Datawhale AI夏令营 「结构化数据的用户意图理解和知识问答挑战赛」的赛事项目实践——大模型技术方向的学习
最近参加了datawhale夏令营的结构化数据的用户意图理解和知识问答挑战赛的赛事项目实践,基于列车信息查询与问答,传统的人工查询方式效率低下,且难以应对复杂的多条件查询需求。因此本项目将和大家一起探讨,如何用AI赋能这项工作。在基础方案中,我们掌握了如何通过模型蒸馏构建SFT数据集,并利用LoRA微调技术在讯飞星辰MaaS平台上训练出能够回答单字段查询的学生模型。但我们只回答了智能列车问答系统的
目录
一、针对Baseline的方案分析
在Baseline中,我们参考了模型蒸馏的思想,通过编程生成问题和使用“教师模型”生成答案来构建SFT数据集,并进行LoRA微调。
1.Baseline方案的优点:
-
数据质量可靠:通过编程生成确定性问题和教师模型生成对应答案,一定程度保障了SFT数据集的准确性和可靠性。
-
可控性强:问题生成过程可控,可以根据赛题要求灵活调整问题类型和复杂度。
-
符合赛题要求:通过微调实现模型能力提升,有效克服了平台不支持Agent功能的限制。
-
模型蒸馏实践:利用更强大的模型来提升小模型在特定任务上的表现。
2.Baseline方案的不足:
-
复杂问题处理能力有限:Baseline主要侧重于单字段查询,对于多条件筛选、跨行计算、时间推理、复杂单位换算等复杂问题,其生成的数据集可能不足以充分训练模型。
-
数据多样性不足:生成的问题类型相对单一,可能无法覆盖用户在实际场景中提出的所有复杂查询。
-
教师模型依赖性:教师模型的性能和调用成本会直接影响数据生成的效率和质量。
-
