云服务器yolov11训练入门
云服务器yolov11训练
1.GPU平台
这块我用的是AutoDL.
这里我打算租用3090来训练数据集。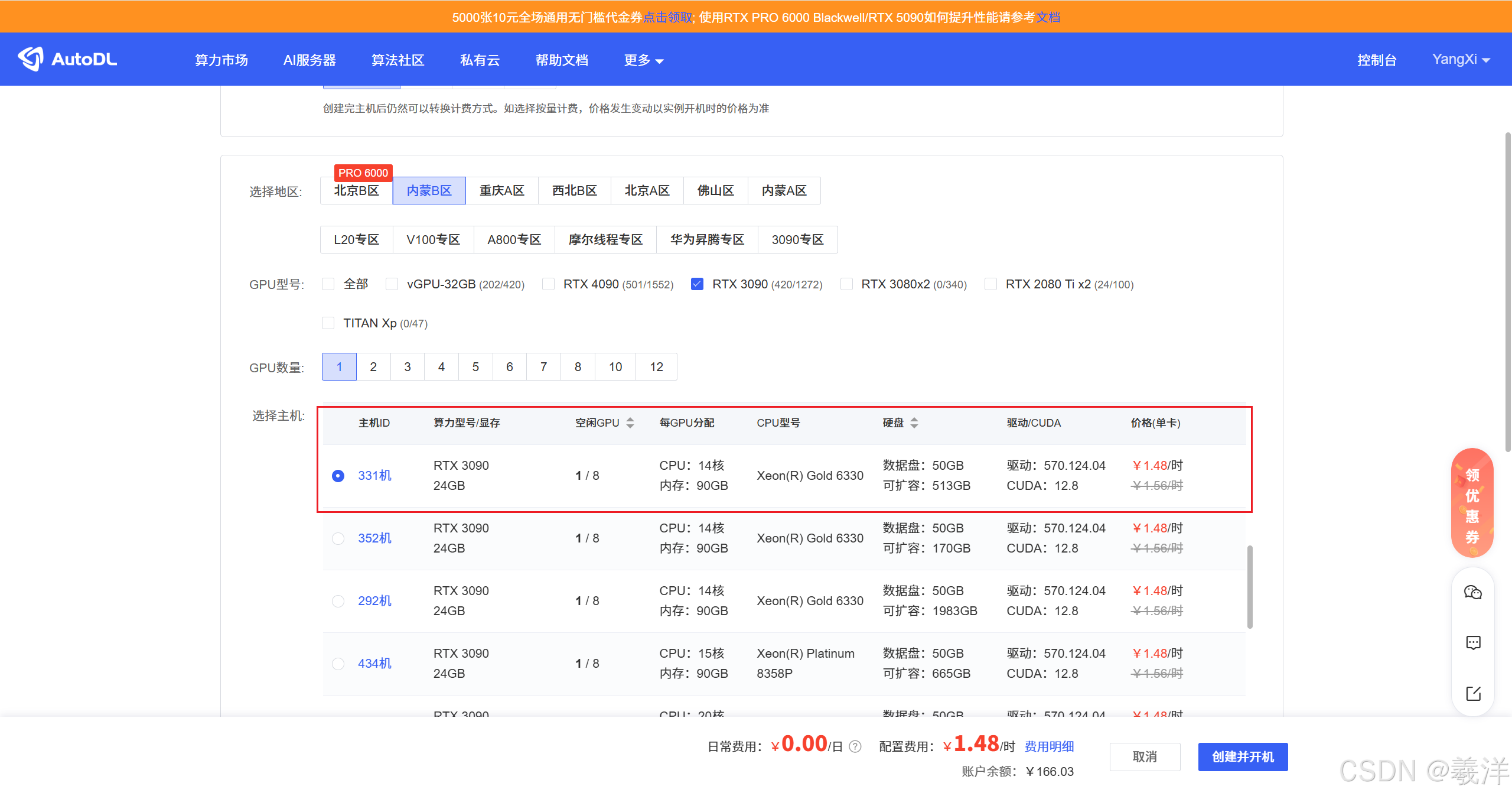
第一次选择基础镜像即可,这里我选择得是pytorch2.0.0,cuda11.8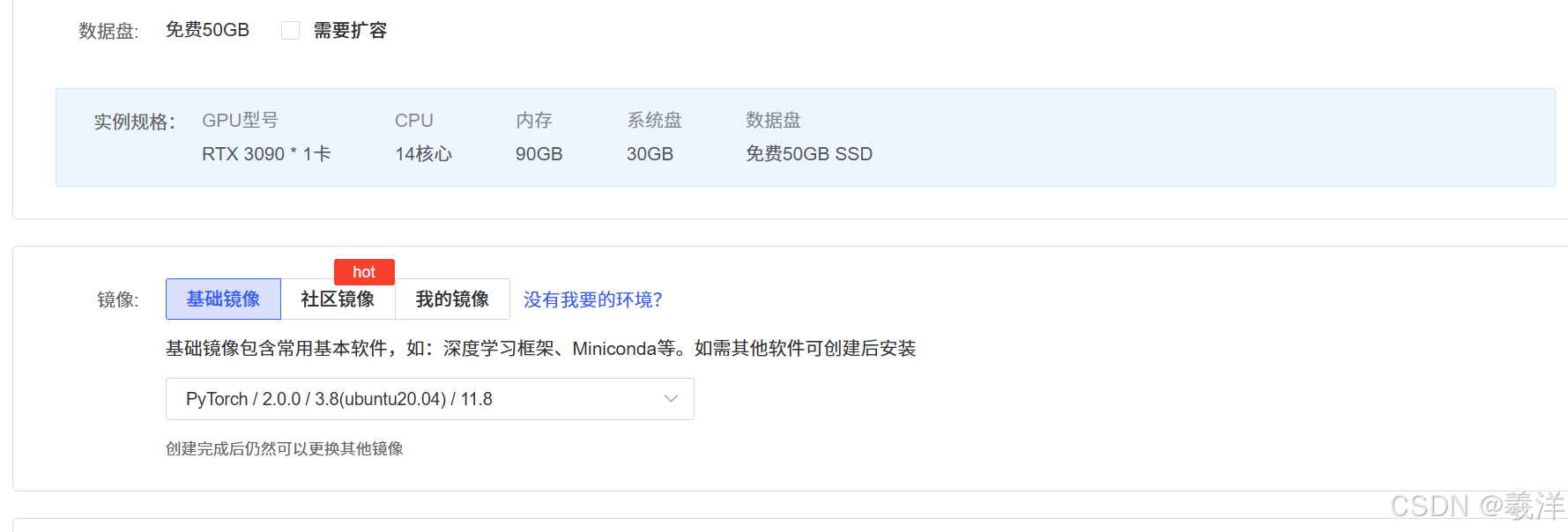
创建并开机即可。
2.云环境安装
2.1 无卡模式开机(省钱,有钱可以略过)
开机之后先关机,然后咱们通过无卡模式先把环境调好,把数据集上传好(要是有钱不在意可以直接忽略)。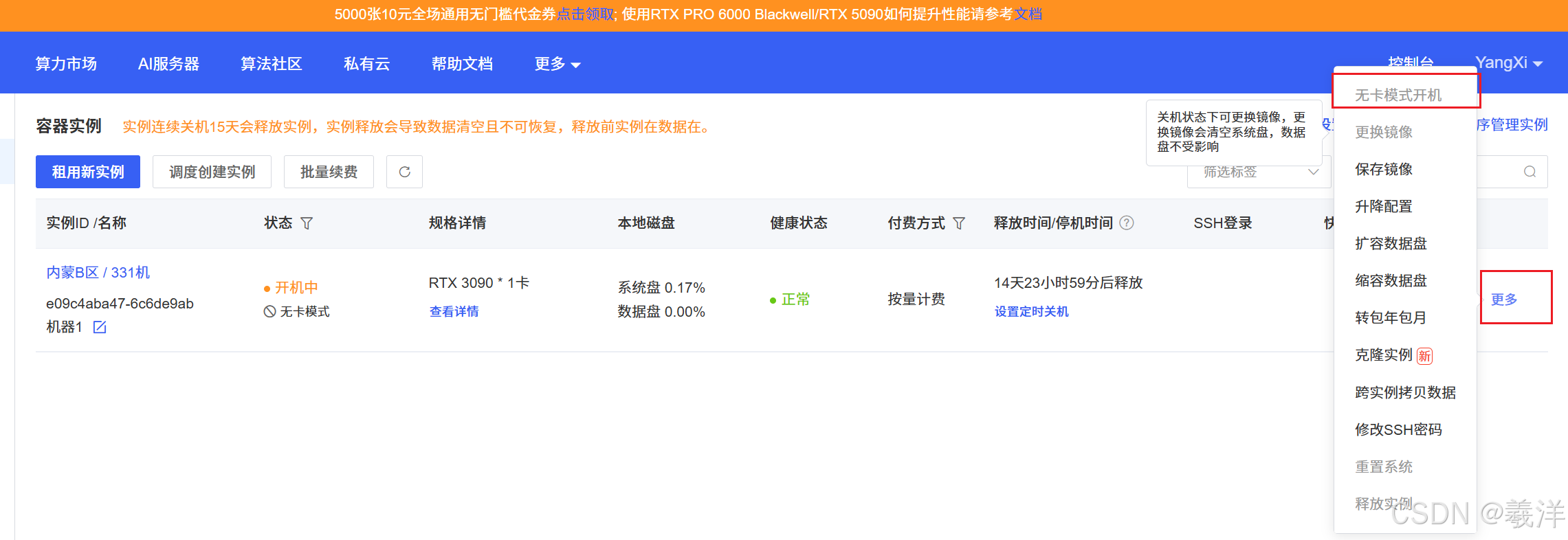
2.2 上传数据集
这里我使用的是FileZila上传的数据集。FileZila使用教程,不过我看这里下载地址无法访问,这里可以自己到官网下载。
还是说一下吧。
(1)左上角[文件]=>[站点管理器]=>[新站点]
(2)协议选择SFTP,复制autodl上的登录指令到txt文档中查看,例如ssh -p xxx root@xxxx.com。其中这里就有相关端点和主机地址,用户root,密码也从autodl控制台上复制。连接,然后点击总是信任该主机(要不然每次连接都会提示一次)。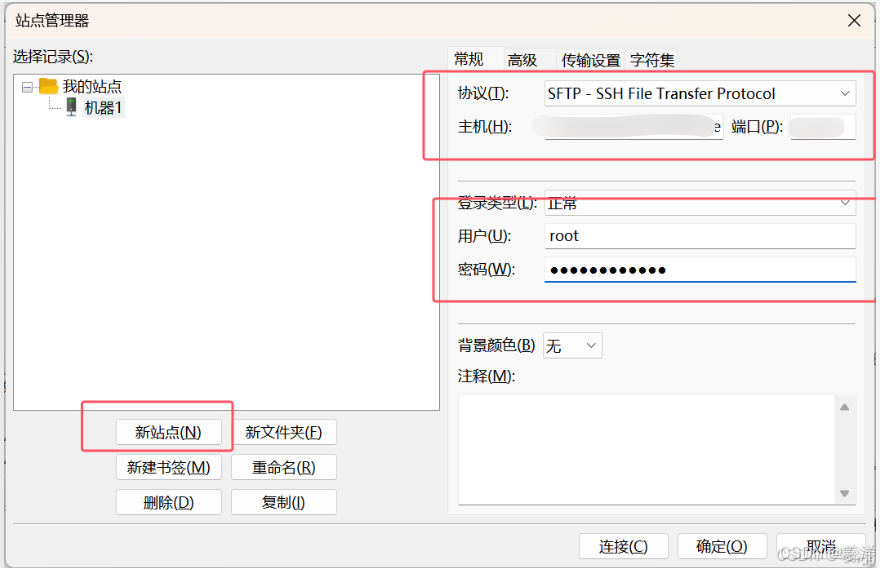
(3)我们操作的文件夹目录主要是/root/autodl-tmp这个目录。
下面新建一个datasets文件夹。然后将我们的数据集文件夹拖拽上传即可。
这里yolo训练我只上传了train和val文件夹。
2.3 配置训练环境
复制ssh指令到cmd登录即可。
