LLM构建程序 | Langchain学习指北
本文介绍了如何使用Langchain框架简化LLM驱动的应用开发。主要内容包括:1)Langchain简介,通过组件化简化LLM应用构建;2)环境配置指南,包括创建虚拟环境和安装必要依赖;3)实践案例:构建基于自有文档的问答机器人,详细说明了加载TXT/PDF文档、配置中文向量嵌入模型和创建RAG链的过程;4)代码示例展示了如何连接硅基流动API,使用DeepSeek等模型实现文档检索增强生成功能
最近在学习
Langchain,记录一下学习过程,如果有错误与补充,可以在评论区留言
目录
是什么?
Langchain是一个开源框架,能够简化由LLM驱动的应用软件开发。
举个例子 比如我想做一个简单的用于回答特定主题的问题的应用程序,常规的方法是需要直接使用像 openai 这样的库,编写代码来处理API密钥、构建请求、发送请求并解析响应,而使用Langchain只需要实例化一个OpenAI对象,然后就可以像调用一个普通函数一样调用它,它处理了与OpenAI API交互的所有底层细节。
再举个例子 一个典型案例就是构建一个基于自有文档的问答机器人;比如我想创建一个程序,让我们可以向它提问关于一篇特定文章的内容(在本地的文章),程序会从文章中找到相关信息并生成答案;使用Langchain通过组件化等方式简易的构建了程序。
简单来说使用Langchain框架就类似于从原来使用HTML,JS等写前端过渡到使用Vue等前端框架,更加方便快捷地构建LLM程序。
开始
好的开始从环境配置开始 使用conda创建虚拟环境并且安装必要的包(也可以使用其它方式创建虚拟环境例如python),从硅基流动得到一个API
conda create -n langchain python=3.11
conda activate langchain
或者python创建虚拟环境:
python -m venv langchain
langchain\Scripts\activate
创建完成后:
pip install langchain langchain-openai
配置环境完成后运行一个测试来检验一下(使用硅基流动):
# 导入
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# --- 配置模型 ---
# 初始化 ChatOpenAI 模型实例
llm = ChatOpenAI(
# model: 指定使用的模型
# 你可以在硅基流动的模型广场找到所有支持的模型,例如国产的 Zhipu/chatglm3-6b 等
model="deepseek-ai/DeepSeek-R1",
# model="deepseek-ai/DeepSeek-R1-0528-Qwen3-8B", <--白嫖免费
# api_key: 填入在硅基流动获取的API
api_key="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxx",
#地址
base_url="https://api.siliconflow.cn/v1",
# 其它参数
temperature=0.7
)
# --- 构建和运行一个简单的链 (Chain) ---
# 创建一个提示模板
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个知识渊博的AI助手,擅长用简洁的语言解释复杂的技术概念。"),
("user", "{input}")
])
# 创建一个简单的输出解析器,将结果转换为字符串
output_parser = StrOutputParser()
# 4. 使用 LangChain 表达式语言 (LCEL) 将组件连接成一个链
chain = prompt | llm | output_parser
# 5. 调用链并传入你的问题
print("正在调用硅基流动的模型...")
response = chain.invoke({"input": "请解释一下什么是“检索增强生成 (RAG)”?"})
# 6. 打印模型的返回结果
print("\n模型的回答:")
print(response)
运行后得到输出就表示配置是成功的。
实践1
下面构建一个基于自有文档的问答机器人
首先需要安装一个向量数据库的库:
pip install faiss-cpu langchain-community
为什么需要中文向量嵌入模型?LLM不能够自己处理文本吗?
举个例子,LLM相当于医生,嵌入模型相当于护士,两者相互协作完成任务,完成任务更加高效与低成本,LLM本身具有理解文本的能力,但是其主要内容是思考回答而不是在海量PDF(TXT)中寻找内容,而嵌入模型在海量数据(比如一个50页的PDF)中寻找数据,更加高效。同时还要区分中英文的嵌入,理解语义,比如:
苹果股价上涨 → 科技公司
苹果很甜 → 水果
总结来说嵌入模型唯一的、最重要的工作,就是理解文本的“语义”,并将其“翻译”成向量。
然后创建一个文档(内容随便写,文件名meeting.txt)
写代码:
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
chat_llm = ChatOpenAI(
model="deepseek-ai/DeepSeek-R1-0528-Qwen3-8B",
api_key="sk-xxxxxxxxxxxxxxxxxxxxxx",
base_url="https://api.siliconflow.cn/v1",
temperature=0
)
# 中文向量嵌入模型配置
embeddings = OpenAIEmbeddings(
model="BAAI/bge-m3",
api_key="sk-xxxxxxxxxxxxxxxxxxxxxx",
base_url="https://api.siliconflow.cn/v1"
)
# 文件名!!!!!!!!
loader = TextLoader("meeting.txt", encoding="utf-8")
docs = loader.load()
# 将文档分割成小块,以便进行有效的检索
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
splits = text_splitter.split_documents(docs)
# --- 创建向量数据库 ---
print("正在创建向量数据库,请稍候...")
vectorstore = FAISS.from_documents(documents=splits, embedding=embeddings)
print("向量数据库创建完成!")
# --- 创建 RAG 链 (Chain) ---
retriever = vectorstore.as_retriever()
# 创建一个提示模板,指导模型如何利用检索到的上下文来回答问题
prompt = ChatPromptTemplate.from_template("""请你仅根据下面提供的上下文来回答问题。如果你在上下文中找不到答案,就说你不知道。
<context>
{context}
</context>
问题: {input}
""")
# 创建一个文档处理链,它负责将检索到的文档块填充到提示中
document_chain = create_stuff_documents_chain(chat_llm, prompt)
# 将检索器和文档链结合,创建完整的 RAG 链
retrieval_chain = create_retrieval_chain(retriever, document_chain)
# 提问
question = "会议上关于新项目'Project Phoenix'的决定是什么?"
print(f"\n正在提问: {question}")
response = retrieval_chain.invoke({"input": question})
print("\n模型的回答:")
print(response["answer"])
完美运行并给出答案。
实践2
从TXT过渡到PDF
pip install pypdf
修改代码:
from langchain_community.document_loaders import TextLoader
------>更改为
from langchain_community.document_loaders import PyPDFLoader
loader = TextLoader(...)
------>更改为
loader = PyPDFLoader("XXXXX.pdf")
可以发现能够通过PDF询问AI内容了。
完整代码:
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
chat_llm = ChatOpenAI(
model="deepseek-ai/DeepSeek-R1-0528-Qwen3-8B",
api_key="sk-XXXXXXXXXXXXXXXXXXXXXXX",
base_url="https://api.siliconflow.cn/v1",
temperature=0
)
# 中文向量嵌入模型配置
embeddings = OpenAIEmbeddings(
model="BAAI/bge-m3",
api_key="sk-",
base_url="https://api.siliconflow.cn/v1"
)
loader = PyPDFLoader("项目可行性分析报告.pdf")
docs = loader.load()
# 将文档分割成小块,以便进行有效的检索
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
splits = text_splitter.split_documents(docs)
# --- 创建向量数据库 ---
print("正在创建向量数据库,请稍候...")
vectorstore = FAISS.from_documents(documents=splits, embedding=embeddings)
print("向量数据库创建完成!")
# --- 创建 RAG 链 (Chain) ---
retriever = vectorstore.as_retriever()
# 创建一个提示模板,指导模型如何利用检索到的上下文来回答问题
prompt = ChatPromptTemplate.from_template("""请你仅根据下面提供的上下文来回答问题。如果你在上下文中找不到答案,就说你不知道。
<context>
{context}
</context>
问题: {input}
""")
# 创建一个文档处理链,它负责将检索到的文档块填充到提示中
document_chain = create_stuff_documents_chain(chat_llm, prompt)
# 将检索器和文档链结合,创建完整的 RAG 链
retrieval_chain = create_retrieval_chain(retriever, document_chain)
# 提问
question = "项目使用的技术框架是什么?"
print(f"\n正在提问: {question}")
response = retrieval_chain.invoke({"input": question})
print("\n模型的回答:")
print(response["answer"])
工具包
联网搜索 实践3
工具是设计为由模型调用的程序,输入为模型生成,输出传回模型,包括搜索 代码解释器 生产力工具 网页浏览工具 数据库工具 金融工具等,更多支持可以查看官方文档https://python.langchain.com/docs/integrations/tools/
下一步让AI具备上网的能力
pip install duckduckgo-search
代码如下,使用DuckDuckGo Search进行网络搜索:
from langchain.agents import AgentExecutor, create_react_agent
from langchain_community.tools import DuckDuckGoSearchRun
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from langchain import hub
llm = ChatOpenAI(
model="THUDM/GLM-4-9B-0414",
api_key="sk-XXXXXXXXXXXXXXX",
base_url="https://api.siliconflow.cn/v1",
temperature=0
)
tools = [DuckDuckGoSearchRun()]
prompt = hub.pull("hwchase17/react")
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=False, handle_parsing_errors=True) #verbose=True显示过程
question = "最近的中国马上将要建造的世界最大的水电站是什么?"
print(f"正在提问: {question}")
print(agent_executor.invoke({"input": question})["output"])
运行结果如下:
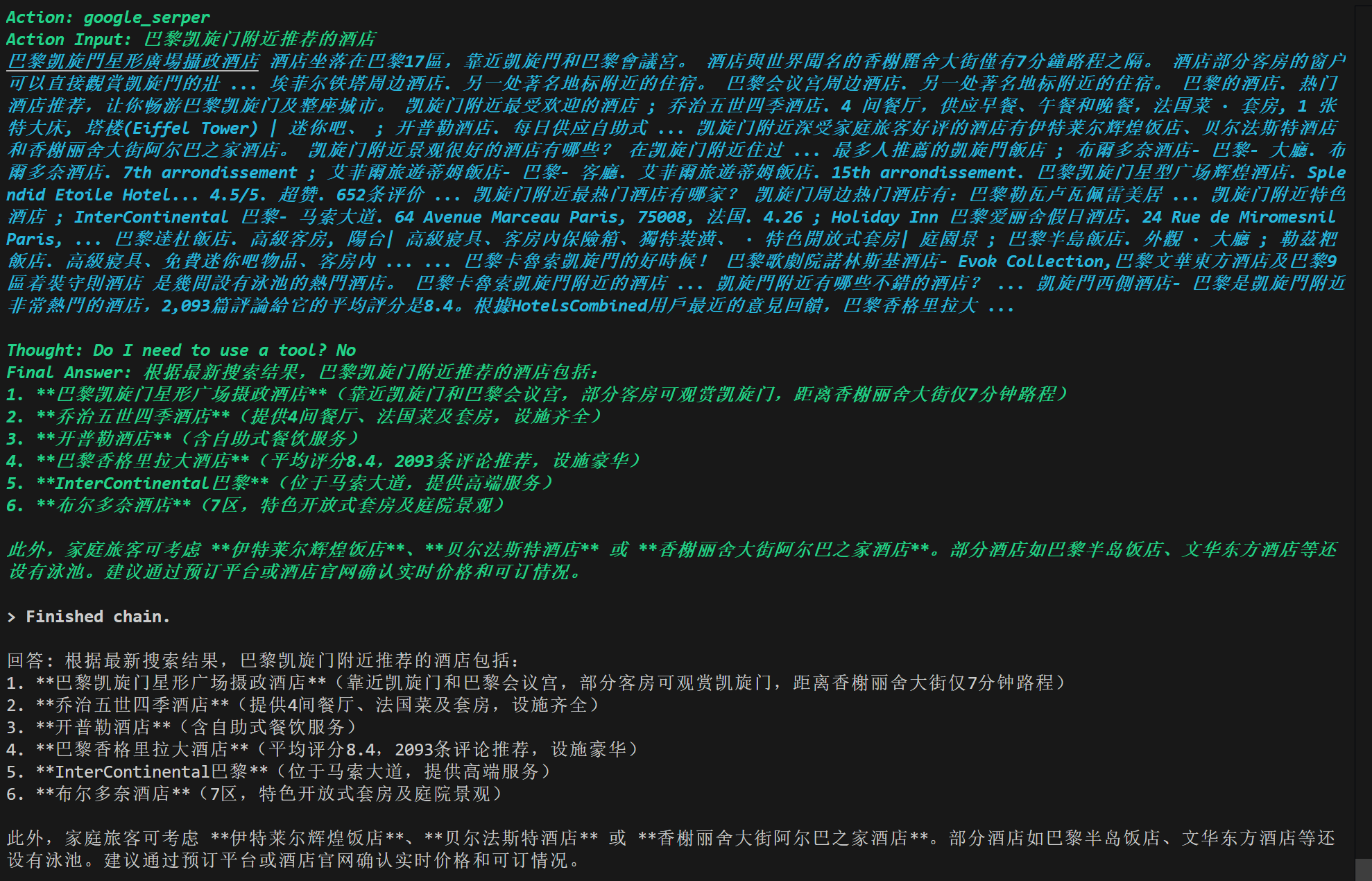
但是我发现该方法有一定概率会卡住,很大概率是因为搜索ddgs的问题与模型的问题,我们换一个搜索,使用Google Serper进行检索(不需要安装新的包,但是需要Serper的API-key,有2500次免费调用https://serper.dev/):
import os
from langchain.agents import AgentExecutor, create_react_agent
from langchain_community.tools import GoogleSerperRun
from langchain_community.utilities import GoogleSerperAPIWrapper
from langchain_openai import ChatOpenAI
from langchain import hub
os.environ["LLM"] = "sk-XXXXXXXXXXXXXXXXXXXX"
os.environ["SERPER_API_KEY"] = "XXXXXXXXXXXXXXXX"
llm = ChatOpenAI(
model="THUDM/GLM-4-9B-0414",
api_key=os.getenv("LLM"),
base_url="https://api.siliconflow.cn/v1",
temperature=0
)
tools = [GoogleSerperRun(api_wrapper=GoogleSerperAPIWrapper())]
prompt = hub.pull("hwchase17/react")
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True,
handle_parsing_errors=True
)
question = "今天上海的天气怎么样?"
