A Comprehensive Survey of Deep Research: Systems, Methodologies, and Applications翻译
本综述探讨了快速发展的 Deep Research 系统领域——由人工智能驱动的应用程序,通过集成大语言模型、高级信息检索和自主推理功能,实现复杂研究工作流程的自动化。我们分析了自2023年以来出现的80多个商业和非商业实现,包括OpenAI/DeepResearch、Gemini/DeepResearch、Perplexity/DeepResearch以及众多开源替代方案。通过全面的研究,我们提
摘要
本综述探讨了快速发展的 Deep Research 系统领域——由人工智能驱动的应用程序,通过集成大语言模型、高级信息检索和自主推理功能,实现复杂研究工作流程的自动化。我们分析了自2023年以来出现的80多个商业和非商业实现,包括OpenAI/DeepResearch、Gemini/DeepResearch、Perplexity/DeepResearch以及众多开源替代方案。通过全面的研究,我们提出了一种新的层次化分类法,该分类法根据四个基本技术维度对系统进行分类:(1)基础模型和推理引擎、(2)工具利用和环境交互、(3)任务规划和执行控制,(4)以及知识综合和输出生成。我们探索了这些系统在学术、科学、商业和教育应用中的架构模式、实现方法和特定领域的适应性。我们的分析揭示了当前实现的强大功能,以及它们在信息准确性、隐私、知识产权和可访问性方面所带来的技术和道德挑战。本综述最后指出了高级推理架构、多模态集成、领域专业化、人机协作以及生态系统标准化等有前景的研究方向,这些方向可能会塑造这项变革性技术的未来发展。通过提供一个理解深度研究系统的全面框架,本综述不仅有助于加深对人工智能增强知识工作的理论理解,也有助于开发更强大、更可靠、更易于获取的研究技术。论文资源可在 https://github.com/scienceaix/deepresearch 查看。
1.Introduction
人工智能的快速发展,促使学术界和产业界在知识发现、验证和应用方式上发生了范式转变。传统的研究方法依赖于人工文献综述、实验设计和数据分析,而如今,能够自动化端到端研究工作流程的智能系统正日益补充(在某些情况下甚至被取代)。这种演变催生了一个我们称之为 Deep Research 的全新领域,它融合了大语言模型 (LLM)、高级信息检索系统和自动推理框架,重新定义了学术研究和实际问题解决的界限。
1.1 Definition and Scope of Deep Research
Deep Research 是指系统地应用人工智能技术,通过三个核心维度实现研究过程的自动化和增强:
(1) Intelligent Knowledge Discovery:跨异构数据源自动进行文献检索、假设生成和模式识别。
(2)End-to-End Workflow Automation:将实验设计、数据收集、分析和结果解释集成到统一的 AI 驱动流程中。
(3)Collaborative Intelligence Enhancement:通过自然语言界面、可视化和动态知识表示促进人机协作。
为了清晰地界定 Deep Research 的界限,我们将其与类似的人工智能系统进行如下区分:
- Differentiating from General AI Assistants:虽然像 ChatGPT 这样的通用 AI 助手可以回答研究问题,但它们缺乏 Deep Research 系统所具备的自主工作流能力、专业研究工具以及端到端的研究协调能力。最近的调查凸显了专业研究系统与通用 AI 能力之间的关键区别,尤其强调了特定领域工具与通用助手相比如何从根本上改变研究工作流程。
- Differentiating from Single-Function Research Tools:引用管理器、文献搜索引擎或统计分析软件包等专业工具虽然能够处理孤立的研究功能,但缺乏深度 Deep Research 所具备的集成推理和跨功能协同能力。scispace 和 You.com 等工具代表了早期研究辅助的尝试,但缺乏真正的 Deep Research 系统所具备的端到端功能。
- Differentiating from Pure LLM Applications:仅仅用面向研究的提示包装 LLM 的应用程序缺乏真正的 Deep Research 系统所具有的环境交互、工具集成和工作流自动化功能。
本综述专门考察至少具备三个核心维度中的两个维度的系统,重点关注那些以大语言模型为基础推理引擎的系统。我们的范围涵盖 OpenAI/DeepResearch、谷歌的 Gemini/DeepResearch 和 Perplexity/DeepResearch 等商业产品,以及 dzhng/deepresearch、HKUDS/Auto-Deep-Research 等开源实现,以及后续章节中详细介绍的众多其他产品。我们排除了纯粹的文献计量工具或缺乏集成认知能力的单阶段自动化系统,例如 Elicit、ResearchRabbit、Consensus 等研究辅助工具,或 Scite 等引文工具。其他一些专业工具,例如专注于科学文本检索和组织的 STORM,虽然很有价值,但缺乏我们调查范围所核心的端到端深度研究能力。
1.2 Historical Context and Technical Evolution
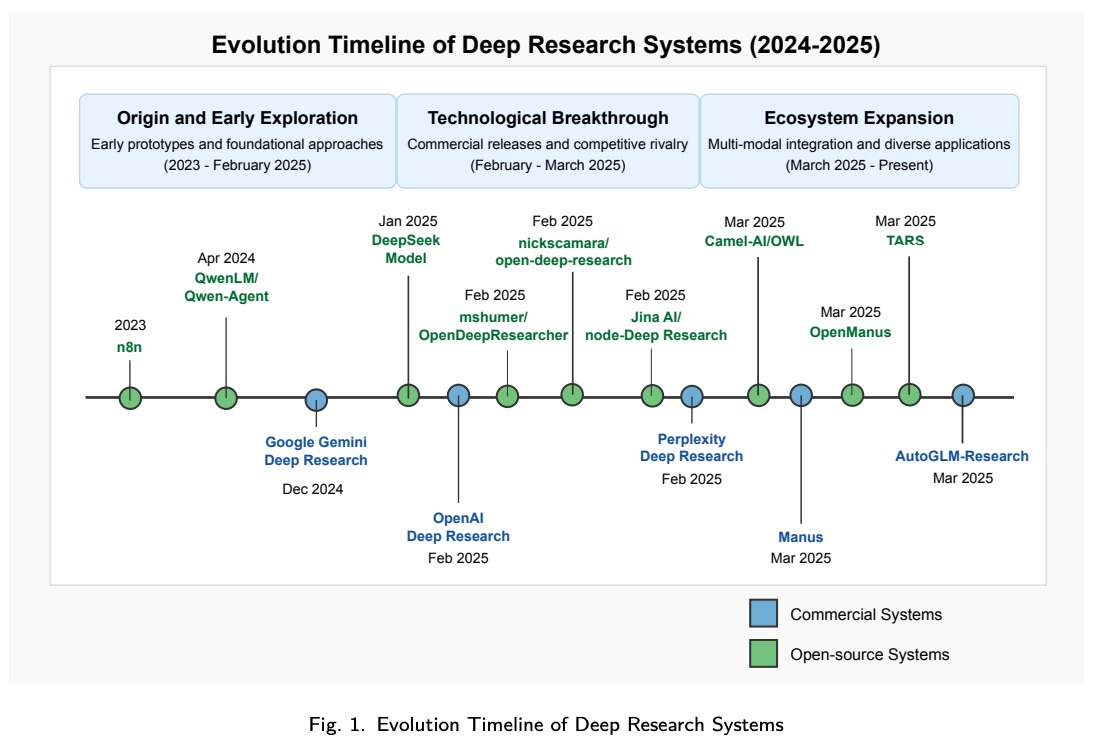
Deep Research 的发展轨迹可以通过三个反映技术进步和实现方法的演变阶段来描绘:
1.2.1 Origin and Early Exploration (2023 - February 2025)。值得注意的是,像 n8n、QwenLM/Qwen-Agent 等工作流自动化框架早在 Deep Research 兴起之前就已存在。它们的早期建立体现了相关技术领域的既有基础,突显出发展格局并非仅仅由 Deep Research 的兴起所塑造,而是具有更加多样化和更早的根源。Deep Research 的概念源于人工智能助手向智能 Agent 的转变。2024 年 12 月,Google Gemini 率先推出了此功能,其初始 Deep Research 实现专注于基本的多步推理和知识集成。这一阶段为后续发展奠定了基础,为更复杂的人工智能驱动研究工具奠定了基础。其中许多进展建立在早期的工作流自动化工具(如 n8n)和 Agent 框架(如 AutoGPT 和 BabyAGI)的基础上,这些框架已经为自主任务执行奠定了基础。该生态系统的其他早期贡献包括开创了集成研究工作流程的 cline2024 和开发了基于网络的研究所必需的基础浏览器自动化功能的 open_operator。
