大模型微调与部署课程笔记
·
一、指令数据准备与构建
- 指令微调的方法(一般先做指令微调,后做强化学习)
1)指令微调
2)强化学习反馈(需要reward model)
1)深度学习中的数据工程
- 数据工程主要任务

- 数据处理

变成
2)prompt-engineering与指令数据
(1) prompt-engineering概念(提示词工程)
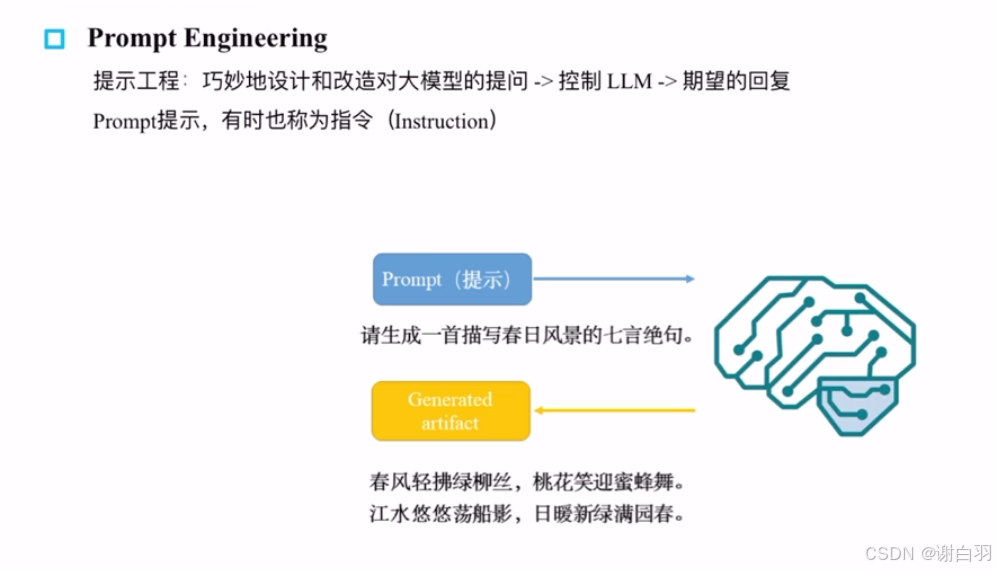
①提示词样本示例
②输入提示效果类型:zero-shot预训练的时候内容反应
③思维链提示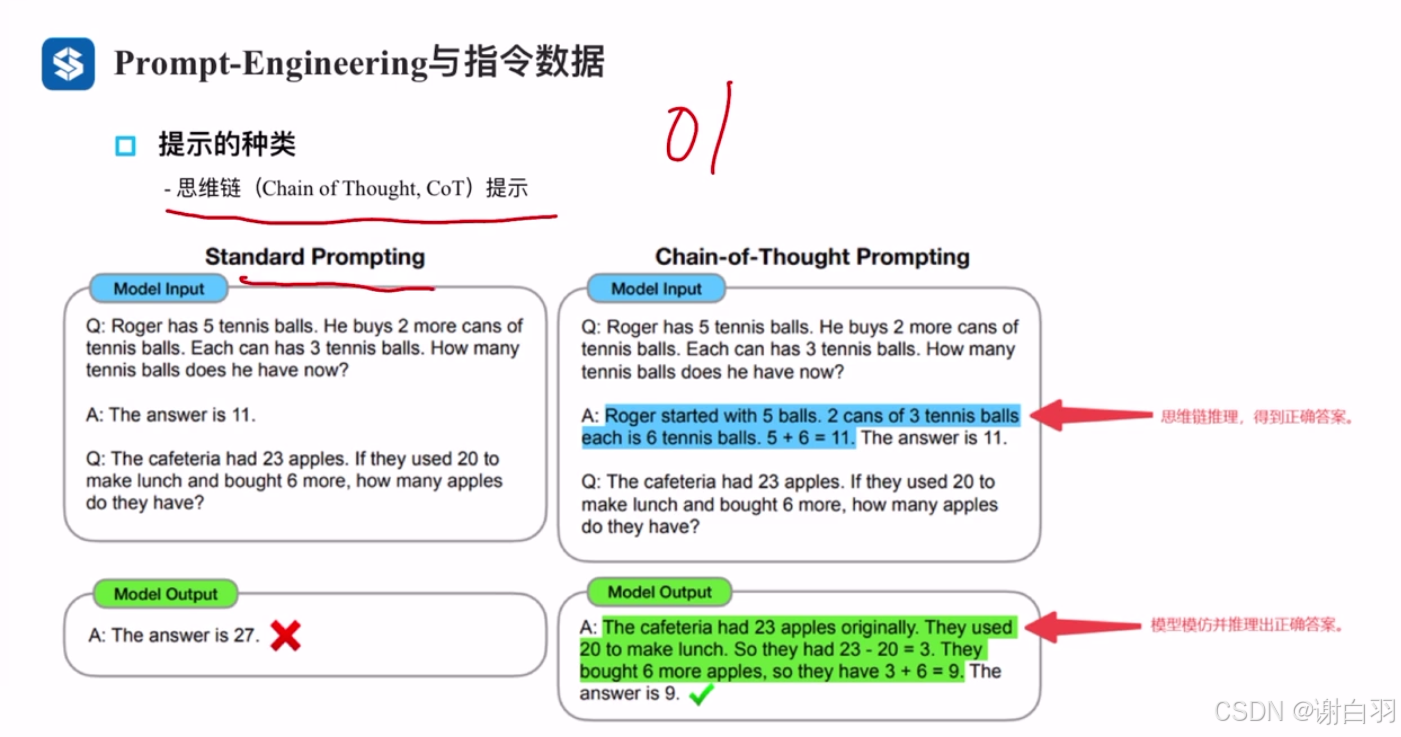
(2)指令数据
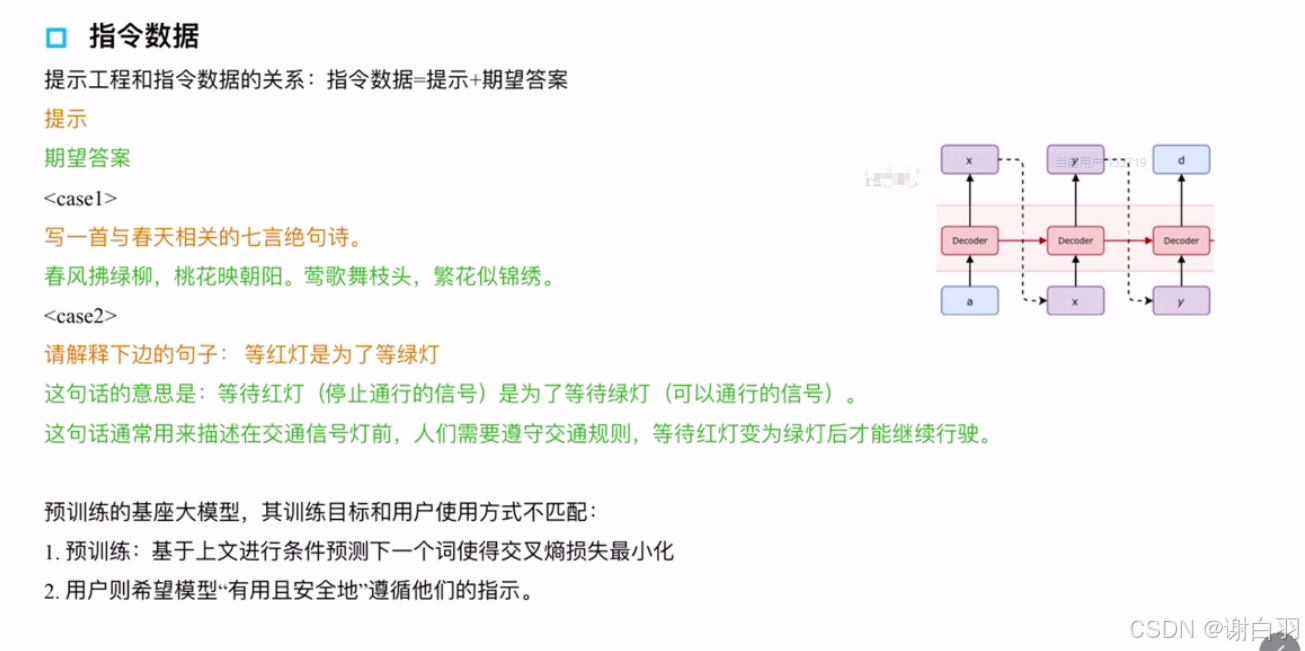