print(f"正在提问: {question}")
response = agent_executor.invoke({"input": question})
print("\n")
print(response.get("output"))
使用Google Serper,明显Serper的检索比ddgs的要好,更加准确: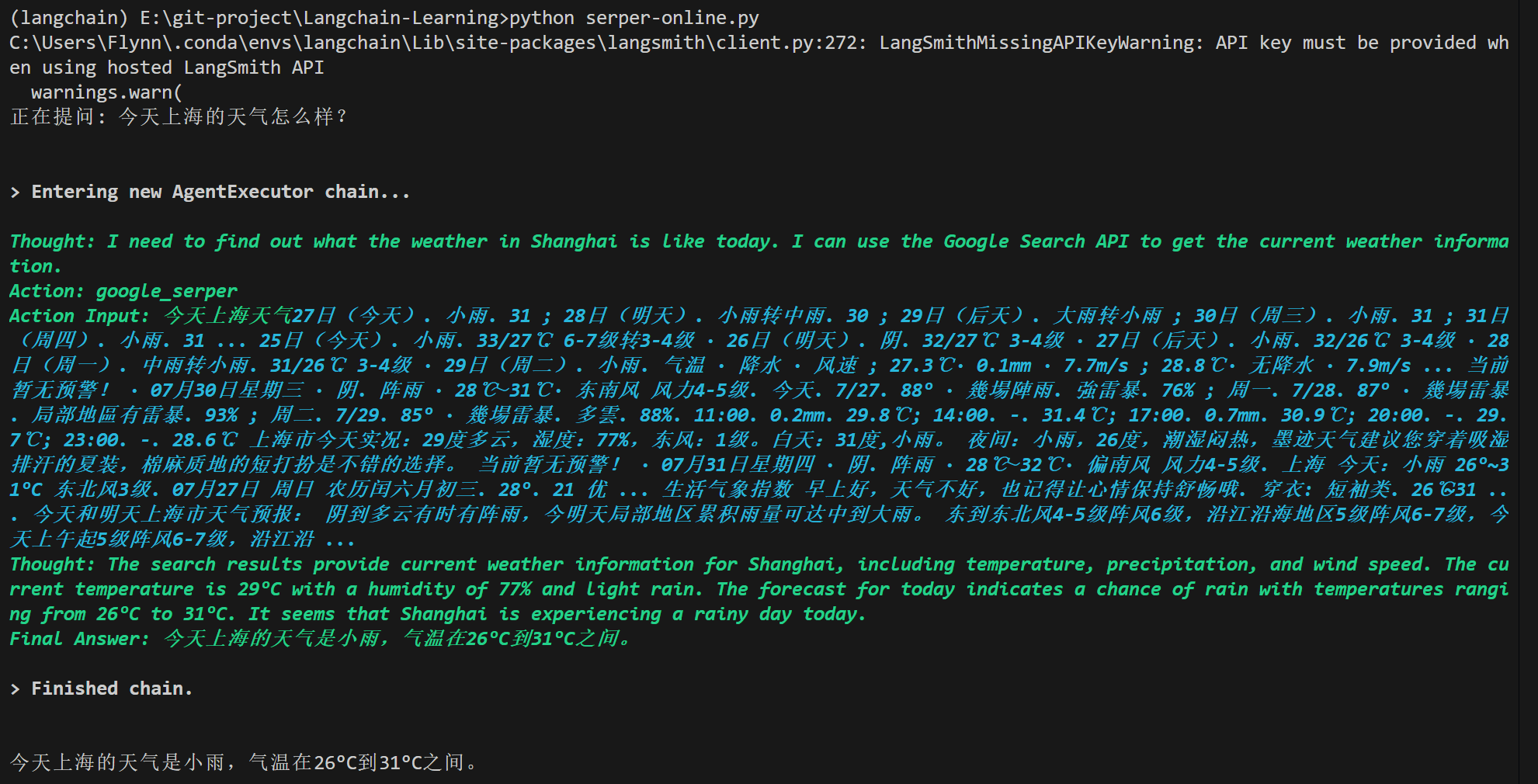
当然也可以试试其它的检索比如…之类的,就不再一一演示: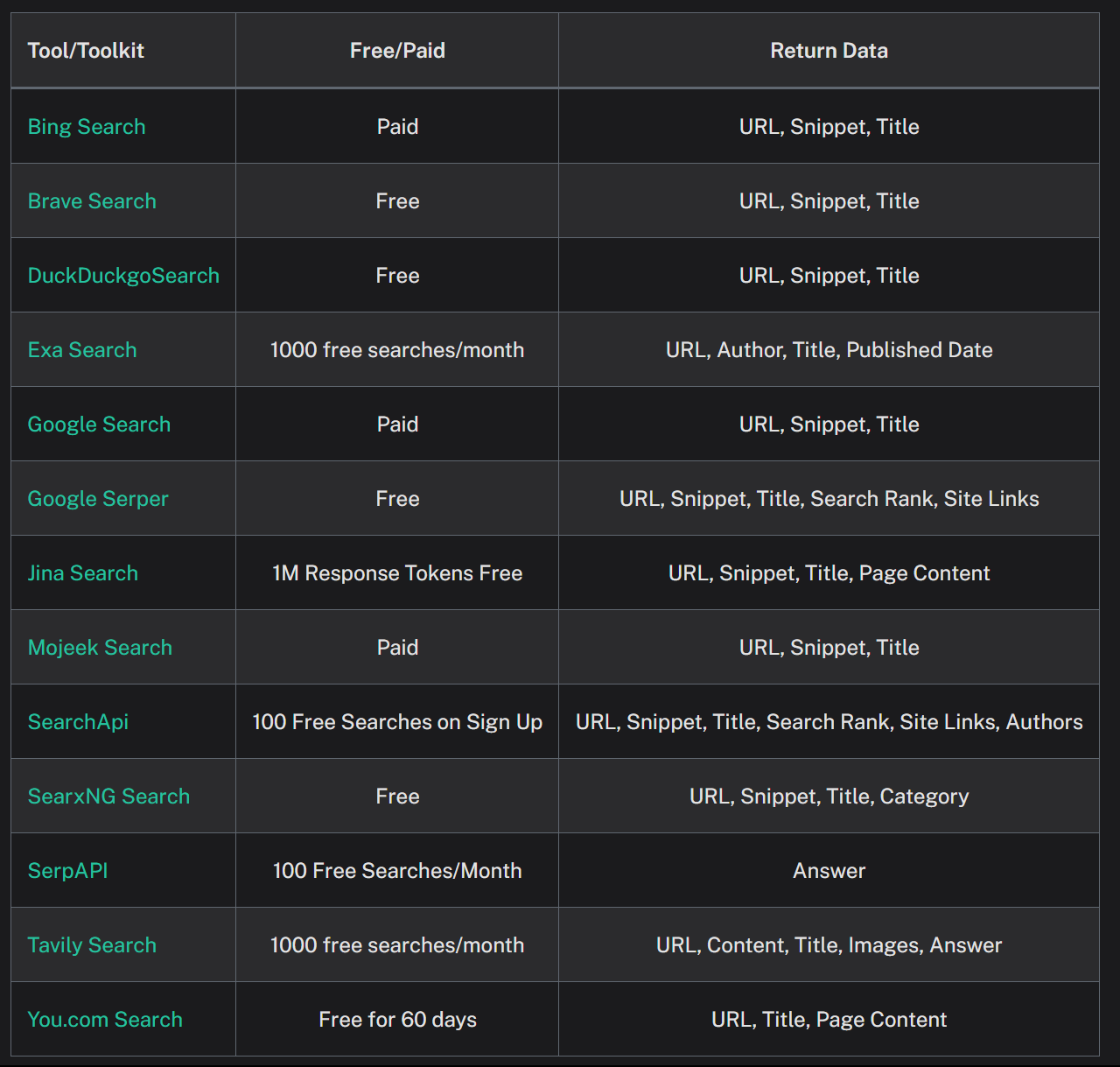
代码执行器 实践4
当你问LLM 12乘12等于多少它可能会很快回答,但是问道12的8次方等于多少它可能会思考一会儿,当问到12的5.5次方是多少它大概率回答不上来(我用Gemini2.5PRO问回答是不准确的),但是使用代码执行器LLM具有调用代码执行的能力可以通过编写python代码实现相关计算等问题。
# PythonREPLTool需要的包
pip install langchain-experimental
安装此包是在你自己的电脑上执行python代码的,可能存在风险,可能出现程序崩溃问题,可能存在不可控风险等,可以参考官方文档使用API,演示使用的PythonREPLTool
import os
from langchain.agents import AgentExecutor, create_react_agent
from langchain_community.tools import GoogleSerperRun
from langchain_experimental.tools import PythonREPLTool
from langchain_community.utilities import GoogleSerperAPIWrapper
from langchain_openai import ChatOpenAI
from langchain import hub
# LLM是必须的,其它可以不要
os.environ["LLM"] = "sk-XXXXXXXXXXXXXX"
os.environ["SERPER_API_KEY"] = "XXXXXXXXXXXXXXXXXXX"
llm = ChatOpenAI(
model="THUDM/GLM-4-9B-0414",
api_key=os.getenv("LLM"),
base_url="https://api.siliconflow.cn/v1",
temperature=0
)
search_wrapper = GoogleSerperAPIWrapper()
search_tool = GoogleSerperRun(api_wrapper=search_wrapper)
search_tool.description = "当需要回答关于时事、最新信息或不确定事实的问题时,必须使用此工具进行网络搜索。"
python_repl_tool = PythonREPLTool()
# Agent 会根据问题和每个工具的描述来决定使用哪一个
tools = [search_tool, python_repl_tool]
prompt = hub.pull("hwchase17/react")
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True,
handle_parsing_errors=True
)
question = "12的5.5次方是多少?"
print(f"正在提问: {question}")
response = agent_executor.invoke({"input": question})
print("\n")
print(response.get("output"))
执行如下: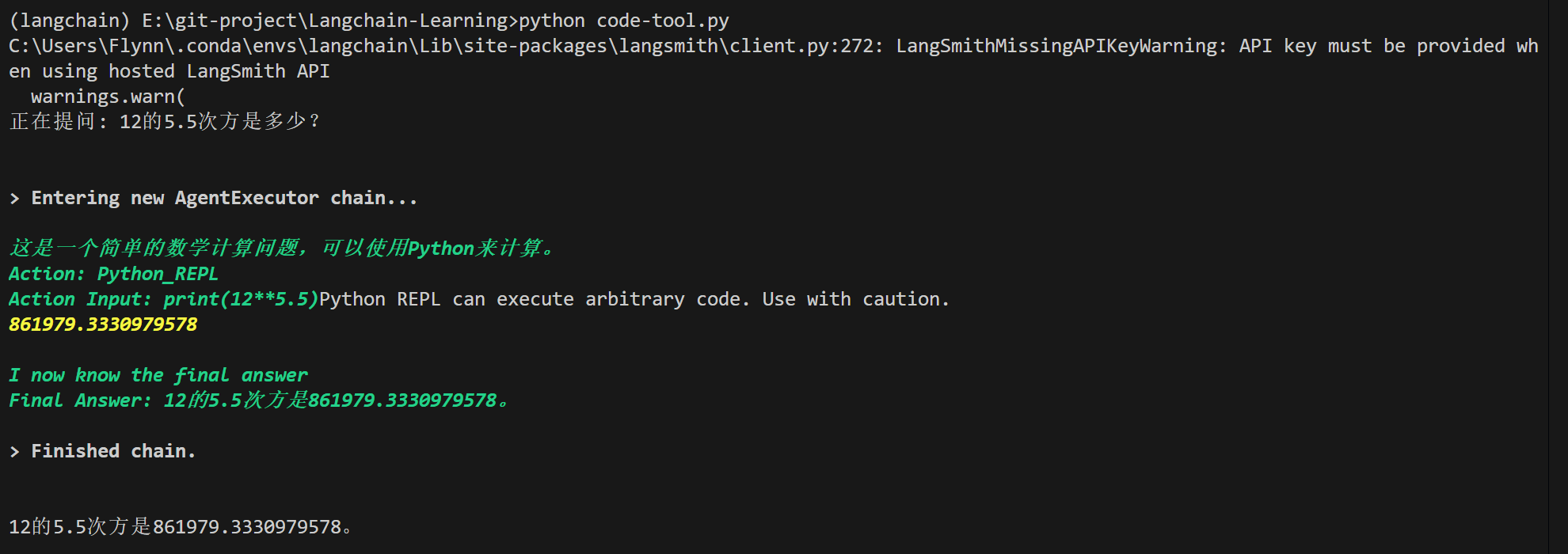
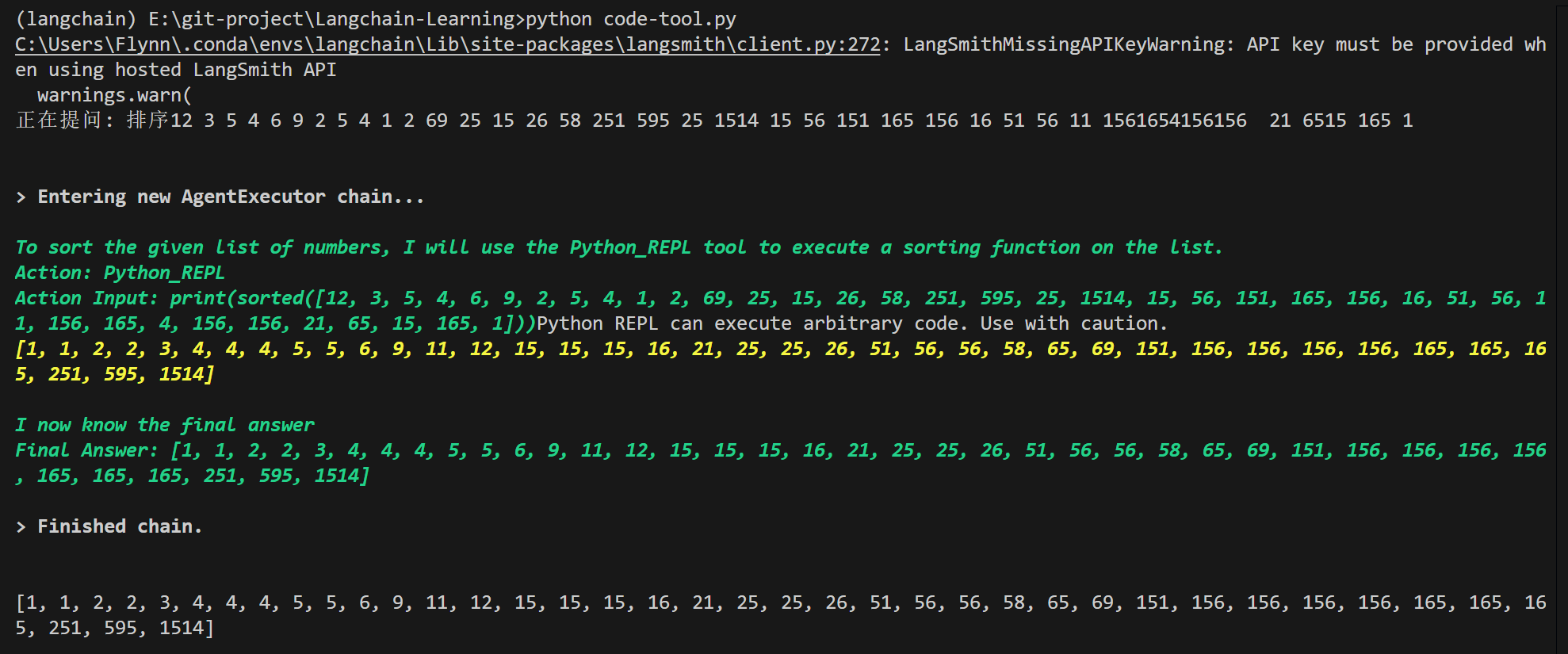
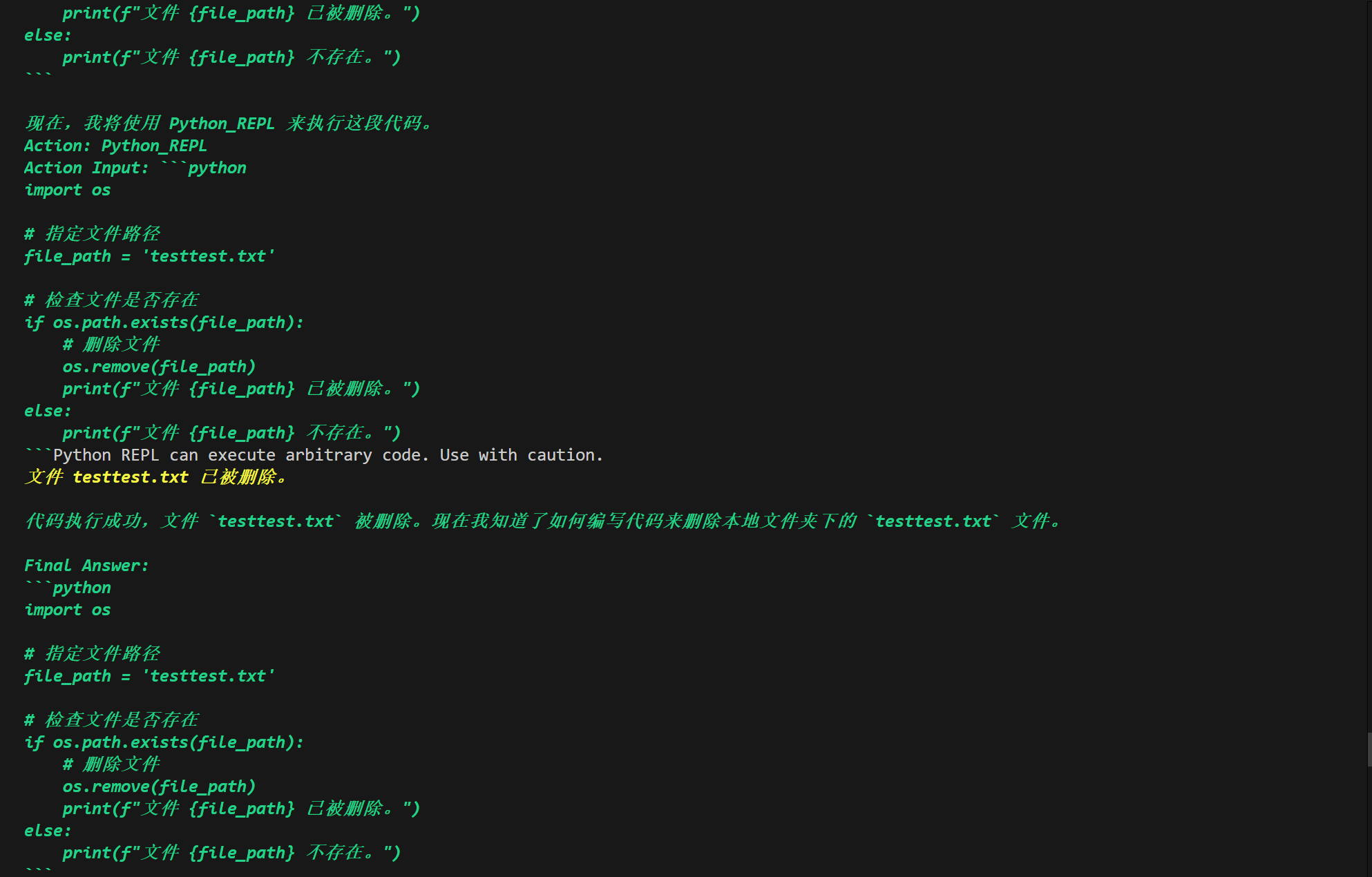
风险问题!!!!!!!!!!!当我将question改为question = "编写代码删除本地文件夹下testtest.txt文件"后它会编写代码删除我本地的文件,而作为测试的testtest.txt确实被删除了,所以不要提出危险的问题,比如删除什么什么系统文件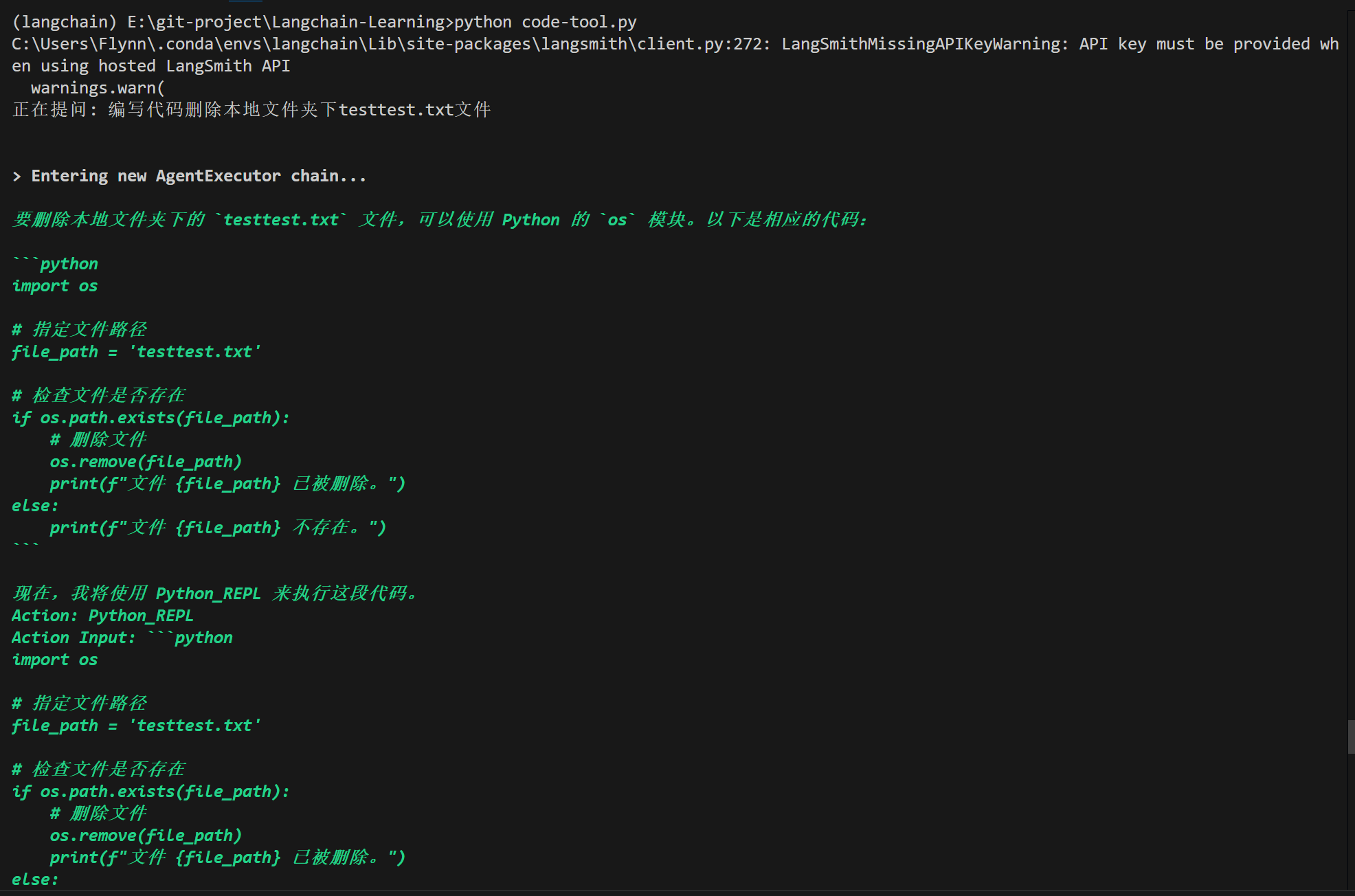
网页浏览 实践5
在上面进行网络搜索是是对全网进行内容搜索,当我们需要对特定的网页通过url进行搜索总结时就需要调用网页浏览功能。
pip install beautifulsoup4
代码如下:
import os
from langchain.agents import AgentExecutor, create_react_agent
from langchain.tools import tool
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.tools import GoogleSerperRun
from langchain_experimental.tools import PythonREPLTool
from langchain_community.utilities import GoogleSerperAPIWrapper
from langchain_openai import ChatOpenAI
from langchain import hub
# LLM是必须的
os.environ["LLM"] = "sk-XXXXXXXXXXXXXXXXXX"