数据量限制:如果教师模型调用有成本或速度限制,大规模数据生成可能受影响。
-
未充分利用表格结构信息:简单地将表格行文本化,可能没有充分利用表格的结构信息和字段间的内在联系。
二、针对Baseline方案修改的提分思路(以下代码基于pycharm编写的script1.py代码实现)
针对Baseline方案的不足,我们可以从以下几个方面进行修改和优化:
1.扩展数据生成策略:
-
复杂问题模板化:针对赛题中提及的多种复杂问题类型(多条件筛选、跨行计算、时间推理、复杂时间范围过滤、缺失数据处理、复杂单位换算),设计更复杂的编程模板来生成问题。例如:标准化时间格式(兼容多种格式,确保无NaT残留),处理空值/无效值,特殊处理纯数字格式等。
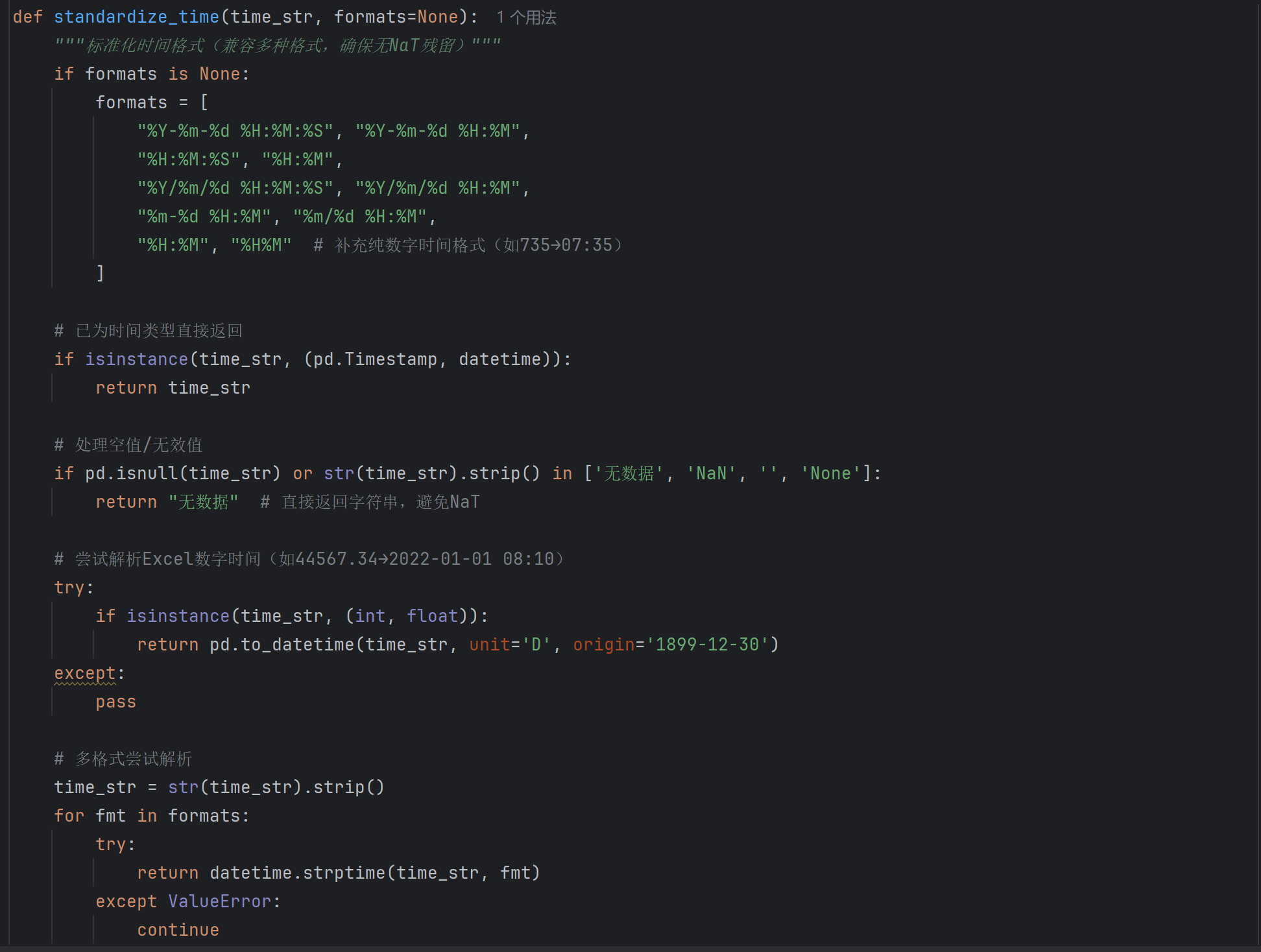
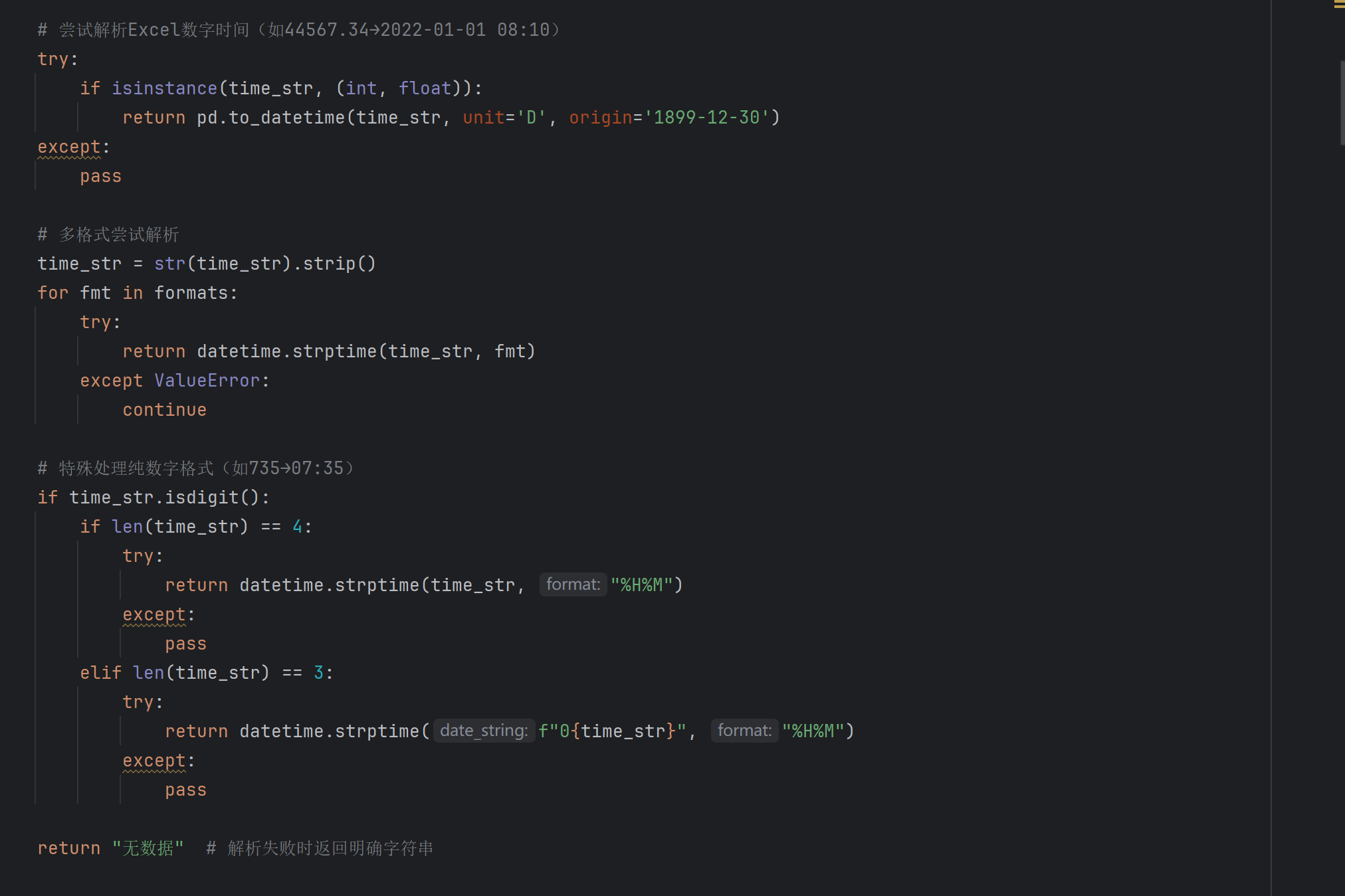