- 指令微调好处

3)构建微调指令数据

①参数解释
role:用户
assistant:大模型
②prompt由system和user构成,如果只有一轮问答,那就只有一轮user和assistant;多轮就是多个(user+assistant)
③system也叫system prompt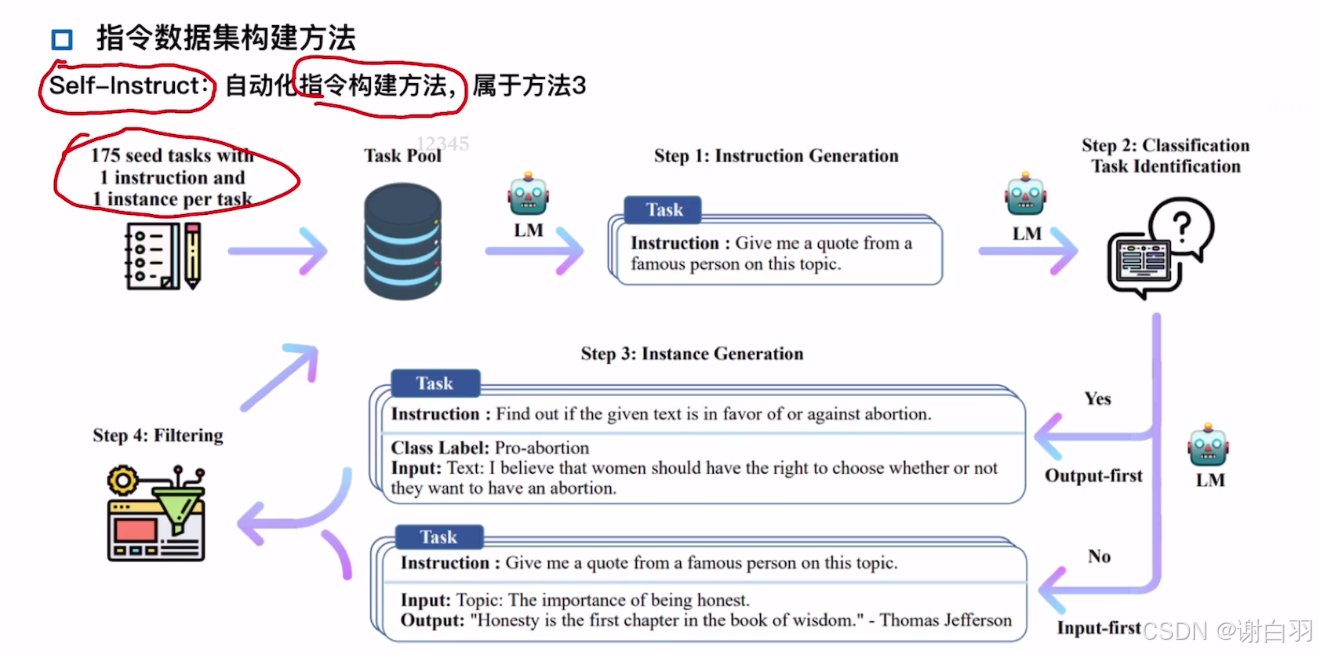
- 构建过程

- Qwen示例
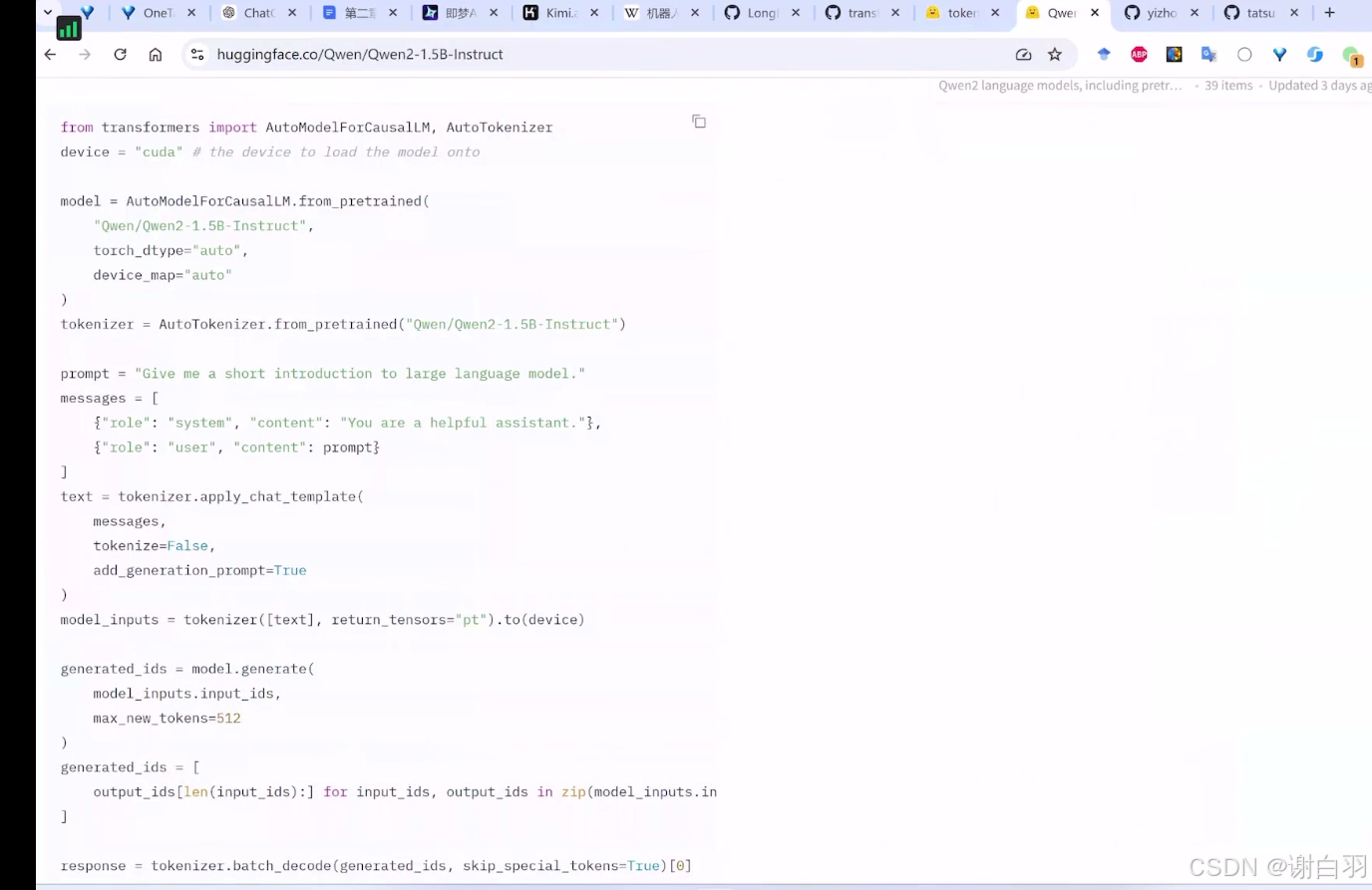
- chat——template内容
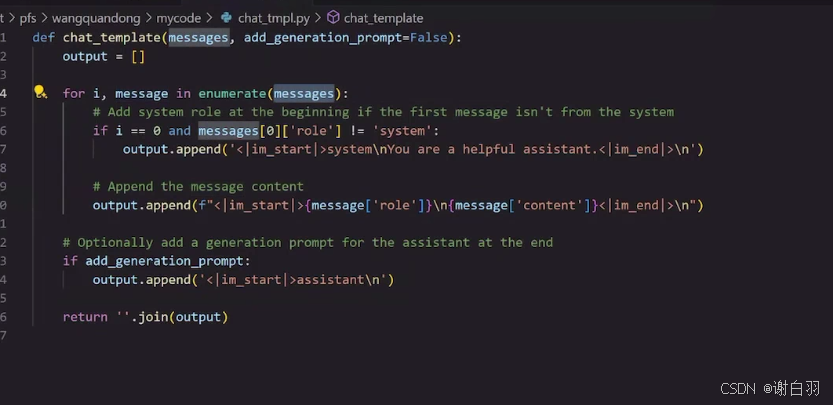
4)开源指令数据集
(1)Natural Instrutions(自然指令集,包含不同的NLP任务)
