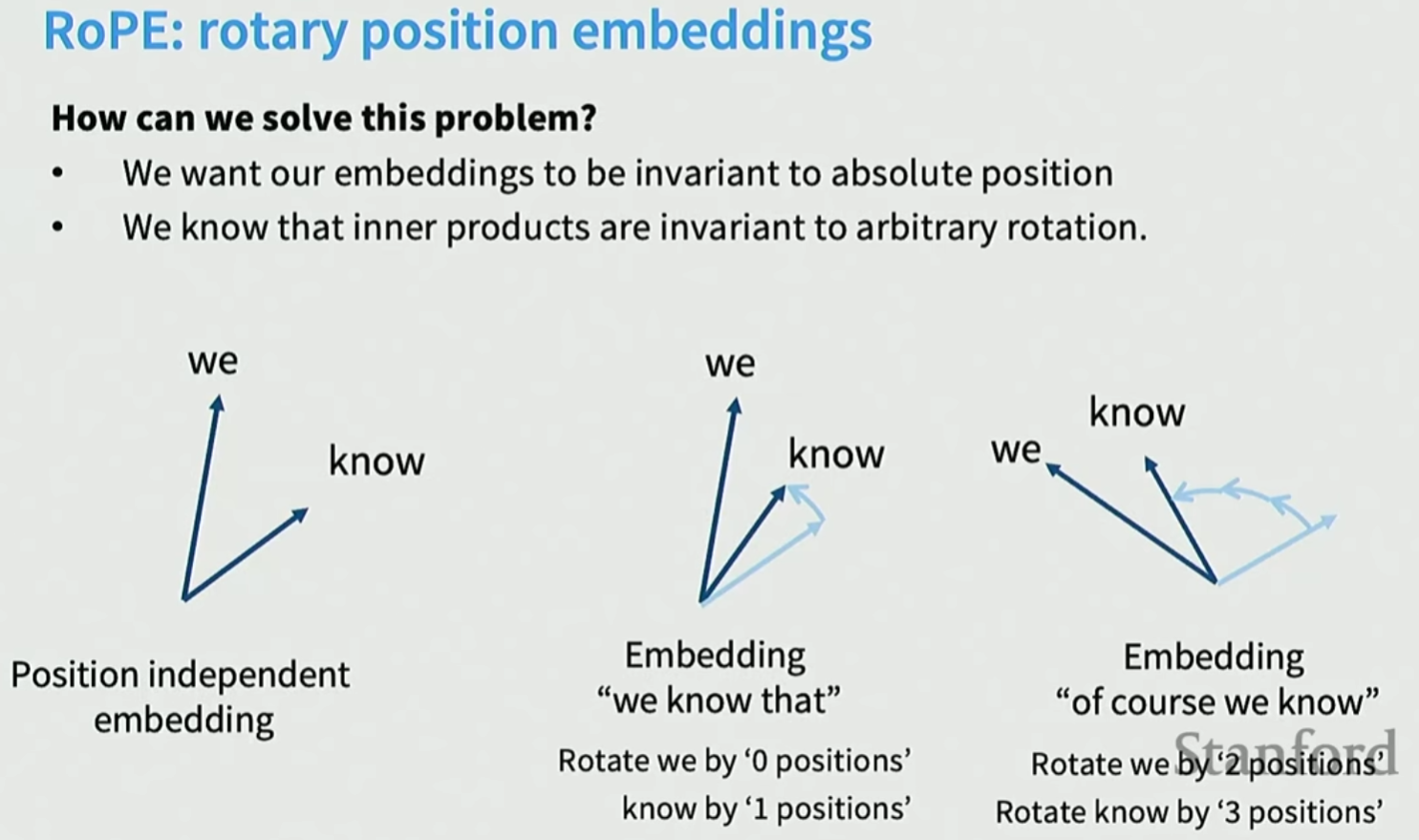
内积运算不受相对位置影响, 仅与位置间距有关。
二维空间的旋转非常直观, 但是高维空间怎么旋转?
最简单有效的办法就是将高维向量 d d d切分成若干个2维的, 每2个维度都以角度 θ \theta θ进行旋转。然后某些二维pair旋转更快, 另外一些维度旋转更慢。这样既能获取高频信息, 也能获取邻近信息, 以及遥远的低频信息。
这里的旋转位置编码是不可学习的, 是固定值。 θ \theta θ不同, 捕捉的频率也不同。实际运算时, 用旋转位置编码乘以key和query即可。


然后我们计算attention的时候:
Q ′ @ K ′ T = Q @ R q @ ( K @ R k ) T = Q @ ( R q @ R k T ) @ K T = Q @ R m − n @ T Q'@K'^T = Q@R_q @ (K@R_k)^T = Q@(R_q@R_k^T)@K^T=Q@R_{m-n}@T Q′@K′T=Q@Rq@(K@Rk)T=Q@(Rq@RkT)@KT=Q@Rm−n@T
这里的 θ \theta θ不决定旋转角度, 只是用于不同的频率(frequency)范围。
RoPE支持上下文窗口的扩展, 效果好, 成为标配。
def precompute_freqs_cis(dim: int, end: int, theta: float = 10000.0):
""" Precomputing the frequency tensor with complex exponentials