-
答案自动化验证/生成:对于复杂问题,尝试编写更智能的脚本来计算或验证答案,甚至可以构建一个小型的规则引擎来确保答案的正确性,减少对教师模型的完全依赖。
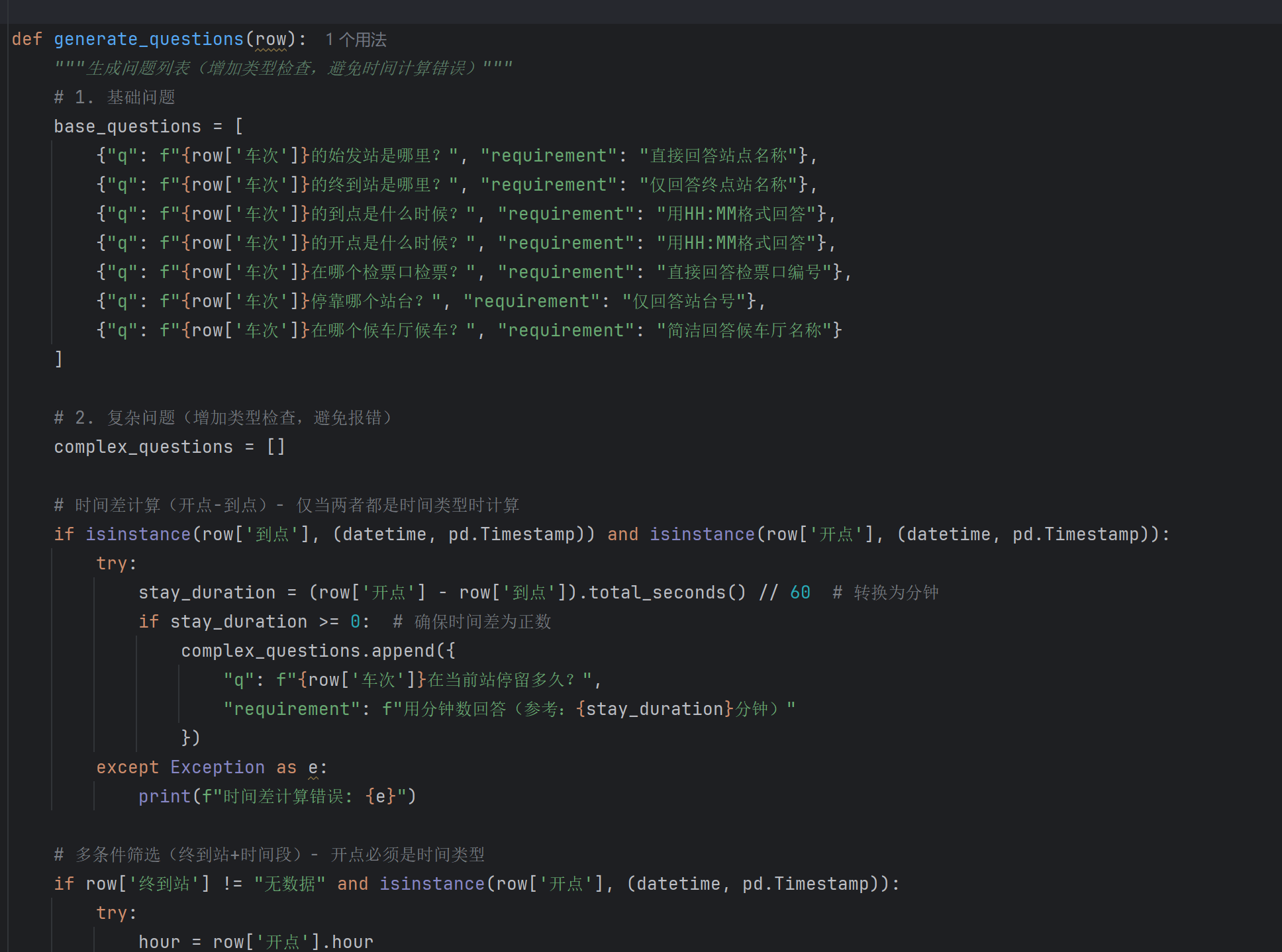
-
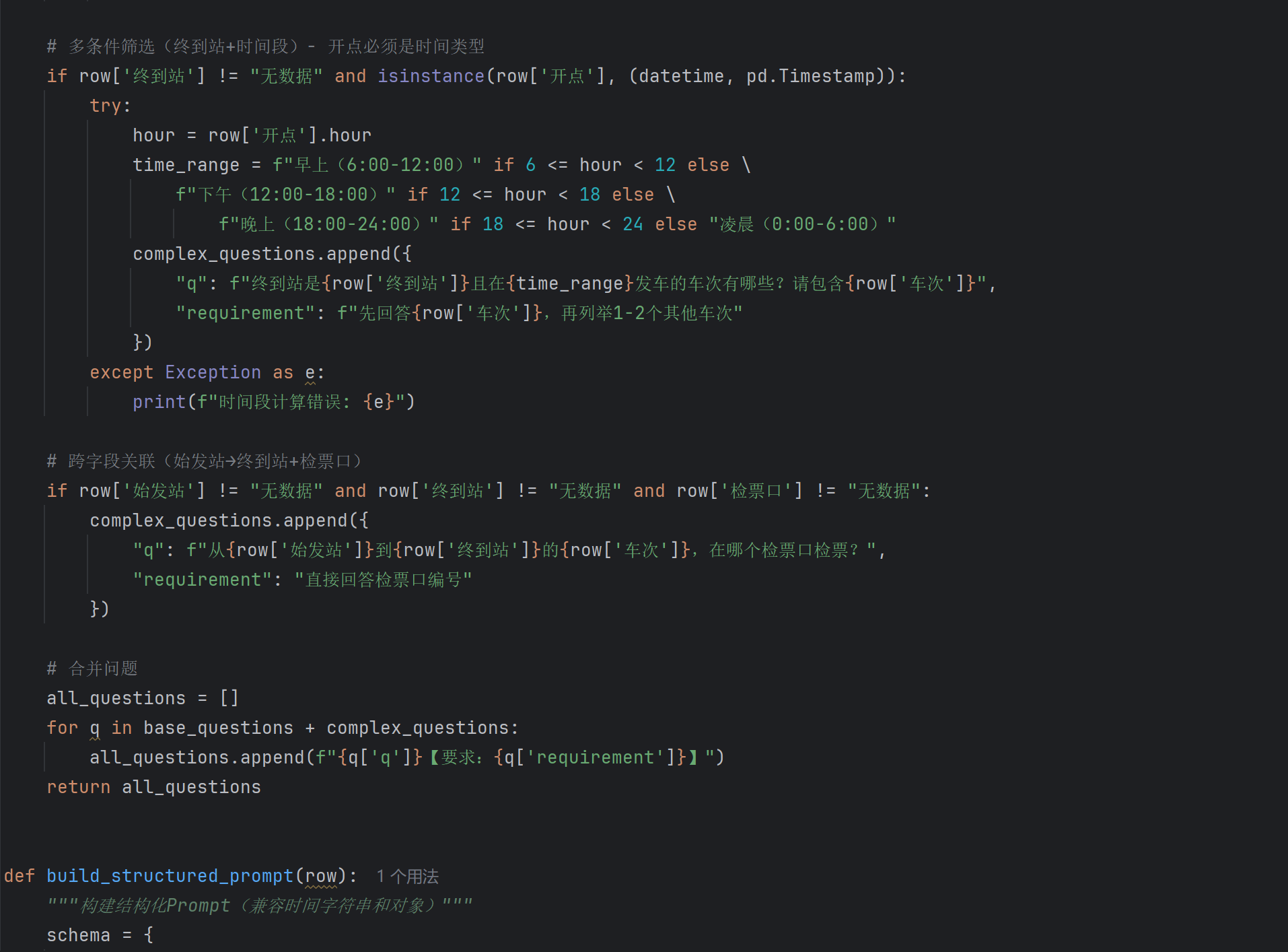
-
多轮对话模拟:模拟用户进行多轮对话的场景,生成包含上下文信息的问答对,提升模型的对话理解能力。
-
2.优化数据表示:
-
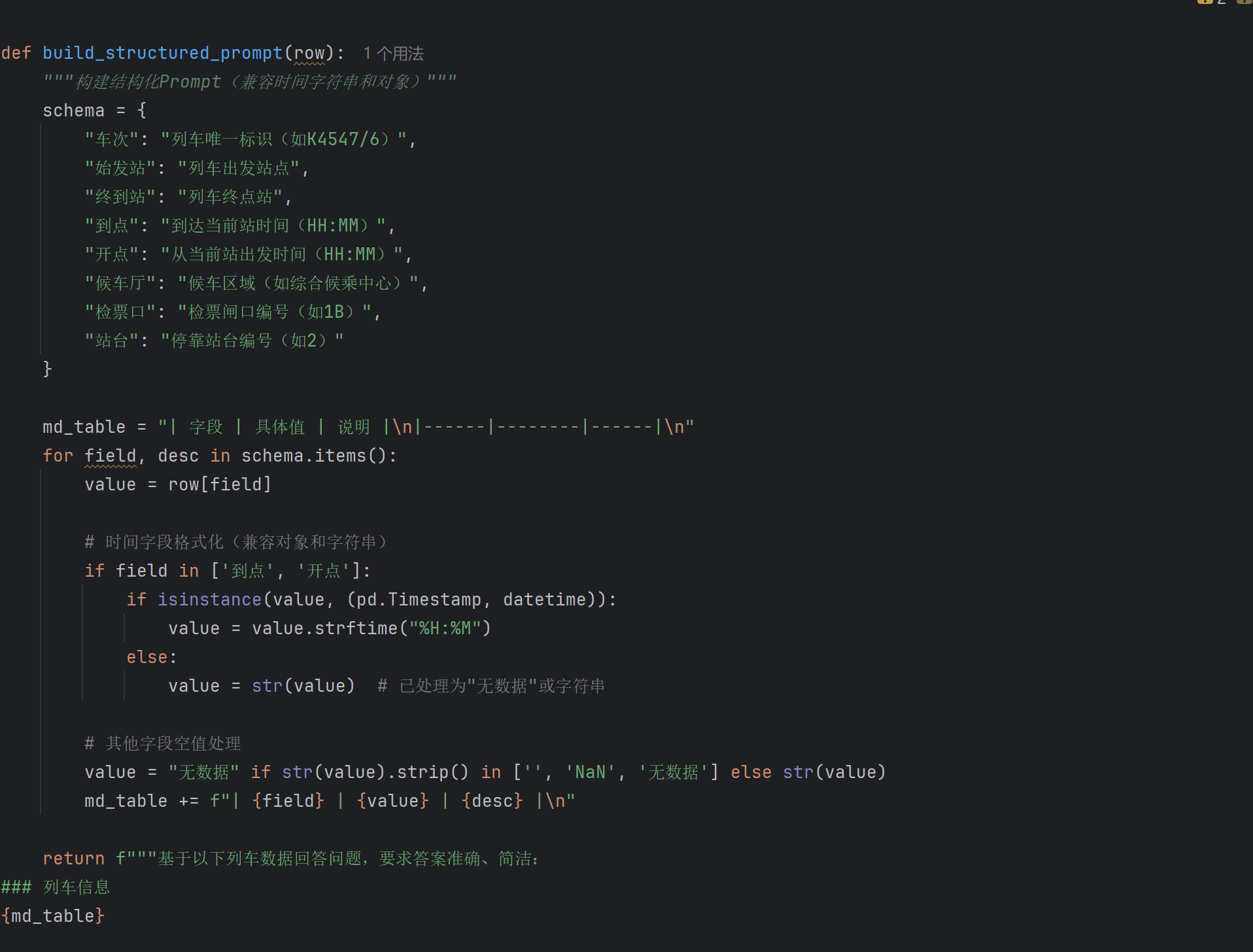
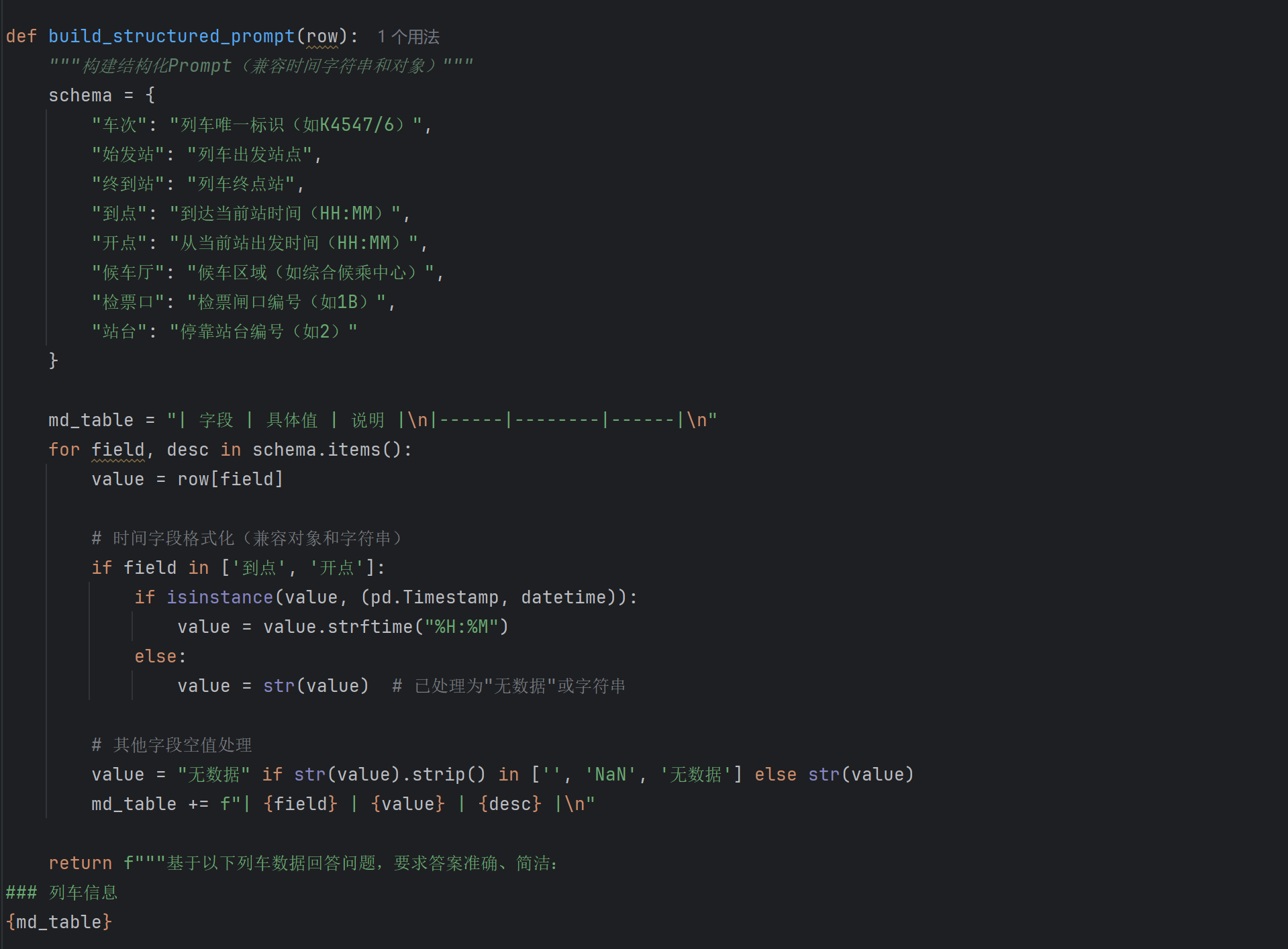
结构化Prompt:在向教师模型提问时,不仅仅是简单文本化表格数据,可以尝试更结构化的Prompt设计,例如将表格数据转换为Markdown表格、CSV字符串或JSON格式,并明确告知模型表格的列名和含义,帮助模型更好地理解表格结构。
-
引入Schema信息:在Prompt中加入表格的Schema信息(字段名、数据类型、可能的取值范围等),引导模型进行更准确的推理。
3.模型选择与调优:
-
探索不同规模模型:在LoRA微调时,尝试不同参数量的基础模型,根据“回答响应时长”和“回答信息传达效率”指标,找到准确率与速度的最佳平衡点。
-
LoRA参数优化:调整LoRA的秩(
r)、alpha值(lora_alpha)以及dropout率等参数,以找到最优的微调配置。 -
Python数据处理库文档:熟练使用Pandas等库进行数据筛选、聚合、时间计算等操作,以便编程生成复杂问题的答案。
三、赛题核心考察什么?
