大模型修炼之路
本文分享了在Windows 11系统下通过WSL运行Ubuntu来部署vLLM框架的经验。使用RTX 5060Ti 16GB显卡测试Qwen3-4B模型,显存占用约15GB,其中模型权重8GB,KV缓存5.6GB(基于40960上下文长度)。详细解释了GQA(Grouped Query Attention)机制如何通过多个Query头共享KV头来减少显存占用和计算量,相比传统MHA机制更高效。文章
今天开始在家用机器上跑qwen,测试微调,langchain以及mcp等等一系列功能,配置目前为rtx5060ti 16gb版本,Windows11系统,由于Windows对vllm不够友好,选择了采用wsl跑Ubuntu系统的方案,很方便,网络以及硬盘都能便捷的读取,并且安装操作什么的也很便捷,目前没发现有什么bug的地方。
那么我们目前初步架构就为wsl中跑Ubuntu来运行vllm提供大模型功能,原生系统上跑python代码通过http通信请求(不想折腾直接用transformers直接可以起大模型服务,但是这里主要还是为了学习vllm框架)
目前选用的是qwen3-4b模型,显存占用量为15gb,此处主要涉及了两个方面:
1.权重,4b模型的参数在FP16下大概就是40亿再乘以每个参数占2个字节(因为fp16或者bf16是16bit),这样模型大概占了8个g显存左右;
2.KV缓存,这个随上下文长度线性增长,我设置的长度比较大是40960,因为vllm还是基于Transformer,所以计算方式为:
KV ≈ 2 × 层数 × n_kv_heads × head_dim × seq_len × 2B
每一项的含义如下:
| 项目 | 含义解释 |
| 2 | 每个 token 有 K(Key)和 V(Value),各算一次 |
| 层数 | 模型有多少层(如 Qwen3-4B 是 36 层) |
| n_kv_heads | 实际缓存的 KV Head 数(注意是 GQA 后的头数) |
| head_dim | 每个 Attention Head 的维度(一般是 128) |