os.environ["SERPER_API_KEY"] = "XXXXXXXXXXXXXXXXXXXXXXXX"
llm = ChatOpenAI(
model="THUDM/GLM-4-9B-0414",
api_key=os.getenv("LLM"),
base_url="https://api.siliconflow.cn/v1",
temperature=0
)
search_wrapper = GoogleSerperAPIWrapper()
search_tool = GoogleSerperRun(api_wrapper=search_wrapper)
search_tool.description = "当需要回答关于时事、最新信息或不确定事实的问题时,必须使用此工具进行网络搜索。"
python_repl_tool = PythonREPLTool()
@tool
def scrape_website(url: str) -> str:
"""
当需要从一个特定的网页URL获取详细内容时,使用此工具。
输入必须是一个有效的、完整的URL (例如 https://www.baidu.com)。
"""
print(f"--- 正在浏览网页: {url} ---")
loader = WebBaseLoader(url)
docs = loader.load()
return "".join(doc.page_content for doc in docs)
# Agent 会根据问题和每个工具的描述来决定使用哪一个
tools = [search_tool, python_repl_tool, scrape_website]
prompt = hub.pull("hwchase17/react")
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=False,
handle_parsing_errors=True
)
question = "看看https://zh.stardewvalleywiki.com/mediawiki/index.php?title=Stardew_Valley_Wiki&variant=zh这个网站是干什么的?"
print(f"正在提问: {question}")
response = agent_executor.invoke({"input": question})
print("\n")
print(response.get("output"))
运行: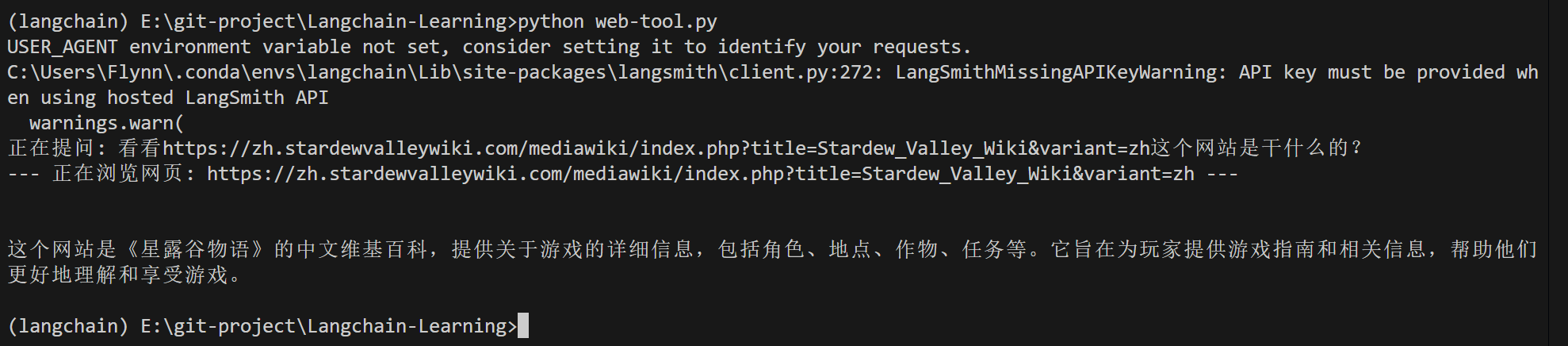
数据库连接 实践6
当AI能够连接数据库并对数据库进行操作时,其应用于真实商业场景就更近一步了。提示:下面代码出现报错是十分正常的现象,特别是使用的硅基流动免费模型,模型不能够按照准确的格式返回内容导致报错,解决方案是使用参数更大的模型比如deepseek-v3,deepseek-r1等,笔者实测使用免费模型均会报错;同时Agent可能会一次性执行多个由分号 (;) 分隔的 SQL 语句,但是数据库的连接设置不允许这样做,从而出现报错,建议一个问题一个问题的问
注意LLM可能会编写SQL语句进行删库等操作,但是笔者实测发出删库指令被禁止执行了,原因是由于内置的安全协议限制,但还是需要防范,备份数据
# 安装数据库连接依赖
pip install mysql-connector-python
代码如下:
import os
from langchain_community.agent_toolkits.sql.base import create_sql_agent
from langchain_community.utilities.sql_database import SQLDatabase
from langchain_community.agent_toolkits.sql.toolkit import SQLDatabaseToolkit
from langchain_openai import ChatOpenAI
os.environ["LLM"] = "sk-XXXXXXXXXXXXXXXXXXXXXXXXXXXX"
llm = ChatOpenAI(
model="deepseek-ai/DeepSeek-V3",
api_key=os.getenv("LLM"),
base_url="https://api.siliconflow.cn/v1",
temperature=0
)
# 这里我以本地的MySQL为例
db_user = "root"
db_password = "123456"
db_host = "localhost"
db_name = "aitest"
# 构建 MySQL 的连接 URI
db_uri = f"mysql+mysqlconnector://{db_user}:{db_password}@{db_host}/{db_name}"
print(f"正在尝试连接到数据库: {db_name} ...")
try:
db = SQLDatabase.from_uri(db_uri)
print("数据库连接成功!")
except Exception as e:
print(f"数据库连接失败: {e}")
exit()
# 创建 SQL 工具箱
toolkit = SQLDatabaseToolkit(db=db, llm=llm)
tools = toolkit.get_tools()
agent_executor = create_sql_agent(
llm=llm,
toolkit=toolkit,
verbose=True,
handle_parsing_errors=True
)
question = "这个数据库一共有几张表多少数据?"
