HLMEA-AAAI-2025论文翻译
实体对齐(EA)对整合多源知识图谱(KG)至关重要。传统无监督EA方法试图消除人工干预,但常受限于准确率。随着大语言模型(LLM)兴起,利用其能力实现EA成为新方向,但面临两大挑战:如何构建基于LLM的EA问题框架,以及如何提取LLM中的背景知识实现无人工干预的EA。本文提出HLMEA——基于混合语言模型的无监督EA方法,将EA任务构建为筛选-单选问题,协同整合小语言模型(SLM)与LLM:SLM
文章目录
- 本文是对原论文学习过程中的中文翻译,仅用于学术交流与科普分享,无任何商业目的。
- 翻译已尽力忠实原文,但受限于译者水平,可能存在偏差;术语或公式若有疑义,请以原文为准。
- 若原作者、期刊或版权方提出异议,译者将在收到通知后 24 小时内删除本文并致歉。
- 欢迎读者引用原文,并请注明出处
HLMEA: Unsupervised Entity Alignment Based on Hybrid Language Models
HLMEA:基于混合语言模型的无监督实体对齐方法
Xiongnan Jin, Zhilin Wang, Jinpeng Chen, Liu Yang, Byungkook Oh, Seung-won Hwang, Jianqiang Li
摘要
实体对齐(EA)对整合多源知识图谱(KG)至关重要。传统无监督EA方法试图消除人工干预,但常受限于准确率。随着大语言模型(LLM)兴起,利用其能力实现EA成为新方向,但面临两大挑战:如何构建基于LLM的EA问题框架,以及如何提取LLM中的背景知识实现无人工干预的EA。本文提出HLMEA——基于混合语言模型的无监督EA方法,将EA任务构建为筛选-单选问题,协同整合小语言模型(SLM)与LLM:SLM基于KG三元组生成的文本表示筛选候选实体,LLM进一步精筛出语义最匹配的实体。通过迭代自训练机制,SLM能从LLM输出中蒸馏知识,逐步增强混合模型的EA能力。基准数据集实验表明,HLMEA显著优于无监督乃至有监督EA基线,证明其在大规模KG上可扩展的有效性。代码与数据详见https://github.com/xnjin-ai/HLMEA。
引言
知识图谱(KG)通过符号化图结构表述人类知识,使机器能理解语义逻辑。随着KG建模技术发展,各领域已构建大量KG以支持问答、推理、检索等应用(Wang等2024b;Li等2024)。然而由于异构性与数据源不完整性,KG间的互联互通存在普遍困难。例如苹果联合创始人史蒂夫·乔布斯在不同KG中可能被标识为S. Jobs、Steve_Jobs等不同关系名称,甚至以多语言形式出现。
实体对齐(EA)旨在通过识别语义等价实体建立KG间的关联,为实现KG融合的关键技术。传统EA方法在人工标注监督下,将符号化KG嵌入向量空间后通过嵌入距离度量相似度(Yang等2019)。半监督EA方法采用自举训练等技术降低对高成本标注的依赖(Sun等2018),但仍需人工参与。无监督EA研究通过非采样校准等机制利用KG自包含信息实现对齐(Li和Song2022),亦有研究引入多模态预训练模型提升精度(Liu等2021)。
随着GPT-4(OpenAI 2023)等大语言模型(LLM)的出现,传统信息技术正面临革命性变革。基于LLM的实体对齐(EA)是利用大模型能力进一步提升EA性能的新方向,但面临两大挑战:其一是如何构建适配LLM的EA问题框架。直接方法是将源实体与所有目标实体组成提示文本输入LLM进行匹配,但单个实体通常包含数百至数千条三元组,而知识图谱可能拥有数百万实体。简单注入全部实体信息会导致提示文本过长,可能超出上下文长度限制或产生难以接受的推理耗时。
LLM通过海量多样化文本预训练,能够掌握广泛的人类知识,甚至在文本摘要等特定NLP任务中超越人类表现。但对于EA任务,由于计算成本过高及幻觉问题(Ji et al. 2023),使用LLM逐对评估实体相似度并不现实。此外,在无监督场景下缺乏人工标注数据,无法对LLM进行EA专项微调。因此第二大挑战在于:如何从LLM中提取背景知识来解决无监督EA任务。
本文提出新型 H ‾ \underline{\mathbf{H}} H混合 L ‾ \underline{\mathbf{L}} L语言模型无监督EA解决方案HLMEA。针对第一项挑战,我们将EA问题重构为过滤-单选任务:首先设计实体文本表征(TRE)格式实现高信息密度的实体描述;然后基于预训练嵌入向量,使用SLM(如BERT等轻量预训练模型)对源实体 s e {se} se的候选目标实体tes进行初筛,缩减搜索空间与提示文本长度;最后由LLM从筛选结果中确定对齐实体。