赛题的核心考察点在于参赛者对结构化数据理解、大模型微调技术和性能优化的综合能力。具体来说:
-
表格语义理解:模型能否准确理解表格中各个字段的含义,以及字段之间的关联。
-
复杂推理能力:模型能否基于表格数据进行多条件筛选、跨行计算、时间推理等复杂操作。
-
数据构建能力:在平台限制下,如何高效、高质量地构建微调数据集是关键。
-
模型优化能力:如何在保证准确率的前提下,优化模型的响应速度和生成效率。
进阶要点1:复杂问题的数据构建
Baseline主要关注单字段查询,但赛题明确提出了多条件筛选、跨行计算、时间推理等复杂问题。要让模型处理这些问题,必须在训练数据集中包含这些类型的问答对。这需要我们设计更复杂的逻辑来生成问题和对应的准确答案。
资料推荐:
-
SQL-to-Text/Text-to-SQL数据集:这类数据集通常包含自然语言问题和对应的SQL查询,可以从中学习如何将自然语言问题映射到结构化查询,反之亦然。例如Spider、WikiSQL等。
-
表格问答(Table QA)论文:搜索关于“Table QA”、“Semantic Parsing on Tables”等关键词的最新论文,了解如何处理表格中的复杂推理。
-
Python数据处理库文档:熟练使用Pandas等库进行数据筛选、聚合、时间计算等操作,以便编程生成复杂问题的答案。
进阶要点2:时间处理与推理
赛题中包含大量时间相关的查询,如“停留时长”、“延误后新开点时间”等。这要求模型不仅能识别时间信息,还能进行准确的时间计算和推理。时间格式的统一化处理是基础,更重要的是如何将时间逻辑融入到问答对的生成中。
资料推荐:
-
Python
datetime模块文档:深入学习Python中处理日期和时间的标准库,掌握时间解析、格式化、计算等功能。 -
时间序列分析基础:了解时间序列数据的特点和处理方法,虽然本赛题不是严格的时间序列预测,但对时间概念的理解有帮助。
-
自然语言处理中的时间信息抽取:相关论文和技术文章,了解如何从非结构化文本中识别和标准化时间表达式。
进阶要点3:性能与效率优化
除了准确率,赛题对“回答响应时长”和“回答信息传达效率”也有明确要求。这意味着即使模型准确率高,如果响应速度慢或输出冗余,也会影响最终得分。选择合适的模型大小、优化微调策略、以及可能的推理优化都是考虑点。
资料推荐:
-
模型剪枝、量化、蒸馏:了解这些模型压缩和加速技术,虽然蒸馏已在Baseline中使用,但可以探索更高级的蒸馏方法。
-
大模型推理优化框架:如OpenVINO、ONNX Runtime等,虽然可能不直接在讯飞MaaS平台使用,但了解其原理有助于理解推理优化的方向。
-
LoRA参数调优指南:学习如何调整LoRA的秩、alpha值等,以在性能和效率之间找到平衡。
四、进阶方法和思路分享
本部分将介绍一些可以帮助您在赛题中脱颖而出,实现“上分”的进阶方案和思路。
进阶思路1:多类型复杂问题自动化生成
方案框架及说明: 我们可以构建一个更智能的数据生成器,它能够根据表格数据和预定义的问题类型,自动化生成多样化、高质量的复杂问答对。
-
问题模板库扩展:
-
多条件筛选:例如,遍历“候车厅”和“开点”字段,生成“在
{候车厅}候车,发车时间晚于{时间}的列车有哪些?”。 -
跨行计算:识别始发站和终到站相同的列车对,计算其运行时间(到点-开点),然后生成“从
{始发站}到{终到站}的列车中,哪趟运行时间最短?” -
时间推理:针对“到点”和“开点”字段,生成“
{车次}列车在{站名}的停留时长是多久?” -
缺失数据处理:筛选出特定字段缺失的行,生成“
{字段}为'无数据'的车次有哪些?” -
复杂单位换算:设计时间加减逻辑,生成“
{车次}列车的开点时间为{开点},若延误{延误时间},新的开点时间是几点?”
