3.1 Encoder-only PLM
datawhale ai 共学。
第三章 预训练语言模型 datawhale ai 共学
3.1 Encoder-Only 预训练模型笔记
为什么只保留 Encoder?
-
任务指向:情感分类、文本匹配、问答检索等 NLU 场景只需得到句子级/ token 级表示,不必显式解码
-
并行友好:Encoder 全自注意力,输入一次即可全局计算,推理延迟低于自回归 Decoder
-
参数利用率:同样预算下,把全部容量放在理解侧,往往比「读写通吃」更划算
BERT → RoBERTa → ALBERT:三条演化路线的来龙去脉、技术细节与经验教训
一、BERT:双向 Transformer 的奠基之作
| 维度 | 核心设计 | |
|---|---|---|
| 架构 | 纯 Encoder(12/24 层), 聚合句级语义 | 用分类头即可应付大多数 NLU 任务,微调门槛低 |
| 预训练 |
① MLM:随机 15 % token → 80 % ② NSP:判断句对是否相邻 |
MLM 让模型看“左右文”→ 双向; NSP 早期用于句对任务,后来被证明贡献有限 |
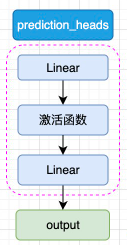
| 微调范式 | “一次预训,多头微调”,Softmax/CRF/池化随取随用 |
重新定义了 NLU 研发工作流: 数据小也能用大模型 |
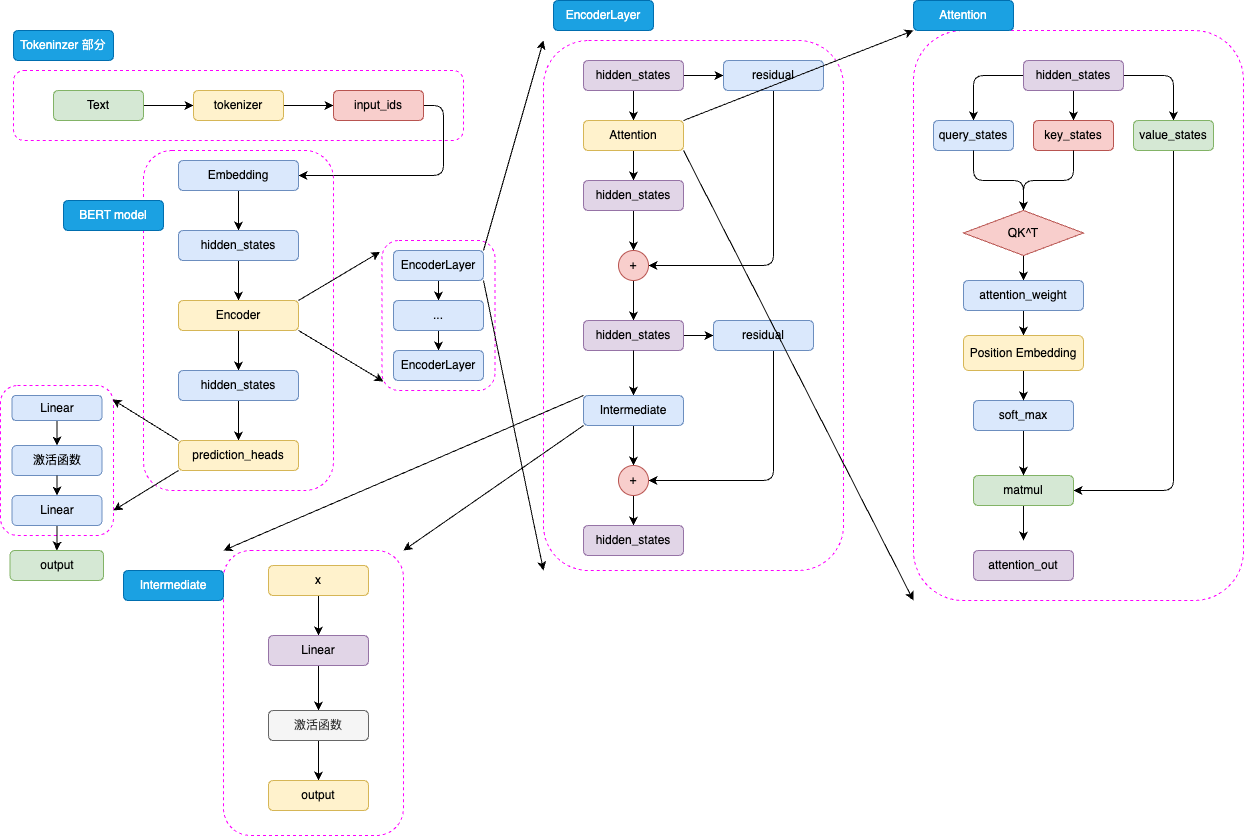
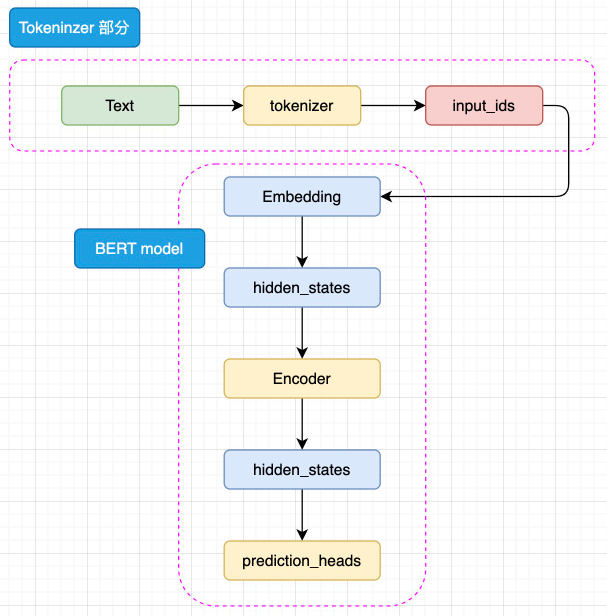
1. Tokenizer & Embedding
Tokenizer → input_ids
| 步骤 | 说明 |
|---|---|
| WordPiece 子词切分 | 基于贪婪合并规则得到 30 522 词表(含 [CLS][SEP][MASK] 等标记) |
