从零开始学习Dify-从理论到实践深度理解MCP三部曲(一)
MCP协议:让大模型从"说"到"做"的关键突破 MCP(ModelContextProtocol)是Anthropic推出的开源协议,旨在解决大模型与外部工具集成的标准化问题。该协议采用客户端-服务器架构,包含Host、Client和Server三个核心组件,支持访问本地和远程数据源。通过MCP,大模型可以自主选择并调用工具,执行文件读写、数据库操作等实际任
概述
你的大模型还停留在“思想的巨人,行动的矮子”阶段吗?你是否希望在使用大模型时,它能自动读写本地文件、直接操作数据库?你让它写好了画图代码,却还需手动运行才能看到图表?反复多轮对话才能得到理想结果?根本原因在于大模型缺乏对工具与环境的“操作权”。而 MCP(Model Context Protocol,模型上下文协议)的出现,帮助大模型从“光说不做”迈向“边说边做”,真正实现从“嘴强王者”向“优秀工具人”的转变。
基本介绍
2.1 定义和定位
- 定义:
MCP全称 Model Context Protocol(中文名:模型上下文协议),是由 Anthropic 于 2024 年 11 月推出的开源协议。 - 定位:解决不同大语言模型(LLM)与多种外部工具之间的标准化集成问题。通过 MCP,开发者可以统一、高效地连接各种数据源与工具,极大提高大模型的实用性与灵活性。
(简而言之:让开发者不用重复造轮子,通过MCP协议,以期构建更强大的 AI Agent 生态。
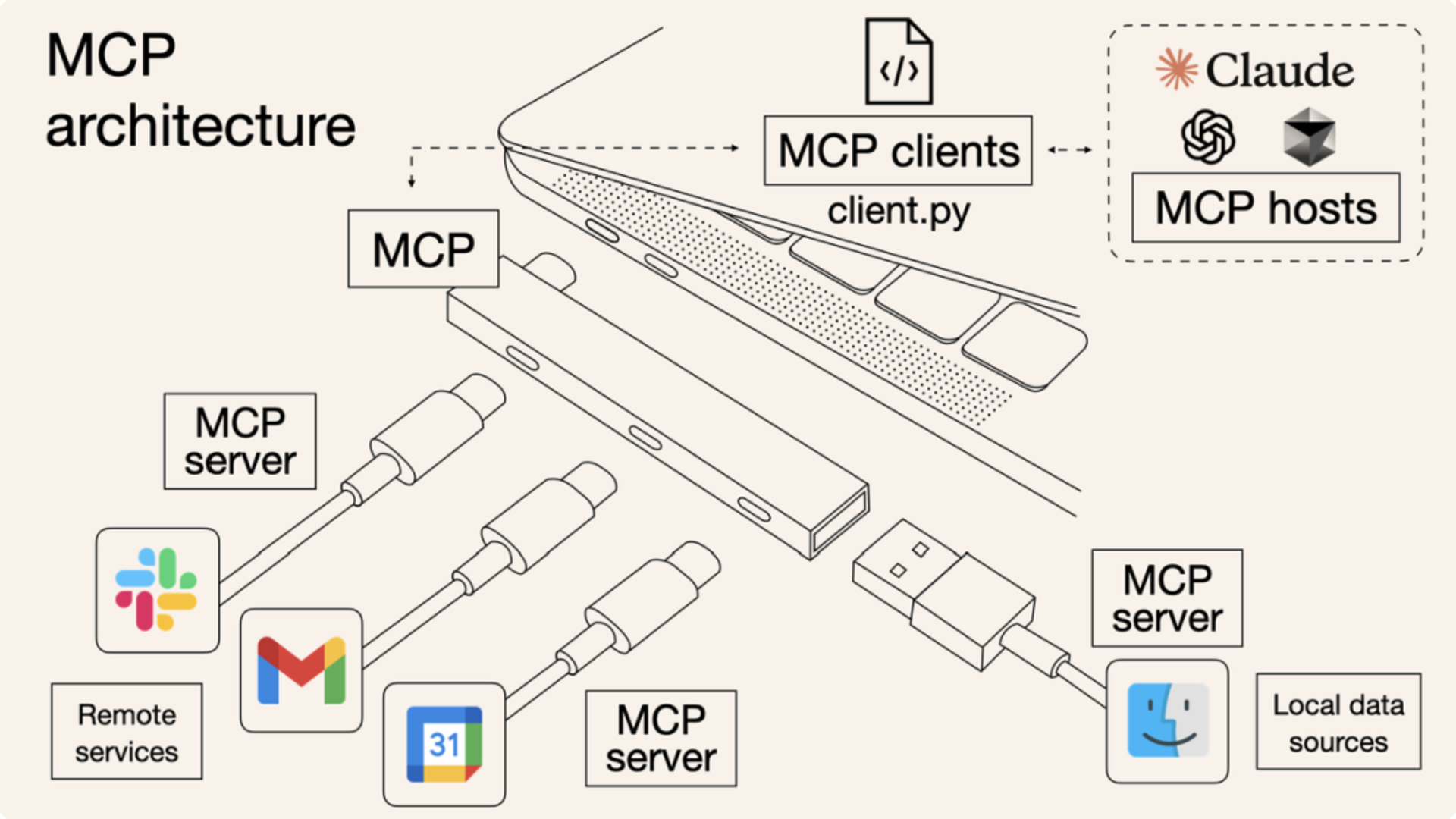
MCP 就像一个“通用插头”或“USB 接口”,提供统一的规范。无论是连接数据库、第三方 API,还是本地文件,都可通过这一通用接口实现,让 AI 模型与外部工具或数据源的交互更标准、更高效、更易复用。
目前,MCP 生态已获得广泛的行业支持,包括 Anthropic 的 Claude 系列、OpenAI 的 GPT 系列、Meta 的 Llama 系列、DeepSeek、阿里通义系列以及 Anysphere 的 Cursor 等主流模型均已接入 MCP 生态。