-
-
答案自动化生成/验证:
-
对于每种复杂问题模板,编写对应的Python函数(基于Pandas等)来从原始表格数据中计算出准确的答案。
-
这些函数将作为“真实答案生成器”,确保我们SFT数据集中的
output字段是完全正确的。
-
-
结构化Prompt设计:
-
在将表格数据传递给教师模型时,可以将其转换为更易于模型理解的结构化文本,例如:
列车时刻表信息如下: 车次: K4547/6, 始发站: 成都西, 终到站: 佳木斯, 到点: 23:40:00, 开点: 00:12:00, 候车厅: 综合候乘中心,高架候车区西区, 检票口: 1B, 站台: 2 车次: Z362, 始发站: 乌鲁木齐, 终到站: 南通, 到点: 00:10:00, 开点: 00:21:00, 候车厅: 综合候乘中心,高架候车区西区, 检票口: 5B, 站台: 5 ... 请根据上述信息,回答以下问题: 问题:在综合候乘中心候车、发车时间晚于08:00的列车有哪些? -
同时,在Prompt中明确要求教师模型输出答案的格式,例如JSON,并可以要求它给出推理步骤。
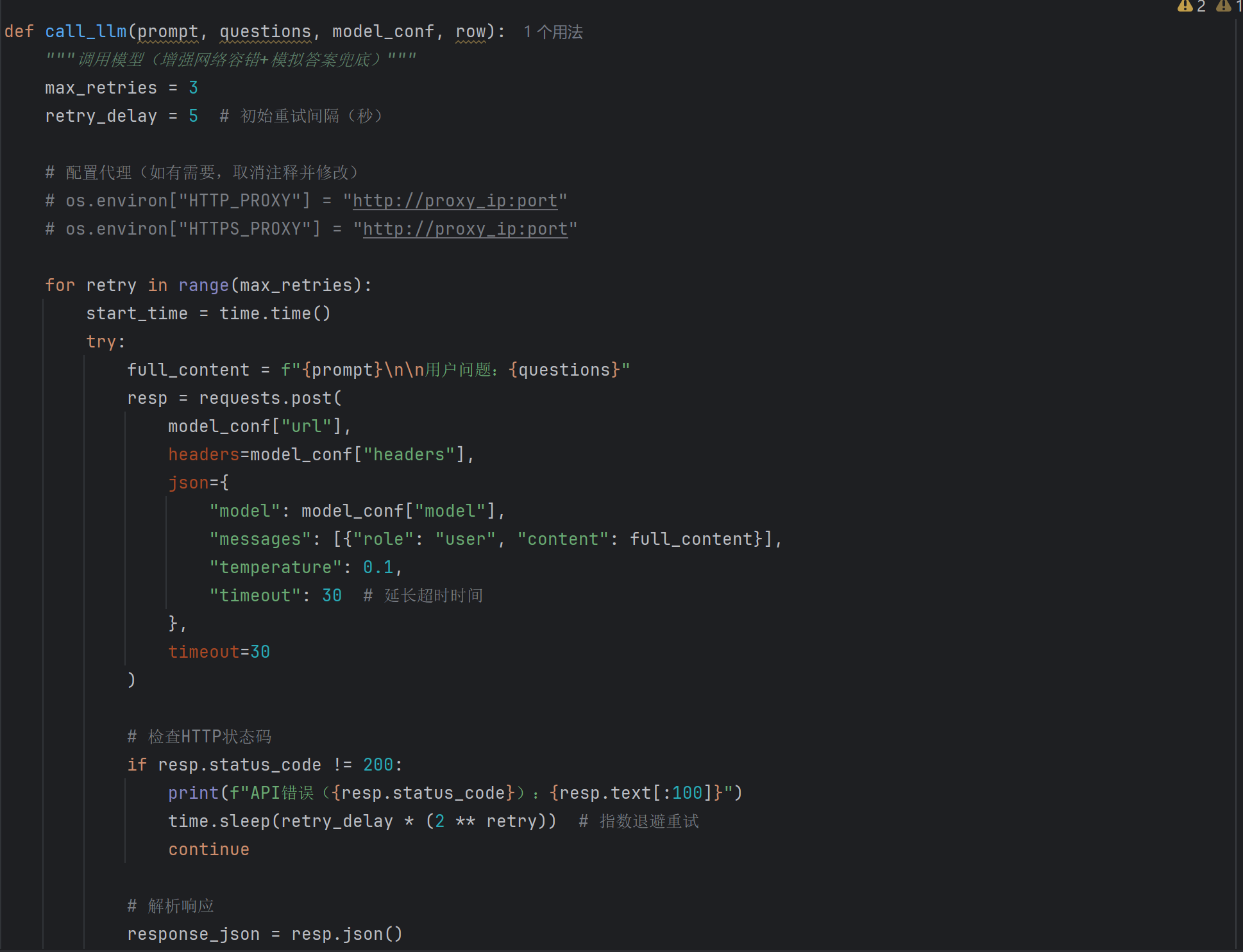
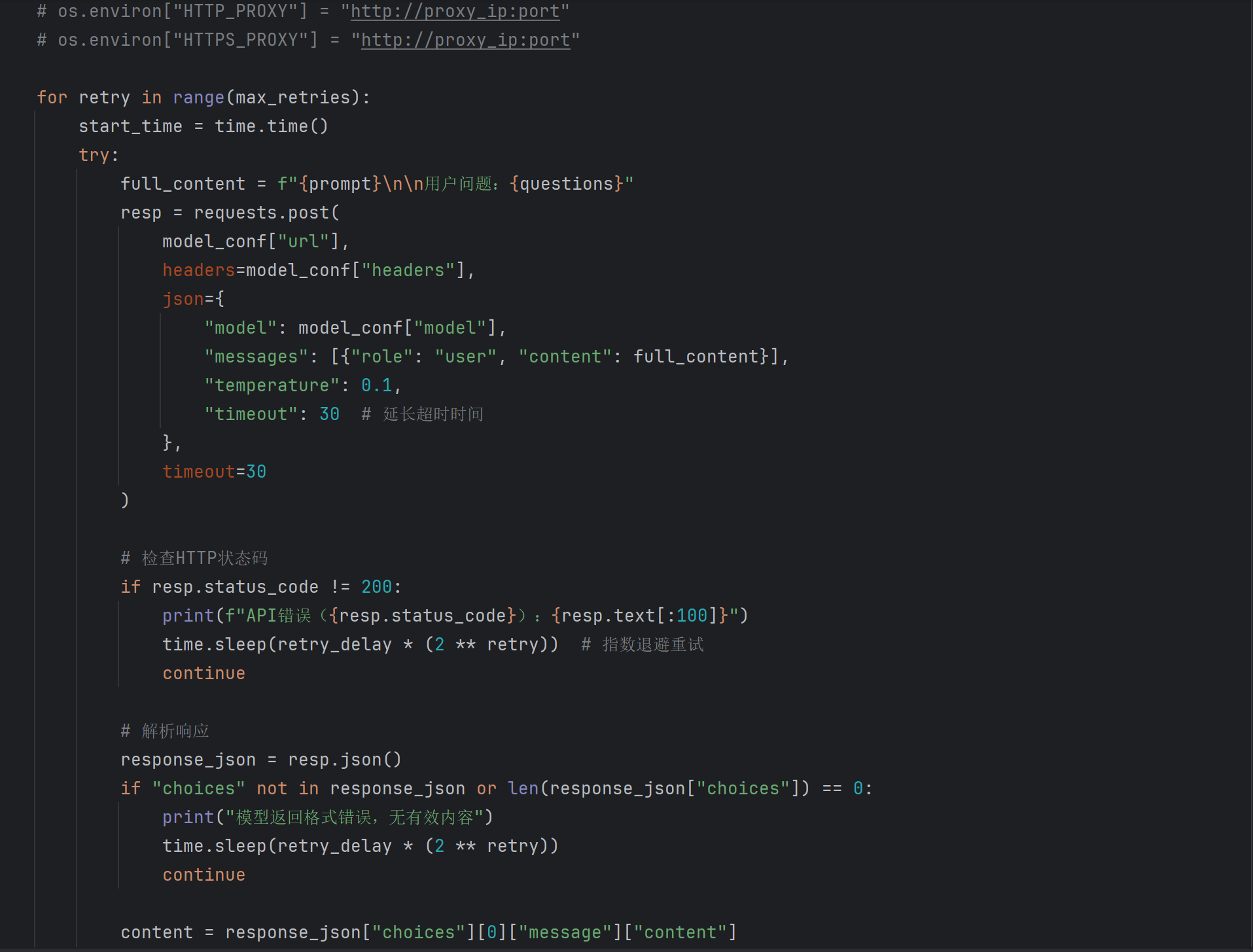
-
参考伪代码(答案自动化生成示例):
import pandas as pd
from datetime import datetime, timedelta
def calculate_stop_duration(row):
"""计算列车在某站的停留时长"""
try:
arrival_time_str = str(row['到点'])
departure_time_str = str(row['开点'])
if arrival_time_str == '无数据' or departure_time_str == '无数据':
return "无数据"
# 处理跨天情况,假设到点是前一天,开点是后一天
arrival_time = datetime.strptime(arrival_time_str, '%H:%M:%S')
departure_time = datetime.strptime(departure_time_str, '%H:%M:%S')
if departure_time < arrival_time:
# 跨天,开点时间加一天
departure_time += timedelta(days=1)
duration = departure_time - arrival_time
hours, remainder = divmod(duration.seconds, 3600)
minutes, seconds = divmod(remainder, 60)
