LangChain缓冲记忆组件的使用与解析
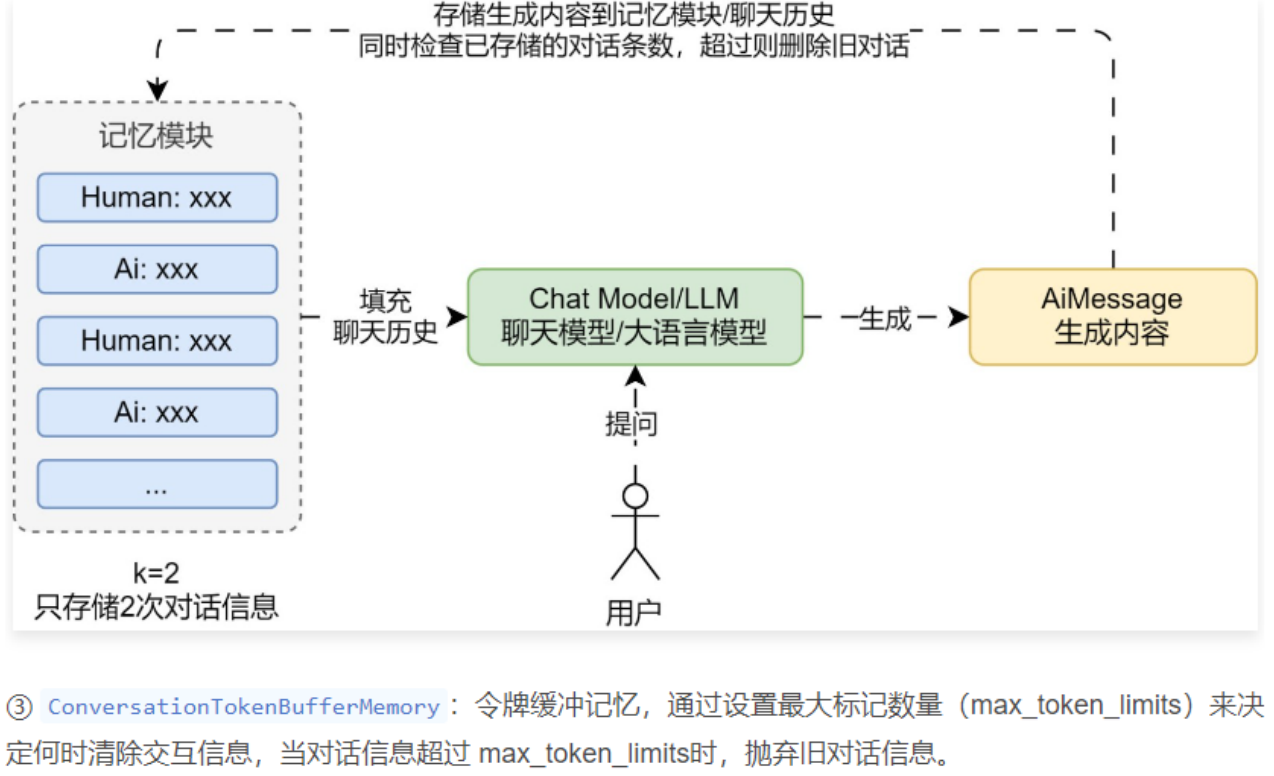
② ConversationBufferWindowMemory:缓冲窗口记忆,通过设定 k 值,只保留一定数量(2*k)的对话信息作为历史。① ConversationBufferMemory:缓冲记忆,最简单,最数据结构和提取算法不做任何处理,将所有对话信息全部存储作为记忆。使用 LangChain 实现一个案例,让 LLM 应用拥有 2 轮的对话记忆,超过 2 轮的记忆全部遗忘。("syst
01. 缓冲记忆组件的类型
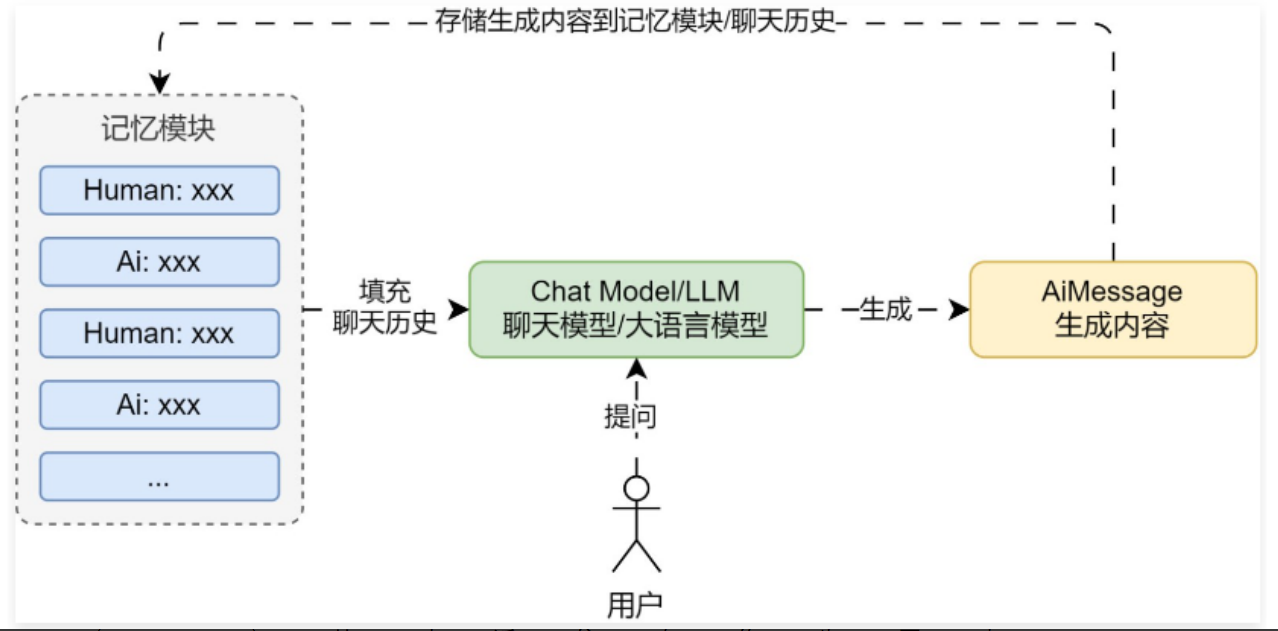
缓冲记忆组件是 LangChain 中最简单的记忆组件,绝大部分都不对数据结构和提取算法做任何处理,就是简单的原进原出,也是使用频率最高的记忆组件,在 LangChain 中封装了几种内置的缓冲记忆组件,涵盖:
① ConversationBufferMemory:缓冲记忆,最简单,最数据结构和提取算法不做任何处理,将所有对话信息全部存储作为记忆。
② ConversationBufferWindowMemory:缓冲窗口记忆,通过设定 k 值,只保留一定数量(2*k)的对话信息作为历史。
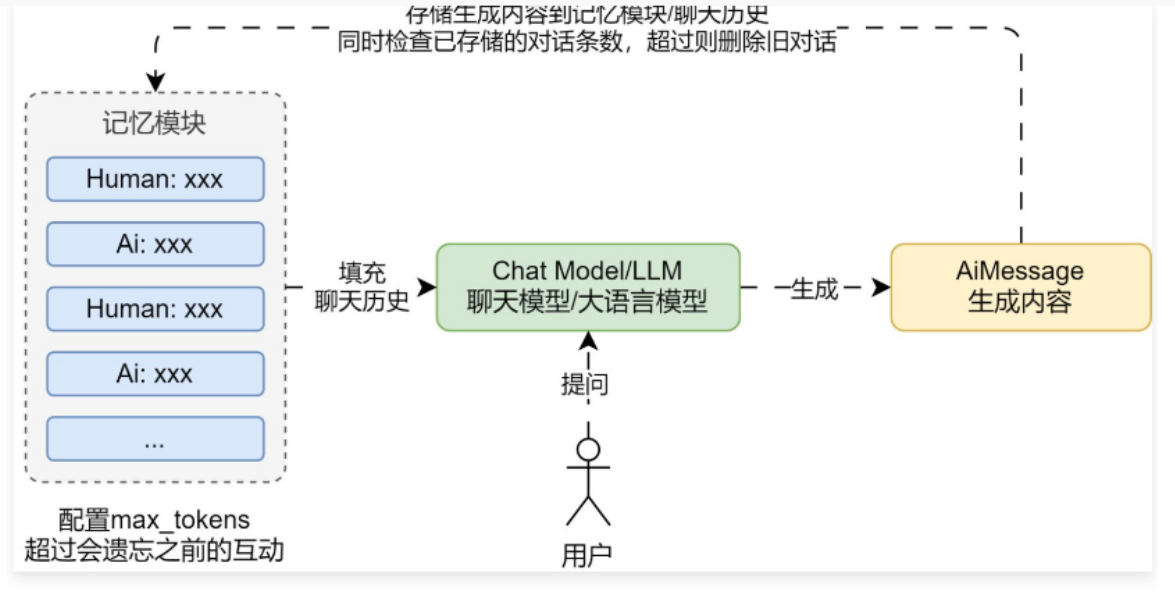