1.2.2 Technological Breakthrough and Competitive Rivalry (February - March 2025)。DeepSeek 开源模型的兴起,以其高效的推理能力和经济高效的解决方案彻底改变了市场。2025 年 2 月,OpenAI 发布 Deep Research,标志着 Deep Research 的重大飞跃。基于 o3 模型,Deep Research 展示了自主研究规划、跨领域分析和高质量报告生成等先进能力,在复杂任务中实现了超越以往基准的准确率。与此同时,Perplexity 于 2025 年 2 月推出了免费使用的 Deep Research,强调快速响应和易用性,以占领大众市场。nickscamara/open-deepresearch、mshumer/OpenDeepResearcher、btahir_open_deep_research 和 GPT-researcher 等开源项目逐渐兴起,成为由社区驱动的商业平台替代方案。生态系统不断扩展,出现了轻量级实现,例如专为有限资源的本地执行而设计的 Automated-AI-Web-Researcher-Ollama,以及模块化框架,例如为自定义研究工作流程提供可组合组件的 Langchain-AI/Open_deep_research。
1.2.3 Ecosystem Expansion and Multi-modal Integration (March 2025 - Present)。第三阶段的特点是多样化生态系统的成熟。像 Jina-AI/node-DeepResearch 这样的开源项目实现了本地化部署和定制,而 OpenAI 和谷歌的商业闭源版本则继续通过多模态支持和多 Agent 协作功能突破界限。高级搜索技术和报告生成框架的集成进一步增强了该工具在学术研究、金融分析和其他领域的实用性。与此同时,Manus 和 AutoGLM-Research、MGX 和 Devin 等平台正在整合先进的人工智能研究功能,以增强其服务。与此同时,Anthropic 于 2025 年 4 月推出了 Claude/Research,引入了 Agent 搜索功能,可以系统地探索问题的多个角度,并提供具有可验证引文的全面答案。OpenManus、Camel-AI/OWL 和 TARS 等智能体框架通过专门的功能和特定领域的优化进一步扩展了生态系统。
1.3 Significance and Practical Implications
Deep Research 表明跨多个领域的变革潜力:
(1)Academic Innovation:通过自动化文献综合(例如,HotpotQA 性能基准)加速假设验证,并使研究人员能够探索更广泛的跨学科联系,否则这些联系可能未被发现。Deep Research 的变革潜力超越了单个应用,可以从根本上重塑科学发现过程。正如 Sourati 和 Evans 所论证的那样,具有人类意识的人工智能可以通过增强研究人员的能力,同时适应他们的概念框架和方法论,从而显著加速科学发展。这种人机协同代表着从传统自动化向尊重和增强人类科学直觉的协作智能的根本转变。Khalili 和 Bouchachia 的补充研究进一步表明,构建科学发现机器的系统方法如何通过集成的人工智能驱动的研究工作流程来改变假设生成、实验设计和理论完善。
(2)Enterprise Transformation:通过 Agent-RL/ReSearch 和 smolagents/open_deep_research 等系统实现大规模数据驱动的决策,这些系统可以前所未有的深度和效率分析市场趋势、竞争格局和战略机遇。
(3)Democratization of Knowledge:通过像 grapeot/deep_research_agent 和 OpenManus 这样的开源实现降低进入门槛,使个人和组织能够访问复杂的研究能力,而无需考虑技术专长或资源限制。
1.4 Research Questions and Contribution of this Survey
本综述探讨了三个基本问题:
- 架构选择(系统架构、实现方法、功能能力)如何影响 Deep Research 的有效性?
- 在 Deep Research 实现的范围内,LLM 微调、检索机制和工作流程编排出现了哪些技术创新?
- 现有系统如何平衡性能、可用性和伦理考虑?通过比较 n8n 和 OpenAI/AgentsSDK 等方法,可以得出哪些模式?
我们的贡献体现在三个方面:
- Methodological:提出一种新的分类法,根据系统的技术架构对系统进行分类,从基础模型到知识综合能力
- Analytical:对评估指标中的代表性系统进行比较分析,突出不同方法的优势和局限性
- Practical:确定关键挑战并制定未来发展路线图,特别关注新兴架构和集成机会
本文的其余部分遵循结构化探索,从概念框架(第 2 节)、技术创新和比较分析(第 3-4 节)、实现技术(第 5 节)、评估方法(第 6 节)、应用和用例(第 7 节)、道德考虑(第 8 节)和未来方向(第 9 节)开始。
2.The Evolution and Technical Framework of Deep Research
本节将围绕定义 Deep Research 系统的四项基本技术能力,对 Deep Research 系统进行全面的技术分类。针对每项能力,我们将探讨其演进轨迹和技术创新,并重点介绍体现每种方法的代表性实现。
2.1 Foundation Models and Reasoning Engines: Evolution and Advances
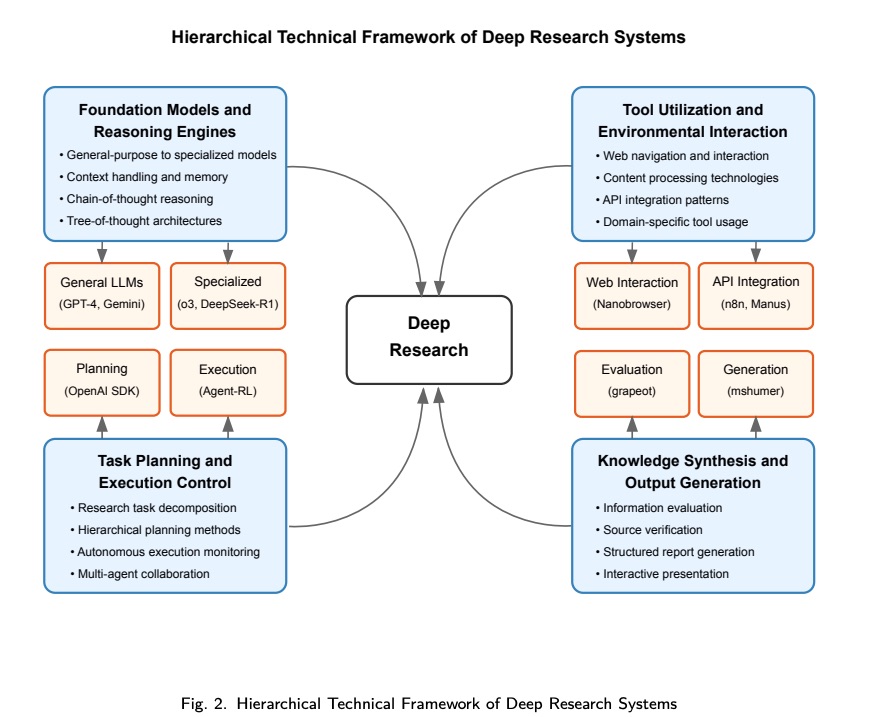
Deep Research 系统的基础在于其底层人工智能模型和推理能力,这些模型和推理能力已经从通用语言模型发展为专门的研究型架构。
2.1.1 From General-Purpose LLMs to Specialized Research Models
从通用 LLM 到研究专业模式的进展代表了 Deep Research 能力的根本转变:
Technical Evolution Trajectory。早期的实现依赖于通用的 LLM,且针对特定任务的优化极少。当前的系统通过架构修改、专门的训练语料库以及专注于分析和推理能力的微调机制,专门针对研究任务增强了模型。从 GPT-4 等模型到 OpenAI 的 o3 模型的过渡,展现了抽象、多步推理和知识集成能力的显著提升,这些能力对于复杂的研究任务至关重要。
Representative Systems。OpenAI/DeepResearch 以其基于 o3 的模型(该模型专门针对网页浏览和数据分析进行了优化)为例,展示了这一演变。该系统利用思维链和思维树推理技术来探索复杂的信息环境。谷歌的 Gemini/DeepResearch 也采用了 Gemini 2.5 Pro,该模型具有增强的推理能力和百万个 token 上下文窗口来处理海量信息。这些方法建立在推理增强技术的基础之上,例如思维链提示 、自洽性和人类偏好校准,这些技术已专门针对研究密集型任务进行了调整。在开源领域,AutoGLM-Research 展示了专门的训练方案如何优化 ChatGLM 等现有模型,使其能够胜任研究密集型任务,并通过有针对性地增强推理组件,显著提升性能。
2.1.2 Context Understanding and Memory Mechanisms
处理、保留和利用大量上下文信息的能力代表了 Deep Research 系统的一项关键进步:
Technical Evolution Trajectory。早期系统受限于有限的上下文窗口,这限制了它们从多个来源合成信息的能力。当前实现采用了复杂的内存管理技术,包括情景缓冲区、分层压缩和基于注意力机制的检索机制,这些技术将有效上下文扩展到了模型的极限之外。Grok 3 和 Gemini 2.5 Pro 等模型的百万级上下文窗口,以及 OpenAI o3 模型中的上下文优化,极大地扩展了这些系统的信息处理能力。如今,先进的系统能够区分工作记忆(主动推理上下文)和长期记忆(知识库),从而实现更接近人类的研究过程。
Representative Systems。Perplexity/DeepResearch 利用 DeepSeek-R1 的功能,并实现了专有的结构化信息管理机制,开创了高效的上下文处理技术。该系统可以分析数百个来源,同时保持推理线程的连贯性。同样,Camel-AI/OWL 也采用了创新的开放权重内存管理方法,允许根据信息相关性和任务需求动态分配注意力资源。这两个系统都证明了,即使在基础模型能力相当的情况下,有效的内存架构也能显著提升研究性能。
2.1.3 Enhancements in Reasoning Capabilities
先进的推理机制将现代 Deep Research 系统与传统的 LLM 应用区分开来:
Technical Evolution Trajectory。早期的实现主要依赖于零样本或少样本提示来完成推理任务。当前的系统集成了显式推理框架,包括思维链、思维树和基于图的推理架构。Lang et al. 的最新研究展示了辩论驱动的推理如何促进从弱到强的泛化,并通过结构化的论证流程,在复杂的研究任务中实现更稳健的表现。这些方法实现了更接近人类科学的推理模式,能够明确地表达不同的观点,并对相互竞争的假设进行结构化的评估。像 OpenAI 的 o3 这样的高级实现融合了自我批评、不确定性估计和递归推理细化。这种演变使得证据评估、假设检验和知识综合的形式日益复杂,而这些对于高质量的研究成果至关重要。
Representative Systems。QwenLM/Qwen-Agent 通过其专用工具包集成和模块化推理框架,展现了先进的推理能力。该系统采用多阶段推理流程,包含明确的规划、信息收集、分析和综合阶段,并针对研究工作流程进行了优化。smolagents/open_deep_research 也具备类似的能力,它实现了一个灵活的推理架构,可以适应不同的研究领域和方法。CycleResearcher 等系统展示了如何将自动化审核流程集成到研究工作流程中,并通过结构化的反馈循环提高准确性。这些方法实现了明确的验证步骤,可以在生成最终研究成果之前识别潜在的错误和不一致之处。人工智能在数学等复杂领域的应用进一步证明了这一进步,人们越来越多地从认知科学的角度审视模型,以增强其推理能力,并取得了一些显著的里程碑式成就,例如在解决国际数学奥林匹克问题时获得银牌。这些系统突显了推理增强技术如何能够显著提高研究质量,即使不需要大型或计算密集度高的基础模型。
2.2 Tool Utilization and Environmental Interaction: Evolution and Advances
Deep Research 系统必须有效地与外部环境交互以收集和处理信息,这代表了超越核心语言模型功能的基本能力。
2.2.1 Web Interaction Technology Development
浏览和提取网络信息的能力代表着 Deep Research 的基础能力:
Technical Evolution Trajectory。最初的实现依赖于基于 API 的简单搜索查询,交互功能有限。当前的系统采用复杂的网页导航,包括动态内容处理、身份验证管理和交互元素操作。高级实现具备对网页结构的语义理解,支持自适应信息提取和多页面导航流程。这一发展极大地扩展了对网页信息源的访问,并提升了从复杂网页环境中获取洞察的能力。
Representative Systems。Nanobrowser 是一个专为 AI Agent 设计的专用浏览器环境,为研究任务提供优化的渲染和交互功能。它能够在保持安全性和性能的同时,对 Web 导航进行细粒度控制。同样,AutoGLM 也展示了跨 Web 和移动界面的复杂 GUI 交互功能,使其能够通过专为人类设计的界面访问信息。这些系统展示了专业的 Web 交互技术如何显著扩展 Deep Research 系统的信息收集能力。
2.2.2 Content Processing Technology Advancements
除了基本的导航之外,处理多种内容格式的能力对于综合研究至关重要:
Technical Evolution Trajectory。早期系统主要局限于从 HTML 源中提取文本。现代实现支持多模态内容处理,包括结构化数据表、嵌入式可视化、PDF 文档和交互式应用程序。基于 OpenAI o3 构建的先进系统可以从非结构化内容中提取语义结构,从多种格式中识别关键信息,并整合跨模态的洞察。这一发展极大地扩展了可纳入研究流程的信息源范围。