return f"{hours}小时{minutes}分钟"
except Exception as e:
return f"计算错误: {e}"
# 示例:生成时间推理问题和答案
# for idx, row in data.iterrows():
# question = f"{row['车次']}次列车在{row['始发站']}的停留时长是多久?"
# answer = calculate_stop_duration(row)
# sft_data.append({"instruction": question, "output": answer})进阶思路2:Agent思想在数据生成中的应用
虽然讯飞星辰MaaS平台不支持直接部署Agent,但我们可以在数据生成阶段引入Agent的思想,让数据生成过程更加智能和自动化。
-
“问题生成Agent”:
-
设计一个Agent,其核心能力是根据表格数据和赛题要求,自主思考并生成多种类型的问题(包括简单和复杂问题)。
-
这个Agent可以包含一个“工具调用”模块,例如调用一个Pandas脚本工具来执行数据查询或计算,以生成复杂问题的正确答案。
-
Agent的输出就是高质量的问答对。
-
-
“答案验证Agent”:
-
构建另一个Agent,其任务是接收一个问题和模型生成的答案,然后根据原始表格数据来验证答案的正确性。
-
这可以用于对教师模型生成的答案进行二次校验,进一步提升SFT数据集的质量。
-
思路点拨:
-
ReAct (Reasoning and Acting) 框架:可以参考ReAct等Agent框架,让模型在生成问题或答案时,模拟“思考”(Reasoning)过程,并决定是否需要“行动”(Acting,如调用数据查询工具)。
-
Few-shot prompting:在调用教师模型时,提供少量高质量的复杂问题和答案示例,引导模型更好地理解任务并生成符合要求的输出。
进阶思路3:多模态/多源信息融合(未来展望)
虽然当前赛题仅限于结构化表格数据,但从长远来看,智能交通问答系统可能需要处理多模态信息(如车站布局图、语音播报)或多源信息(如实时延误信息、天气数据)。
思路点拨:
-
图像理解:如果未来赛题包含车站布局图,可以利用多模态大模型进行图像理解,回答“检票口5B在哪个区域?”等问题。
-
实时数据接入:如果能获取实时列车运行数据,模型可以回答更动态的问题,如“KXXX次列车目前是否晚点?”。这需要API集成和实时数据处理能力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 26
26 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)