这块比较简单啊。这里我是yolov11,就直接
pip install ultralytics=8.3.169
然后说下这个安装的相关代码在哪呢?在这
/root/miniconda3/lib/python3.8/site-packages/ultralytics
今后我们要改网络结构改这里的文件即可。
3.准备开始训练
3.1 基本文件目录
我这里创建了这样的目录,其实可以随意,我想好好分类一点。
yolov11 (yolo版本)
train(训练文件夹)
tt100k2021_new(数据集)
origin(原始:啥也没改的)
3.2 数据集配置文件目录
我放置在在这个目录了:/root/autodl-tmp/datasets/cfg
配置数据集配置文件,例如下:
配置path根目录,train训练图像文件夹,val验证图像文件夹,test测试图像文件夹,names类别。
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: /root/autodl-tmp/datasets # dataset root dir
train: tt100k_2021_new/train/images # train images (relative to 'path') 6961 images
val: tt100k_2021_new/val/images # val images (relative to 'path') 1907 images
test: tt100k_2021_new/val/images
# Classes
names: ['pn', 'pne', 'i5', 'p11', 'pl40', 'pl50', 'pl80', 'p26', 'pl60', 'i4', 'pl100', 'pl30', 'pl5',
'il60', 'i2', 'i2r', 'p5', 'w57', 'p13', 'p10', 'ip', 'i4l', 'pl120', 'il80', 'p23', 'w59',
'pr40', 'p12', 'ph4.5', 'w55', 'p3', 'pl20', 'pg', 'pm20', 'pl70', 'pm55', 'p27', 'il100', 'w13',
'p19', 'w32', 'ph4', 'ph5', 'p6', 'pm30']
3.3 编写训练文件
网络结构配置yaml文件的路径,ultralytics/cfg/models/version,例如
ultralytics/cfg/models/11。说一点这个yaml中有个nc参数,是80,这个可以改也可以不改,因为后面会按数据集yaml也就是3.2那个yaml来进行覆盖,为了统一还是改下,这里不改第一次打印网络结构的时候打印是80。也复制到对应训练文件夹下/root/autodl-tmp/yolov11/train/tt100k2021_new/origin。
接下来编写配置文件
说明下:
epochs:训练200轮
data:数据集配置文件
batch:训练批次
imgsz:图像输入尺寸
workers:数据加载采用的工作线程,默认是8,这个可以根据实际自己进行调整。
project:结果存放地址父级文件夹,默认是run/detect