针对第二项挑战,HLMEA通过LLM与SLM的迭代协同实现知识迁移:提出SLM自训练机制,基于LLM输出生成训练数据对SLM进行微调;通过 n n n次LLM选择(标注)及多数投票机制降低输出不确定性;训练数据生成机制确保SLM相似度更高的候选实体获得更多投票。如图1所示,HLMEA通过多轮迭代执行1-4步骤,使SLM逐步吸收LLM的背景知识提升相似度度量能力,同时LLM也能受益于SLM改进后的候选实体质量。
近期提出的ChatEA采用KG编码转换增强LLM对知识图谱的理解,结合基于嵌入的Simple-HHEA等方法进行候选过滤与LLM推理。但ChatEA需依赖大规模LLM及额外实体描述才能实现高性能。相比之下,HLMEA无需这些依赖条件,仅需Qwen-7B等较小模型即可实现精确EA,在缺乏高质量描述数据的场景中更具资源效率与灵活性。本文主要贡献如下:
-
我们将实体对齐(EA)任务形式化为过滤加单选问题,以利用大语言模型(LLM)提升准确率。提出文本关系表达(TRE)方法,用简洁且富有表现力的文本格式描述符号化实体。基于TRE,小语言模型(SLM)通过嵌入距离度量相似性来筛选候选实体,从而缩减LLM搜索空间和提示词规模。最终由LLM从SLM预筛的候选集中识别对齐实体。
-
提出无监督实体对齐框架HLMEA,通过促进LLM与SLM的协同交互提升性能。该框架通过精心设计的自训练机制,使SLM能蒸馏LLM的背景知识,同时LLM可逐轮利用过滤后候选实体质量提升的优势。
-
在基准数据集上的大量实验表明,HLMEA在效果和扩展性方面均优于无监督及有监督基线方法。
相关工作
有监督实体对齐。现有EA方法大多基于人工标注,HMAN利用距离 ℓ 1 {\ell }_{1} ℓ1在共享向量空间搜索等价实体。BERT-INT定义成对边际损失微调BERT模型,采用交互式知识图谱嵌入获取对齐实体对。MSNEA提出多模态知识嵌入与对比学习方法实现跨模态增强融合。半监督方法如BootEA通过自举迭代标注扩充训练数据,SEA采用度感知嵌入和循环一致损失整合未标注实体。DuGa-DIT基于双门图注意力网络进行批次标签迭代训练。但这些方法依赖耗时费力的人工标注,制约了应用范围。
无监督实体对齐。UPLR通过非采样校准逐步增强来降低噪声影响。SelfKG设计相对相似度度量规避正样本监督。SLOTAlign将EA转化为最优传输问题联合优化。部分研究引入图像描述等多模态信息,如EVA以图像为枢轴融合多模态特征,XGEA通过图神经网络整合结构细节,MEAformer动态预测模态间相关系数实现细粒度对齐。本文提出无需辅助数据的无监督EA方法,通过问题重构实现LLM与SLM的能力互补增强。
问题定义
知识图谱表示为 K G = ( S , P , O ) \mathcal{K}\mathcal{G} = \left( {\mathcal{S},\mathcal{P},\mathcal{O}}\right) KG=(S,P,O),其中 S , P \mathcal{S},\mathcal{P} S,P和 O \mathcal{O} O分别表示主语、谓词和宾语集合。每个主语对应实体,宾语可为实体或属性。谓词连接实体间关系或实体-属性间特性。EA旨在发现两个不同KG中的相同实体,其形式化定义为:
定义1(实体对齐:EA)给定源知识图谱 K G s \mathcal{K}{\mathcal{G}}_{s} KGs和目标知识图谱 K G t \mathcal{K}{\mathcal{G}}_{t} KGt,EA旨在计算出一个对齐实体对列表,使得 A K G s , K G t = {\mathcal{A}}_{\mathcal{K}{\mathcal{G}}_{s},\mathcal{K}{\mathcal{G}}_{t}} = AKGs,KGt= { ( s e , t e ) ∈ E s × E t , E s ∈ K G s , E t ∈ K G t ∣ s e ∼ t e } \left\{ {\left( {{se},{te}}\right) \in {\mathcal{E}}_{s} \times {\mathcal{E}}_{t},{\mathcal{E}}_{s} \in \mathcal{K}{\mathcal{G}}_{s},{\mathcal{E}}_{t} \in \mathcal{K}{\mathcal{G}}_{t} \mid {se} \sim {te}}\right\} {(se,te)∈Es×Et,Es∈KGs,Et∈KGt∣se∼te},其中 ∼ \sim ∼和 E \mathcal{E} E分别表示等价关系和实体集合。