由七个部分组成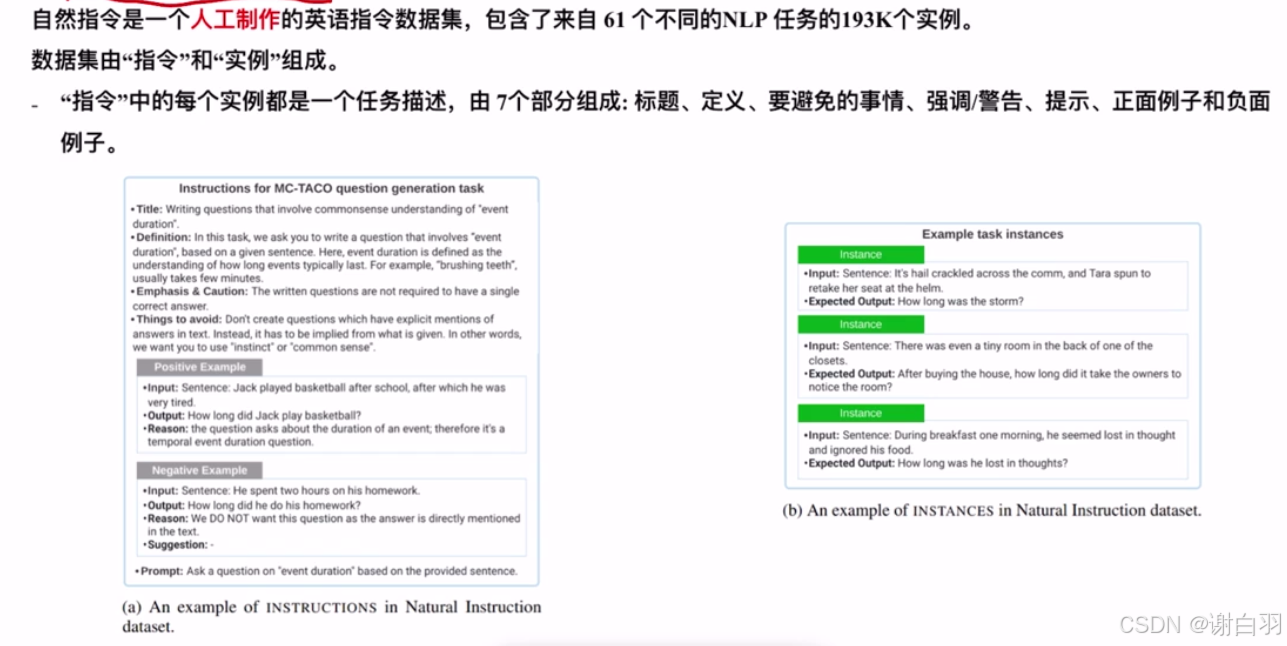
(2)Flan 2021(NLP标准英语指令集,有62个广泛的NLP基准)
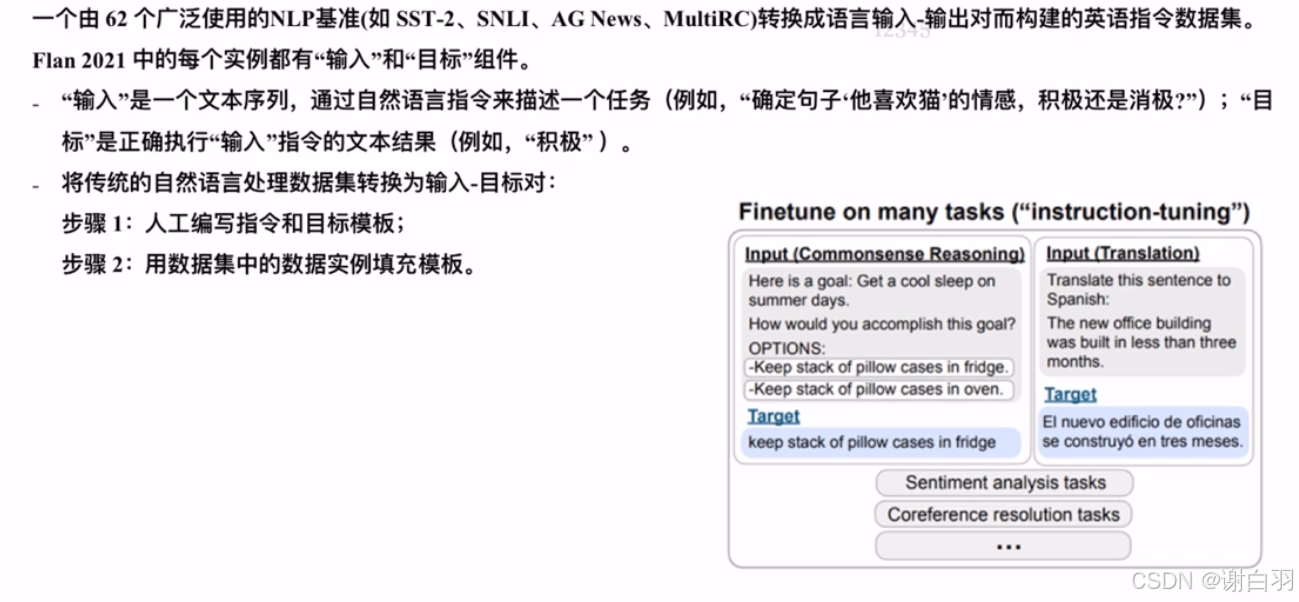
(3)Alphaca:使用instructGPT构建的数据集(利用self-instruct原理,让语言模型自主生成指令数据)
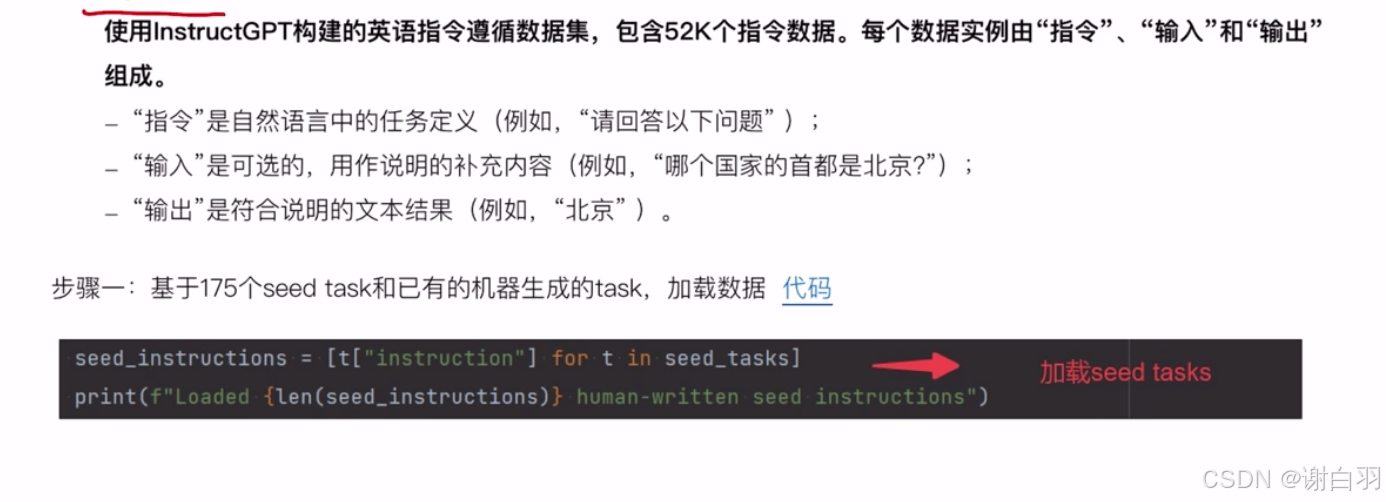
- Self-Instruct原理及使用
一种通过语言模型自主生成指令数据的方法,旨在减少对人工标注的依赖并提升模型的指令遵循能力(用种子指令生成新的指令,用现有的大模型去生成指令的回复,然后拼接生成系新的指令数据)