2.2 架构设计
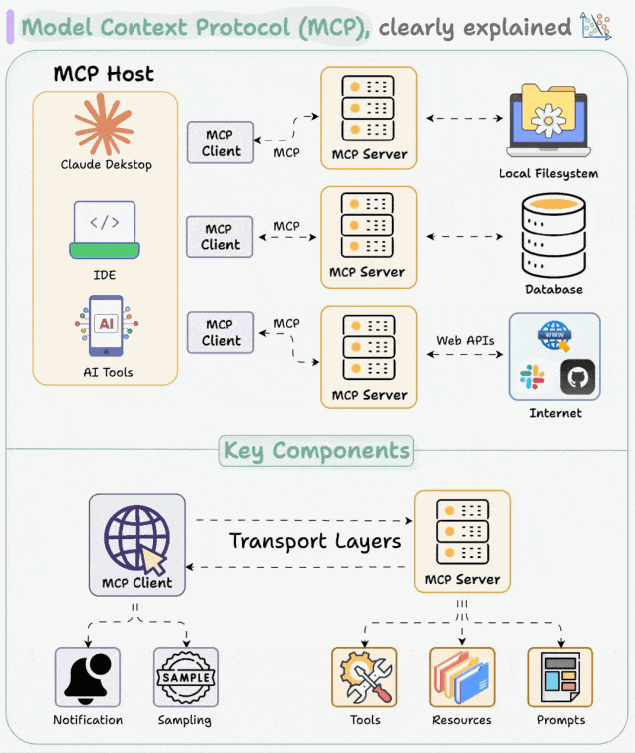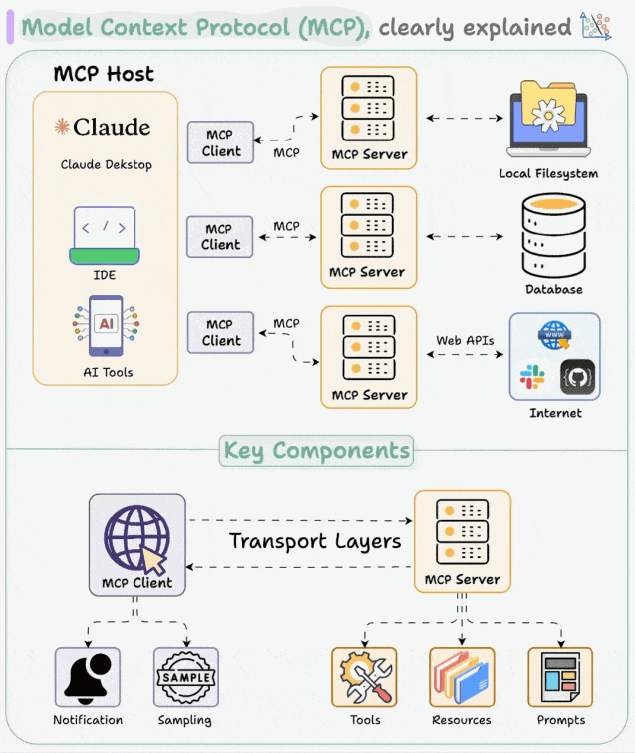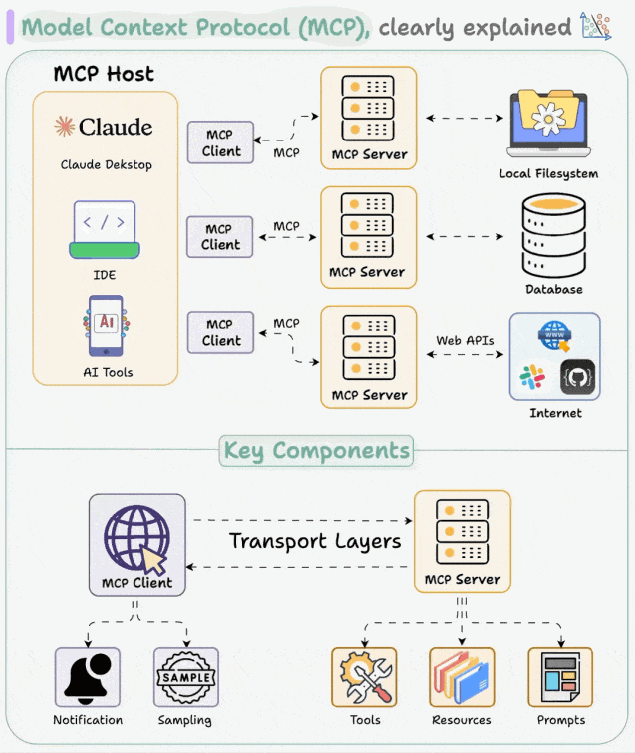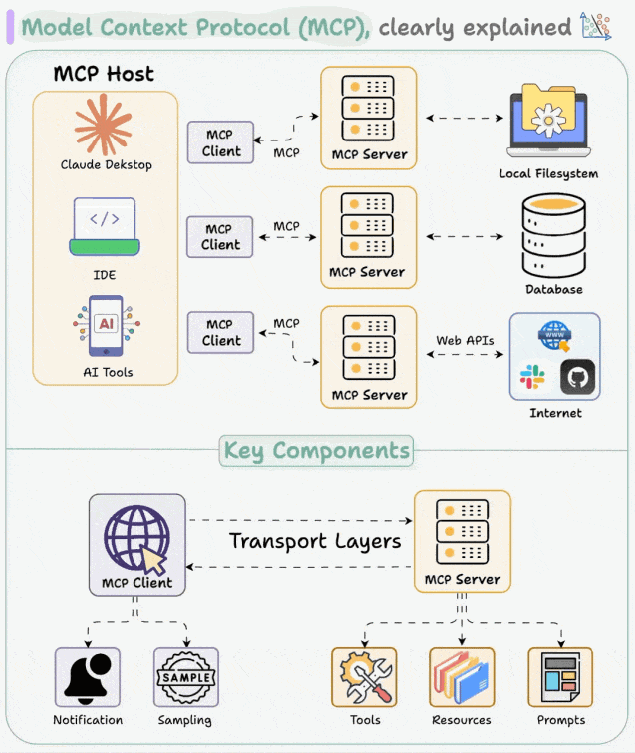
MCP 采用客户端-服务器的架构,主要包括以下三个核心组件及数据资源:
- MCP Host(主机):用户的可操作界面,如 Cursor、Trae、CherryStudio。
- MCP Client(客户端):一般内置于 Host 中,负责连接 Host 与 Server,发送请求与接收响应,实现消息的传递。
- MCP Server(服务器):负责处理来自 Client 的指令,与外部环境(如网络、数据库)互动,完成任务并返回结果。
- 数据资源:MCP 服务器能够访问两类数据源:
- 本地数据源:用户计算机本地存储的数据,通过 STDIO 协议访问。