本文旨在通过利用大型语言模型(LLMs)中包含的背景知识,在无需人工干预的情况下解决EA问题。基于LLM的EA问题形式化定义如下:
定义2(基于LLM的实体对齐:LEA)给定源实体 s e ∈ K G s {se} \in \mathcal{K}{\mathcal{G}}_{s} se∈KGs和目标实体 t e ∈ K G t {te} \in \mathcal{K}{\mathcal{G}}_{t} te∈KGt,LEA的目标是通过精心设计的提示词,借助LLM的能力选择最相似的目标实体 t e te te。提示词通常包含描述任务的指令,以及关于 s e {se} se和 t e {te} te的符号-语义信息。
提出方法
本节介绍提出的基于混合语言模型的无监督实体对齐方法HLMEA。如图1所示,HLMEA包含四个模块:目标实体选择、LLM标注、多数投票和SLM自训练。在第0轮步骤1中,目标实体选择基于SLM为给定源实体 s e {se} se筛选出前 k k k个候选目标实体 t e s tes tes。接着在步骤2中,LLM标注模块构建由指令、演示和查询组成的提示词,发送给LLM以识别最相似的 t e te te。步骤3中,多数投票将LLM标注重复 n n n次并聚合结果,以降低LLM幻觉带来的不确定性。步骤4中,SLM自训练根据LLM输出分布生成训练数据并对SLM进行微调。随后HLMEA在每轮迭代中重复步骤1至4,共执行 r r r轮。通过这种方式,混合语言模型相互作用、协同提升性能。
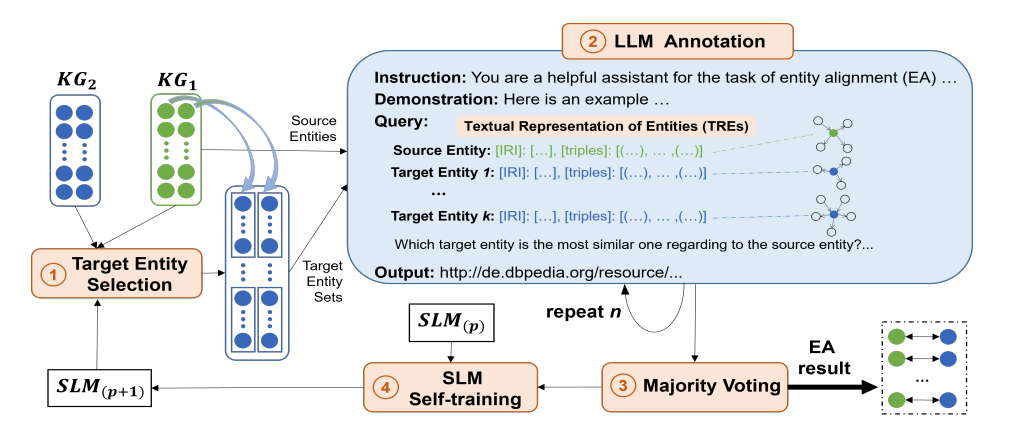
图1:无监督实体对齐方法HLMEA架构。 S L M ( p ) {\mathrm{{SLM}}}_{\left( p\right) } SLM(p)表示第 p . S L M ( 0 ) p.{\mathrm{{SLM}}}_{\left( 0\right) } p.SLM(0)轮微调后的SLM, p . S L M ( 0 ) p.{\mathrm{{SLM}}}_{\left( 0\right) } p.SLM(0)代表SLM原始版本。
目标实体选择
给定 s e {se} se, t e s tes tes通常是EA任务中整个目标KG实体 E t ∈ K G t {\mathcal{E}}_{t} \in \mathcal{K}{\mathcal{G}}_{t} Et∈KGt。但由于LLM输入上下文限制,难以将所有 E t {\mathcal{E}}_{t} Et信息放入提示词,特别是当 K G t \mathcal{K}{\mathcal{G}}_{t} KGt规模较大时。尽管近期提出了无限上下文变换器,巨大推理成本和GPU内存占用问题仍然存在。因此,目标实体选择设计为基于SLMs筛选前 k k k个相似 t e s tes tes以减少候选数量和提示词长度。如此,LLMs便能融合SLM的相似性度量能力来执行LEA标注。
首先将实体的符号化表示转化为文本输入SLM以度量实体间相似度。直观上,实体文本表示(TRE)可通过简单聚合相关属性和关系三元组生成。但一个实体可能包含数百或数千个三元组,这就需要文本剪枝。因此,我们从每个属性、关系输出和关系输入三元组中各选取 m m m个三元组。关系三元组被分类为关系输出和关系输入子集以确保均衡选择。这种划分避免了仅选择关系三元组(纯出向或纯入向)的偏差。谓词指导三元组选择过程,为不同实体提供有价值的识别信息。受TF-IDF启发,谓词得分计算如下:
P F ( p , e ) = ∣ triple ( e ) ( p ) ∣ / ∣ triple ( e ) ( ⋅ ) ∣ (1) {PF}\left( {p,e}\right) = \left| {{\operatorname{triple}}_{\left( e\right) }\left( p\right) }\right| /\left| {{\operatorname{triple}}_{\left( e\right) }\left( \cdot \right) }\right| \tag{1} PF(p,e)= triple(e)(p) / triple(e)(⋅) (1)
IKF ( p , K G ) = ∣ entity ( K G ) ( p ) ∣ / ∣ entity ( K G ) ( ⋅ ) ∣ (2) \operatorname{IKF}\left( {p,\mathcal{{KG}}}\right) = \left| {{\operatorname{entity}}_{\left( \mathcal{{KG}}\right) }\left( p\right) }\right| /\left| {{\operatorname{entity}}_{\left( \mathcal{{KG}}\right) }\left( \cdot \right) }\right| \tag{2} IKF(p,KG)= entity(KG)(p) / entity(KG)(⋅) (2)
P F − I K F ( p , K G ) = P F ( p , e ) × I K F ( p , K G ) (3) {PF} - {IKF}\left( {p,\mathcal{{KG}}}\right) = {PF}\left( {p,e}\right) \times {IKF}\left( {p,\mathcal{{KG}}}\right) \tag{3} PF−IKF(p,KG)=PF(p,e)×IKF(p,KG)(3)
其中 triple ( e ) ( p ) {\operatorname{triple}}_{\left( e\right) }\left( p\right) triple(e)(p)表示实体 e e e中谓词为 p p p的三元组,实体 y ( K G ) ( p ) {y}_{\left( \mathcal{K}\mathcal{G}\right) }\left( p\right) y(KG)(p)代表知识图谱中所有包含 p p p的三元组对应的实体。 P F ( ⋅ ) \mathrm{{PF}}\left( \cdot \right) PF(⋅)和 IKF ( ⋅ ) \operatorname{IKF}\left( \cdot \right) IKF(⋅)分别衡量 p p p在特定 e e e内的重要性及其在知识图谱中的普遍性。根据PF-IKF分数筛选出前 m m m个谓词,若存在多个三元组则随机选取一个。最后缩写知识图谱域名(如http://dbpedia.org/resource/)以精简文本,这种缩写不会导致信息丢失,因为域名和名称已在实体IRI中描述,且同一知识图谱内所有实体通常共享相同域名前缀。表1展示了TRE的示例。

表1:实体的文本表示(TRE)
其次,如图2所示,基于TRE和SLM检索前 k k k个候选 t e s tes tes。通过SLM从TRE推断实体嵌入,使用中心矩差异(CMD)计算成对相似度 sim ( s e , t e 1 ) , … , sim ( s e , t e t ) \operatorname{sim}\left( {{se},t{e}_{1}}\right) ,\ldots ,\operatorname{sim}\left( {{se},t{e}_{t}}\right) sim(se,te1),…,sim(se,tet),该距离度量通过量化中心矩差异来衡量相似性。为简化计算,设变量 a a a和 b b b分别为0和1,CMD值越小表明两个实体嵌入越相似。随后按相似度降序排列 t e s tes tes,选取前 k k k个候选 t e s tes tes供LLMs进一步区分。
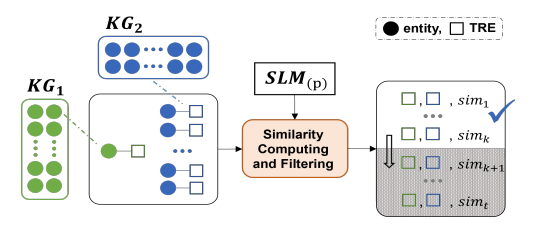
图2:基于TRE和SLM的目标实体选择
LLM标注与多数表决