name:结果存放地址子级文件夹,默认是train,重复则在后面+数字,例如train2、train3等等。
exist_ok:True:开启结果覆盖
optimizer:“SGD"优化器,默认是“auto”
fliplr:图像左右翻转概率,由于我这左右翻转标签类别都变了,所以把这个禁止。
更多参数可参考:https://docs.ultralytics.com/modes/train/#train-settings
如下:
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO("yolo11n.yaml") # pass any model type
results = model.train(epochs=200,
data="/root/autodl-tmp/datasets/cfg/tt100k_2021_new.yaml",
batch=48,
imgsz=1024,
workers=16,
project="../results/yolo11-tt100k_2021_new",
name="origin",
exist_ok=True,
optimizer="SGD",
fliplr=0.0)
无卡模式下可以直接开始验证训练了,但是肯定会报torch.cuda.OutOfMemoryError,报其他错误可以先自己解决
出现OutOfMemoryError就可以准备开始正式环境训练了。
顺嘴提一下,训练的时候不要直接python train.py。使用下面命令保存训练输出到指定日志文件。
nohup python train.py > output.log 2>&1 &
- 其中nohup表示退出终端依然执行
- > output.log 终端正常输出到output.log文件中,而不是显示在终端上。
- 2>&1:错误输出也写入到output.log文件
- 最后的&:将程序放到后台运行,此时终端可以继续输入其他命令,不会被当前程序占用。
然后我们想要查看日志怎么查看呢?用下面命令即可
tail -f output.log
4.镜像环境保存(autodl)
相当于yolo环境,就是你pip install了哪些东西。
这个系统盘我理解就是/root/autodl-tmp(数据盘)之外的。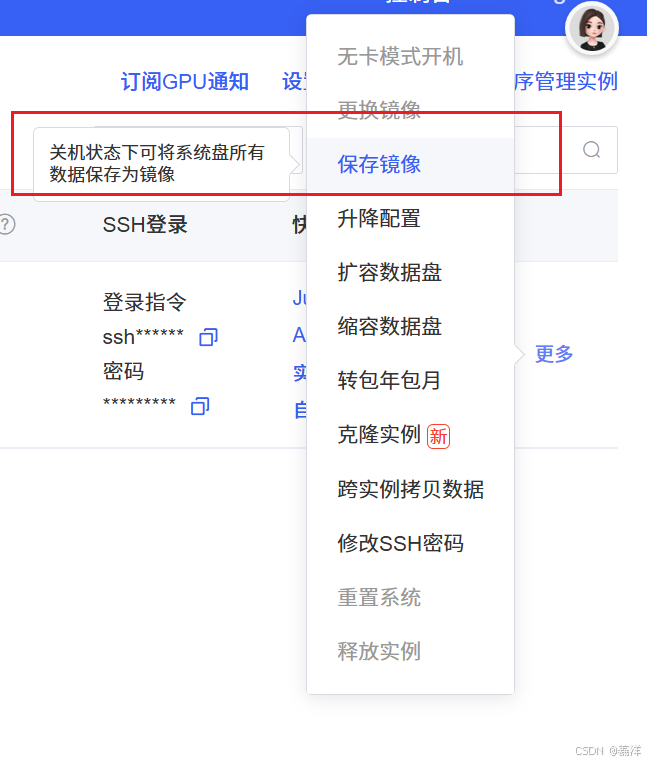
5.如何快速迁移新实例(autodl)
数据上传完毕,或者测试完毕了,发现刚才的实例被别人占用了,怎么办???
5.1 系统盘迁移
组建新实例的时候镜像选择我们自己创建的镜像,系统盘就完成迁移了。
5.2 数据盘迁移
(1)同地区实例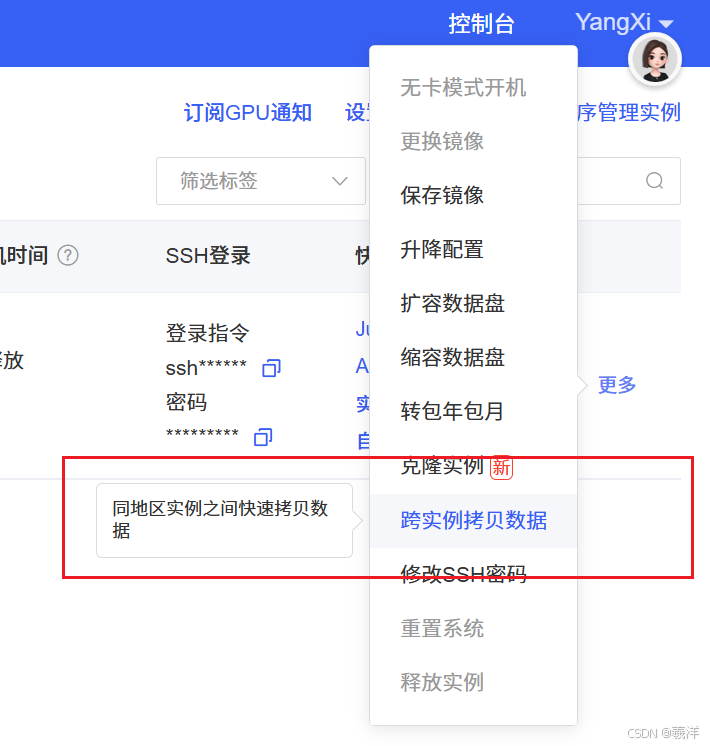
(2)跨地区实例
在源实例下操作。
其中要拷贝的文件夹目录一般都是“/root/autodl-tmp”这个目录。
“ssh -p 35394 root@region-1.autodl.com”为登录目标实例的指令。
cd <要拷贝的文件夹目录下>
tar cf - * | ssh -p 35394 root@region-1.autodl.com "cd /root/autodl-tmp && tar xf -"
参考SCP远程拷贝

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)