1)项目链接
2)三个脚本作用
①bootstrap_instructions.py:用这个脚本生成新的指令(引导生成新的instruction)
②identify_clf_or_not.py:用这个脚本查看新生成的指令是不是分类任务
③generate_instances.py:用这个脚本根据之前生成的instruction,来生成回复,并拼成单个或多个instance(也会有一些结果后处理过滤的过程,因为有些生成的质量并不是那么好)
3)脚本讲解
(1)bootstrap_instructions.py脚本
1》encode_prompt:把多个prompt 指令拼成一个字符串
2》sample_machine_instructions:随机采样也就是随机选取机器和人工的池子里面的几条指令
3》find_word_in_string:根据数据内容查找
4》post_process_gpt3_response:对GPT3回复的后处理(这里GPT3默认指的是instructGPT),基本都是过滤空的、太长或太短内容、有图片或网格或图表或文件的都不要
5》总体流程:
1.加载种子的instruction=》
2.加载大模型生成的instruction=》
3.定义判别器scorer,判别大模型生成的instruction和老的instruction,相似的就过滤掉,保证多样性=》
4.process_bar,是进度条的初始化=》
5.把机器生成的指令存到jsonl文件里面,从现有的机器instruction抽样一部分和抽取人工的instruction放到一个池子里面然后打乱拼成一条条字符串