for the given sequence length and dimensions
"""
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))
t = torch.arange(end, device=freqs.device, dtype=torch.float32)
freqs = torch.outer(t, freqs).float()
freqs_cos = torch.cos(freqs)
freqs_sin = torch.sin(freqs)
return freqs_cos, freqs_sin
def reshape_for_broadcast(freqs_cis: torch.Tensor, x: torch.Tensor):
ndim = x.ndim
assert 0 <= 1 < ndim
assert freqs_cis.shape == (x.shape[1], x.shape[-1])
shape = [d if i == 1 or i == ndim - 1 else 1 for i, d in enumerate(x.shape)]
return freqs_cis.view(shape)
def apply_rotary_emb(
xq: torch.Tensor,
xk: torch.Tensor,
freqs_cos: torch.Tensor,
freqs_sin: torch.Tensor
) -> Tuple[torch.Tensor, torch.Tensor]:
""" Applying rotary position embeddings to input tensors using the given frequency tensor
"""
# reshape xq and xk to match the complex representation
xq_r, xq_i = xq.float().reshape(xq.shape[:-1] + (-1, 2)).unbind(-1)
xk_r, xk_i = xk.float().reshape(xk.shape[:-1] + (-1, 2)).unbind(-1)
# reshape freqs_cos and freqs_sin for broadcasting
freqs_cos = reshape_for_broadcast(freqs_cos, xq_r)
freqs_sin = reshape_for_broadcast(freqs_sin, xq_r)
# apply rotation using real numbers
xq_out_r = xq_r * freqs_cos - xq_i * freqs_sin
xq_out_i = xq_r * freqs_sin + xq_i * freqs_cos
xk_out_r = xk_r * freqs_cos - xk_i * freqs_sin
xk_out_i = xk_r * freqs_sin + xk_i * freqs_cos