LLM标注通过精心设计的提示词,从筛选的 t e s tes tes中识别实体对齐关系。提示词包含指令和查询:指令将EA任务描述为单选题并陈述知识三元组,查询包含 s e {se} se和 k t e s {ktes} ktes的TRE。鉴于LLM输出因幻觉问题存在不稳定性,需执行 n n n次标注以降低不确定性,并采用多数表决根据相对多数原则选择代表性结果。表2展示LLM输出分布示例,数字表示命中次数,下划线tes为多数表决后的LEA结果。若多个top tes命中次数相同,则选择排名最靠前的 t e {te} te以体现SLM的选择倾向。

表2:大语言模型输出分布示例。圆圈数字表示测试实体与SLM相似度的排名,数值越小相似度越高
SLM自训练方法
每轮迭代中对SLM进行微调,从LLM中蒸馏知识以提升SLM实体嵌入效果。自训练数据格式为 ( T R E s e i , T R E p o s i , T R E n e g i ) \left( {{TR}{E}_{s{e}_{i}},{TR}{E}_{{po}{s}_{i}},{TR}{E}_{{ne}{g}_{i}}}\right) (TREsei,TREposi,TREnegi),其生成基于LLM输出分布。 T R E s e i , T R E p o s i , T R E n e g i {TR}{E}_{s{e}_{i}},{TR}{E}_{{po}{s}_{i}},{TR}{E}_{{ne}{g}_{i}} TREsei,TREposi,TREnegi分别表示 i t h s e {i}^{th}{se} ithse的TRE、正样本和负样本。正样本采用多数投票结果,负采样原理是SLM判定相似度更高的测试实体应获得更多LLM标注命中。具体而言,将 t e {te} te按命中次数降序排列后,对比命中次序与SLM相似度次序,选取首个违反次序且相似度排名最小(正样本除外)的 t e {te} te作为负样本。
例如表2中示例实体http://dbpedia.org/resource/Frank_Simek对应的测试实体、SLM相似度排名与命中数排名为:Frank_Simek-①-①、Will_Lee_(音乐家)-②-③、Frank_Langella-③-④、Frank_Wiblishauser-④-②、Frank_Gatski-⑤-⑤。因此首选违反排序的Will_Lee_(音乐家)作为负样本,使其嵌入向量远离示例实体嵌入。最终使用构建的训练数据微调 S L M ( p ) {\mathrm{{SLM}}}_{\left( p\right) } SLM(p),通过成对边际损失生成 S L M ( p + 1 ) {\mathrm{{SLM}}}_{\left( p + 1\right) } SLM(p+1)供下一轮使用。
实验验证
我们在基准数据集上开展实验以验证HLMEA方法的有效性,拟解决的研究问题如下:
-
(Q1) HLMEA在基准数据集上是否优于当前最先进(SOTA)的无监督EA方法?
-
(Q2) HLMEA能否在不损害EA性能的前提下,有效压缩实体信息以适应大语言模型(LLMs)?
-
(Q3) 大语言模型(LLM)与小语言模型(SLM)的协同作用是否能提升EA性能?
-
(Q4) HLMEA各组件及变量对EA任务的关键性如何?
实验设置
数据集。采用九个广泛使用的EA数据集: D B P 15 K Z H − E N , J A − E N , F R − E N DBP15{\mathrm{K}}_{{ZH} - {EN},{JA} - {EN},{FR} - {EN}} DBP15KZH−EN,JA−EN,FR−EN、 D B P 15 K D E − E N , F R − E N DBP15K{}_{{DE} - {EN},{FR} - {EN}} DBP15KDE−EN,FR−EN、 D W 15 K V 1 、 D Y 15 K V 1 DW15K V1、DY15K V1 DW15KV1、DY15KV1及 D B P 100 K D E − E N , F R − E N DBP100{\mathrm{K}}_{{DE} - {EN},{FR} - {EN}} DBP100KDE−EN,FR−EN。其中DW15K V1与DY15K V1是英语单语跨知识图谱数据集,其余是为测试跨语言实体对齐能力构建的双语单知识图谱数据集。 D B P 100 K D E − E N , F R − E N V 1 DBP100{\mathrm{K}}_{{DE} - {EN},{FR} - {EN}}\mathrm{\;V}1 DBP100KDE−EN,FR−ENV1是用于验证EA方法扩展性的大规模数据集,包含10万组对齐实体对。