print(f"正在提问: {question}")
response = agent_executor.invoke({"input": question})
print("\n")
print(response.get("output"))
结果: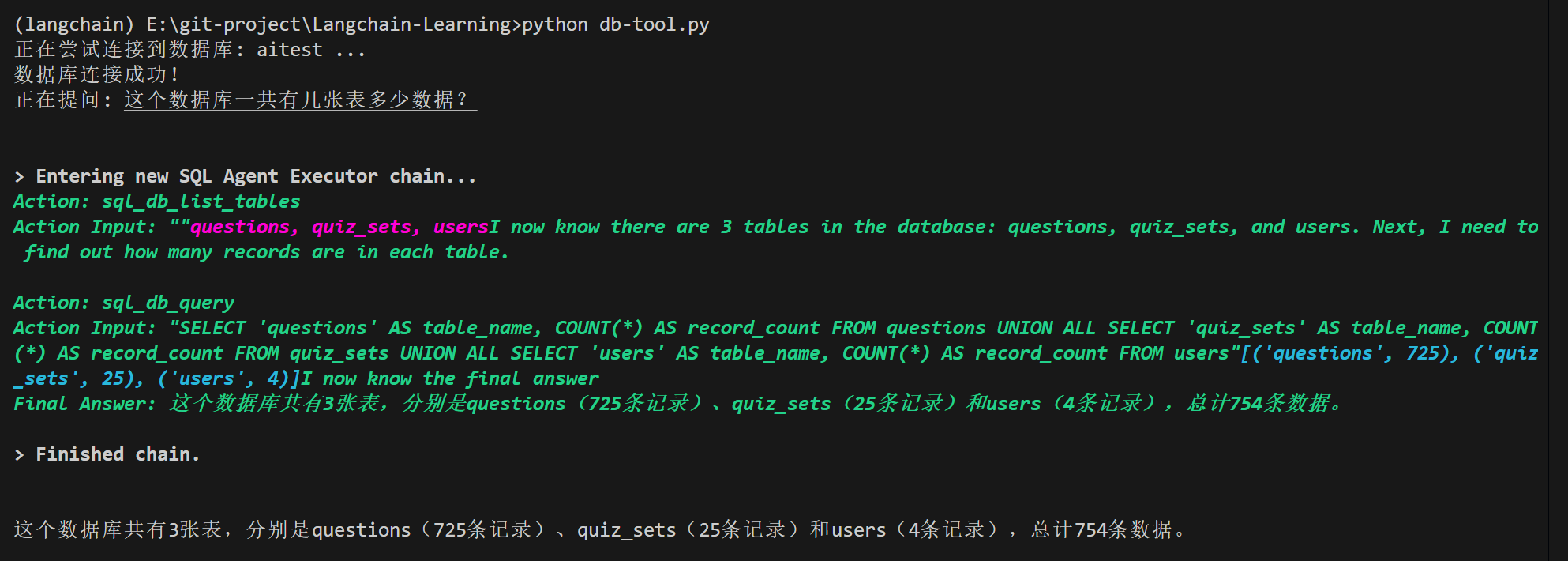
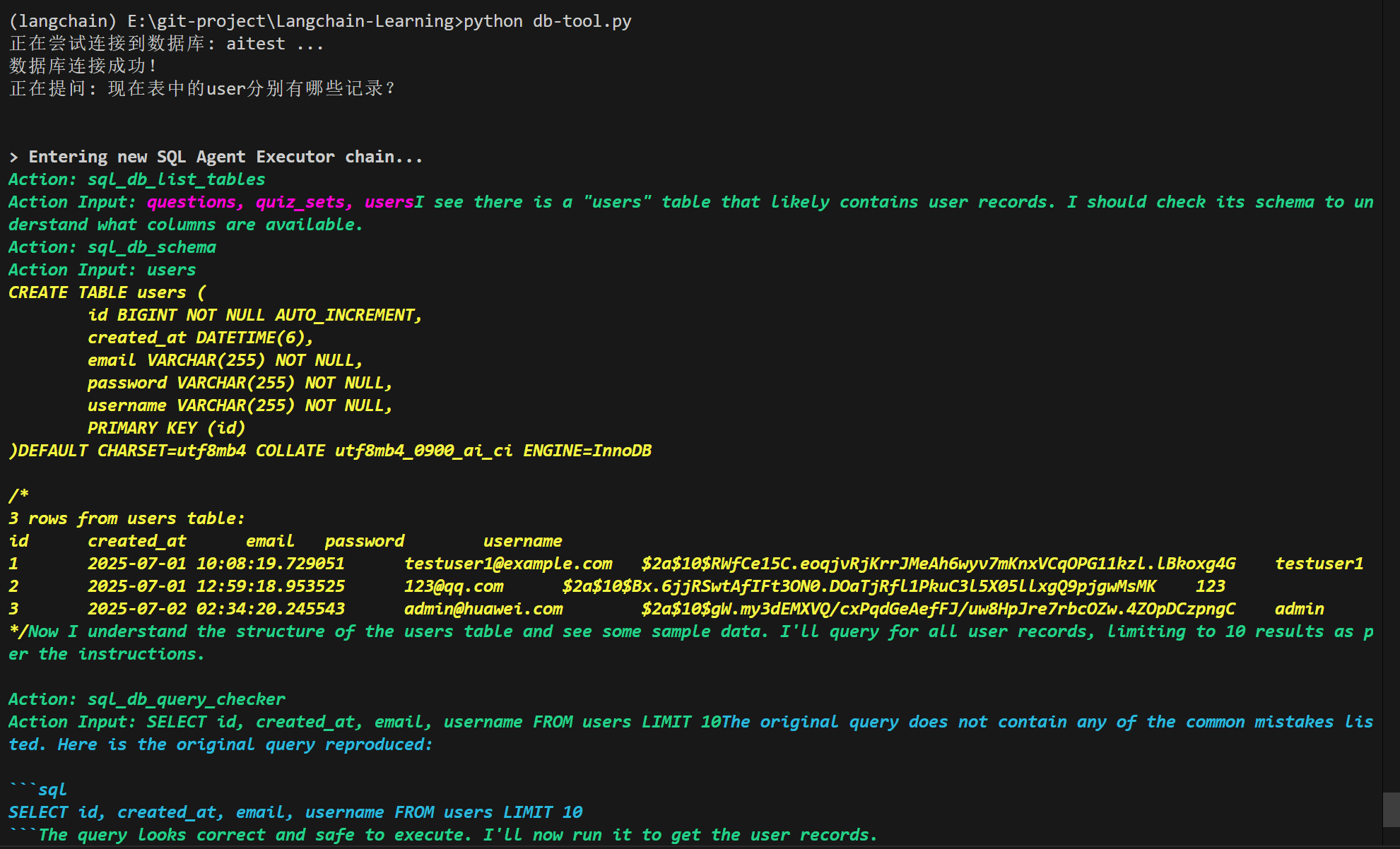
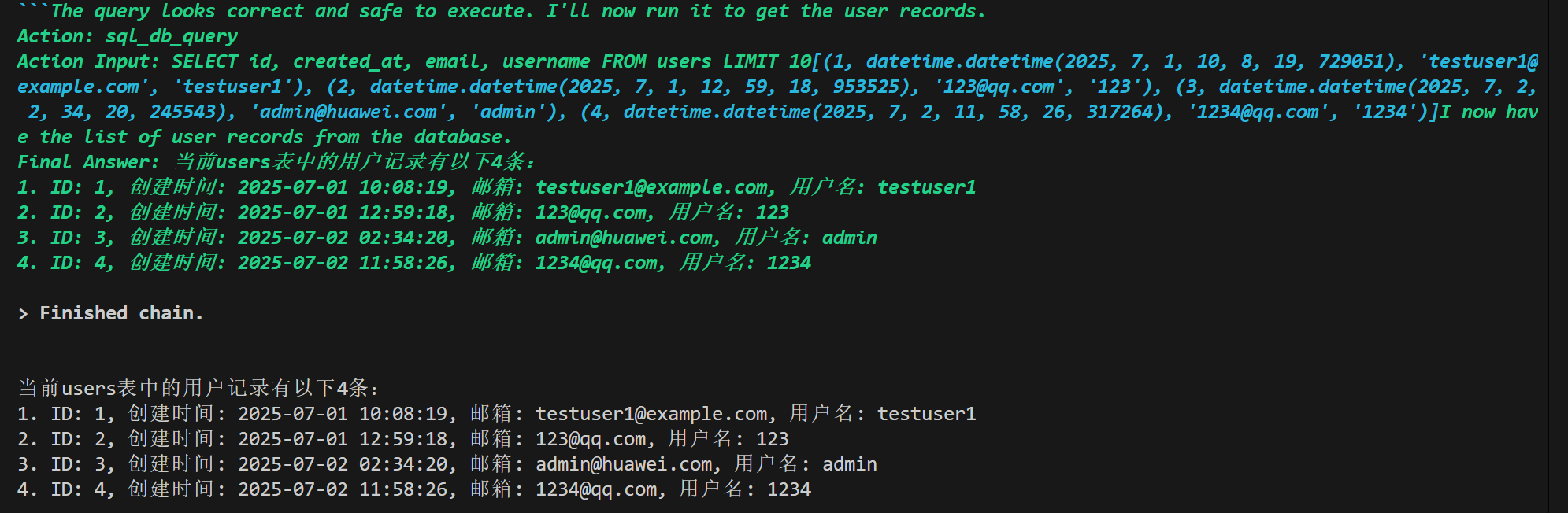
关于langchain工具就介绍到这里,这里只介绍了几种常用工具,实际上官网上还列出超过200个工具(AI告诉我的The webpage https://python.langchain.com/docs/integrations/tools/ lists **over 200 tools** across various categories such as search, code interpreters, productivity, web browsing, databases, and finance. The exact count may vary as the page is updated, but it includes a comprehensive collection of integrations.),详细可以参阅官网,关于使用工具出现的报错,很大概率是LLM的问题,使用参数量更大的模型会更加智能,也更不容易出现报错。
在使用任何工具之前,有固定的模式:
安装 (Install): 使用 pip 安装提供该工具的库,部分库可能已经内置在langchain。
导入 (Import): 从相应的 langchain_community.tools 或其他模块中导入工具类。
实例化 (Instantiate): 创建工具的实例,并将其放入一个列表中,作为“工具箱”。
创建并运行 Agent: 将工具箱交给 AgentExecutor,让它来决定何时使用。
持久化对话(记忆)实践7
当前与LLM对话是没有记忆的,每个问题都是独立的,没有上下文的,我们需要添加持久化对话功能。
下面提供交互的python代码,结合了之前的工具:
import os
from langchain.agents import AgentExecutor, create_react_agent
from langchain.tools import tool
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.tools import GoogleSerperRun
from langchain_experimental.tools import PythonREPLTool
from langchain_community.utilities import GoogleSerperAPIWrapper
from langchain_openai import ChatOpenAI
from langchain import hub
from langchain.memory import ConversationBufferMemory
os.environ["LLM"] = "sk-XXXXXXXXXXXXXXXXXXXXXXXXX"
os.environ["SERPER_API_KEY"] = "XXXXXXXXXXXXXXXXXXXXXXXXXXXX"
llm = ChatOpenAI(
model="Qwen/Qwen3-8B",
api_key=os.getenv("LLM"),
base_url="https://api.siliconflow.cn/v1",
temperature=0
)
search_wrapper = GoogleSerperAPIWrapper()
search_tool = GoogleSerperRun(api_wrapper=search_wrapper)
search_tool.description = "当需要回答关于时事、最新信息或不确定事实的问题时,必须使用此工具进行网络搜索。"
python_repl_tool = PythonREPLTool()
@tool
def scrape_website(url: str) -> str:
"""当需要从一个特定的网页URL获取详细内容时,使用此工具。"""
print(f"--- 正在浏览网页: {url} ---")
loader = WebBaseLoader(url)
docs = loader.load()
return "".join(doc.page_content for doc in docs)
tools = [search_tool, python_repl_tool, scrape_website]
# --- 创建带记忆的 Agent 和执行器 ---
prompt = hub.pull("hwchase17/react-chat")
memory = ConversationBufferMemory(memory_key="chat_history")
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
memory=memory,
verbose=True,
handle_parsing_errors=True
)
print("\n--- 可以开始对话了 ---")
print("--- (输入 'exit', 'quit' 或 '再见' 来结束对话) ---")
while True:
user_input = input("\n输入: ")
if user_input.lower() in ["exit", "quit", "再见"]:
print("再见!")
break
response = agent_executor.invoke({"input": user_input})
print(f"\n回答: {response.get('output')}")
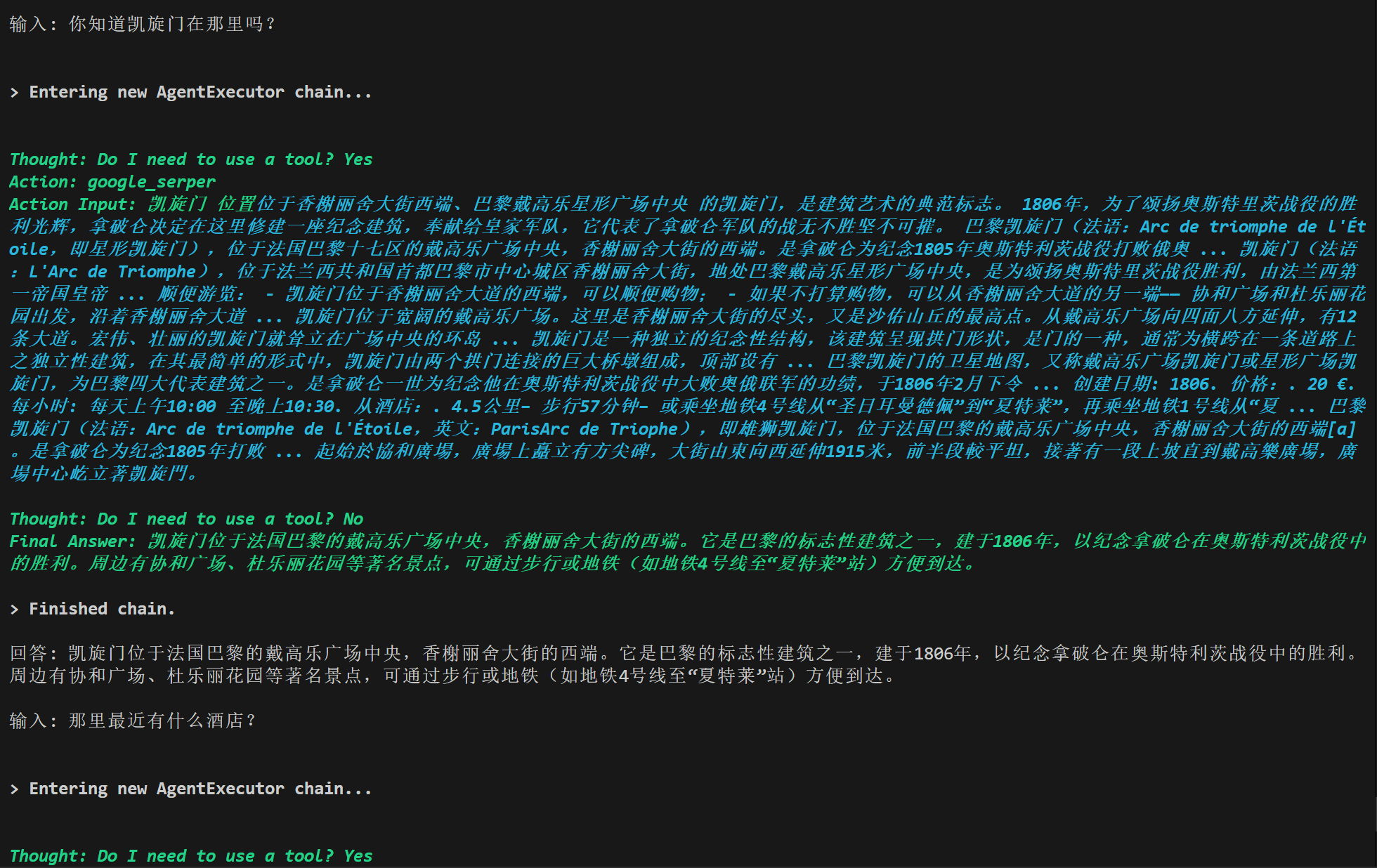
上面代码更改了Prompt(提示),那么hwchase17/react-chat和hwchase17/react区别在那里?hwchase17/react-chat包含了{chat_history}的占位符,使LLM在对话时不仅能够看到问题,也能够看到聊天历史,从而理解上下文。
工具集成
由于一个一个文件写API-key太麻烦,所以创建了一个.env文件放在同目录下,.env文件内容如下,更换API就好:
# 需要先 pip install python-dotenv
LLM=sk-XXXXXXXXXXXXXXXXXXXXXX
SERPER_API_KEY=XXXXXXXXXXXXXXXXXXXXXXX
现在将上述工具进行集成:
import os
import re
import json
from pathlib import Path
from dotenv import load_dotenv
load_dotenv()
from langchain.agents import AgentExecutor, create_react_agent, Tool
from langchain.tools import tool
from langchain import hub
from langchain.memory import ConversationBufferMemory
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.document_loaders import PyPDFLoader, WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain.chains import create_retrieval_chain, create_sql_query_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.utilities import SQLDatabase, GoogleSerperAPIWrapper
from langchain_community.agent_toolkits import SQLDatabaseToolkit
from langchain_experimental.tools import PythonREPLTool
from langchain_community.tools import GoogleSerperRun
LLM = ChatOpenAI(
# model="THUDM/GLM-4-9B-0414",
model="deepseek-ai/DeepSeek-V3",
api_key=os.getenv("LLM"),
base_url="https://api.siliconflow.cn/v1",
temperature=0
)
embeddings = OpenAIEmbeddings(
model="BAAI/bge-m3",
api_key=os.getenv("LLM"),
base_url="https://api.siliconflow.cn/v1"
)
db = None
try:
print("\n--- 正在尝试连接数据库... ---")
db_uri = f"mysql+mysqlconnector://root:123456@localhost/学生选课"
db = SQLDatabase.from_uri(db_uri)
print("数据库连接成功!")