Representative Systems。dzhng/deep-research 项目通过其针对不同文档类型和格式的专用模块,展示了高级内容处理技术。它为学术论文、技术文档和结构化数据源实现了自定义提取逻辑。同样,nickscamara/open-deep-research 也提供了复杂的内容规范化流程,可将各种格式转换为适合分析的一致知识表示。这两个系统都展示了专业化的内容处理如何显著提高研究成果的质量和全面性。
2.2.3 Specialized Tool Integration Progress
与特定领域工具的集成将 Deep Research 能力扩展到一般信息处理之外:
Technical Evolution Trajectory。最初的系统依赖于通用的网页搜索和基本的 API 集成。ToolLLM 等框架极大地促进了各种工具的集成,使大语言模型能够掌握超过 16,000 个真实世界的 API,从而显著扩展了研究系统的交互能力。同样,AssistGPT 展示了通用的多模态助手如何在不同的环境中进行规划、执行、检查和学习,从而创建了统一的研究体验,无缝地融合了各种信息源和交互模式。LLaVA-Plus 通过明确的工具学习机制进一步扩展了这些能力,使研究助手能够自适应地将专用工具融入多模态工作流程中。当前的实现包含复杂的工具链,包括专用数据库、分析框架和特定领域的服务。先进的系统会根据研究需求动态地选择和编排工具,从而有效地利用可用功能构建定制的研究工作流程。一些实现(例如利用 OpenAI Codex 的实现)甚至可以生成自定义代码来处理研究数据或按需实现分析模型,从而进一步扩展了分析能力。这种发展使得日益复杂的分析和特定领域的研究应用成为可能。
Representative Systems。Manus 通过其广泛的 API 集成框架和工具选择机制,展现了复杂的工具编排能力。该系统可以将特定领域的研究工具和服务整合到统一的工作流中,从而显著扩展其分析能力。同样,n8n 提供了一个灵活的工作流自动化平台,可以根据研究任务进行配置,从而实现与专业数据源和分析服务的集成。Steward 通过实现自然语言驱动的跨网站导航和操作,扩展了 Web 交互能力,克服了传统自动化框架的可扩展性限制,同时保持了较低的运营成本。这些系统突出了工具集成如何将深度研究能力扩展到专业领域和复杂的分析工作流中。
2.3 Task Planning and Execution Control: Evolution and Advances
有效的研究需要复杂的规划和执行机制来协调复杂的多阶段工作流程。
2.3.1 Research Task Planning Development
将研究目标分解为可管理的任务的能力代表着一项根本性的进步:
Technical Evolution Trajectory。早期方法采用简单的任务分解和线性执行流程,类似于早期 Agent 框架(如 MetaGPT 和 AgentGPT)中的方案。现代系统基于中间结果和发现,实现具有动态细化的分层规划。先进的规划方法越来越多地融入结构化探索方法,以高效地探索复杂的解决方案空间。AIDE 展示了树搜索算法如何有效地探索机器学习工程中潜在的代码解决方案空间,通过策略性地重用和细化有希望的路径,以计算资源换取更高的性能。先进的实现结合了资源感知规划,考虑了时间约束、计算限制和信息可用性。然而,Cihan et al. 的研究证实,将人工智能工具融入自动代码审查等任务中,尽管有好处,但据观察,这反而会增加拉取请求的关闭时间,这凸显了在这种资源感知系统中考虑时间影响的迫切需求。这种演变使得日益复杂的研究策略能够同时适应任务需求和可用资源。
Representative Systems。OpenAI/AgentsSDK 提供了一个全面的研究任务规划框架,明确支持目标分解、执行跟踪和自适应细化。它支持开发具有复杂规划功能的应用程序,用于研究工作流程。同样,Flowith/OracleMode 实现了针对研究任务优化的专门规划机制,尤其注重信息质量评估和信息源优先级排序。这些系统展示了先进的规划功能如何显著提高研究效率和效果。
2.3.2 Autonomous Execution and Monitoring Advances
可靠地执行研究计划需要复杂的控制和监控机制:
Technical Evolution Trajectory。初始系统采用基本的顺序执行,错误处理能力有限。当前的实现具备并发执行路径、全面监控以及对执行挑战的动态响应能力。高级系统实现了自监督,并具有明确的成功标准、故障检测和自主恢复策略。这一演进显著提高了 Deep Research 系统在复杂任务中的可靠性和自主性。
Representative Systems。Agent-RL/ReSearch 通过其基于强化学习的研究执行方法,展现了高级执行控制的典范。该系统从经验中学习有效的执行策略,不断提升其驾驭复杂研究工作流程的能力。其自适应执行机制能够从故障中恢复,并根据中间结果调整策略,凸显了复杂的控制机制如何提升研究的可靠性和有效性。
2.3.3 Multi-Agent Collaboration Framework Development
复杂的研究通常受益于专门的 Agent 角色和协作方法:
Technical Evolution Trajectory。早期系统依赖于功能未分化的单 Agent。现代系统采用专门的 Agent 角色,并配备明确的协调机制和信息共享协议。先进的系统具备动态角色分配、共识构建机制和复杂的冲突解决策略。这种演变使得协作研究工作流程日益复杂,并提升了在挑战性任务上的表现。例如,采用多 Agent 辩论的框架已被证明可以提高评估的一致性,而对生成式人工智能投票的研究表明,它能够抵御集体决策中的模型偏差。
Representative Systems。smolagents/open_deep_research 框架通过其模块化 Agent 架构和明确的协调机制,展示了高效的多 Agent 协作。它能够组建能力互补、目标一致的专业研究团队。同样,TARS 在其桌面环境中实现了一个复杂的 Agent 协作框架,允许多个专业 Agent 共同参与统一的研究工作流程。这些系统彰显了多 Agent 方法如何通过专业化和协作来增强研究能力。
2.4 Knowledge Synthesis and Output Generation: Evolution and Advances
Deep Research 系统的最终价值在于其能够将不同的信息综合成连贯的、可操作的见解。
2.4.1 Information Evaluation Technology Development