基线方法。将HLMEA与有监督和无监督EA基线对比。有监督基线基于人工标注训练EA模型,无监督基线无需人工标注执行EA,HLMEA属于无监督范畴。
评估指标。沿袭前人研究,采用Hit@ k ( k = 1 , 3 , 5 , 10 , 20 ) k\left( {k = 1,3,5,{10},{20}}\right) k(k=1,3,5,10,20)和平均倒数排名(MRR)评估HLMEA有效性。另使用LLM准确率(LA)衡量SLM筛选的top- k k k目标实体识别能力,其计算公式为 L A = H i t @ 1 / H i t @ k \mathrm{{LA}} = \mathrm{{Hit}}@1/\mathrm{{Hit}}@k LA=Hit@1/Hit@k。
实验环境。基于Python 3.9.18和PyTorch 2.1.2实现HLMEA,在运行Ubuntu 22.04的服务器上完成实验,硬件配置为AMD Ryzen 9 7950X处理器、128GB内存及NVIDIA RTX A6000显卡。
参数设置。采用的大语言模型包括闭源ChatGPT(OpenAI 2022)(gpt-3.5-turbo-1106版)、ERNIE(BaiduResearch 2023)(ERNIE-3.5-8K-0329版)及较小规模开源模型Qwen(Bai et al. 2023)(7B版)。预训练多语言模型E5(Wang et al. 2024a)、LaBSE(Feng et al. 2022)、MPNet和MiniLM(Reimers and Gurevych 2019)作为SLM。优化器选用AdamW(Loshchilov and Hutter 2019),学习率设为 1 e − 5 1{\mathrm{e}}^{-5} 1e−5。为降低LLM使用成本,采用 20 % {20}\% 20%数据通过LLM标注自监督训练SLM,最终报告剩余 80 % {80}\% 80%数据的HLMEA推理结果。LLM标注重复次数 n n n与候选实体数量top- k k k设定在 [ 3 , 20 ] \left\lbrack {3,{20}}\right\rbrack [3,20]区间。
(Q1) 基准数据集主要结果
表3展示了DBP15K上单模态与多模态无监督实体对齐(EA)方法的对比评估结果。多模态方法整合了图像、描述等辅助信息,而单模态方法仅利用数据集自身信息(如我们的HLMEA)。基于非采样校准和多视角结构学习等技术,UPLR和SLOTAlign在单模态类别中表现优异。多模态方法因外部信息的互补利用超越了现有单模态方法。配备ERNIE和LaBSE的HLMEA在几乎所有单模态方法中取得最佳性能,其平均Hit@1分数甚至优于多模态EA方法。这得益于HLMEA通过筛选与单选问题设计,协同融合了LLM(大语言模型)与SLM(小语言模型)的能力。多模态MEAformer在DBP 15 K J A − E N {15}{\mathrm{\;K}}_{{JA} - {EN}} 15KJA−EN数据集上创下最高分,可能因为高质量图像弥补了语言语法差异带来的困难。
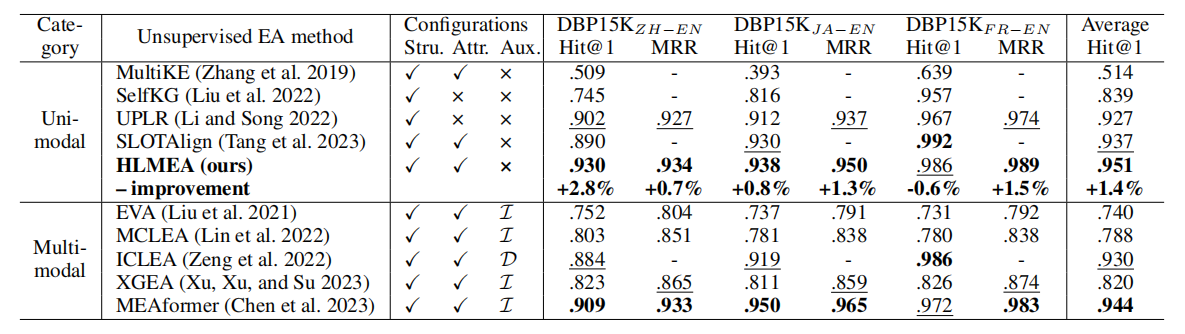
表3:DBP15K双语数据集上无监督实体对齐(EA)在Hit@1和MRR指标上的结果。根据是否融入辅助信息,EA方法分为单模态和多模态两类。加粗与下划线数字分别表示对应类别的最优和次优得分。 I \mathcal{I} I与 D \mathcal{D} D分别代表图像和描述信息。
表4呈现了DBP15K、DW15K和DY15K V1数据集的EA结果。我们选择采用 20 % {20}\% 20%种子(人工标注)进行训练的监督式EA方法作为基线,因目前尚未有无监督方法的公开记录。RDGCN通过建模主关系图与对偶关系图的注意力交互获得次优成绩。提出的HLMEA在零种子条件下,平均Hit@1分数以11.6%的优势超越RDGCN,这归因于HLMEA将LLM的背景知识与SLM的预训练语言知识适配到EA任务中。如表5所示,在DBP100K V1数据集上该差距扩大至23.1%,证明了HLMEA的可扩展性。表4和表5中采用的LLM与SLM分别为ChatGPT和LaBSE。