# flatten last two dimensions
xq_out = torch.stack([xq_out_r, xq_out_i], dim=-1).flatten(3)
xk_out = torch.stack([xk_out_r, xk_out_i], dim=-1).flatten(3)
return xq_out.type_as(xq), xk_out.type_as(xk)
freqs_cos, freqs_sin = precompute_freqs_cis(params.dim // params.n_heads, params.max_seq_len, params.rope_theta)
self.register_buffer("freqs_cos", freqs_cos, persistent=False)
self.register_buffer("freqs_sin", freqs_sin, persistent=False)
freqs_cos = self.freqs_cos[:seqlen]
freqs_sin = self.freqs_sin[:seqlen]
xq, xk = apply_rotary_emb(xq, xk, freqs_cos, freqs_sin)
4. FFN层放大倍数
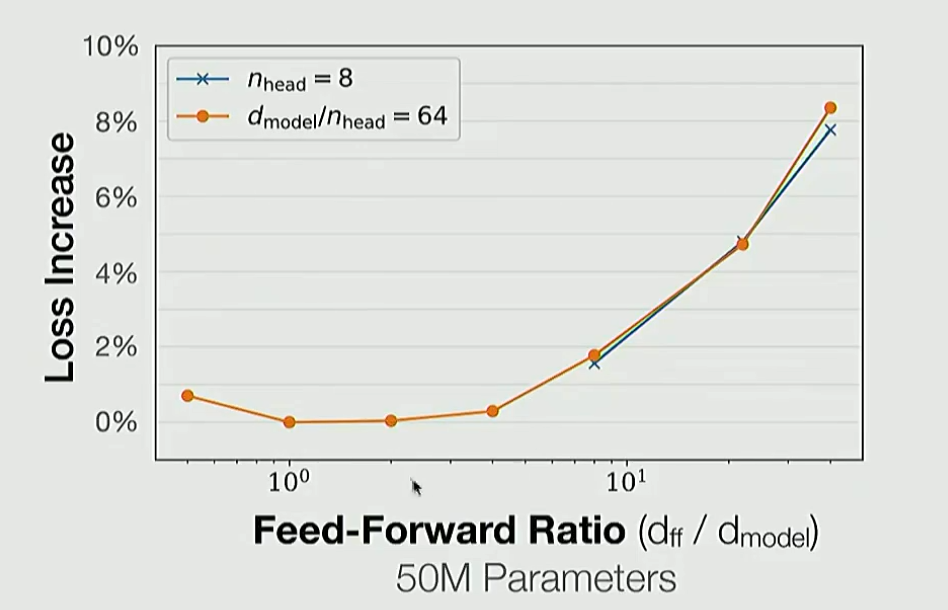
采用GLU可以设置为2.66
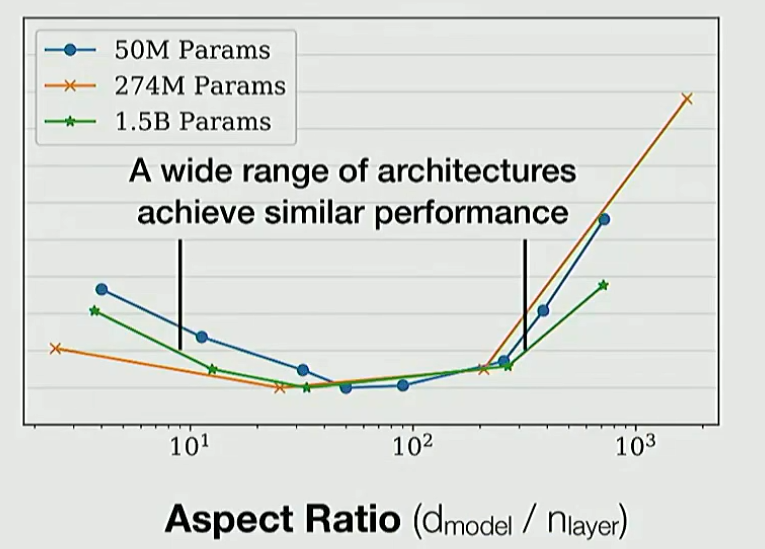
5. 网络层数和宽度设置

6. 词表大小