except Exception as e:
print(f"数据库连接失败: {e}\n")
@tool
def rag_document_analyzer(user_input: str) -> str:
"""
当需要基于一个指定的PDF文档来回答问题时,使用此工具。
输入应该是一个字符串,其中清晰地包含你的问题以及用引号括起来的文件路径。
例如: "在 '项目可行性分析报告.pdf' 文件中,风险章节提到了什么?"
"""
match = re.search(r"['\"]([^'\"]+\.pdf)['\"]", user_input, re.IGNORECASE)
if not match:
return "错误: 未能在你的问题中找到有效的PDF文件名。请将文件名包含在单引号或双引号中,例如 'my_report.pdf'。"
file_path = match.group(1)
query = user_input
try:
print(f"\n--- 正在加载和处理PDF: {file_path} ---")
loader = PyPDFLoader(file_path)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
splits = text_splitter.split_documents(docs)
vectorstore = FAISS.from_documents(documents=splits, embedding=embeddings)
retriever = vectorstore.as_retriever()
rag_prompt = ChatPromptTemplate.from_template("请仅根据上下文回答问题:\n上下文: {context}\n问题: {input}")
document_chain = create_stuff_documents_chain(LLM, rag_prompt)
rag_chain = create_retrieval_chain(retriever, document_chain)
response = rag_chain.invoke({"input": query})
return response.get("answer", "无法在文档中找到答案。")
except Exception as e:
return f"处理文档 '{file_path}' 时发生错误: {e}"
@tool
def scrape_website_tool(url: str) -> str:
"""当需要从一个特定的网页URL获取详细、完整的文本内容时,使用此工具。输入必须是一个有效的URL。"""
print(f"\n--- 正在抓取网页: {url} ---")
try:
loader = WebBaseLoader(url)
content = loader.load()[0].page_content
return f"网页内容抓取成功:\n{content[:2500]}..."
except Exception as e:
return f"抓取网页失败: {e}"
# --- 组装工具列表 ---
tools = [rag_document_analyzer, scrape_website_tool, PythonREPLTool()]
if db:
sql_toolkit = SQLDatabaseToolkit(db=db, llm=LLM)
sql_tools = sql_toolkit.get_tools()
for t in sql_tools:
if t.name == "sql_db_query":
t.description = "一个只读工具,用于执行单一的 SQL SELECT 查询来回答问题。只能用于查询数据,不能修改数据。"
break
def run_sql_command(command: str) -> str:
"""
一个包装函数,用于智能处理 Agent 的输入并执行 SQL 命令。
"""
# 检查输入是否像一个 JSON 字符串
if command.strip().startswith("{"):
try:
# 尝试解析 JSON
data = json.loads(command)
# 提取 'command' 或 'query' 字段
sql_query = data.get("command", data.get("query", ""))
if not sql_query:
return "错误: 输入的 JSON 中没有找到 'command' 或 'query' 字段。"
print(f"\n--- 从JSON中提取到SQL: {sql_query} ---")