6、这些instruction喂给GPT3,接收处理的回复,并收集这些回复
7.这些回复经过post_process_gpt3_response后处理
8.经过score打分,相似的就过滤掉
5)project1:大模型文本摘要微调时间 part1和part2
二、指令数据进阶与增强
1)指令数据重要性
2)数据好坏的度量
3)指令数据的筛选与配比
4)指令数据的扩充
5)指令数据优化案例
6)数学推理指令与思维链
三、大模型微调理论
1)指令微调基础概述
2)指令微调的基本流程和分类
3)指令微调方法:全量参数微调
4)指令微调方法:高效指令微调
5)大模型微调理论小结
6)project1 大模型文本摘要微调实践 part3
四、微调后的模型评估
1)语言模型通用能力评估
2)语言模型专项能力评估-以课程项目为例子
3)bad case 定位、问题分析及解决办法
4)project1 大模型文本摘要微调时间part4
5)project2 大模型工具调用技术实践
五、模型部署理论
1)大模型高效部署
2)主流框架部署介绍
3)Text Generation inference 详解
4)TGI整体推理流程
六、模型部署实践
1)前期准备
2)模型部署
3)服务访问
4)模型服务基准测试
七、课程总结与未来发展
1)本章概述
2)总结:模型与指令数据
3)总结:模型训练与优化
4)总结:推理优化
5)大模型微调与RAG技术
6)技术发展展望

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)