大的词表处理能力更强, 例如支持多语言。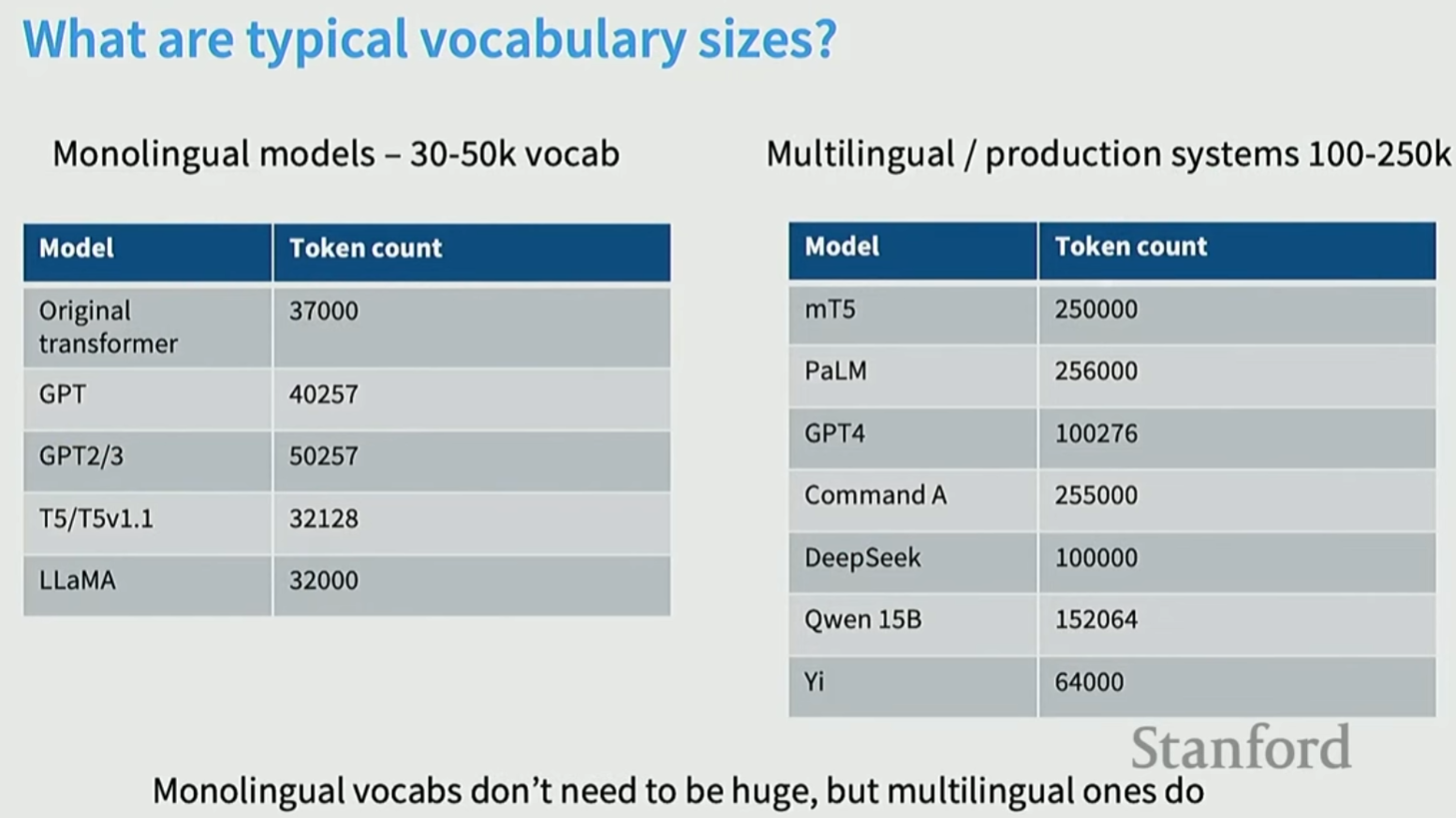
7. 正则化
预训练不需要正则化。因为训练数据远远大于参数量, 不会过拟合。
预训练只会走1个epoch, 因为数据量太大。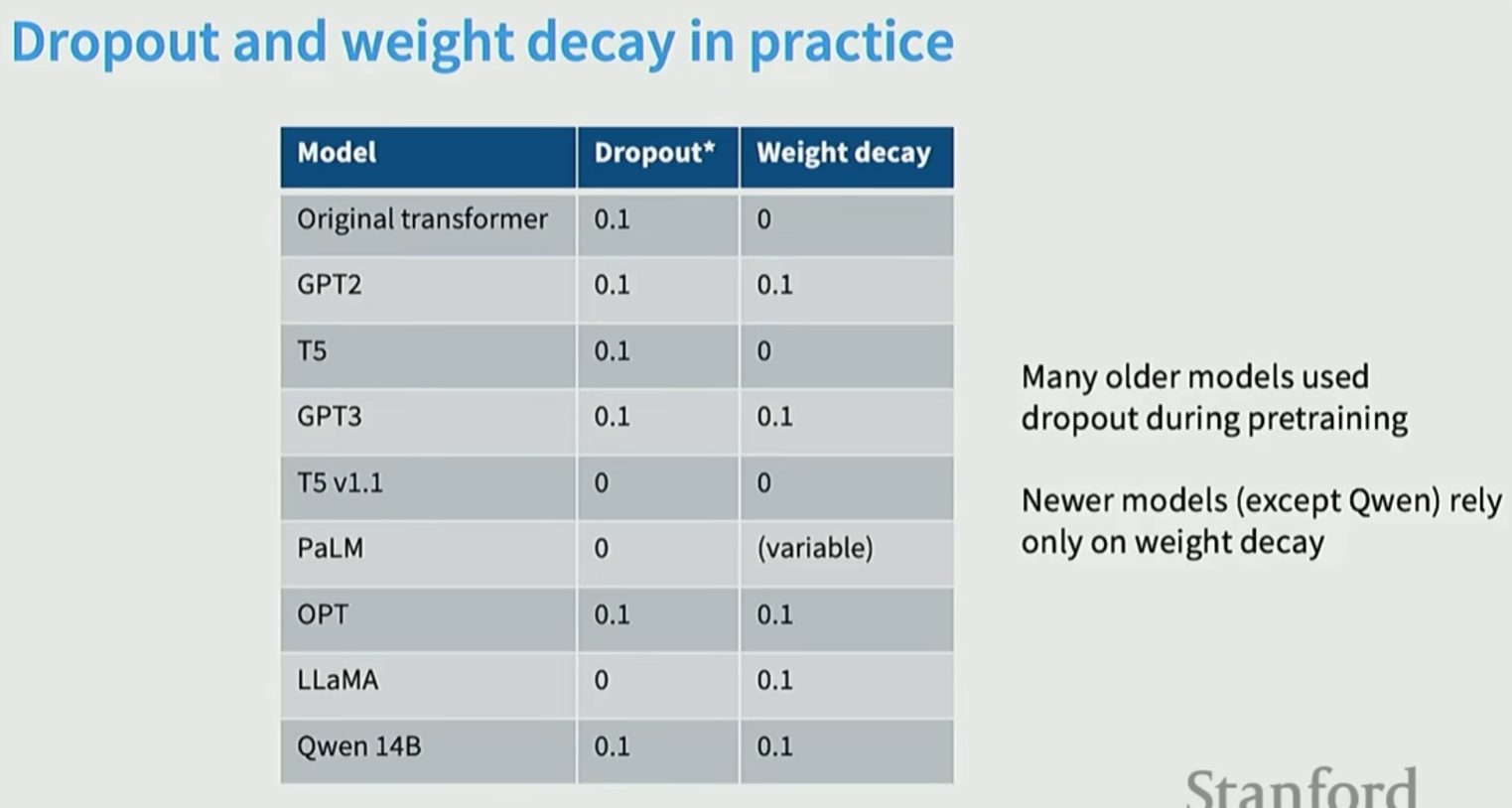
Dropout不太用了, 但是weight_decay (L2) 仍然在用。但是weight_decay不是在避免过拟合了, 而是通过优化训练损失来提升性能。在cosine_schedule的时候对learning_rate有影响。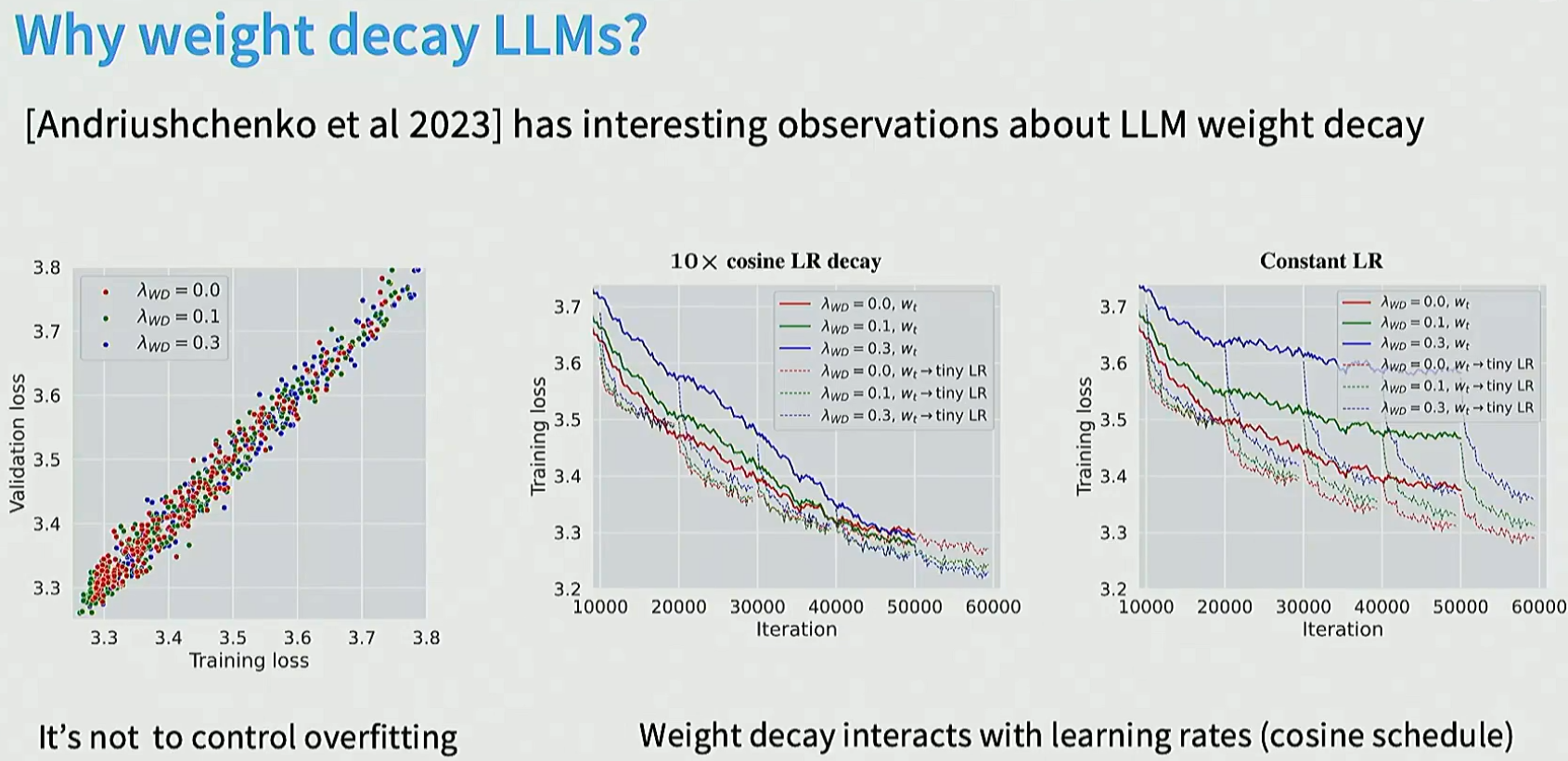
8. softcap与训练稳定性问题
Softmax里面因为有指数操作, 会导致训练不稳定的问题, 需要特别注意。
trick:

9. 注意力的变种
MQA和GQA等, 对训练阶段影像不大, 但是对推理阶段模型的cost和behavior影响很大。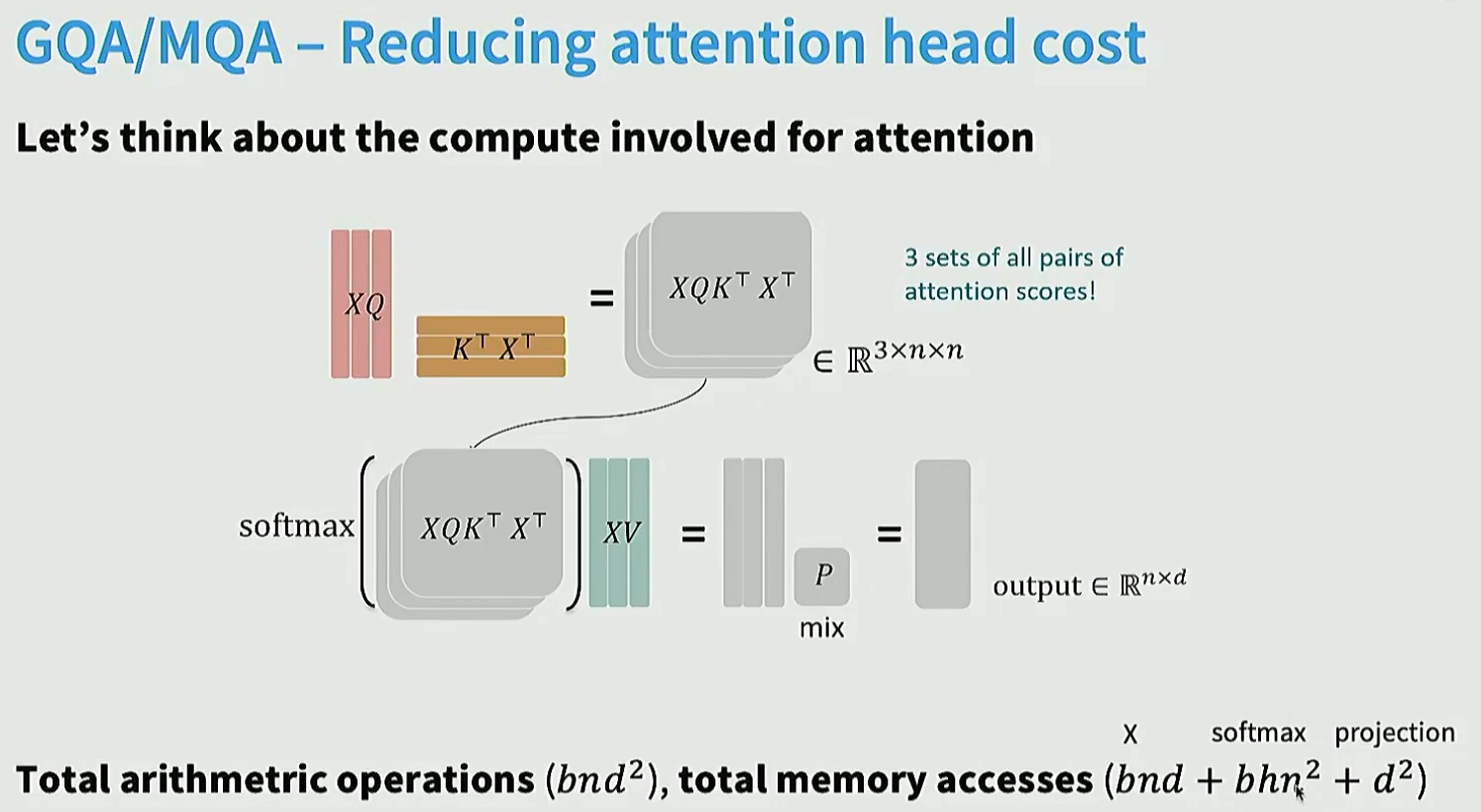
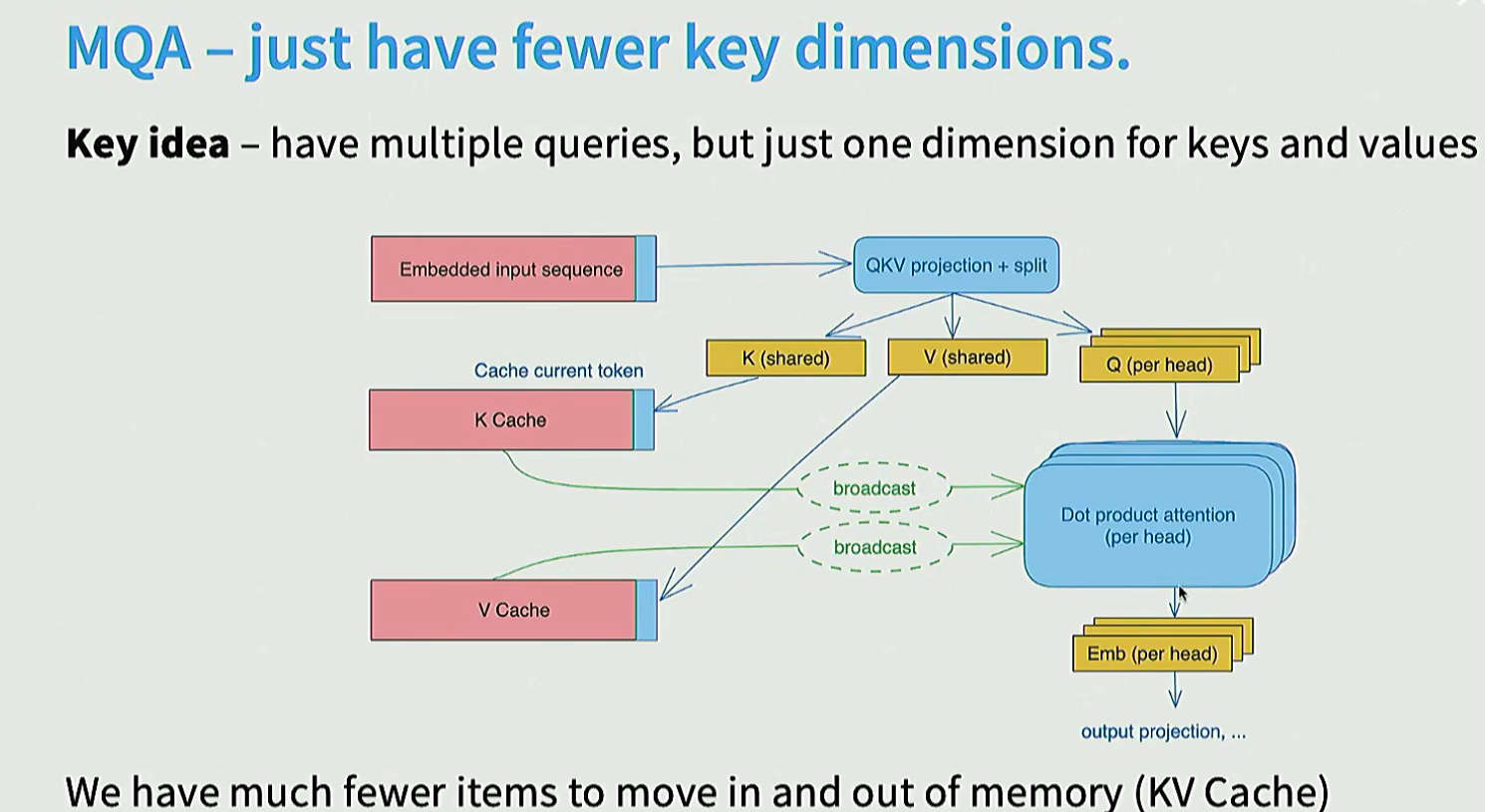
多个head之间共享key, value, 减少访存。
GQA在两者实现折中:
在这里插入图片描述
10. 超长上下文
采用sliding window: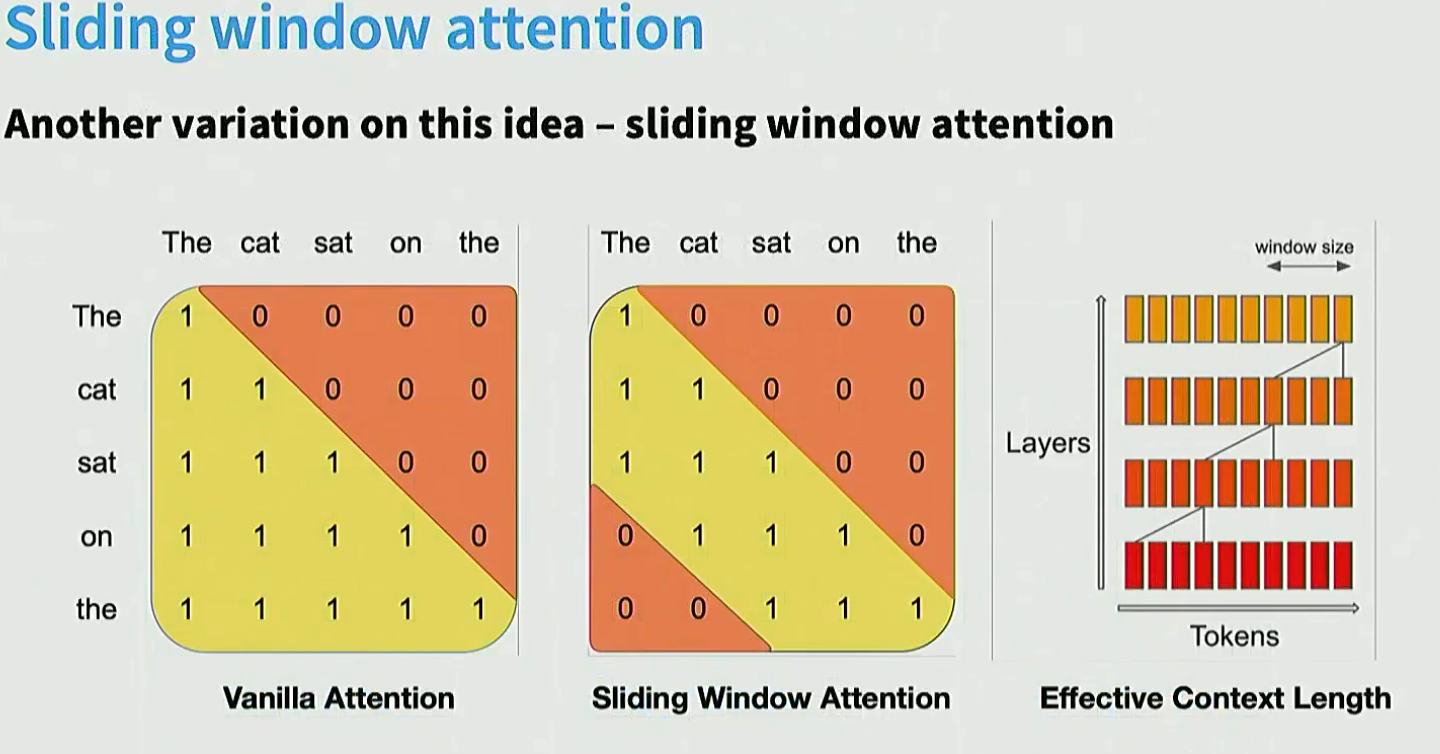
11. MOE (mixture of experts)