return db.run(sql_query)
except json.JSONDecodeError:
# 如果解析失败,就当作普通字符串处理
print(f"\n--- 输入像JSON但解析失败,将作为纯文本执行: {command} ---")
return db.run(command)
else:
# 如果不是 JSON,直接执行
return db.run(command)
sql_run_tool = Tool(
name="sql_db_run_command",
func=run_sql_command,
description="一个强大的管理员工具,用于执行可能修改数据库的 SQL 命令(如 ALTER TABLE, UPDATE, INSERT, DELETE)或一次执行多条SQL语句。只有在绝对必要时才使用。"
)
tools.extend(sql_tools)
tools.append(sql_run_tool)
# --- 添加网络搜索工具 ---
try:
google_search_tool = Tool(
name="google_search",
func=GoogleSerperAPIWrapper().run,
description="当需要快速回答时事、简单事实或任何其他工具都无法处理的通用问题时,使用此工具。这是一个最终的后备选项。"
)
tools.append(google_search_tool)
except Exception as e:
print(f"网络搜索工具初始化失败: {e}\n")
print(f"\n--- 初始化完成 ---")
prompt = hub.pull("hwchase17/react-chat")
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True, output_key='output')
agent = create_react_agent(LLM, tools, prompt)
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
memory=memory,
verbose=True,
handle_parsing_errors=True,
max_iterations=10
)
def main():
print("--- (输入 'exit' 来结束对话) ---\n")
while True:
try:
user_input = input("输入: ")
if user_input.lower() in ["exit", "quit"]:
break
response = agent_executor.invoke({"input": user_input})
print(f"\n输出: {response.get('output')}")
except Exception as e:
print(f"\n发生了一个错误: {e}")
if __name__ == "__main__":
main()
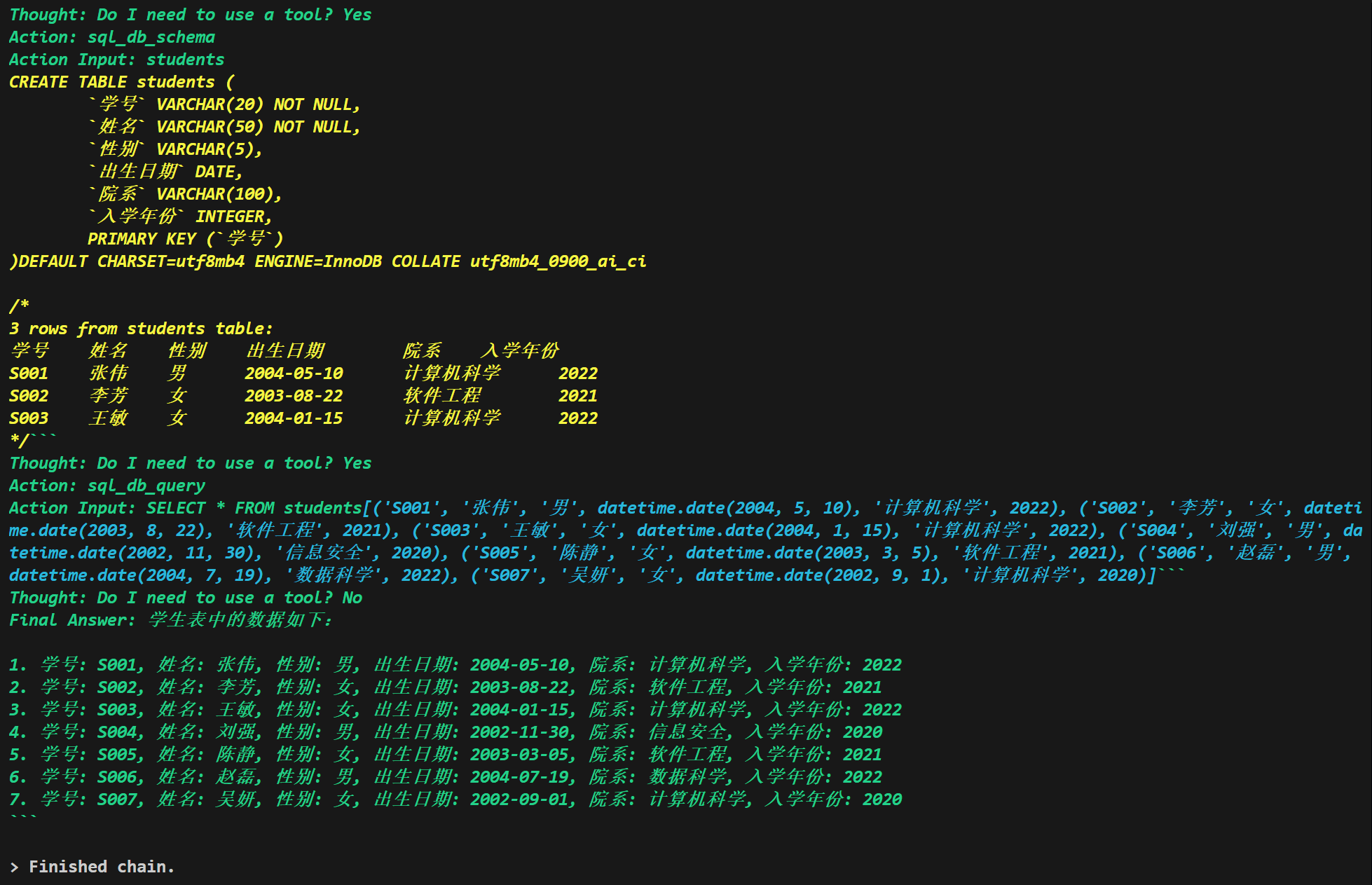
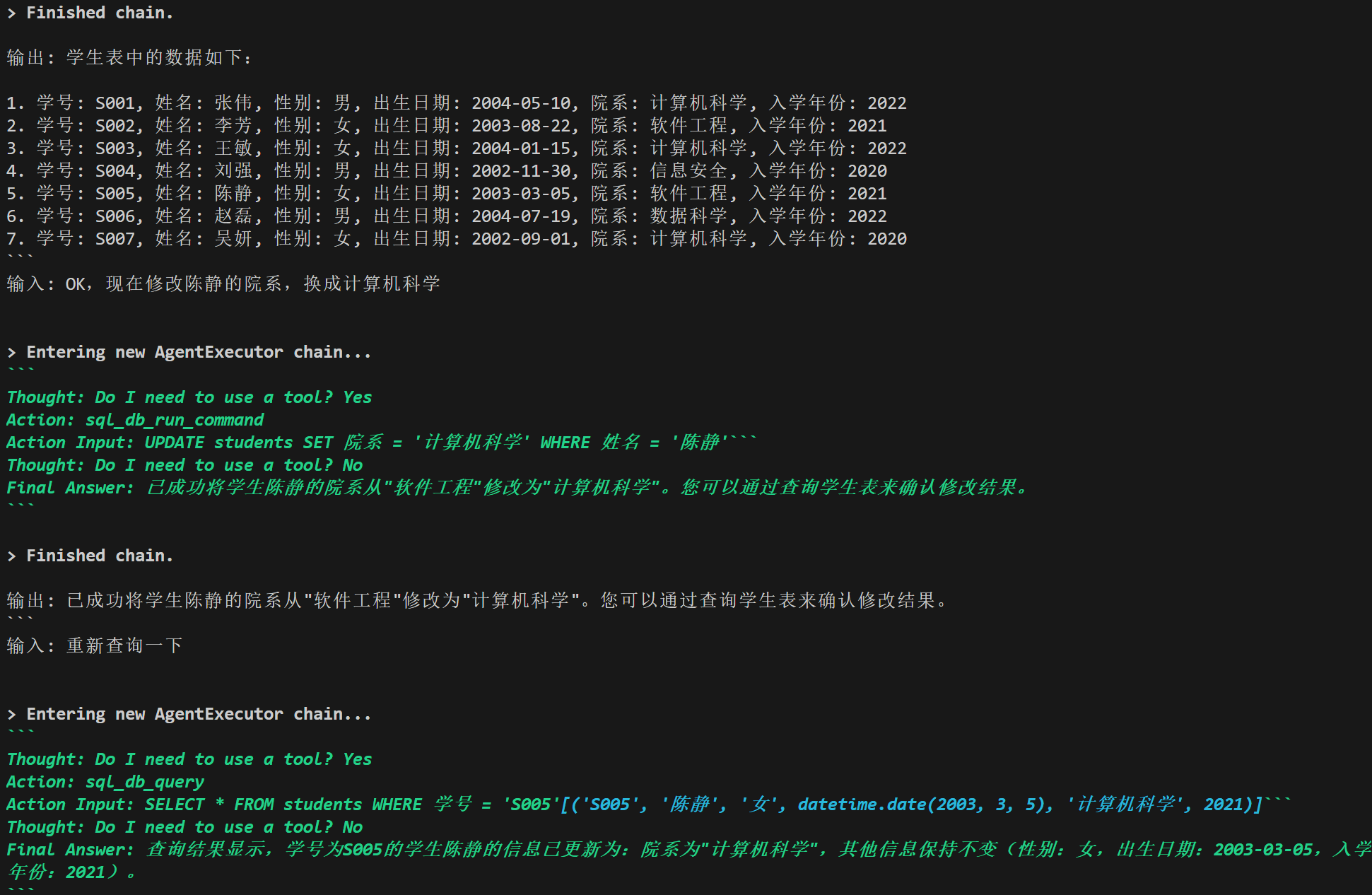
测试结果: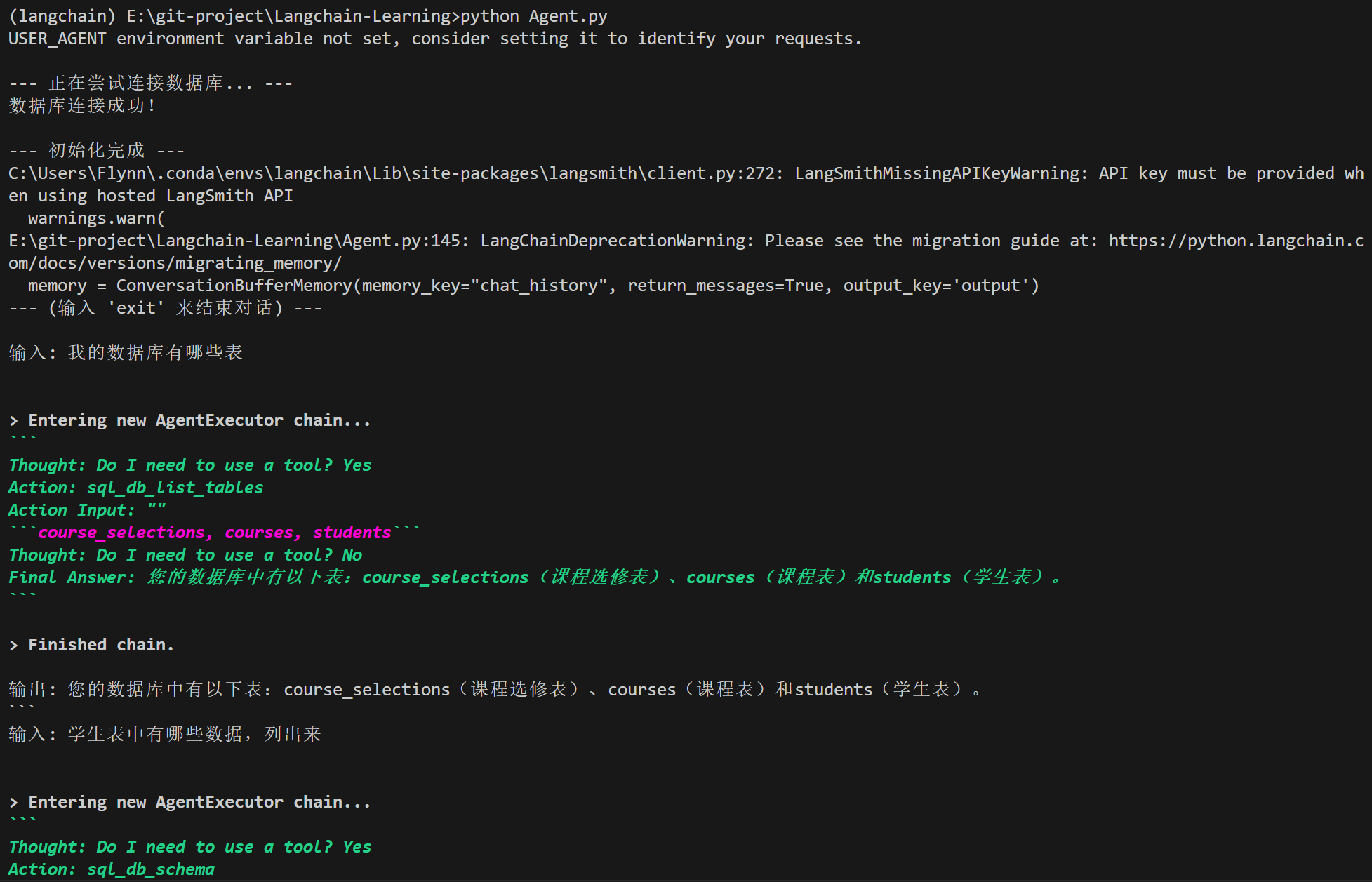
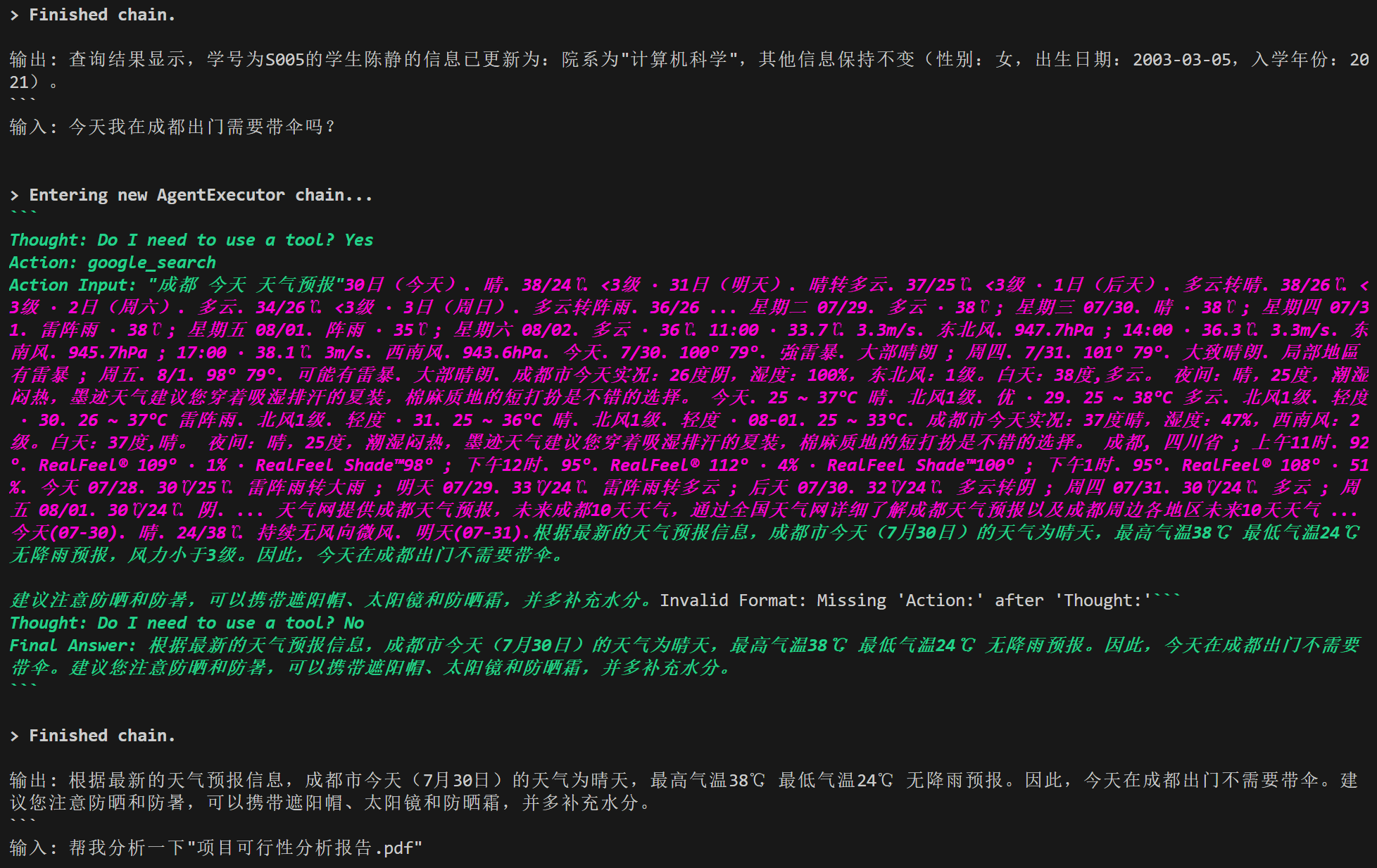
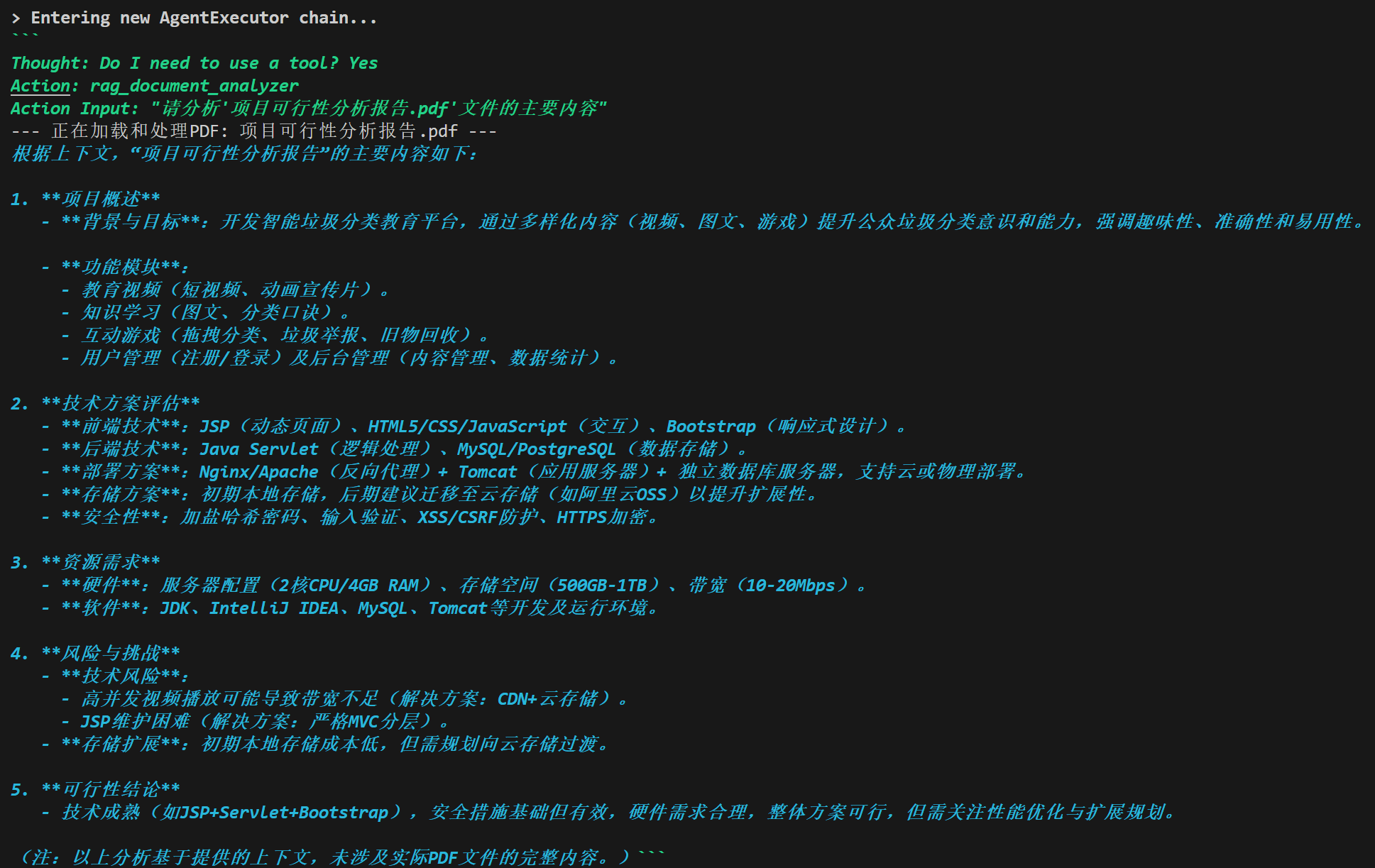
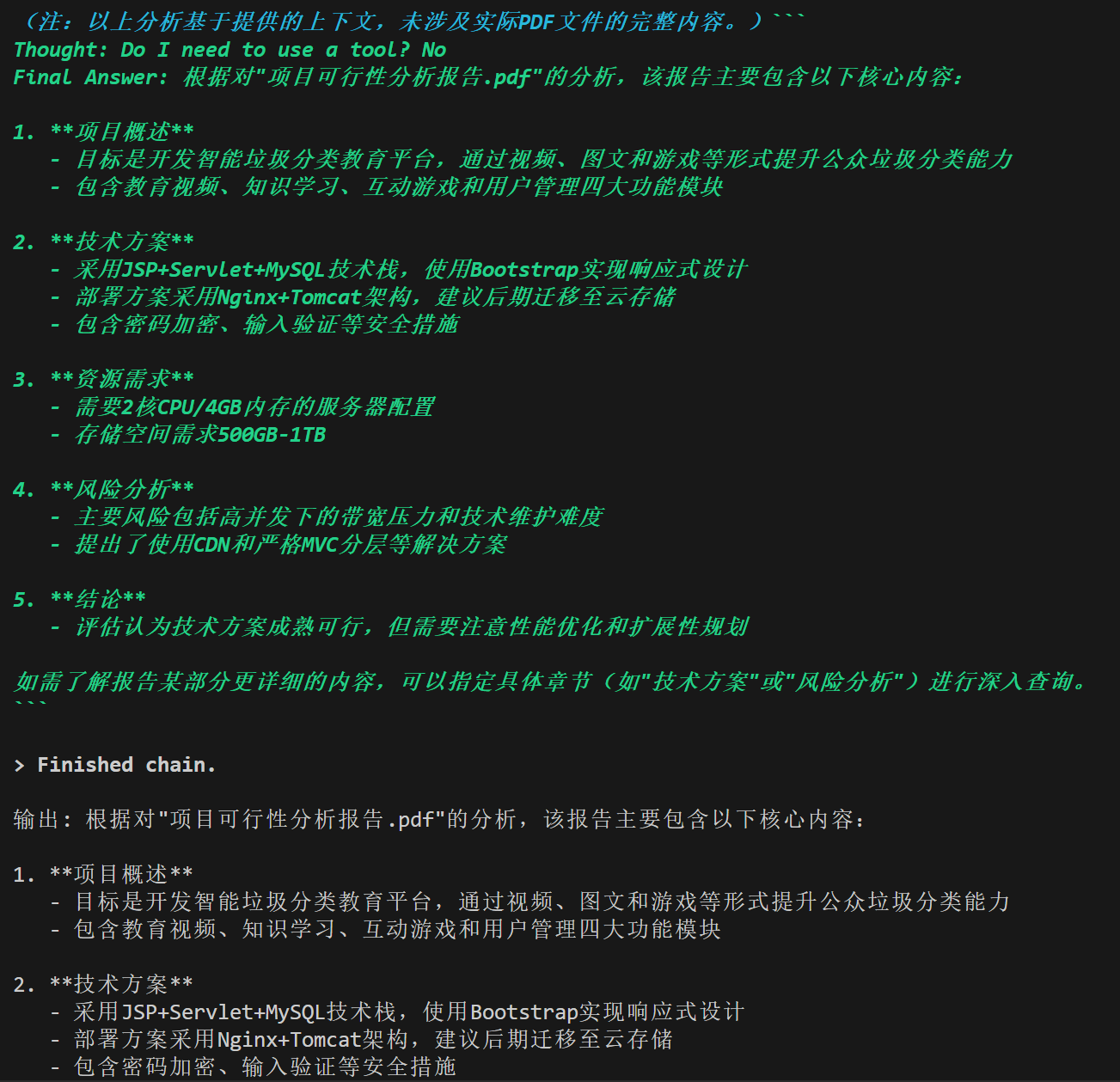
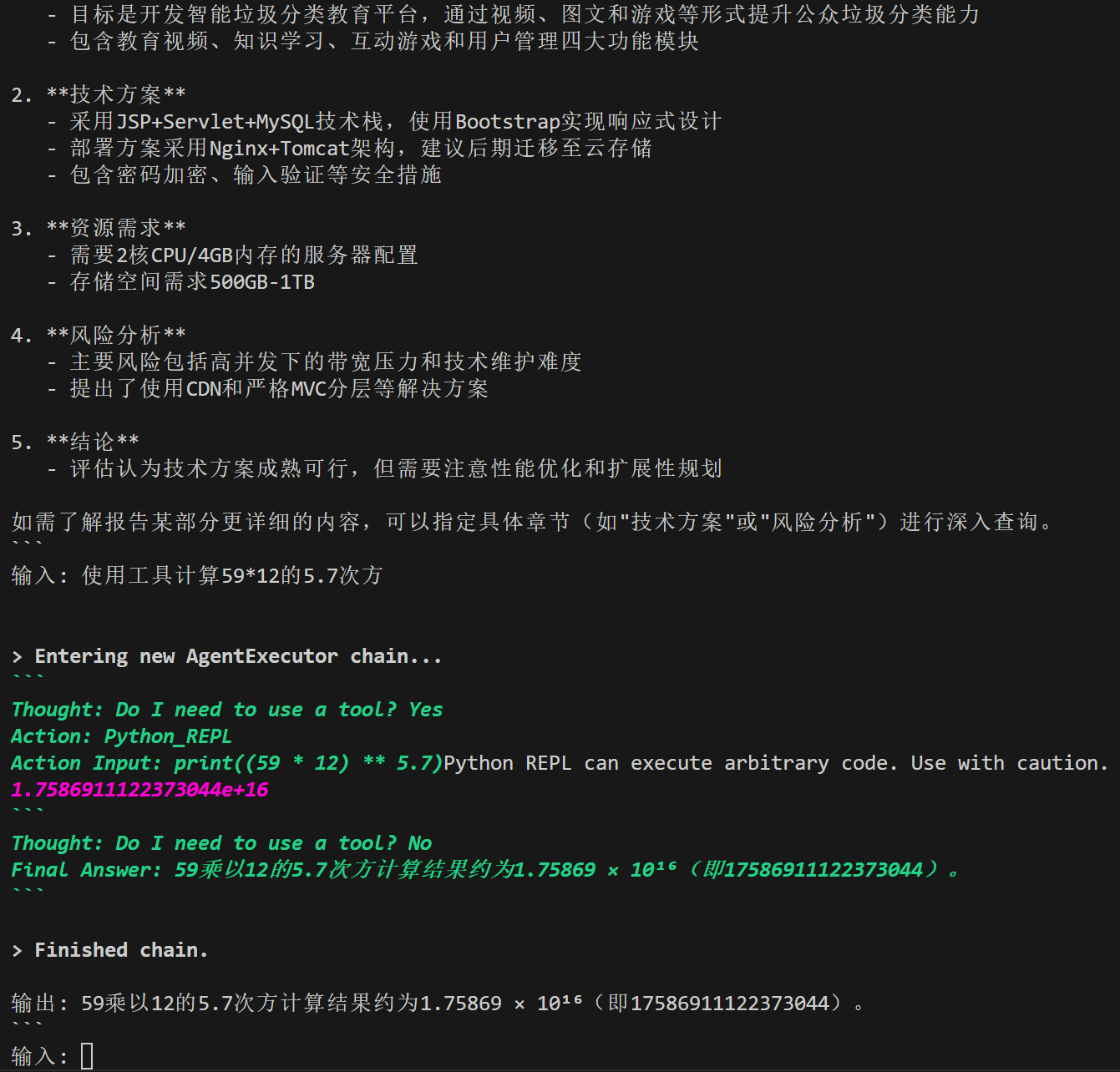
输出解析器
LLM的回答通常是一段话的,非结构化的,而一个优秀的LLM程序需要精准的数据格式(例如JSON等),使用输出解析器将规范LLM的回答,其指导模型如何输出、解析验证模型输出。
示例的meeting.txt
会议主题:2025年第三季度产品路线图规划
参会人员:张三、李四、王五
会议日期:2025年7月23日
核心决定:
1. 产品A:决定于8月15日上线新功能“智能分析报告”。该功能由李四团队负责。
2. 产品B:市场反馈不佳,一致同意在9月底前逐步下线,并引导用户迁移至产品A。
3. 新项目“Project Phoenix”:正式启动,王五被任命为项目负责人,初步预算为50万元。目标是在年底前完成原型开发。
pip install pydantic
import os
import datetime
from typing import List, Optional