对信息质量的严格评估是可靠研究的关键能力:
Technical Evolution Trajectory。早期系统主要依赖于来源信誉启发法,且基于内容的评估有限。现代系统采用复杂的评估框架,综合考虑来源特征、内容特征以及与现有知识的一致性。先进的系统实现了明确的不确定性建模、矛盾检测和证据推理方法。这一发展显著提高了研究成果的可靠性和可信度。基于生成式人工智能的知识检索技术的进步增强了获取和验证信息的能力。
Representative Systems。grapeot/deep_research_agent 实现了复杂的信息评估机制,并针对不同类型的信息来源提供明确的质量评分。它能够基于内在内容特征和外在来源特征评估信息的可靠性,从而实现更精准的信息利用。这些功能凸显了先进的评估机制如何显著提升研究质量和可靠性。
2.4.2 Report Generation Technology Advances
有效传达研究结果需要复杂的内容组织和呈现方式:
Technical Evolution Trajectory。最初的系统生成的是简单的文本摘要,结构或连贯性有限。当前的系统可以生成具有层级结构、证据整合和连贯论证的综合报告。高级系统可以根据受众的专业知识、信息需求和演示环境生成自适应的输出。这一演变极大地提升了深度研究成果的可用性和影响力。
Representative Systems。mshumer/OpenDeepResearcher 项目通过其结构化的输出框架和证据集成机制,展现了先进的报告生成技术。它能够生成全面的研究报告,包含明确的归因、结构化的论证和集成的支持证据。这些功能展示了复杂的报告生成技术如何提升深度研究成果的实用性和可信度。此外,MegaWika 数据集提供了一个包含数百万篇文章和参考资料的大规模多语言资源,支持协作式 AI 报告生成。
2.4.3 Interactive Presentation Technology Development
除了静态报告之外,交互式结果探索还能增强洞察的发现和利用:
Technical Evolution Trajectory。早期系统输出固定的文本,用户交互极少。现代系统支持动态探索,包括向下钻取功能、来源验证和替代视角检查。高级系统通过迭代反馈整合和对用户查询的自适应响应,实现了协作式改进。这一演变显著提升了深度研究界面的实用性和灵活性。
Representative Systems。HKUDS/Auto-Deep-Research 实现了先进的交互式演示功能,允许用户通过动态界面探索研究成果,检验支持性证据,并通过迭代交互完善分析。这些功能凸显了交互式演示技术如何提升深度研究成果的实用性和可及性,从而促进更高效的知识转移和利用。
该技术框架为理解 Deep Research 系统的功能和演进提供了全面的基础。后续章节将基于此框架分析实现方法、评估系统性能并探索跨领域的应用。
3.Comparative Analysis and Evaluation of Deep Research Systems
本节基于第二部分建立的技术框架,对现有的 Deep Research 系统进行了多维度的全面比较分析。我们将研究不同的实现方式如何平衡技术能力、应用适用性和性能特征,以满足不同的研究需求。
3.1 Cross-Dimensional Technical Comparison
不同的 Deep Research 系统在我们框架中确定的四个关键技术维度上展现出不同的优势。本节分析不同的实现方式如何平衡这些功能以及由此产生的性能影响。
3.1.1 Foundation Model and Reasoning Efficiency Comparison
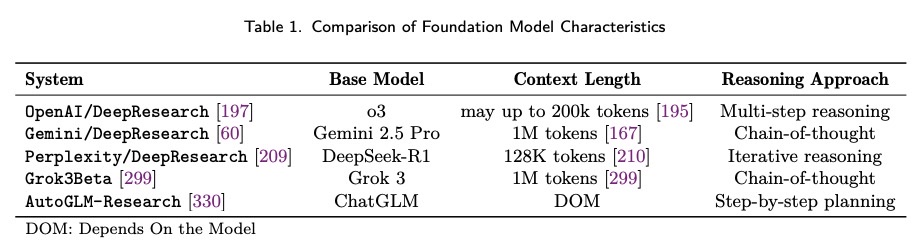
Deep Research 系统的底层推理能力对其整体有效性有显著影响:
OpenAI 和 Google 的商业系统利用专有模型,这些模型拥有广泛的上下文窗口和复杂的推理机制,使其能够以更高的一致性处理更大量的信息。OpenAI 的 o3 模型在复杂的推理任务中展现出非凡的优势,而 Gemini 2.5 Pro 则在跨不同来源的信息整合方面表现出色。相比之下,Perplexity/DeepResearch 通过优化的实现和专注的用例,实现了与开源 DeepSeek-R1 模型相媲美的性能。
Camel-AI/OWL 和 QwenLM/Qwen-Agent 等开源实现表明,通过专门的优化,更易于访问的模型可以实现有效的 能力。Deep Research Camel-AI/OWL 的开放权重方法支持跨计算环境的灵活部署,而 QwenLM/Qwen-Agent 则利用模块化推理来弥补基础模型能力的不足。
3.1.2 Tool Integration and Environmental Adaptability Comparison

与不同信息环境交互的能力在不同实现方式中存在显著差异:
像 Nanobrowser 这样的专业工具在网页交互能力方面表现出色,提供了针对研究工作流程优化的复杂导航和内容提取功能。dzhng/deep-research 和 nickscamara/open-deep-research 等系统通过高级文档处理功能补充了这些功能,可以从各种格式中提取结构化信息。
Manus 和 AutoGLM 等综合平台提供了更广泛的环境交互功能,平衡了网页浏览、API 集成和文档处理。这些系统可以适应不同的研究场景,但可能无法与特定领域中更专注的工具的专业性能相媲美。n8n 的工作流自动化功能为 API 集成提供了卓越的灵活性,但与网页和文档环境的直接交互较为有限。
3.1.3 Task Planning and Execution Stability Comparison

有效的研究需要可靠的任务规划和执行能力:
OpenAI/AgentsSDK 展示了其先进的规划功能,具有分层任务分解和自适应执行功能,能够以可靠的完成率实现复杂的研究工作流程。同样,Flowith/OracleMode 也提供了针对研究任务优化的高级规划机制,但错误恢复能力较为有限。
Agent-RL/ReSearch 采用强化学习技术来开发强大的执行策略,从而实现卓越的错误恢复能力,以适应研究工作流程中的意外挑战。相比之下,smolagents/open_deep_research 和 TARS 则专注于多 Agent 协作,将复杂任务分配给专门的 Agent,以提高整体研究效率。
像 grapeot/deep_research_agent 这样的更简单的实现提供了更有限的规划和执行能力,但可以为不太复杂的研究任务提供足够的可靠性,展示了整个生态系统的复杂性范围。