| seq_len | 当前最大上下文长度(如目前设置40960) |
| 2B | FP16/BF16 表示一个元素需要 2 字节 |
这样算出来KV缓存大小 ≈ 2 × 36 × 8 × 128 × 40960 × 2B ≈ 6,029,885,440 字节 ≈ 5.6 GiB
3.再加上:
PagedAttention 页表(几百 MB ~ 1 GiB)
CUDA context
临时 kernel 缓冲区
这样总计算起来大概约15G左右。
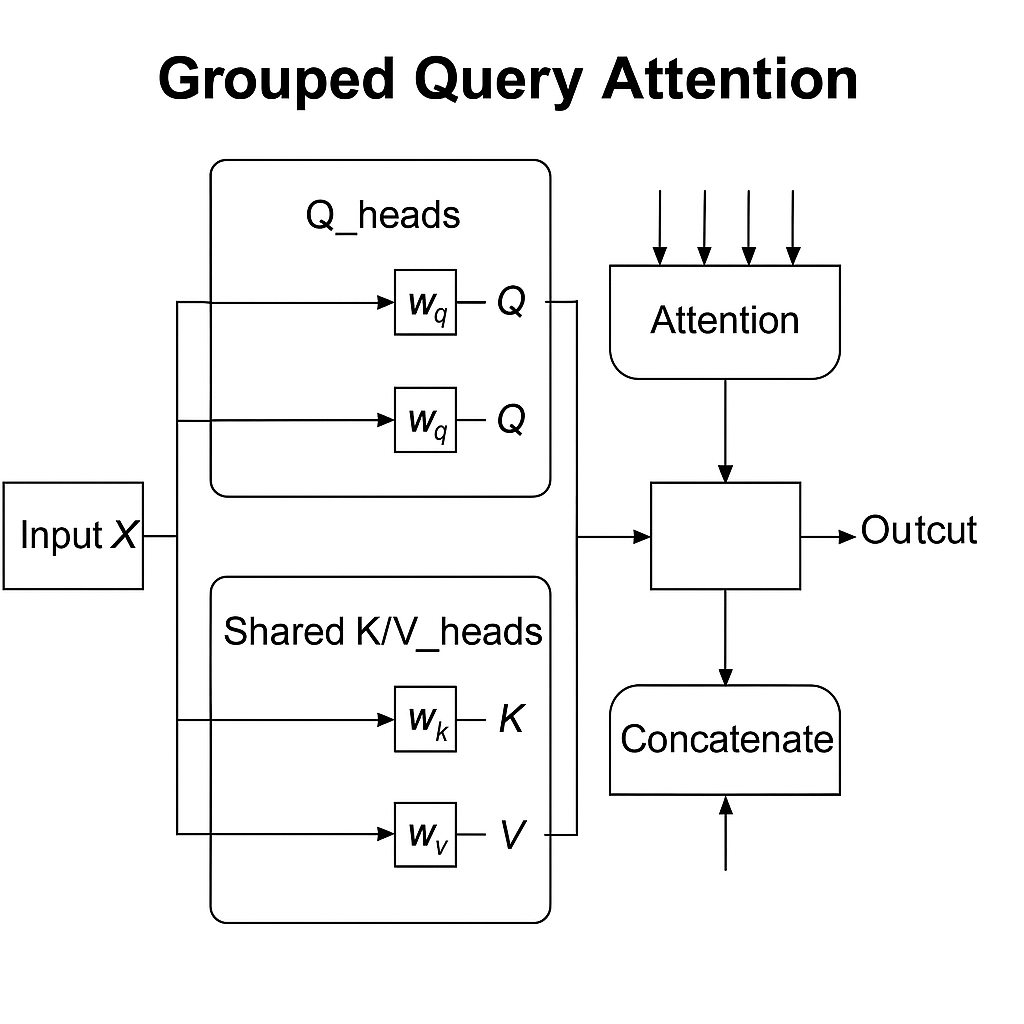
此外,关于GQA说明一下:
原始 Transformer 是 每个 Attention Head 都有自己的 K/VGQA(Grouped Query Attention)是优化版,多个 Query Head 共享同一组 KV Head,所以实际缓存的是 n_kv_heads,远小于总头数,大幅减少显存占用。
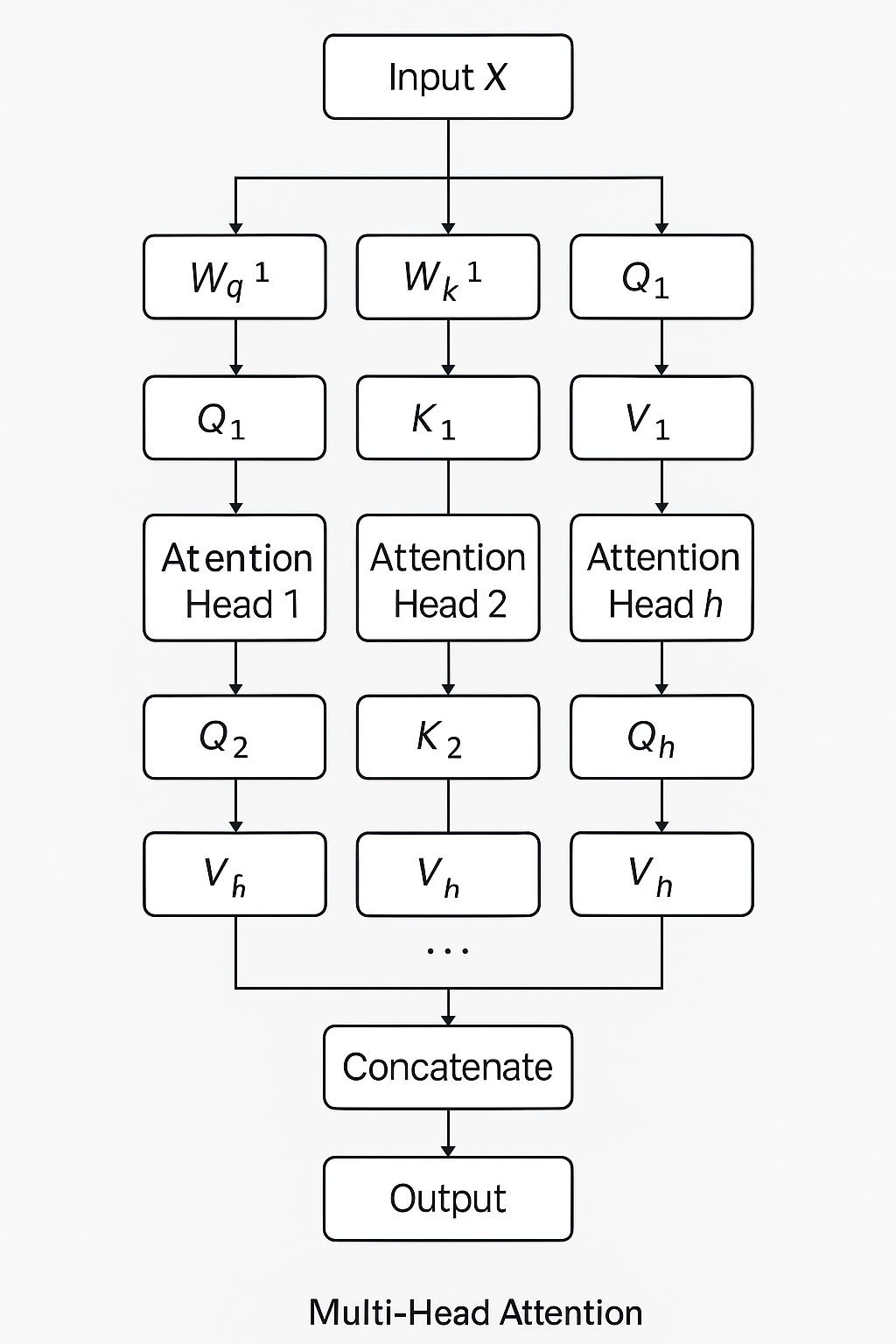
然后我们再回顾一下GQA的机制:
传统的 Transformer 使用标准的 Multi-Head Attention(MHA),每一组QKV都有独立的头,反过来说,每个注意力头都有自己的qkv,但是GQA的核心思想是多个Query Head可以共享同一组Key 和 Value Head。也就是说:GQA的Query 头很多(保持高表达能力)但是Key和Value头比较少,这样就节省显存和计算量。
那GQA 如何工作?对于每个 Query Head:使用它自己的 W_q 计算出 Query,但使用共享的 Key 和 Value(通过分组索引或广播)来做 Attention。所以计算流程仍然有效,表达能力也保留。
最后,总结一句话:GQA让多个 Query Head 共用一组 KV Head,减少内存和计算量。
下面是两张图直观对比一下原生MHA机制和GQA机制:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)