表4:DBP15K、DW15K和DY15K V1数据集上的实验结果。加粗及带下划线的数字分别表示最优结果与次优结果。

表5:DBP100K V1数据集上的实体对齐结果。加粗及带下划线的数字分别表示最优和次优结果。
(Q2) 实体信息压缩的影响
HLMEA通过TREs和SLM过滤压缩实体信息,将每个实体的三元组数量减少至 m m m,候选测试集缩减至 k k k。图3(a)显示配备Qwen和LaBSE的HLMEA在DY15K V1数据集上( m ( k m(k m(k设置与 m m m相同)的R0结果。当 m m m值较小时,LLM输入上下文规模和各次推理时间自发降低,而EA性能反而提升并在 m = 5 m = 5 m=5时达到最高Hit@1。这表明HLMEA通过剪枝实体信息并构建合适提示,有效激发了LLM处理EA任务的能力。
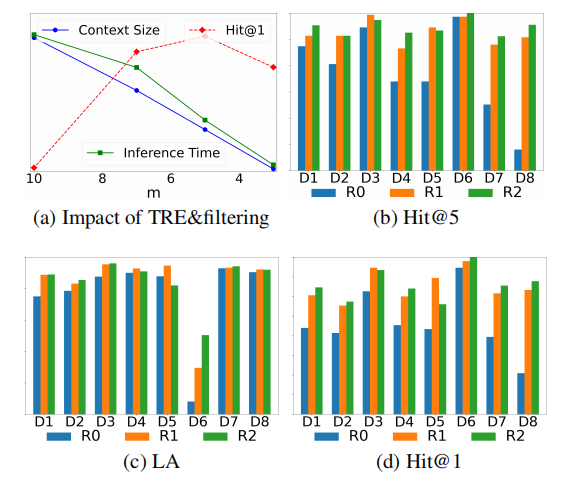
图3:TRE与SLM过滤的影响(a)——上下文规模区间[600,2000]token、Hit@1值域 [ 0.8 , 1 ] \left\lbrack {{0.8},1}\right\rbrack [0.8,1]、推理时间范围 [ 1 , 2.6 ] \left\lbrack {1,{2.6}}\right\rbrack [1,2.6]秒;以及LLM与SLM协作(b至d)——D1至D8分别表示 D B P 15 K Z H − E N {\mathrm{{DBP15K}}}_{{ZH} - {EN}} DBP15KZH−EN、DBP 15 K J A − E N {15}{\mathrm{\;K}}_{{JA} - {EN}} 15KJA−EN、DBP 15 K F R − E N {15}{\mathrm{\;K}}_{{FR} - {EN}} 15KFR−EN、 D B P 15 K D E − E N V 1 , D B P 15 K F R − E N V 1 , D Y 15 K V 1 {\mathrm{{DBP15K}}}_{{DE} - {EN}}\mathrm{V}1,{\mathrm{{DBP15K}}}_{{FR} - {EN}}\mathrm{V}1,\mathrm{{DY}}{15}\mathrm{K}\mathrm{V}1 DBP15KDE−ENV1,DBP15KFR−ENV1,DY15KV1、 D B P 100 K D E − E N V 1 {\mathrm{{DBP100K}}}_{{DE} - {EN}}\mathrm{\;V}1 DBP100KDE−ENV1和 D B P 100 K F R − E N V 1 {\mathrm{{DBP100K}}}_{{FR} - {EN}}\mathrm{\;V}1 DBP100KFR−ENV1。
(Q3) 大语言模型与小语言模型的协作
为验证LLM与SLM协作效能,图3记录了HLMEA各轮次表现。Hit@5分数体现SLM筛选含真实值高质量候选的能力。如图3(b)所示,从R0到R1轮SLM性能显著提升,多数情况下持续增长,表明SLM通过自训练机制有效吸收了LLM的背景知识。图3©展示LLM从top- k k k候选中识别真实值的表现,随着SLM生成候选质量提高,LA分数自R0起普遍上升。图3(d)显示这种协作机制使EA性能随轮次递增。但SLM与LLM的缺陷可能导致噪声候选或训练数据,影响后期轮次表现。
(Q4) 消融实验
消融研究检验了TRE生成策略( P F − I K F {PF} - {IKF} PF−IKF/随机)、LLM类型、SLM类型及top- k k k等参数对EA性能的影响。 P F − I K F , m {PF} - {IKF},m PF−IKF,m策略选择PF-IKF分数最高的三元组,随机策略则选取 m m m个三元组。图4展示两种策略在两个数据集的表现(LLM=ChatGPT,SLM=LaBSE)。在DBP 15 K Z H − E N {15}{\mathrm{\;K}}_{{ZH} - {EN}} 15KZH−EN数据集上,PF-IKF策略的Hit@1和LA分数显著优于 R a n d {Rand} Rand,表明 P F − I K F {PF} - {IKF} PF−IKF分数能为实体相似度度量提供有效指导。DW15K V1数据集中, P F − I K F {PF} - {IKF} PF−IKF策略在R2轮取得更高Hit@1但优势缩小,因DBpedia与Wikidata的三元组分布差异较大。