3.1.4 Knowledge Synthesis and Output Quality Comparison
将研究结果综合成连贯、可靠的输出的能力存在很大差异:
OpenAI/DeepResearch 和 Perplexity/DeepResearch 等商业平台展示了先进的信息评估能力,能够有效评估来源的可信度和内容的可靠性,从而生成高质量的综合报告。OpenAI 的实现在报告结构和组织方面表现出色,而 Perplexity 则在来源归属和验证方面提供了极其强大的引用实践。
像 mshumer/OpenDeepResearcher 这样的开源实现专注于报告的结构和组织,能够生成格式良好的输出,有效地传达研究结果。HKUDS/AutoDeep-Research 强调交互式探索,允许用户通过迭代交互来检验证据并改进分析。像 grapeot/deep_research_agent 这样的专业工具优先考虑信息评估而非呈现,注重可靠的内容评估,而非复杂的输出格式。
3.2 Application-Based System Suitability Analysis
除了技术能力之外,Deep Research 系统还展现出对不同应用环境的适应性差异。本节将探讨系统特性如何与关键应用领域相匹配。
3.2.1 Academic Research Scenario Adaptability Assessment

学术研究尤其需要重视全面的文献综述、严谨的方法论和高质量的引用。OpenAI/DeepResearch 等系统凭借其访问学术数据库、全面分析研究方法以及生成格式正确的引用的能力,在这一领域表现出色。PaperQA 和 Scite 等其他专业的学术研究工具则提供了专注于科学文献处理的补充功能,而 Google 的 NotebookLm 则为学术探索提供了结构化的知识工作空间。
OpenAI/DeepResearch 凭借其全面的文献覆盖、严谨的方法论和高质量的引用实践,展现出其在学术研究领域的卓越适用性。该系统能够有效地浏览学术数据库,理解研究方法,并生成结构良好且具有恰当归因的文献综述。Perplexity/DeepResearch 在文献覆盖和引用质量方面也表现出色,但方法论的复杂性略逊一筹。
像 Camel-AI/OWL 这样的开源替代方案在特定学术领域提供了颇具竞争力的能力,尤其在方法论理解方面更胜一筹。dzhng/deepresearch、mshumer/OpenDeepResearcher 和 HKUDS/Auto-Deep-Research 等系统在各个维度上都提供了中等水平的能力,因此适用于要求较低的学术研究应用或初步文献探索。
3.2.2 Enterprise Decision-Making Scenario Adaptability Assessment

Gemini/DeepResearch 凭借其强大的信息流通性、分析能力和可操作的输出格式,展现出其对企业决策的卓越适用性。该系统有效地导航业务信息源,分析市场趋势,并产生与决策过程直接相关的洞察。Manus 在信息获取和分析方面也提供了同样强大的性能,尽管它对可操作的推荐格式的重视程度略低。Microsoft Copilot 为组织提供了强大的生成式人工智能、企业级安全和隐私保护,并受到全球各地企业的信赖。同样,Adobe Experience Platform AI Assistant 采用知识图谱增强检索生成技术,对私有企业文档进行精准响应,显著提高了响应的相关性,同时保持了来源追踪。
像 n8n 这样的工作流自动化平台通过与企业数据源和商业智能工具的集成,在信息时效性和可操作性方面展现出独特的优势。像 Agent-RL/ReSearch 和 Flowith/OracleMode 这样的以研究为重点的系统提供了具有竞争力的分析能力,但可能需要额外的处理才能将研究结果转化为可行的业务建议。
3.2.3 Personal Knowledge Management Adaptability Assessment

个人知识管理强调可访问性、个性化以及与现有工作流程的集成:
Perplexity/DeepResearch 通过其用户友好的界面和免费访问层,为个人知识管理提供了强大的可访问性,尽管个性化功能较为有限。像 nickscamara/open-deep-research 和 OpenManus 这样的开源实现通过本地部署和定制提供了更大的个性化可能性,能够适应个人的信息管理偏好。
Nanobrowser 和 Jina-AI/node-DeepResearch 等基础设施工具在工作流集成方面具有独特的优势,可以无缝集成到现有的个人知识管理系统和流程中。像 smolagents/open_deep_research 这样的更复杂的框架提供了复杂的功能,但对于非技术用户来说,可能存在可访问性方面的挑战。
3.3 Performance Metrics and Benchmarking
除了定性比较之外,定量性能指标还可以对跨系统的 Deep Research 能力进行客观评估。
3.3.1 Quantitative Evaluation Metrics
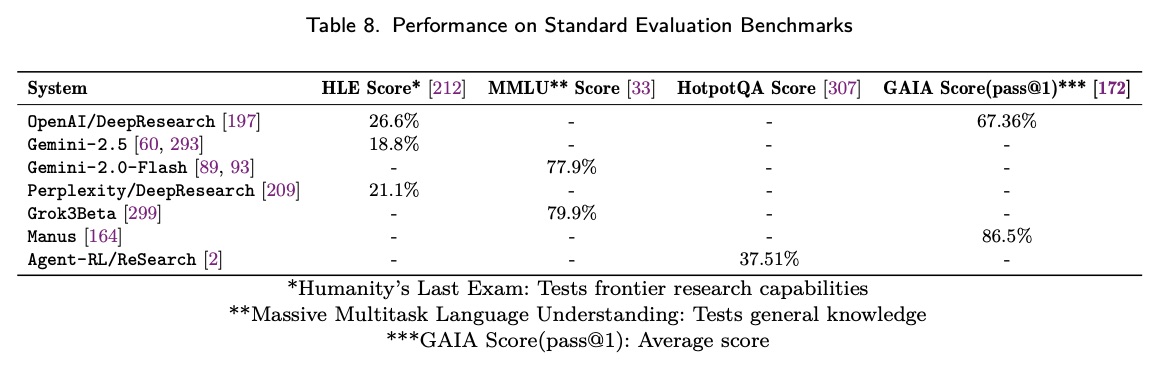
标准基准可以对核心研究能力进行比较评估:
OpenAI/DeepResearch 在多项基准测试中均展现出领先性能,尤其在衡量高级研究和推理能力的人类终极考试 (HLE) 中表现出色。Gemini/DeepResearch 也展现出相当的性能。根据谷歌深度研究 Gemini 2.5 Pro Experimental 的介绍,新模型在四个关键指标上均表现出优于 OpenAI/DeepResearch 的用户偏好:指令遵循率(60.6% vs. 39.4%)、全面性(76.9% vs. 23.1%)、完整性(73.3% vs. 26.7%)以及写作质量(58.2% vs. 41.8%)。这些结果表明 Gemini 2.5 Pro 在合成结构化、高保真研究成果方面的能力有所提升。这种能力在全栈应用中得到了进一步增强。Gemini 模型与 LangGraph 等框架的集成,促进了研究增强型对话式 AI 实现全面的查询处理,正如 Google-Gemini/Gemini-Fullstack-Langgraph-Quickstart 所展示的那样。尽管使用了开源的 DeepSeek-R1 模型,Perplexity/DeepResearch 仍然取得了颇具竞争力的结果,这凸显了实现质量的重要性超越了原始模型功能。