- 远程数据源:通过 Web API 获取的外部数据,使 AI 应用能够直接访问互联网数据,使用 SEE 协议。
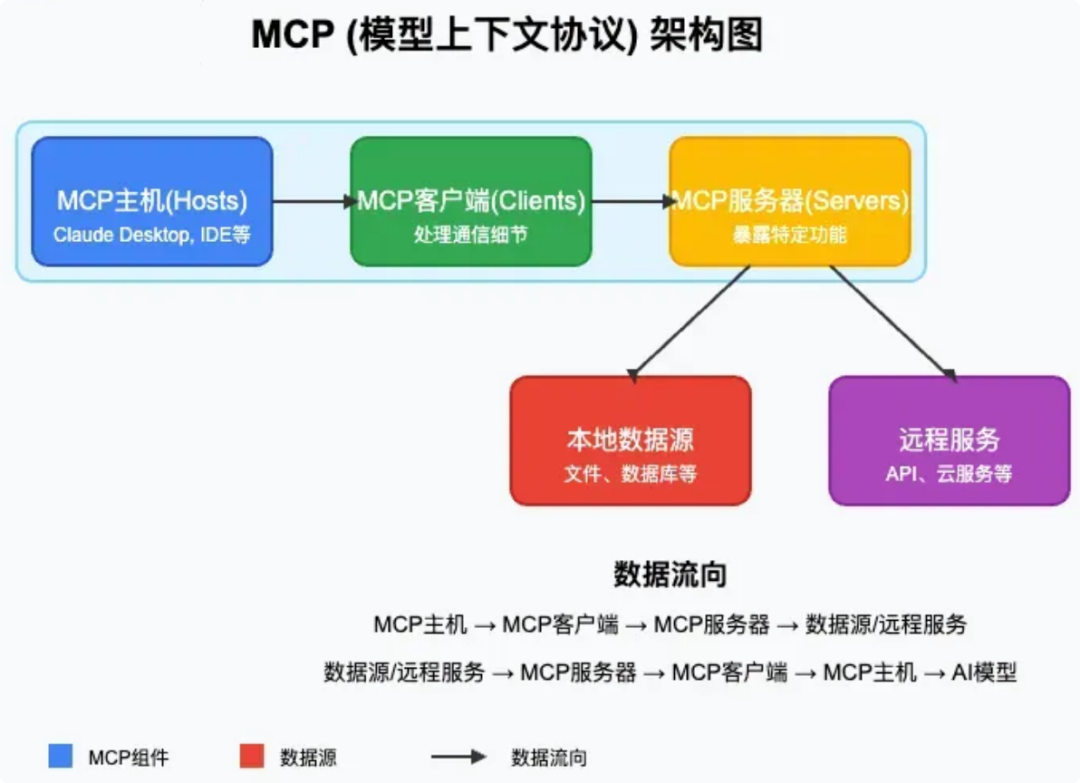
2.3 工作原理
MCP 核心是让我们能方便地调用多个工具,那随之而来的问题是 LLM(模型)是在什么时候确定使用哪些工具的呢? Anthropic 为我们提供了详细的解释,当用户提出一个问题时:
- 客户端(如 Claude Desktop 或 Cursor)首先将问题发送给 LLM。
- LLM 分析可用的工具,决定使用一个或多个工具来处理问题。
- 客户端通过 MCP Server 执行选定的工具。
- 工具执行结果返回给 LLM。
- LLM 根据执行结果综合分析,生成自然语言的最终结果呈现给用户。
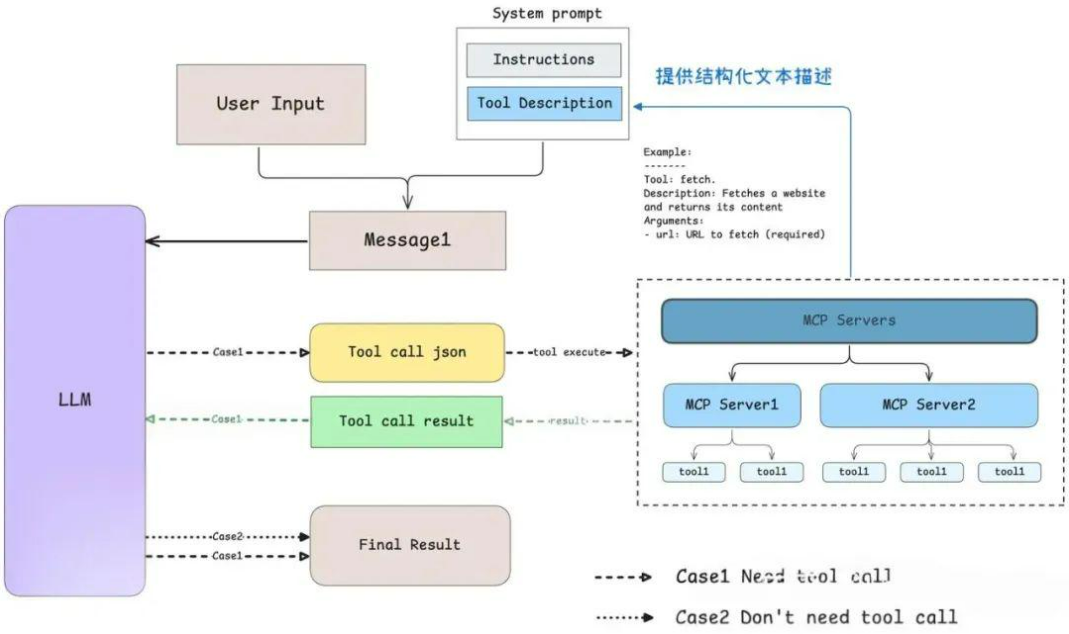
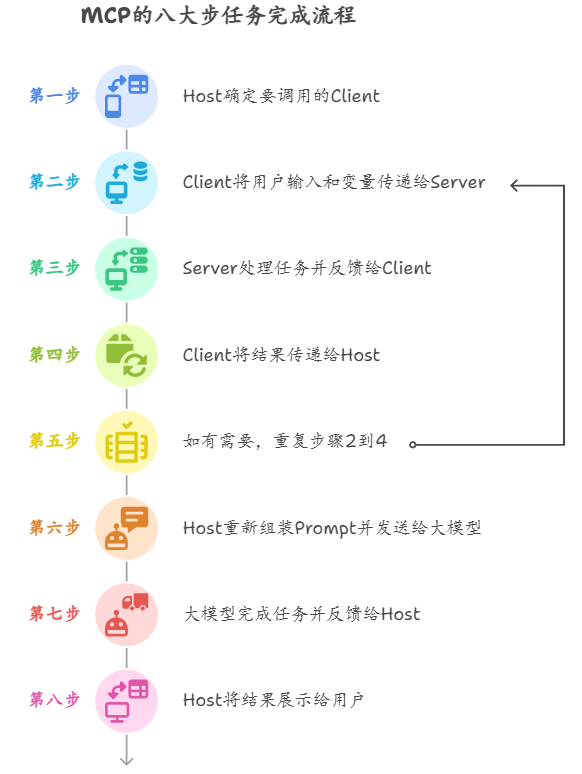
更细致的工作流程如下:用户输入要完成的任务或问题
- 第一步:用户输入待完成的任务或问题,Host 根据输入确定调用哪个 Client。
- 第二步:Client 将用户输入与环境变量传递给 Server。
- 第三步:Server 执行任务并将处理结果返回给 Client。
- 第四步:Client 将结果返回给 Host。
- 第五步(可选):如有需要,重复步骤二至四,调用不同的 MCP 执行不同任务。
- 第六步:Host 将结果重新组装成 Prompt,发送给大模型。
- 第七步:大模型完成任务,生成最终结果。
- 第八步:Host 将最终结果展示给用户。
总结
MCP 为大模型赋予了强大的工具与环境交互能力,有效解决了模型只会“说”而难以实际“做”的瓶颈。它通过标准化接口,使得不同模型与外部工具和数据资源能够无缝连接。未来,随着更多开发者和企业接入 MCP 生态,这一协议将进一步推动 AI Agent 的创新发展,加速大模型在实际场景中的普及与应用落地。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)