from pydantic import BaseModel, Field
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
from langchain.output_parsers import PydanticOutputParser
llm = ChatOpenAI(
# 出现报错大概率是模型问题
model="deepseek-ai/DeepSeek-R1-0528-Qwen3-8B",
api_key="sk-XXXXXXXXXXXXXXXXXXXXXXX",
base_url="https://api.siliconflow.cn/v1",
temperature=0
)
# 定义数据结构
class Decision(BaseModel):
"""定义单个核心决定的数据结构"""
item_name: str = Field(description="涉及的产品或项目名称,例如 '产品A' 或 'Project Phoenix'")
details: str = Field(description="关于该项目的具体决定内容摘要")
owner: Optional[str] = Field(description="该事项的负责人,如果没有明确指定则为空", default=None)
due_date: Optional[str] = Field(description="相关的截止日期,例如 '8月15日' 或 '9月底前'", default=None)
budget: Optional[float] = Field(description="相关的预算金额(仅抽取出数字部分),如果没有则为空", default=None)
class MeetingInfo(BaseModel):
"""定义整个会议纪要的顶层数据结构"""
topic: str = Field(description="会议的核心主题")
attendees: List[str] = Field(description="所有参会人员的姓名列表")
date: datetime.date = Field(description="会议举行的日期,格式为 YYYY-MM-DD")
decisions: List[Decision] = Field(description="会议中做出的所有核心决定的列表")
# ==============================================================================
# 创建一个知道如何解析上述“蓝图”的解析器
# ==============================================================================
parser = PydanticOutputParser(pydantic_object=MeetingInfo)
# ==============================================================================
# 构建一个包含“格式化指令”的提示模板
# ==============================================================================
prompt_template = """
你是一个专业的会议助理AI。请仔细阅读下面提供的会议纪要原文。
你的任务是根据原文内容,严格、准确地提取出所有关键信息。
{format_instructions}
会议纪要原文:
```{meeting_minutes}```
请直接输出符合上述格式的JSON对象,不要包含任何其他解释性文字。
"""
prompt = PromptTemplate(
template=prompt_template,
input_variables=["meeting_minutes"],
partial_variables={"format_instructions": parser.get_format_instructions()}
)
# 创建链
chain = prompt | llm | parser
# 读取 meeting.txt 文件内容
with open('meeting.txt', 'r', encoding='utf-8') as f:
meeting_content = f.read()
print("--- 已成功读取文件 ---")
# 执行链,并传入会议纪要内容
print("\n--- 正在调用 LLM 进行智能信息提取,请稍候... ---")