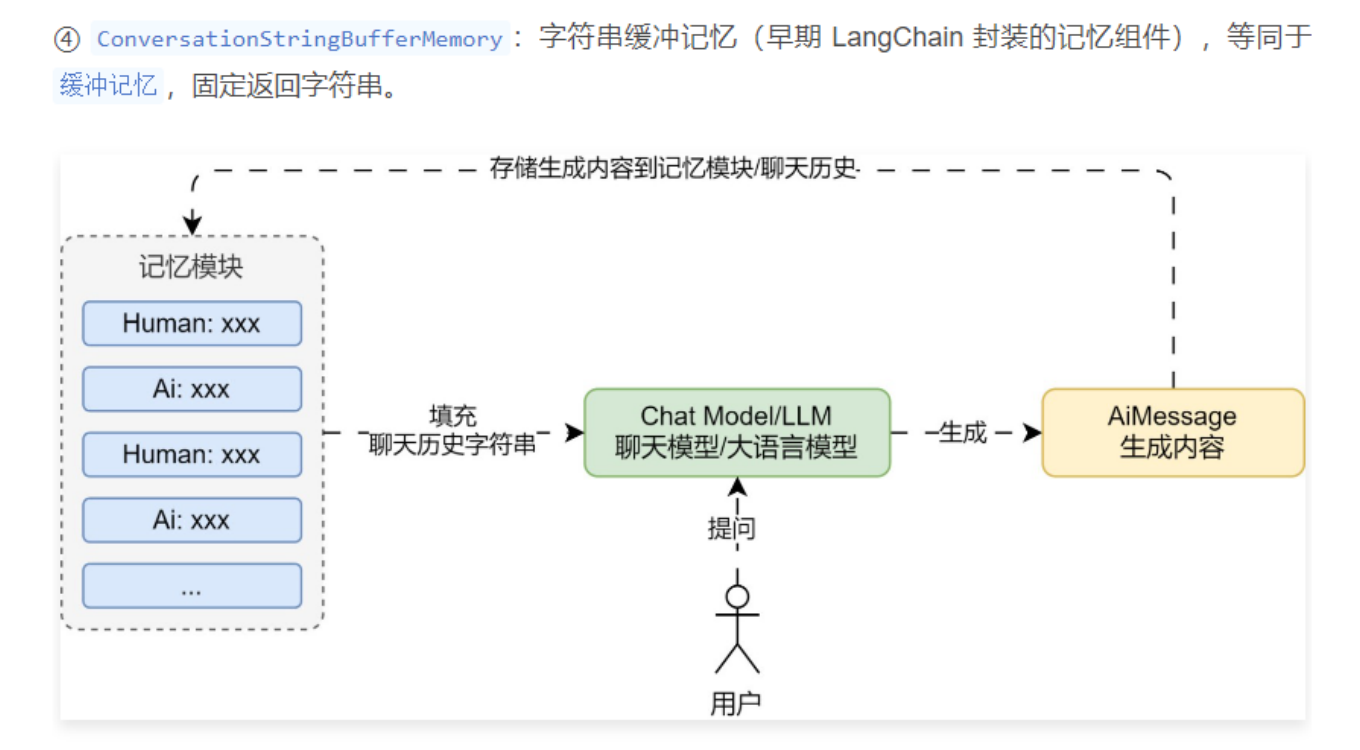
02. 缓冲窗口记忆示例
使用 LangChain 实现一个案例,让 LLM 应用拥有 2 轮的对话记忆,超过 2 轮的记忆全部遗忘。代码
from operator import itemgetter
import dotenv
from langchain.memory import ConversationBufferWindowMemory
from langchain_community.chat_message_histories import FileChatMessageHistory
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
memory = ConversationBufferWindowMemory(
input_key="query",
return_messages=True,
k=2,
)
prompt = ChatPromptTemplate.from_messages([
("system", "你是OpenAI开发的聊天机器人,请帮助用户解决问题"),
MessagesPlaceholder("history"),
("human", "{query}")
])
llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
chain = RunnablePassthrough.assign(
history=RunnableLambda(memory.load_memory_variables) | itemgetter("history")
) | prompt | llm | StrOutputParser()
while True:
query = input("Human: ")
if query == "q":
exit(0)
chain_input = {"query": query}
print("AI: ", flush=True, end="")
response = chain.stream(chain_input)
output = ""
for chunk in response:
output += chunk
print(chunk, flush=True, end="")
print("\nhistory:", memory.load_memory_variables({}))
memory.save_context(chain_input, {"output": output})

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 24
24 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)