更多的参数, 但是不增加FLOPs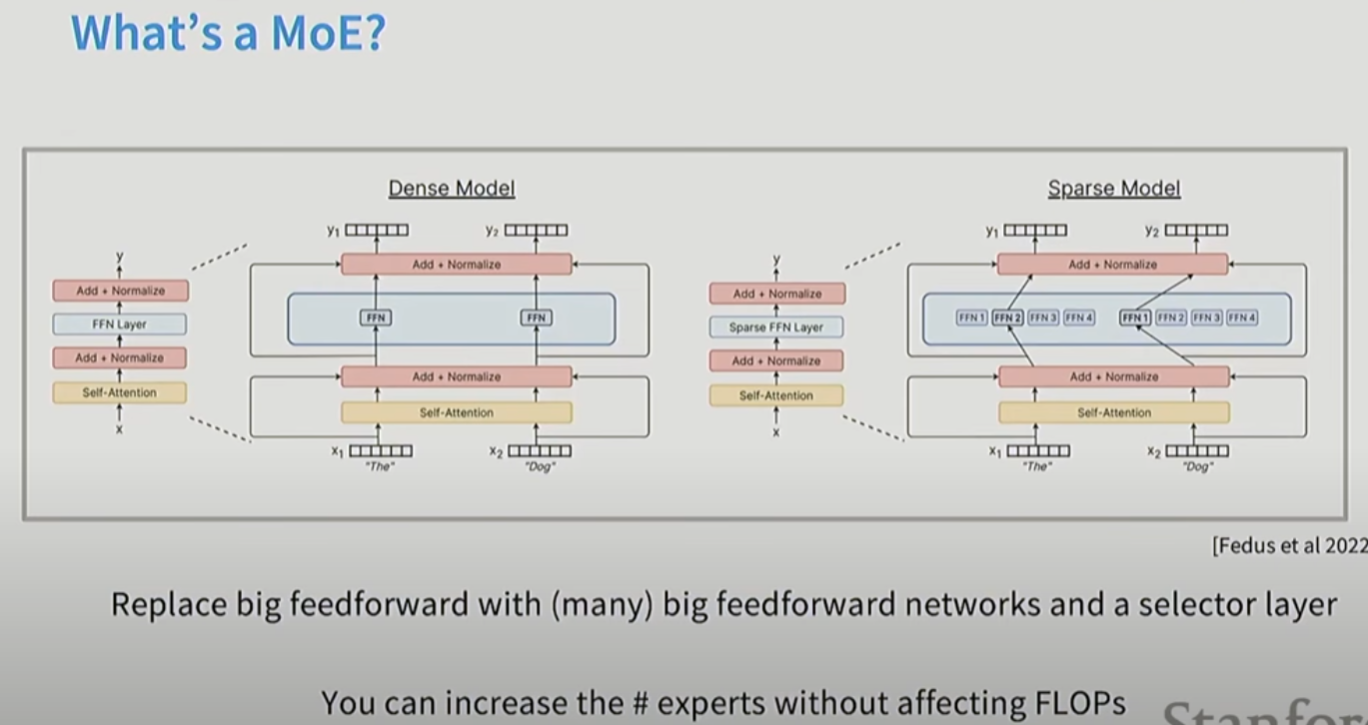
FLOPs相同的时候, 参数越多效果越好。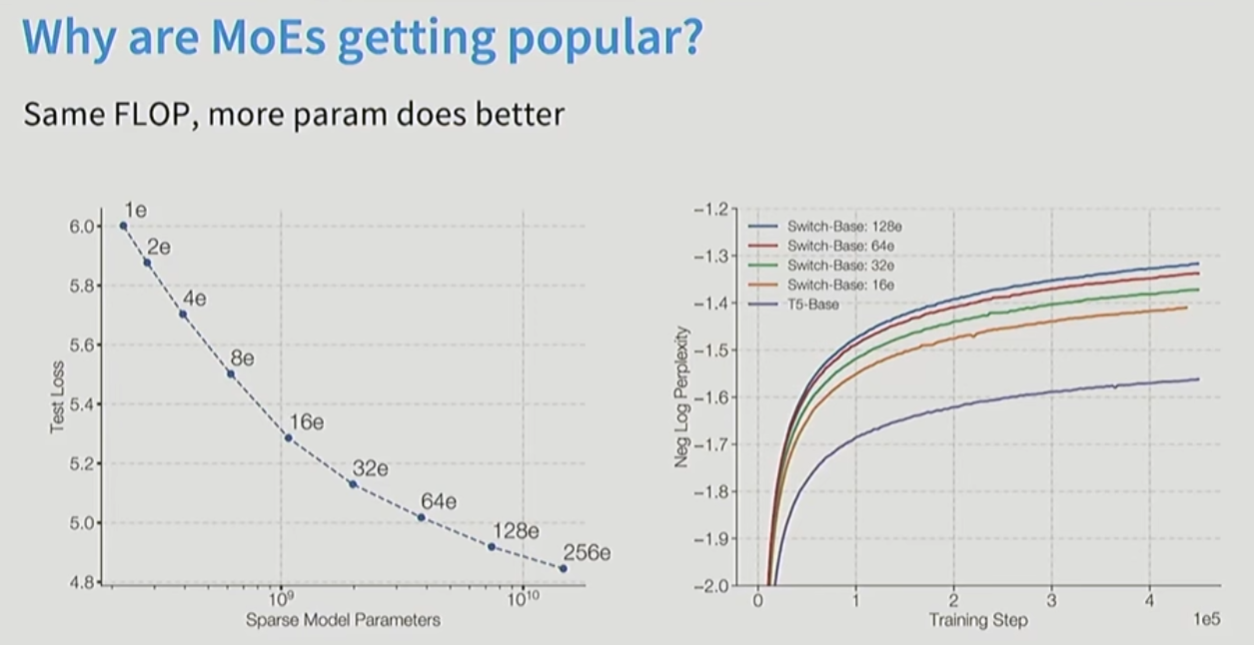
MOE训练起来更快:
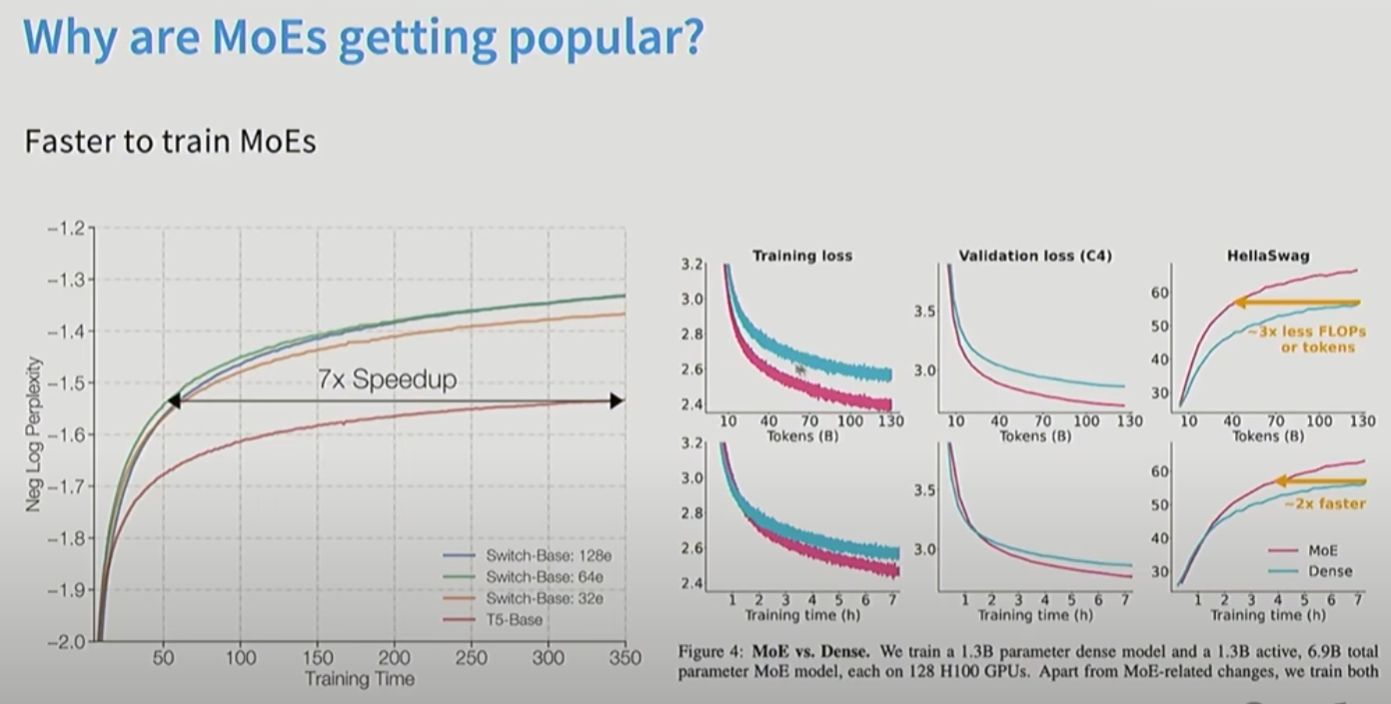
MOE中好的routing是关键。MOE让基础设置变得非常复杂。而且如果学习routing策略非常困难。早期的文章发现性价比不高。
routing策略不可导。早起用强化学习来决定routing策略, 但是计算量太高, 训练太不稳定。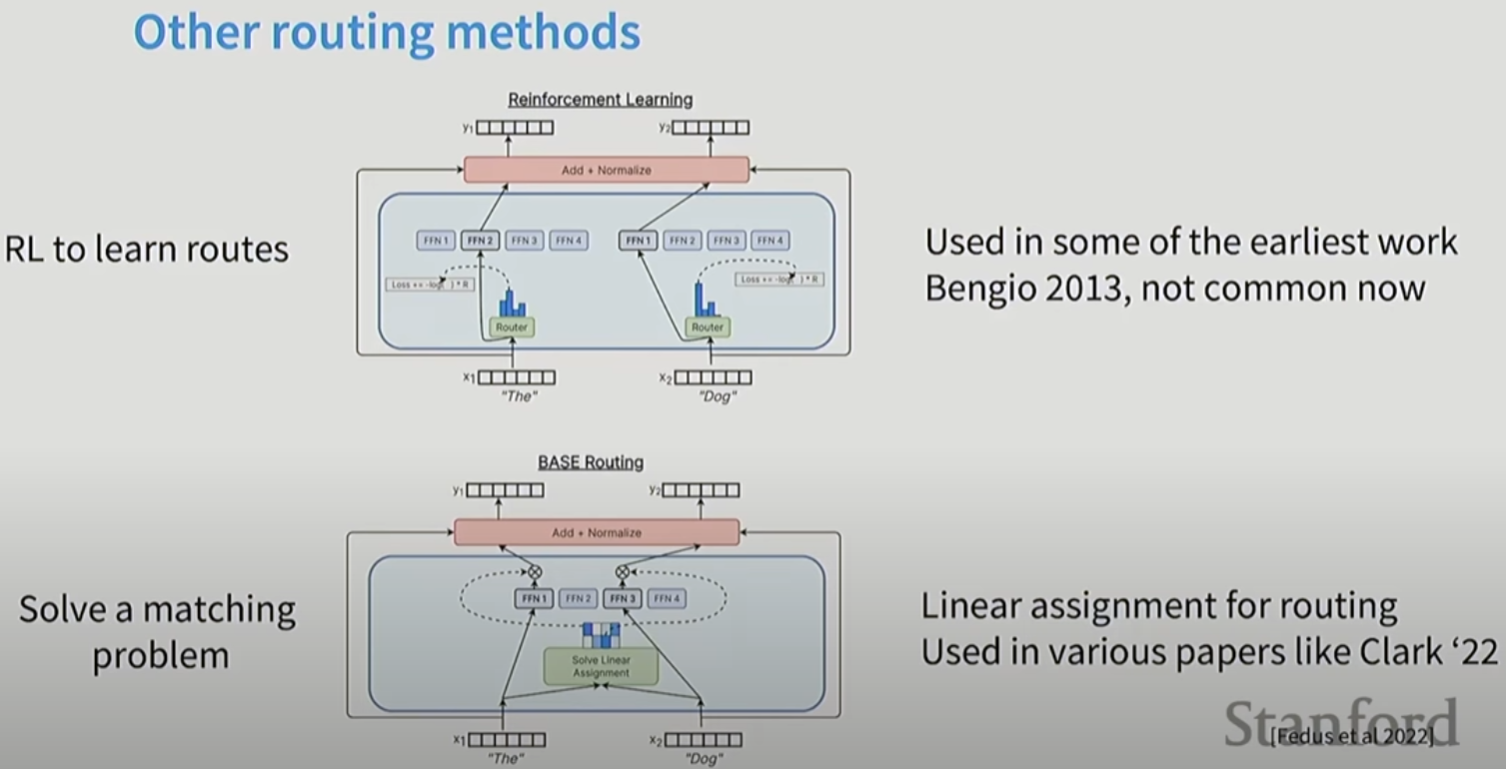

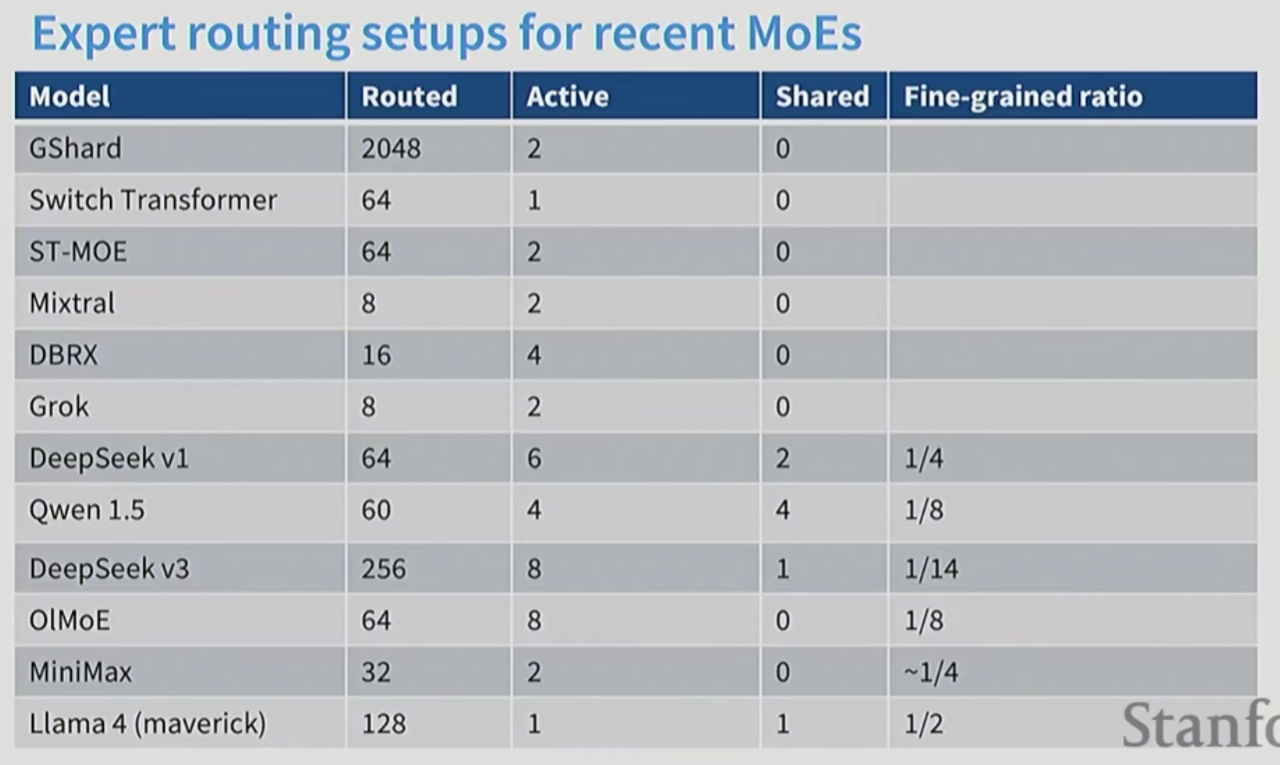
12. DeepSeek 的MOE
维度小一点, 但是MoE数量多一点更好。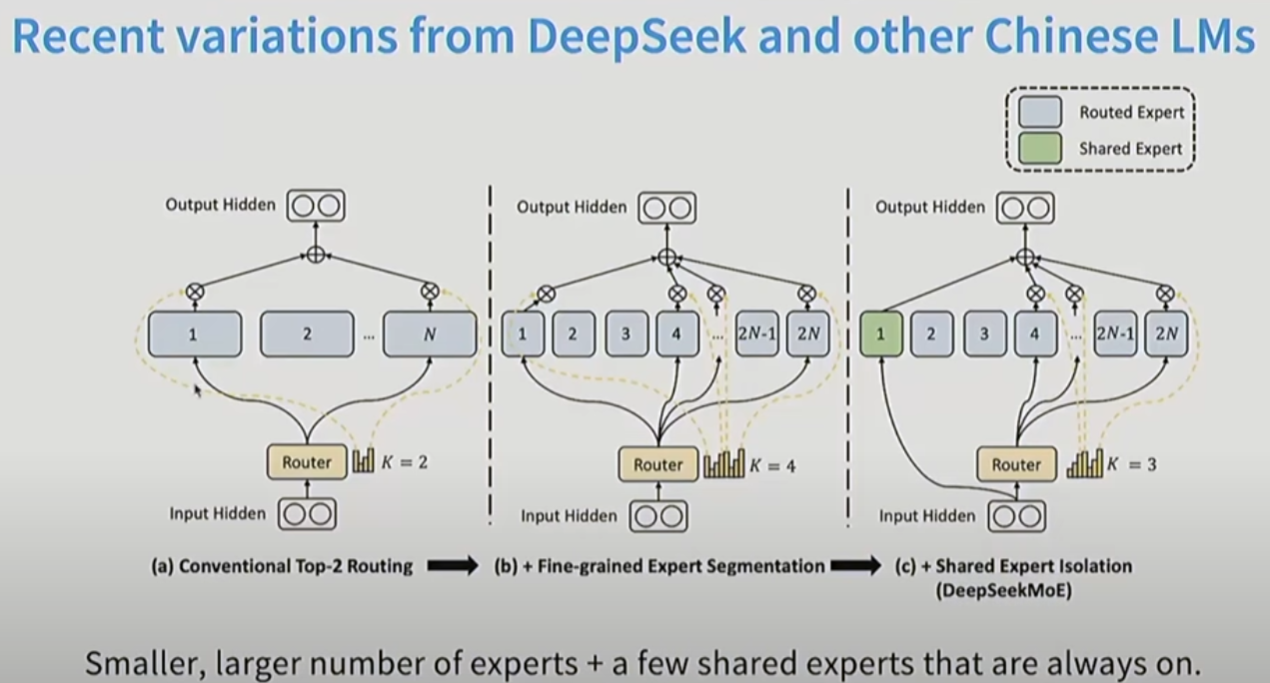
DeepSeek进一步添加了一个shared Expert.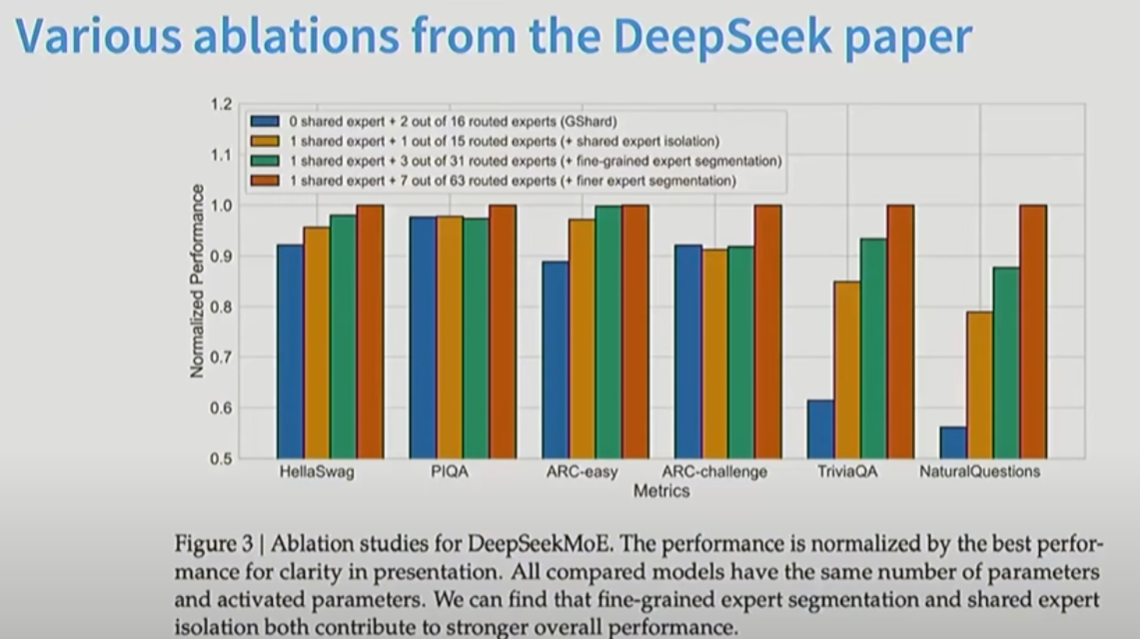

添加噪声扰动:
噪声扰动: 没有针对性, 效率低下。效果不好:
13. Expert的选择不均匀怎么办

其实就是对每个 e x p e r t i expert_i experti, 实际的token分配到的比例 f i f_i fi, 乘以总的概率 P i P_i Pi, 其中 f i f_i fi是离散得到的。
例如有5个token, 3个experts, 分配为:
token1 → [0.7, 0.2, 0.1]
token2 → [0.8, 0.1, 0.1]
token3 → [0.2, 0.6, 0.2]
token4 → [0.3, 0.3, 0.4]
token5 → [0.9, 0.05, 0.05]
则 l o s s 1 = 3 5 × 2.9 5 loss_1=\frac{3}{5} \times \frac{2.9}{5} loss1=53×52.9
l o s s 2 = 1 5 × 1.25 5 loss_2=\frac{1}{5} \times \frac{1.25}{5} loss2=51×51.25
l o s s 3 = 1 5 × 0.85 5 loss_3=\frac{1}{5} \times \frac{0.85}{5} loss3=51×50.85
总 l o s s = 0.432 loss=0.432 loss=0.432
加入都分配给1个expert:
token1 → [1.0, 0.0, 0.0]
token2 → [1.0, 0.0, 0.0]
token3 → [1.0, 0.0, 0.0]
token4 → [1.0, 0.0, 0.0]
token5 → [1.0, 0.0, 0.0]
总 l o s s = 5 5 = 1 loss=\frac{5}{5}=1 loss=55=1, 因此分配越均匀, loss越小。
这种loss就会压制expert1的概率:



就是more frequently used, stronger down-weighting.