| 句对拼接 | 输入一段或两段文本,格式:[CLS] Sentence-A [SEP] Sentence-B [SEP] |
| 生成三组索引 |
|
Embedding 子层
X = token_emb + segment_emb + position_emb → LayerNorm → Dropout
| 参数 | 形状 | Base / Large |
|---|---|---|
| Token Emb | (V=30 522, H) | 23.5 M / 31.3 M |
| Segment Emb | (2, H) | ≈ 1 k |
| Position Emb | (512, H) | 0.4 M / 0.5 M |
| 组件 | 细节 | 设计意图 |
|---|---|---|
| WordPiece | 30 000 token;贪心合并高频子词 | 能用最小词表覆盖 OOV(out-of-vocabulary) |
| 嵌入矩阵 | V=30k; H=768 (base) or 1024 (large) |
参数 23 M / 30 M,占总体 20%+ |
| 三向相加 | token emb + segment emb + position emb | segment 辨 A/ B 句,position 固定 sin/cos |
x_tok = tok_emb[input_ids] # (B,T,H)
x_seg = seg_emb[token_type_ids] # (B,T,H)
x_pos = pos_emb[:, :T, :] # (1,T,H)
hidden = ln_drop(x_tok + x_seg + x_pos)
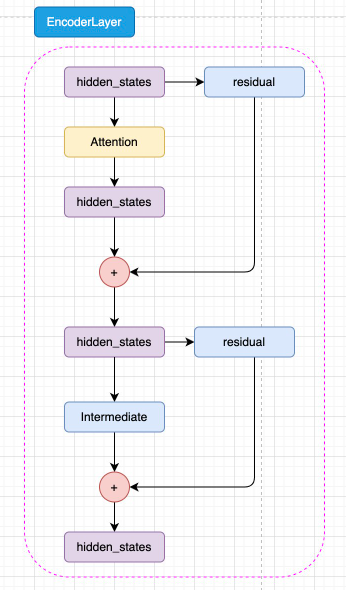
2. Encoder × L 层堆叠
-
层数:12 (base) / 24 (large)
-
维度:768 / 1024;头数 12 / 16;FFN 隐维 3072 / 4096
-
前置 LayerNorm?