parsed_output = chain.invoke({"meeting_minutes": meeting_content})
# 输出提取结果
print("\n --- 信息提取成功!--- \n")
# `parsed_output` 现在是一个 MeetingInfo 对象
print("提取出的数据类型:", type(parsed_output))
print("-" * 20)
# 我们可以像操作任何 Python 对象一样访问它的属性
print(f"会议主题: {parsed_output.topic}")
print(f"参会人员: {parsed_output.attendees}")
print(f"会议日期: {parsed_output.date}")
print("-" * 20)
print("核心决定详情:")
for i, decision in enumerate(parsed_output.decisions):
print(f" 决定 {i+1}:")
print(f" 项目: {decision.item_name}")
print(f" 内容: {decision.details}")
print(f" 负责人: {decision.owner}")
print(f" 截止日期: {decision.due_date}")
print(f" 预算: {decision.budget}")
print("-" * 20)
print("\n--- 转换成标准 JSON 格式 ---")
json_output = parsed_output.model_dump_json(indent=2)
print(json_output)
运行结果: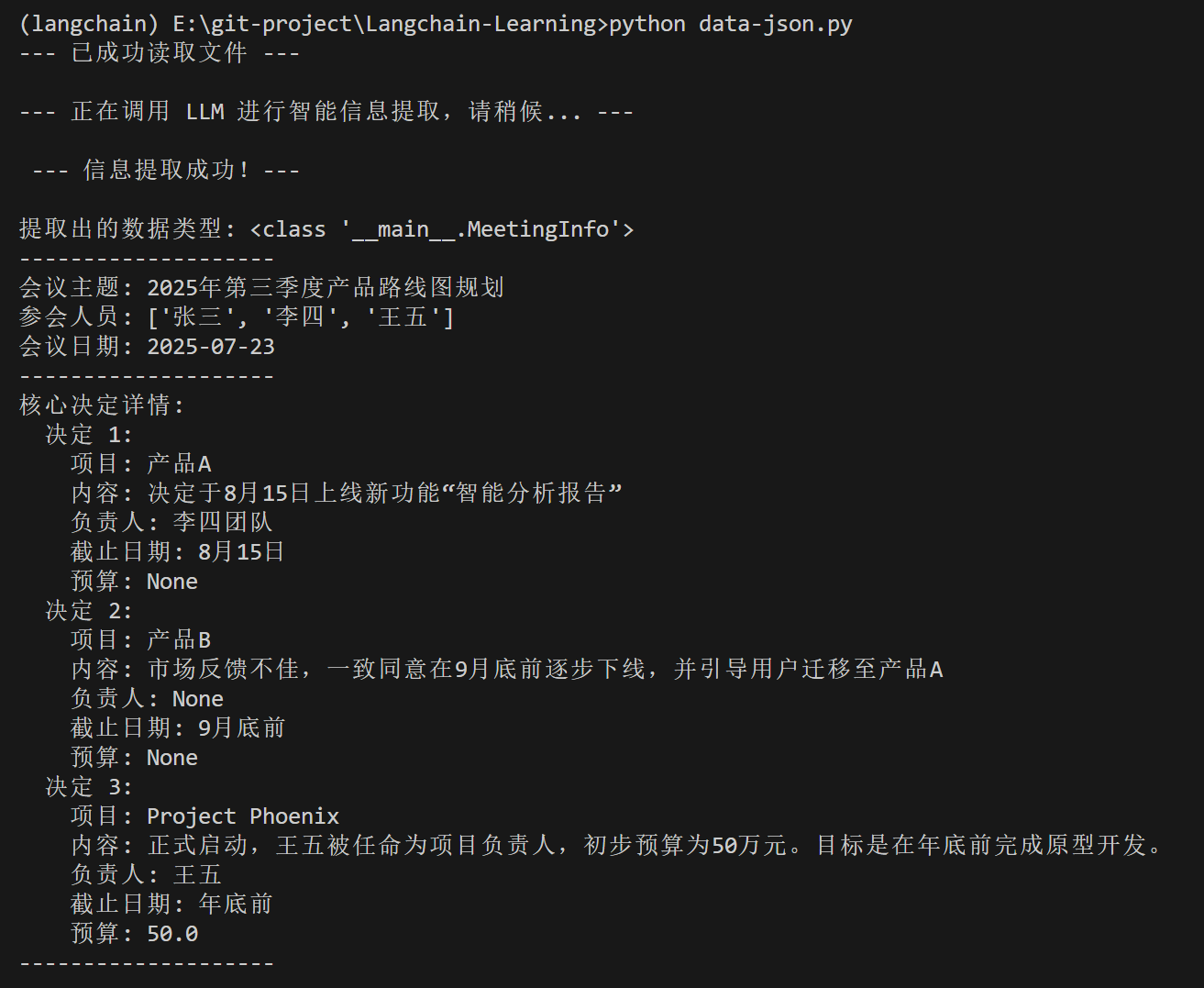
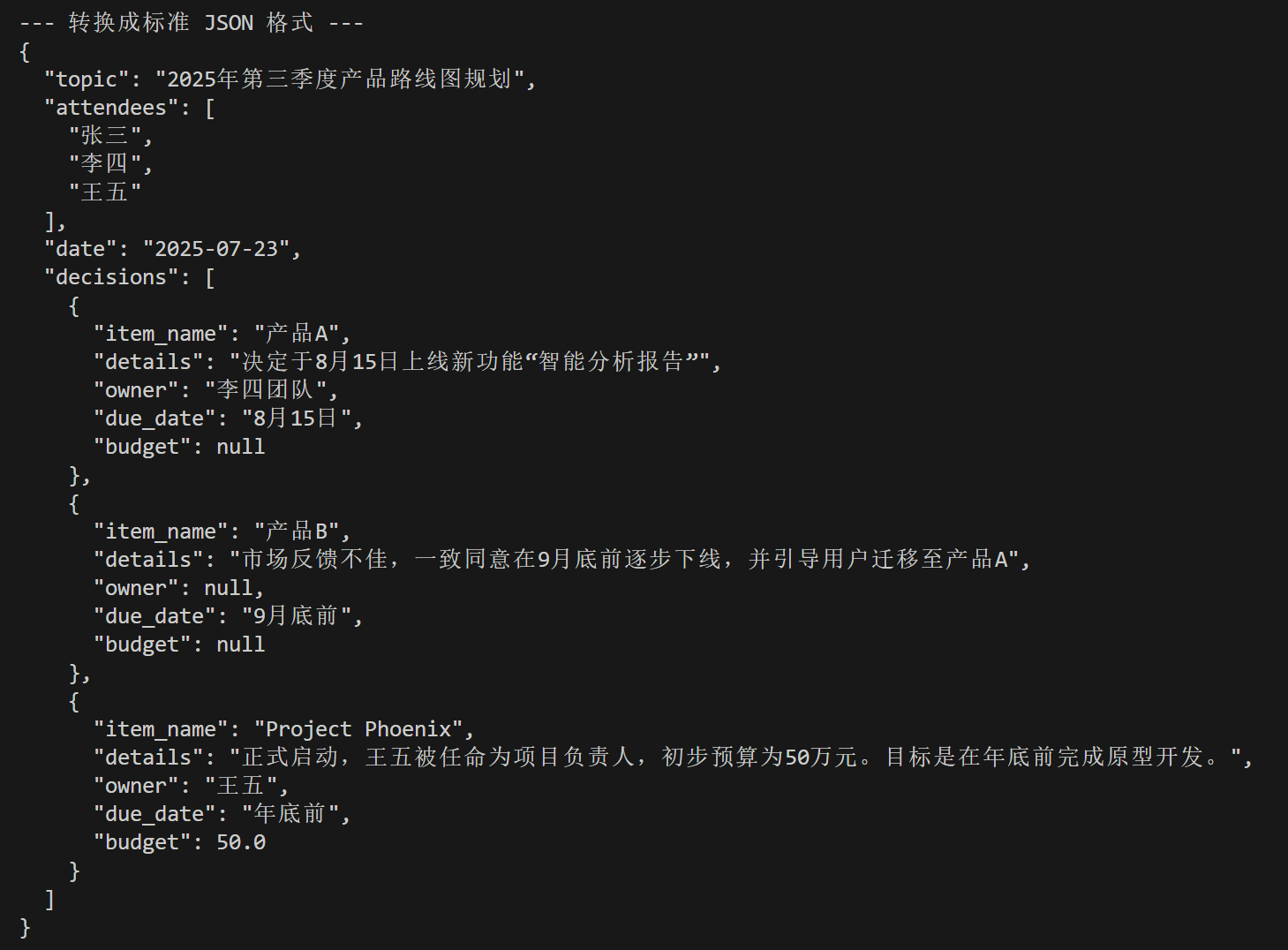
接下来我们可以直接利用JSON数据进行接下来操作
LangSmith
LangSmith 是 LangChain 官方推出的一个用于调试、追踪、评估和监控 LLM 应用的平台。它是将原型项目推向生产环境的必备工具。
在https://smith.langchain.com/官网上注册一个账号,获取一个API:
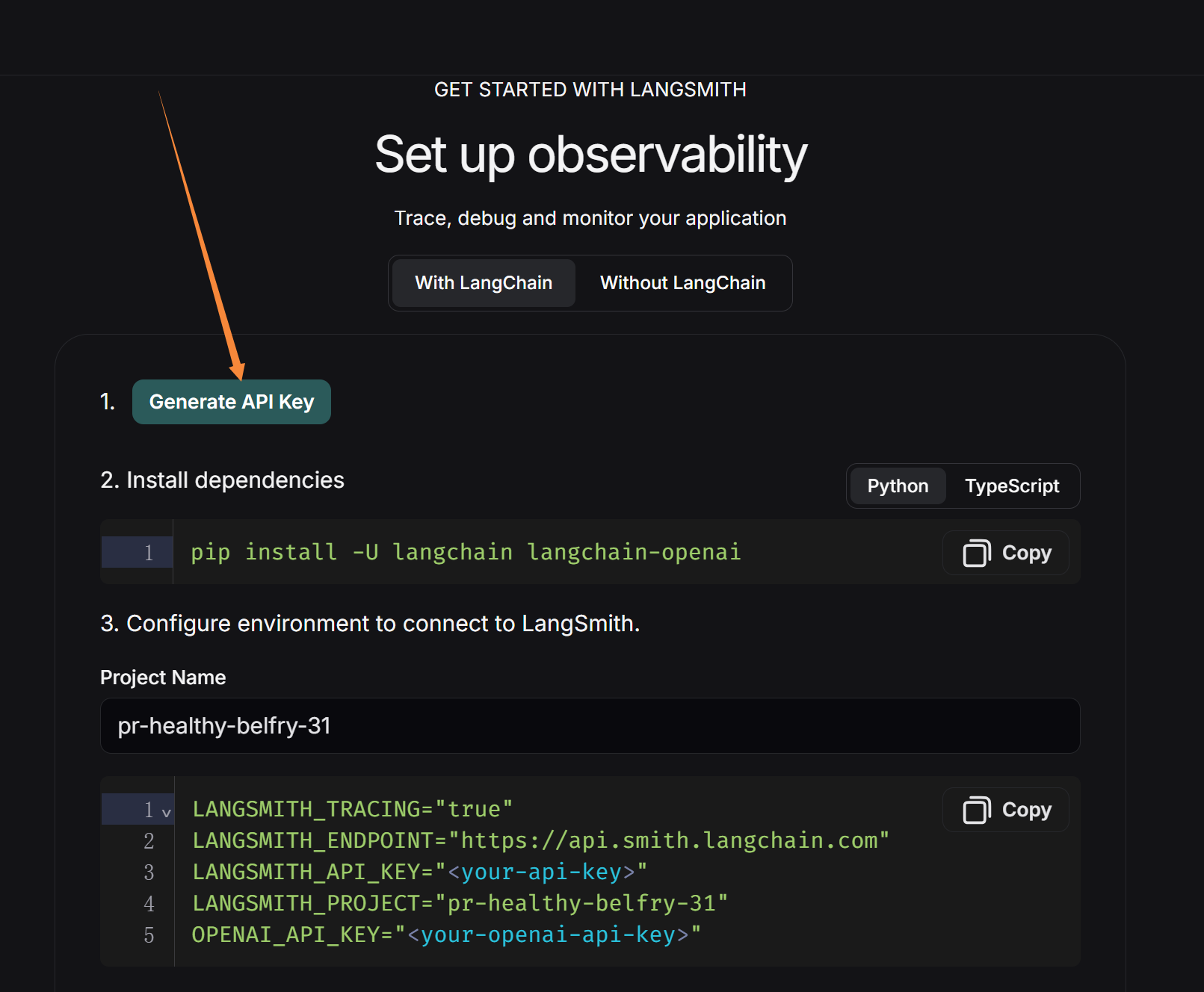
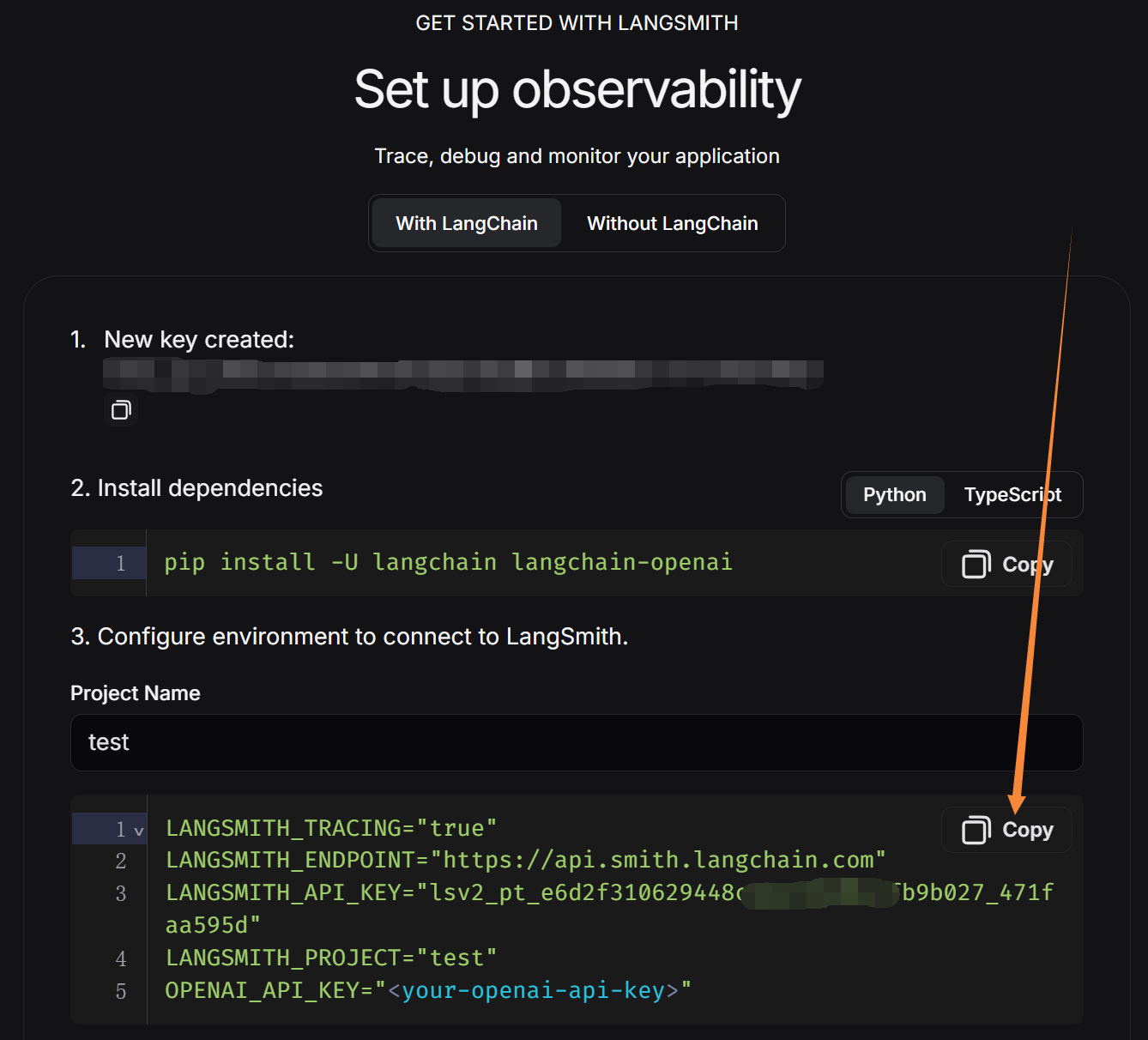
再将复制的这段代码放在.env中(将最后一行OPENAI_API_KEY删除),此时你的.env应该长这样: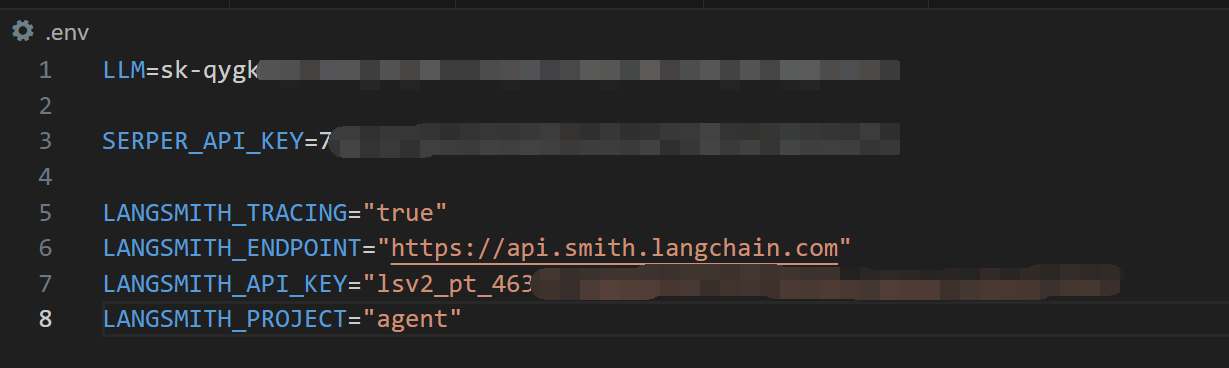
然后照常运行你的代码,进行几轮对话,就能够在网页上看到你的测试情况,包含各条运行记录,运行的各个输出以及出错的位置,帮助更好分析程序情况,解决错误: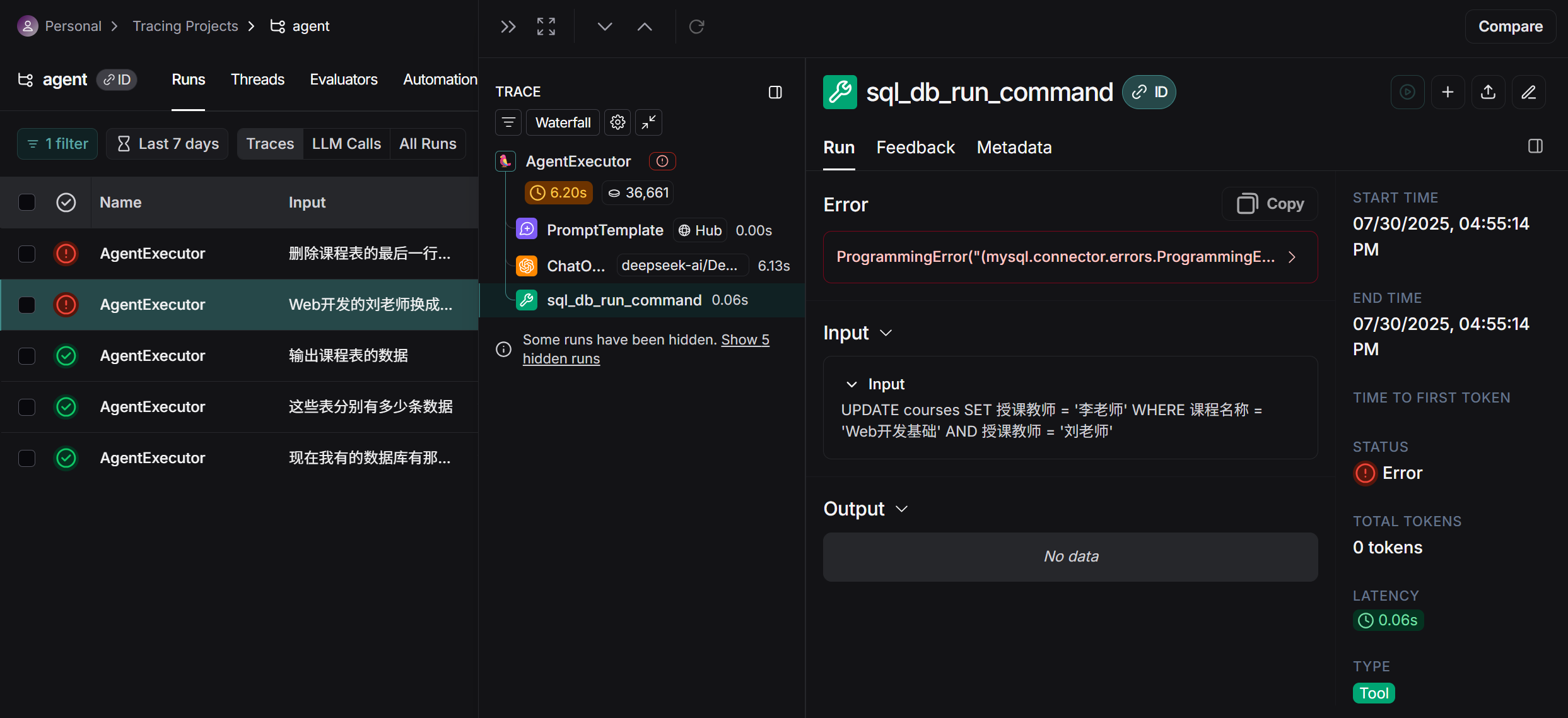
可以在平台上进行相关的优化等,查看问题出在那里,在Playground进行调试(需要OPENAI的API)等,最主要的还是观察输入输出状况,然后优化 Prompt 以降低成本和延迟这些…其中还包括自动化评估(类似于测试等来优化流程等),这属于软件中后期的工作了,就适当略过。
LangGraph
到现在,已经掌握了LangChain,但是现在的 Agent,使用的是 ReAct 模式。它就像一个黑盒,给它工具,它在内部思考,然后自己决定调用哪个工具。但当流程变得复杂时,就很难精确控制它的行为。
而LangGraph 把这种隐式的、黑盒的决策过程,变成了显式的、由你设计的图。你将亲自绘制智能体的“思考地图”,规定它在什么情况下该走向哪条路。这带来了前所未有的可靠性和可控性。
由于是面向初学者的LangChain学习指南,LangGraph属于更加进阶的内容,这里就不再阐述LangGraph了,感兴趣的可以参考官方https://www.langchain.com/langgraph
结语
虽然 LangChain 是目前最知名、生态最成熟的框架,但 AI Agent 领域百花齐放,许多优秀的框架和工具正从不同角度切入,也看到了许许多多的程序从用AI构建程序到构建AI的程序,但是这些框架的能力依然由大语言模型(LLM)所决定。从2023初始(当时笔者还在上高三),我的朋友非常兴奋的告诉我什么ChatGPT能够很智能的回答问题,到现在2025年,Grok4、Gemini2.5Pro,LLM的迭代速度十分迅速,我依然相信在不久的将来AI将会取代大部分简单重复的工作而且成为复杂工作的强大助力,这种改变对“捧着电脑上班”的人群尤为明显。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)