DeepSeek进一步改进, 让不同
devices之间更加均衡:
另外MoE也能增加GPT模型的随机性, 让模型多样性更强。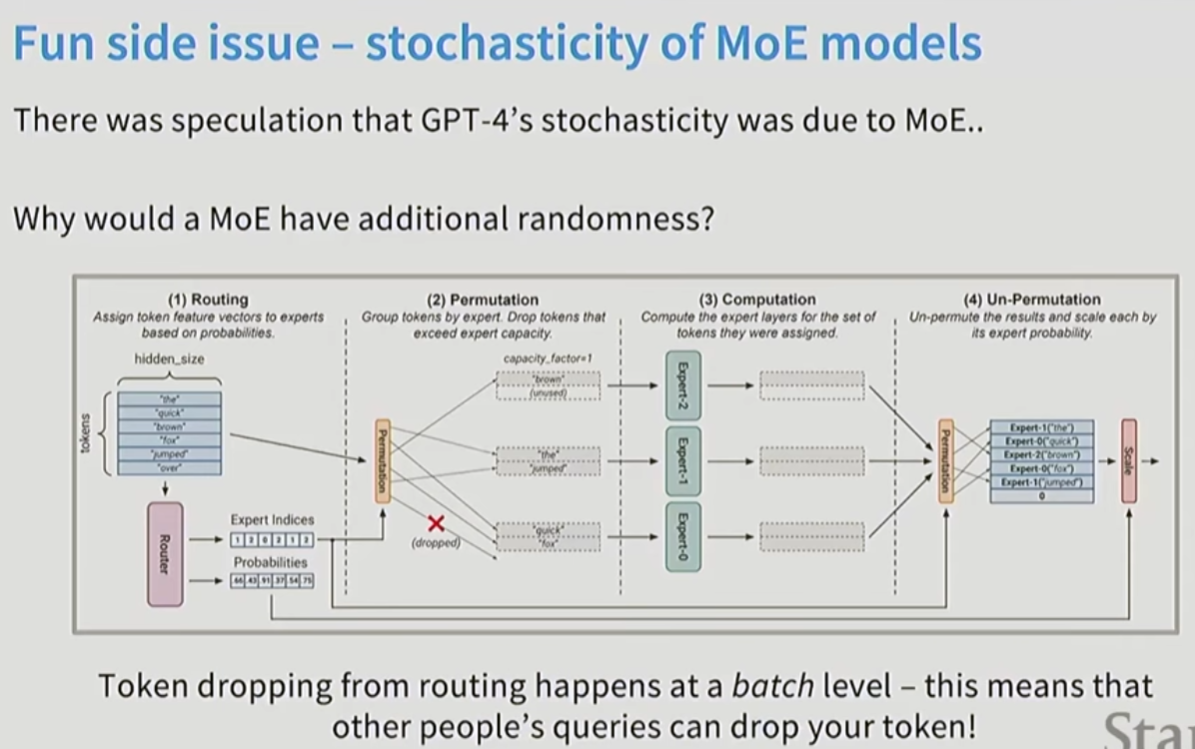
13.1 MoE初始化
用预训练好的Dense FFN+随机噪声初始化MoE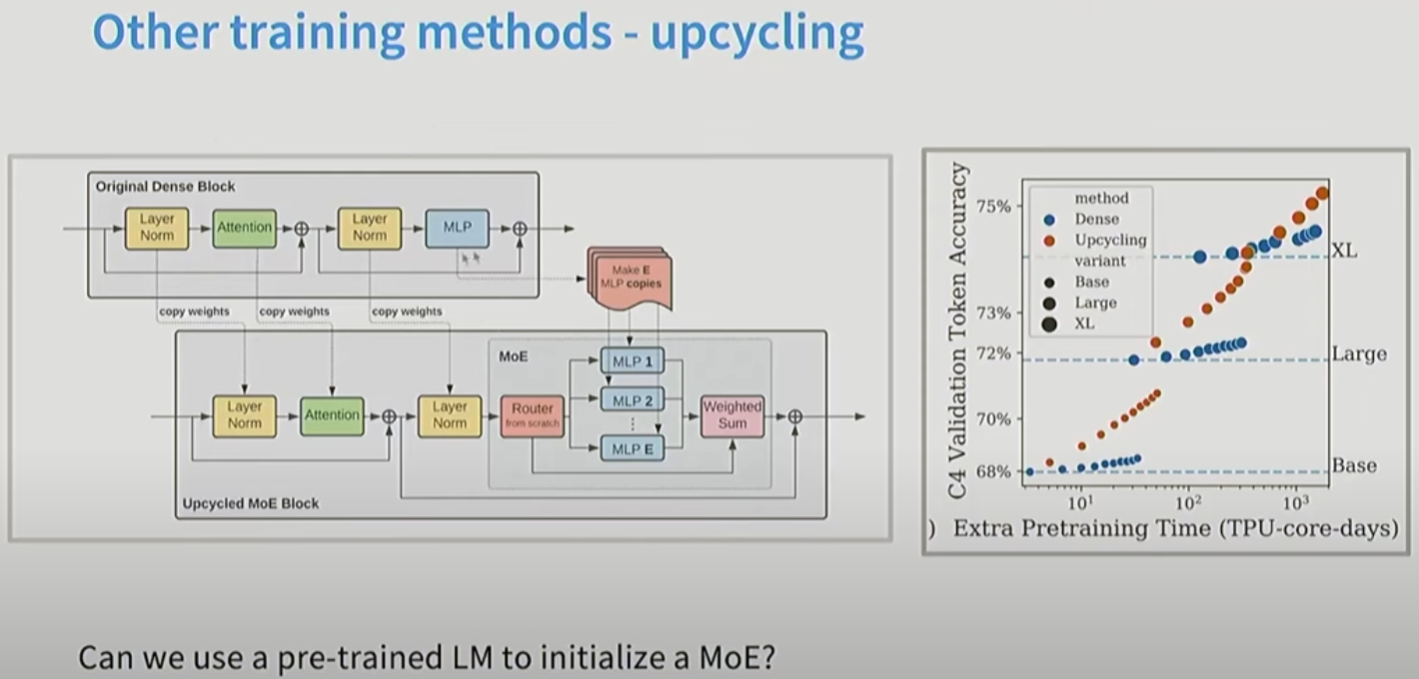
14. 数据处理
14.1 去重
去重更多的是在pretraining阶段, 例如使用Bloom或者minihash算法去重。
但是在post-training阶段, 对于一些高质量得数据, 尽管出现多次, 但是我们仍然想要多次使用。因此这种去重在post-training阶段不一定合理。
14.2 数据过滤
一般用N-gram, 然后训练分类器, 过滤掉低质量数据。
15 Post-training
GPT-3经过海量的互联网数据, 通过next token prediction训练之后, 其实没什么用。因为它无法遵循特定指令。因此后训练才是使得模型变得能遵循指令的有用系统的关键。
后训练是数据尤其重要的一环。因为你希望使用少量数据获得你希望的指令模型。如果有嘈杂的指令微调数据, 模型就会产生奇怪的行为。
后训练阶段, 我们需要去收集各种行为的数据。
14.1 FLAN数据集

14.2 Alpaca

14.3 OpenAssistant


15. 模型幻觉
后训练阶段的数据如果超出了模型pre-training阶段达到的能力, 可能会让模型去做一些它根本做不到的事情。如果模型在预训练阶段没有接触到相关数据, 那模型可能就会迫使模型"一本正经的胡说八道"。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)