-
BERT 原论文用 Post-Norm,官方源码改为 Pre-Norm;公开权重沿用 Post
-
h0 = LayerNorm(hidden) z1 = MultiHeadAttention(h0) # (B,T,H) h1 = hidden + Dropout(z1) # Residual-1 h1n = LayerNorm(h1) z2 = FeedForward(h1n) # (B,T,H) hidden = h1 + Dropout(z2) # Residual-2
2.1 Self-Attention
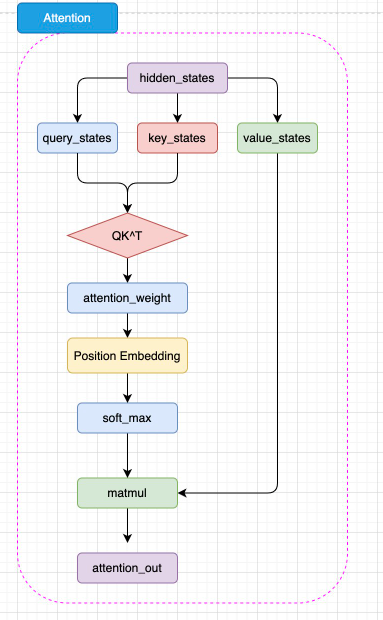
-
线性投影:
Q = hWq,K = hWk,V = hWv(Wq/Wk/Wv ∈ ℝ^{H×H}) -
分头切分:reshape 为 (B, A, T, H/A)
-
点积+缩放:
score = (Q·Kᵀ) / √(H/A)→ mask (padding) -
Softmax → Dropout → 与 V 相乘
-
合并头 + 线性投影
Wo(ℝ^{H×H})
| 参数量 (单层) | Base | Large |
|---|---|---|
| Q/K/V/Wo | 4 × H² = 1.8 M | 4.2 M |
| Attention bias | 忽略不计 |
2.2 Feed-Forward Network
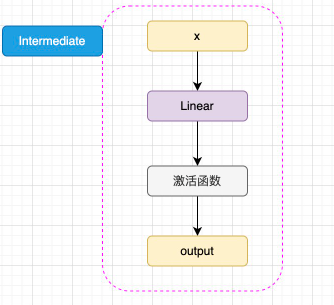
两层全连接 + GELU + Dropout
FFN(x) = W₂ · GELU(W₁·x + b₁) + b₂
| 矩阵 | 形状 |
|---|---|
| W₁ | (H, I) eg. 768×3072 |
| W₂ | (I, H) |
| 激活 | GELU:x * 0.5 * (1 + erf(x / √2)) |
4. 预训练任务
| 任务 | 细节 | |
|---|---|---|
| MLM | 15 % token:80 % <mask>,10 % random,10 % keep |
深度双向;对上下文同权重感知 |
| NSP | 50 % 正例:连续句;50 % 负例:另一篇随机句 | 句对级分类表示 |
训练超参(BERT-base)
语料:BookCorpus + Wikipedia ≈ 3.3 B token (13 GB)
步数:1 M;batch size 256;学习率 1e-4;Adam β=(0.9,0.999)。
90 % 长度 128,10 % 长度 512(梯度累积 模拟大 batch)
4. 优势 & 局限
-
优势:一键下游微调(GLUE 从堪用→SOTA);通用特征变现
-
设计哲学:将任务无关的大规模文本知识预先“蒸馏”进参数 → 下游只需浅层学习即可收获泛化
-
工程平衡:在参数、批量、序列长度三维度内找到适合硬件预算的 sweet-spot;BERT-base 是很多生产系统的天花板
-
演化接口:词表(BPE → SentencePiece)、位置编码(绝对 → 相对/旋转)、预任务(MLM → RTD)都可替换而不破坏主体架构
-
局限:
-
绝对位置编码Sin/Cos使 “>512” 上下文被截断
-
NSP 很快被验证对很多任务无贡献
-
Embedding + 多层 FFN 带来庞大参数,Embedding 参数 23 M,模型再加宽吃不消
-
训练成本高(TPU×16 4 天)但仍算“中等语料”
-
二、RoBERTa:更大数据、更久训练
1. 去掉 NSP 只保留 MLM,简化流程
-
直接删除句对预测;输入改为单串(可跨文档拼接)
-
发现 NSP 的梯度信号占比极低,删减后下游准确率反而上涨 (GLUE +0.8)
2. 动态 Mask 策略
-
每次
DataLoader调用前随机选 15% token ⇒ 训练 500 k 步都新mask -
避免 4 次静态 mask 重放带来的“样本贫血”
3. 规模扩张
| 项目 | BERT | RoBERTa |
|---|---|---|
| 语料 | 13 GB | 160 GB (BookCorpus+Wiki+CC-News+OpenWebText+CC-Stories) |
| batch (token) | 256×128 | 8 192×512 (≈ 4 M token) |
| 步数 / Epoch | 1 M / 40 | 500 k / 66 |
| 词表 | 30 k | 50 k 减少未知拆分 |
-
使用 LAMB / AdamW + linear warmup 10 k
-
1024×V100 GPU (32 GB) 1 天完成 large 版训练
4. 成效
-
GLUE 平均 88.5 → 90.2;RACE、SQuAD 1.1/2.0 全线刷新记录