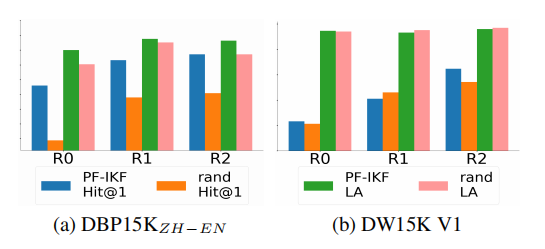
图4: P F − I K F {PF} - {IKF} PF−IKF策略与随机策略的效果对比,其中 y y y轴的范围为 [ 0 , 1 ] \left\lbrack {0,1}\right\rbrack [0,1]。
图5展示了HLMEA在不同大语言模型下的性能,包括闭源的ERNIE3.5、ChatGPT和开源的Qwen-7B。小语言模型(SLM)采用LaBSE。总体而言,闭源大模型表现优于较小规模的Qwen,但Qwen在DW15K V1数据集上得分超过ChatGPT。需注意开源大语言模型可本地部署并通过微调优化。
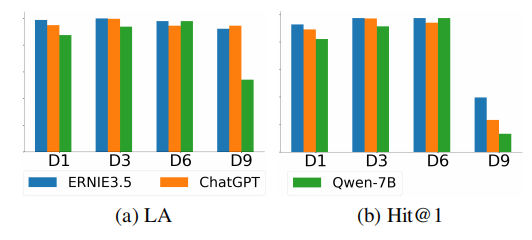
图5:不同大语言模型(LLM)的性能表现,y轴范围为 [ 0 , 1 ] . D 1 , D 3 , D 6 \left\lbrack {0,1}\right\rbrack .\mathrm{D}1,\mathrm{D}3,\mathrm{D}6 [0,1].D1,D3,D6, D 9 \mathrm{D}9 D9表示 D B P 15 K Z H − E N {\mathrm{{DBP15K}}}_{{ZH} - {EN}} DBP15KZH−EN、DBP15K F R − E N {}_{{FR} - {EN}} FR−EN、DY15K V1及DW15K V1数据集。
图6展示了ChatGPT使用不同多语言小语言模型时HLMEA的性能表现。e5(MiniLM)是参数量最大(最小)的SLM,含 560 M ( 118 M ) {560}\mathrm{M}\left( {{118}\mathrm{M}}\right) 560M(118M)参数。总体性能与参数量成正比,但第二大模型LaBSE在两个数据集上表现最佳,却在DW15K V1上表现最差。这表明超过 300 M {300}\mathrm{M} 300M的小语言模型均能胜任实体对齐任务,且单一SLM未必在所有场景都最优。
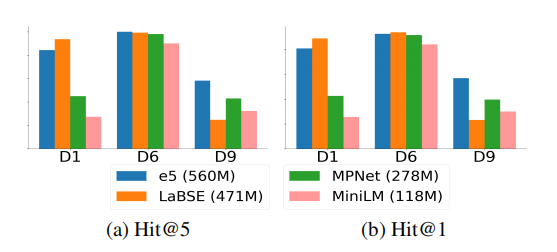
图6:不同小语言模型的性能对比, y y y轴范围为 [ 0 , 1 ] \left\lbrack {0,1}\right\rbrack [0,1]。
图7呈现了HLMEA采用ChatGPT、LaBSE及不同top- k k k候选数的性能表现。Hit@ k k k对应top- k k k选择(如Hit@10对应top-10)。随着 k k k增大,SLM(LLM)因候选范围扩大而能力提升。虽然Hit@1总体上升(因Hit@5增长率高于LA下降率),但10到20区间无改善,且更大的 k k k会导致提示上下文长度增加。
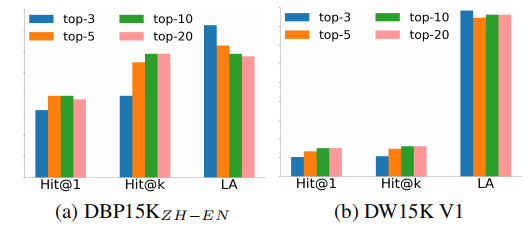
图7:不同top- k k k候选数下的性能表现。
成本讨论
HLMEA仅利用大语言模型和小语言模型内嵌知识,无需人工干预,是现实世界实体对齐任务中经济高效的标注方案。据前人研究(Wang等2021),人工标注成本为每50词元0.11美元,而单个实体对齐样本约含1000词元,即每标注成本2.2美元。HLMEA通常经三轮执行(每轮三次重复)后收敛。以ChatGPT(3.5-turbo-1106版本每百万词元收费1美元)为例,处理单个实体对齐样本的成本为
$ 1 × 1000 × 3 × 3 1000000 = $ 0.009 \$1 \times 1000 \times 3 \times \frac{3}{1000000} = \$0.009 $1×1000×3×10000003=$0.009
这表明HLMEA在保持满意性能的同时,显著降低了实体对齐标注成本。
结论
本文提出新型无监督实体对齐框架HLMEA,通过协同大语言模型与小语言模型提升对齐性能。在基准数据集上的对比实验与消融研究验证了HLMEA在效果和可扩展性上优于基线方法。本工作有望启发更多结合大语言模型的下游任务研究。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)