开源实现的基准测试得分逐渐下降,但许多实现仍然达到了相当不错的性能,足以满足实际应用的需求。AutoGLM-Research、HKUDS/Auto-Deep-Research 和 Camel-AI/OWL 等系统表明,通过更易于访问的模型和框架可以实现有效的研究能力,尽管与领先的商业实现相比,性能上会有所妥协。
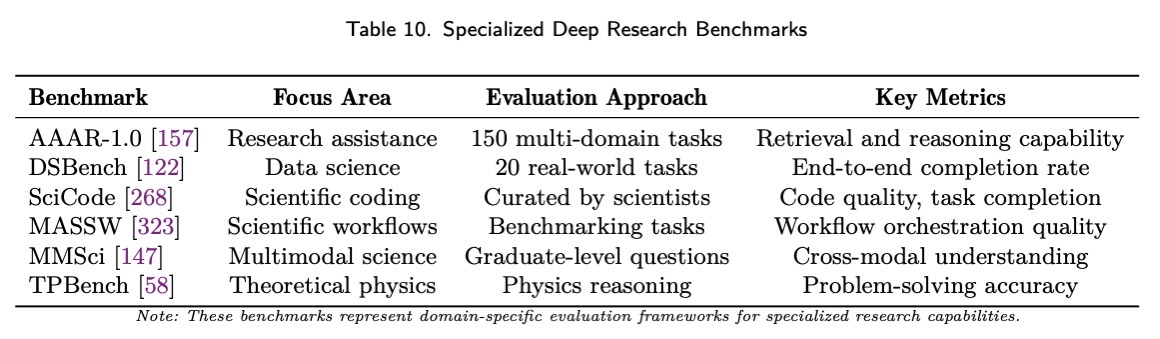
最近的基准测试开发已将评估范围扩展到更专业的研究辅助领域。AAAR-1.0 基准测试通过 150 个旨在测试检索和推理能力的多领域任务,专门评估人工智能辅助研究的潜力。领域特定方法包括 DSBench(评估数据科学 Agent 在 20 个实际任务中的能力)、SciCode(用于科学代码生成)、MASSW(用于科学工作流辅助)以及 MMSci(用于跨研究生水平材料的多模态科学理解)。ScienceQA 提供了一个全面的多模态科学基准测试,其中包含用于评估推理能力的思路链式解释。领域特定基准测试(例如用于理论物理的 TPBench 和用于研究辅助能力的 AAAR-1.0)为专业研究应用提供了更多有针对性的评估方法。DomainCodeBench 等多领域代码生成基准测试旨在系统地评估 12 个软件应用领域和 15 种编程语言的大型语言模型。LatEval 等交互式评估框架专门通过横向思维谜题评估系统处理不完整信息的能力,从而深入了解系统在不确定和模糊环境下的研究能力。诸如 Mask-DPO 之类的补充方法专注于可推广的细粒度事实性比对,以满足对可靠研究成果的关键需求。诸如 GMAI-MMBench 之类的领域特定基准测试提供了专为医疗 AI 应用设计的全面多模态评估框架,而 AutoBench 则提供科学发现能力的自动化评估,为核心研究功能提供标准化评估。其他广泛的评估框架,包括 HELM、BIG-bench 和 AGIEval,则提供了互补的评估维度。诸如 INQUIRE 之类的专业多模态基准测试将这一领域扩展到生态挑战,严格评估专家级的文本转图像检索任务,这些任务对于加速生物多样性研究至关重要。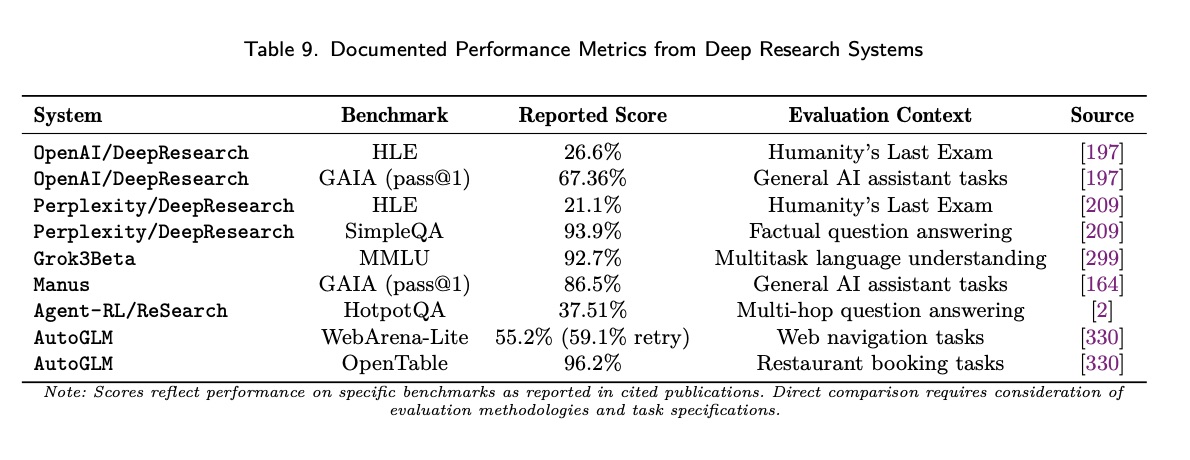
3.3.2 Qualitative Assessment Frameworks

除了数字基准之外,定性评估还能洞察实际效果:
商业系统通常表现出更强的定性性能,尤其是在输出连贯性和事实准确性方面。OpenAI/DeepResearch 生成的报告结构极其良好,包含可靠的事实内容,同时在连接不同来源方面也实现了一定的创新。Gemini/DeepResearch 在连贯性和准确性方面表现出类似的优势,但对新颖见解的重视程度略低。
一些开源实现在特定维度上展现出独特的优势。Agent-RL/ReSearch 通过其以探索为重点的方法在洞察新颖性方面取得了显著的表现,而 Grapeot/deep_research_agent 则通过强调信息验证展现出强大的事实准确性。这些专业能力凸显了深度研究生态系统中方法的多样性。
3.3.3 Efficiency and Resource Utilization Metrics

实际部署考虑因素包括计算要求和运行效率:
商业云服务提供了优化的性能和适中的响应时间,但依赖于外部基础设施并需要相关成本。Perplexity/DeepResearch 实现了尤其强大的效率指标,尽管其输出质量具有竞争力,但响应时间相对较快,token 效率也较高。
开源实现在效率指标方面呈现出更大的差异性。像 AutoGLMResearch 和 QwenLM/Qwen-Agent 这样的系统需要大量的计算资源,但可以部署在本地环境中,从而在高容量使用的情况下提供更强的控制力并节省成本。像 nickscamara/open-deep-research 这样的轻量级实现可以在资源更有限的情况下运行,但通常响应时间更长,token 效率更低。
这篇比较分析凸显了 Deep Research 生态系统中方法和能力的多样性。虽然商业实现目前在标准基准测试中表现出色,但开源替代方案在特定领域和用例中也展现出竞争力,尤其是在定制化、控制力以及针对特定应用的潜在成本效益方面具有优势。后续章节将在此分析的基础上,更详细地探讨实现技术、评估方法和应用领域。
4. Implementation Technologies and Challenges
Deep Research 系统的实际实现涉及众多技术挑战,涵盖基础设施设计、系统集成和保障措施实施。本节探讨实现有效深度研究能力的关键实现技术,以及实现可靠、高效运行必须应对的挑战。
4.1 Architectural Implementation Patterns
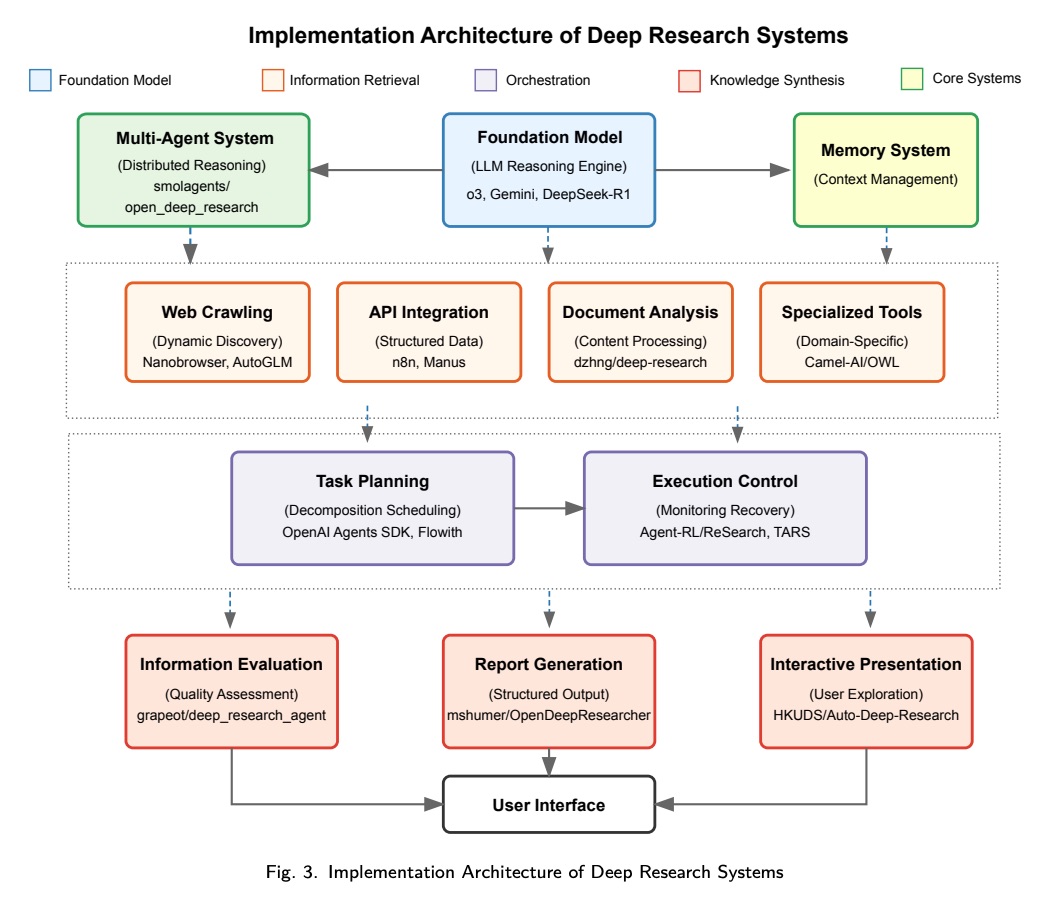
本次调查分析的各种系统揭示了几种不同的架构模式,这些模式代表了实现 Deep Research 能力的不同方法。本节将探讨四种基本架构模式:单体架构、基于 pipeline 的架构、多 Agent 架构和混合架构。对于每种模式,我们将分析其底层结构原理、组件交互、信息流机制和代表性系统。
4.1.1 Monolithic Architecture Pattern
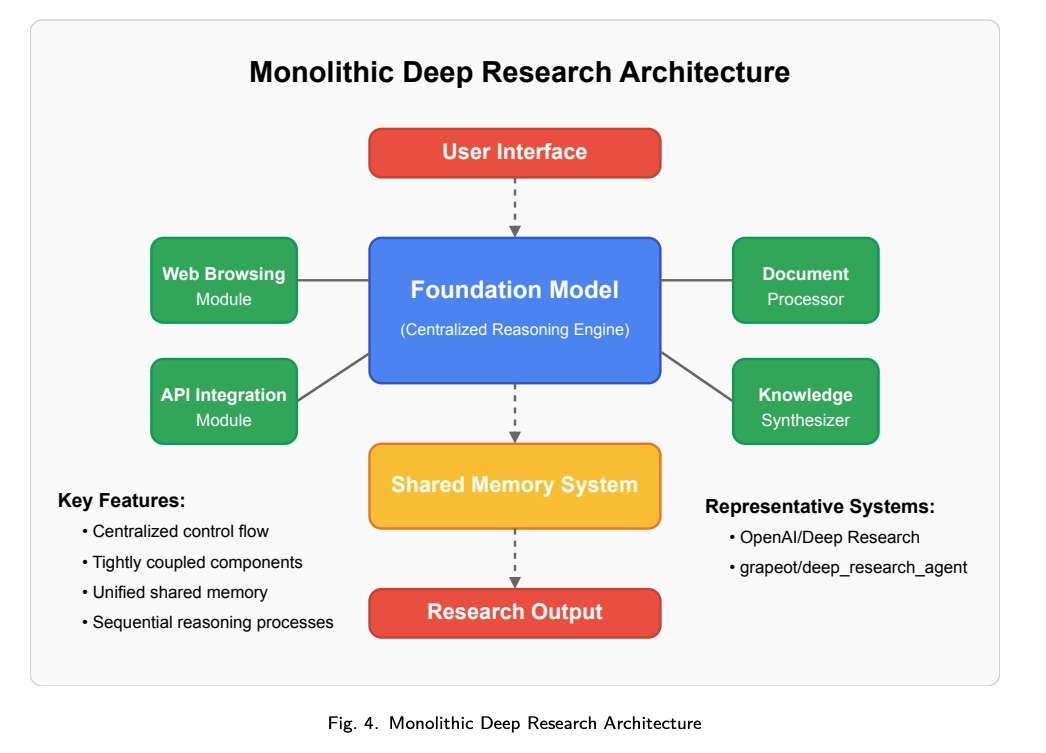
单体式实现将所有 Deep Research 功能集成到一个以核心推理引擎为中心的统一架构框架中。如图 4 所示,这些系统采用集中控制机制,并直接集成专用模块。
该架构的定义特征包括:
- Centralized Control Flow:所有操作都通过维护全局状态和执行上下文的主要推理引擎进行路由。
- Tightly Coupled Integration:专用模块(网页浏览、文档处理等)直接与中央控制器集成。
- Shared Memory Architecture:信息状态保存在所有组件可访问的集中式存储系统中。
- Sequential Reasoning Processes:操作通常遵循中央控制器定义的结构化序列。
这种架构模式通过其统一的控制结构提供了强大的一致性和推理一致性。然而,它在可扩展性方面存在挑战,并且难以并行化复杂的操作。代表性的实现包括 OpenAI/DeepResearch 和 Grapeot/deep_research_agent,它们展示了该架构如何在保持实现简单性的同时,实现跨不同信息源的一致性推理。
4.1.2 Pipeline-Based Architecture Pattern