-
结论被业内总结为 “More data, longer training, larger batch ∝ 更好结果”
三、ALBERT:参数压缩与新任务 SOP
1. Embedding 分解
W_embed ∈ ℝ^{V×H} → E:V×E' (128) + P:E'×H
-
参数缩减比
(V·E' + E'·H) / (V·H) -
允许把 H 扩到 2 048 而总参数仍 < BERT-base
2. 跨层权重共享
-
Option A:仅共享 FFN
-
Option B:共享 Attention + FFN(论文选 B,全共享)
实际训练:24 次前向仍要算注意力,但优化内存 & 存储显著
3. SOP (Sentence Order Prediction)
-
正例:两连续句;负例:互换顺序
-
理由:NSP 太容易被段落主题/粗粒度统计特征破解 SOP 迫使模型捕获细粒度语序逻辑
-
实验:MLM+SOP > MLM+NSP ≈ MLM
4. 模型族
| 版本 | 层×宽 | 参数(M) | dev GLUE |
|---|---|---|---|
| base | 12 × 768 | 12 M | 80.1 |
| large | 24 × 1 024 | 18 M | 82.3 |
| xlarge | 24 × 2 048 | 59 M | 89.4 |
-
同容量下优于 RoBERTa;蒸馏友好
-
缺点:推理速度并未线性加速(仍 24 前向),微调阶段需要谨慎调 lr
在“轻量化”与“性能”之间找到一条折中路线,训练/推理加速不明显,工业落地更多依赖 Distil-/Tiny-BERT 这类蒸馏方案
四、实践速查
| 模型 | 规模 (M) | 预训任务 | 语料 | 亮点 | 常见应用 |
|---|---|---|---|---|---|
| BERT-base | 110 | MLM + NSP | 13 GB | 双向表示开山 | 情感/NER/问答 |
| RoBERTa-large | 355 | MLM | 160 GB | 动态 mask、超大 batch | 句向量检索 |
| ALBERT-xlarge | 59 | MLM + SOP | 16 GB | 参数共享 + 宽层 | 移动端推理 |
| 问题场景 | 推荐路线 | 说明 |
|---|---|---|
| GPU 低显存 / 移动端 | DistilBERT / ALBERT-base | 6-12 M 参数,蒸馏后 97 % BERT 准确度 |
| 大批量离线文本检索 | RoBERTa-large + FAISS | 512 上下文 & bi-encoder pooling |
| 长文档 (>1 K token) | Longformer / BigBird | 稀疏注意力改造;或分块 + 分段聚合 |
| 高并发 API 服务 | BERT-base 半精度 + TensorRT | throughput 可达 3 k qps / A30 |
五、Encoder-Only 系列的历史影响
-
奠定通用特征市场:微调式 NLP pipeline(Tokenizer → BERT → 轻头)成为工业默认模板
-
创造新 Benchmark:GLUE / SQuAD 曲线被不断刷新,推动任务设置升级(SuperGLUE、MMLU)
-
催生蒸馏与剪枝热潮:参数膨胀带来的部署痛点直接衍生出 Tiny-, Mobile-, Quant-BERT 等大量研究
-
为 LLM 铺路:RoBERTa 的“大数据 + 大 batch + 长训练”经验,被 GPT-2/3 直接继承;ALBERT 的跨层共享又影响到了深度可达 100+ 层的 PaLM/LLaMA 规范化设计
六、反思
-
预训练任务设计是“性价比艺术”:太简单无益,太难损坏通用性;MLM→SOP→RTD(ELECTRA)是一条逐渐“加信息密度”而不过拟合的数据再利用路径
-
资源利用率重要性:RoBERTa 侧重横向扩容,ALBERT 探索纵向压缩;两种思路在实际业务中常结合使用——先 RoBERTa 级别 teacher,再蒸馏为 ALBERT / Tiny 模型落地
-
Encoder-only ≠ 过时:在需要高吞吐、低延迟、强解释性的场合(搜索、规则引擎、零售推荐)仍是主力;与 LLM 形成分工而非替代
BERT 家族让 NLP 真正进入“预训练时代”,RoBERTa “堆料上分”,ALBERT “减宽增智”
共同奠基今天对 数据规模、模型容量、任务设置 的经典认知

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 30
30 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)