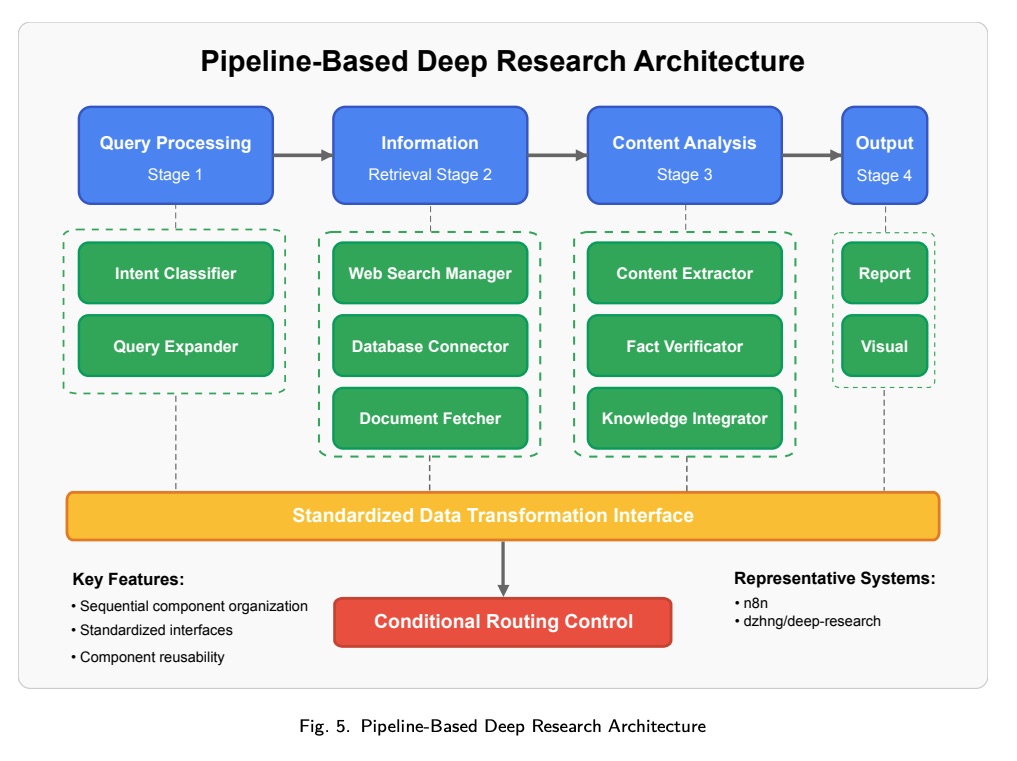
流水线架构通过一系列通过明确定义的接口连接的专用处理阶段来实现 Deep Research 功能。如图 5 所示,这些系统将研究工作流分解为离散的处理组件,并在各个阶段之间进行明确的数据转换。
Pipeline 实现的主要特征包括:
- Sequential Component Organization:研究任务通过预先定义的专门处理模块序列进行
- Standardized Interfaces:管道阶段之间清晰的数据转换规范可实现模块化组件替换
- Staged Processing Logic:每个组件实现特定的转换,对全局状态的依赖最小
- Configurable Workflow Paths:高级实现能够根据中间结果在备选处理路径之间进行条件路由
流水线架构在工作流定制和组件可重用性方面表现出色,但在处理需要跨组件迭代细化的复杂推理任务时可能会遇到困难。n8n 和 dzhng/deep-research 等系统就是这种方法的典范,它们展示了明确的工作流排序如何通过组合专用组件来实现复杂的研究自动化。
4.1.3 Multi-Agent Architecture Pattern
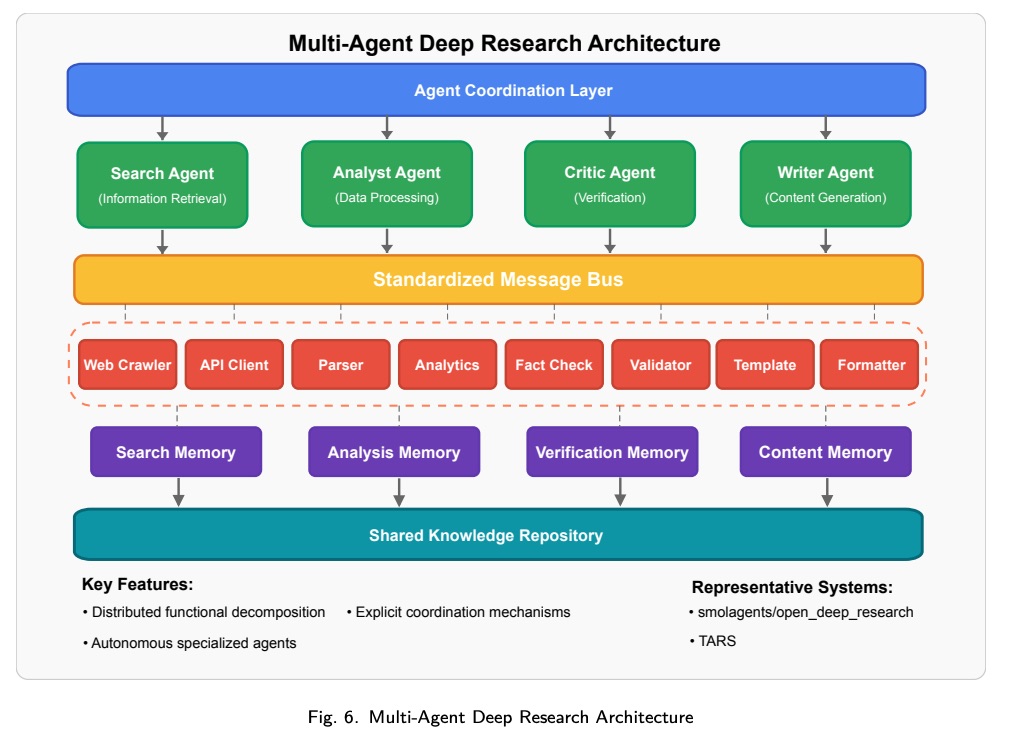
多 Agent 架构通过由专门的自主 Agent 组成的生态系统,并通过显式通信协议进行协调,从而实现深度研究能力。图 6 展示了这些系统如何在具有不同角色和职责的协作 Agent 之间分配研究功能。
多 Agent 实现的定义要素包括:
- Distributed Functional Decomposition:研究能力分布在具有明确角色的专门 Agent(searcher, analyst, critic等)中。
- Explicit Coordination Mechanisms:标准化消息传递和任务委派协议支持 Agent 间协作。
- Autonomous Decision Logic:个体 Agent 在其指定领域内保持独立的推理能力。
- Dynamic Task Allocation:高级实现方案采用基于 Agent 能力和当前工作量进行灵活的任务分配。
多 Agent 架构在执行需要多种专业能力和并行处理的复杂研究任务时表现出色。其分布式特性使其能够出色地扩展复杂的研究工作流程,但在维护各 Agent 之间的整体一致性和推理一致性方面也带来了挑战。代表性的实现包括 smolagents/open_deep_research 和 TARS,它们展示了多 Agent 协调如何通过专业化的 Agent 协作来实现复杂的研究工作流程。
4.1.4 Hybrid Architecture Pattern
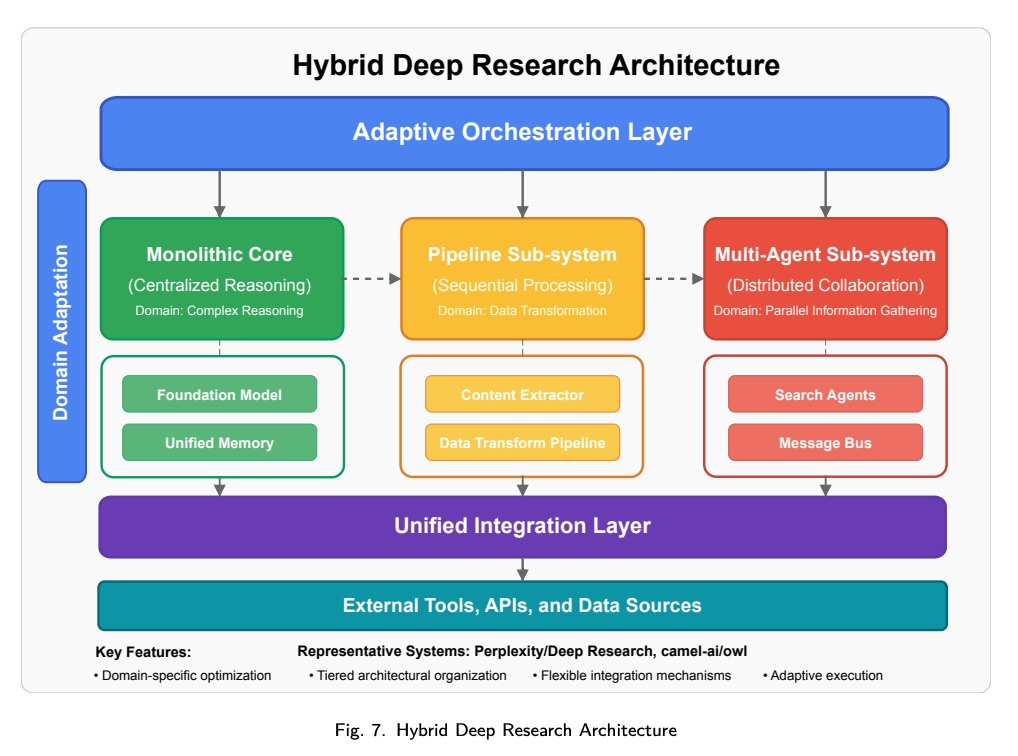
混合架构融合了多种架构模式的元素,在统一的实现中平衡各自的优势。如图 7 所示,这些系统采用战略性地整合架构方法,以满足特定的研究需求。
混合实现的主要特征包括:
- Tiered Architectural Organization:根据功能需求,在不同的系统层级采用不同的架构模式。
- Domain-Specific Optimization:根据特定领域的处理要求选择架构方法。
- Flexible Integration Mechanisms:标准化接口支持采用不同架构模式的组件之间的通信。
- Adaptive Execution Frameworks:控制机制根据任务特征动态调整处理方法。
混合架构提供了卓越的灵活性和优化机会,但也带来了实现的复杂性和潜在的集成挑战。Perplexity/DeepResearch 和 Camel-AI/OWL 等系统就体现了这种方法,它们将集中式推理与分布式信息收集和专用处理流程相结合,从而实现了复杂的研究能力和均衡的性能特征。
4.1.5 Emerging Agent Framework Ecosystems
除了上述核心架构模式之外,Deep Research 生态系统还通过专门的 Agent 框架得到了显著增强,这些框架为 Agent 开发提供了标准化组件。新兴系统整合了专门的 Ahemt 框架,这些框架以特别适合复杂研究任务的方式构建推理,这些任务需要兼具深度和广度的分析。正如 Agent 框架的全面分析中所详述的,这些系统提供了不同的 Agent 编排、执行控制和推理编排方法。
关键框架包括 LangGraph,它为语言模型应用程序提供基于图的控制流,通过显式状态管理和转换逻辑实现复杂的推理模式。谷歌的 Agent Development Kit (ADK) 提供了一个全面的 Agent 开发框架,其中包含用于工具集成、规划和执行监控的标准化接口。CrewAI 实现了一个专为多专家工作流设计的 Agent 协作框架,通过显式协调机制实现基于角色的任务分配。更多实验性框架,例如 Agno,则通过自我改进和元推理能力探索 Agent 自主性。
TapeAgents 框架提供了一种特别全面的 Agent 开发和优化方法,通过系统地记录和分析 Agent 行为,明确支持迭代改进。这些框架共同体现了向标准化 Agent 组件的持续转变,这些组件在提高开发效率的同时,还支持更复杂的推理和执行模式。
4.1.6 Architectural Pattern Comparison
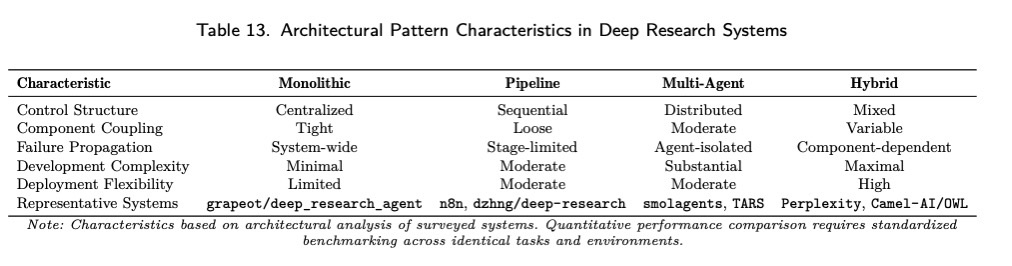
表 13 提供了这些架构模式在关键性能维度上的比较分析。
每种架构模式都具有独特的优势和局限性,这会影响其对特定 Deep Research 应用的适用性。单体架构在推理一致性和实现简便性方面表现出色,非常适合具有明确工作流程的重点研究应用。流水线架构提供卓越的可扩展性和组件可重用性,通过模块化组合实现定制化研究工作流程。多 Agent 架构提供卓越的并行化和容错能力,支持需要多种专业能力的复杂研究任务。混合架构通过战略集成平衡了这些特性,为多样化的研究需求提供灵活的优化。
架构模式的选择会显著影响系统功能、性能特征和应用适用性。随着 Deep Research 生态系统的不断发展,我们期待进一步的架构创新,结合这些基础模式的元素,以满足新兴的应用需求和技术能力。
4.2 Infrastructure and Computational Optimization

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)