机器学习学习笔记7:心脏病预测
本研究基于心脏病数据集(303个样本,12个特征),采用随机森林、XGBoost、逻辑回归和SVM四种机器学习模型进行心脏病预测。通过数据清洗(异常值处理后保留228个样本)、模型训练和网格搜索调优,最终选择SVM作为最优模型。特征重要性分析显示"thal"、"ca"和"cp"为关键预测因子。实验结果表明机器学习能有效辅助心脏病诊断,未来
一、实验目的与背景
心脏病是全球范围内导致死亡的主要原因之一。早期预测和诊断对于降低心脏病风险至关重要。机器学习技术在医疗领域的应用日益广泛,通过分析患者的生理指标,可以辅助医生进行更准确的诊断。本实验使用包含患者年龄、性别、血压、胆固醇水平等特征的数据集,通过随机森林、xgboost、逻辑回归、SVM四个分类器择优构建预测模型。
数据集来源:heart.csv,其中,有“ sex,cp,trestbps,chol,fbs,restecg,thalach,exang,oldpeak,slope,ca, thal”12个自变量列, "target"列作为因变量,共包含303个样本。
二、实验过程与结果
1. 数据加载与预处理
加载pandas加载心脏病数据集('heart.csv'),并将数据集分为特征(X)和目标变量(y)。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_curve, auc, confusion_matrix, classification_report
import matplotlib.pyplot as plt
import seaborn as sns
import shap
#1、加载数据
df = pd.read_csv('heart.csv')
X = df.drop('target', axis=1)
y = df['target']2. 数据探索与预处理
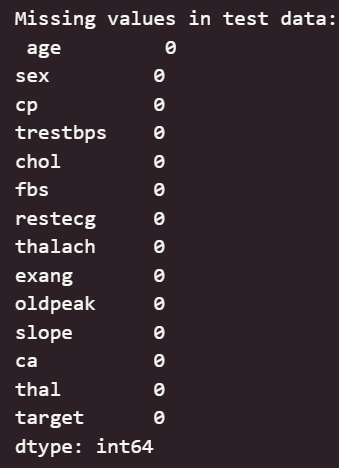
检查数据缺失值情况,确认数据完整无缺失;
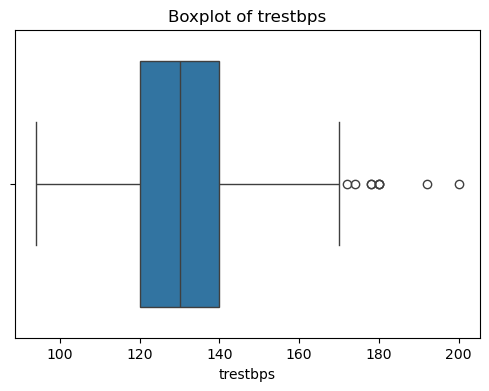
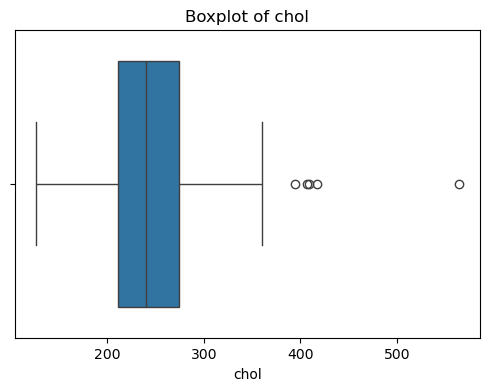
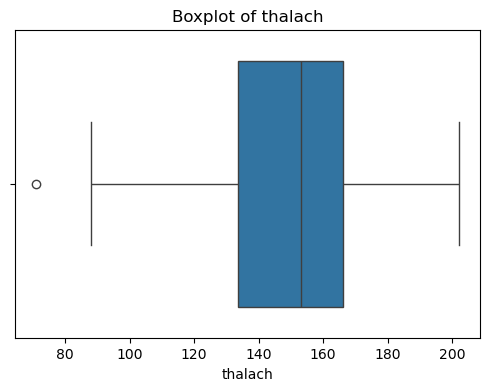
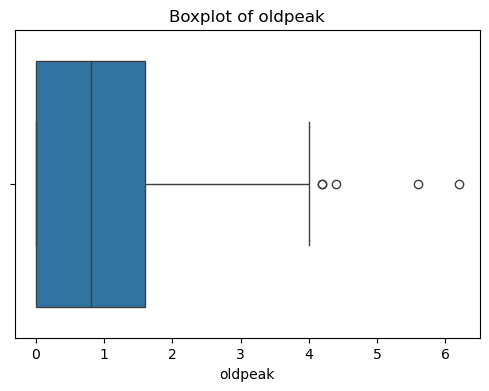
同时绘制特征分布图,了解各特征的分布情况,并对其中异常分布的样本进行删除处理。
#2、数据预处理
from scipy import stats
import numpy as np
# 检测缺失值
print("Missing values in test data:\n", df.isnull().sum())
#数据异常值检测(使用Z-score方法)
z_scores_X = stats.zscore(X)
z_scores_y = stats.zscore(y)
abs_z_scores_X = np.abs(z_scores_X)
abs_z_scores_y = np.abs(z_scores_y)
for col in X.columns:
plt.figure(figsize=(6, 4))
sns.boxplot(x=X[col])
plt.title(f'Boxplot of {col}')
plt.show()
#处理异常值
def remove_outliers_iqr(df, factor=1.5):
df_cleaned = df.copy()
for col in df.columns:
Q1 = df[col].quantile(0.25)
Q3 = df[col].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - factor * IQR
upper_bound = Q3 + factor * IQR
df_cleaned = df_cleaned[(df_cleaned[col] >= lower_bound) & (df_cleaned[col] <= upper_bound)]
return df_cleaned
cleaned_df_X = remove_outliers_iqr(X)
cleaned_df_y = y[cleaned_df_X.index]
print("原始样本数量:", len(X))
print("清洗后样本数量:", len(cleaned_df_X))输出结果如下:
![]()
观察结果可知,特征无缺失值,但部分特征有异常值,需进行异常值处理。
异常值处理之后的样本数量由303减少至228个。
3. 模型构建与训练
将数据集划分为训练集和测试集,并训练随机森林、xgboost、逻辑回归、SVM四个分类器。
#3、划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(cleaned_df_X, cleaned_df_y, test_size=0.2, random_state=7)# 按照 80% 训练集,20% 测试集划分
#4、随机森林初始化并训练模型
rf_model = RandomForestClassifier(n_estimators=100, random_state=7)
rf_model.fit(X_train, y_train)
# 预测概率与类别
y_prod_rf = rf_model.predict_proba(X_test)[:, 1]
y_pred_rf = rf_model.predict(X_test)
#5、xgboost模型初始化并训练模型
from xgboost import XGBClassifier
xgb_model = XGBClassifier(use_label_encoder=False, eval_metric='logloss')
xgb_model.fit(X_train, y_train)
# 预测概率与类别
y_prod_xgb = rf_model.predict_proba(X_test)[:, 1]
y_pred_xgb = rf_model.predict(X_test)
#6、luogistic回归模型初始化并训练模型
from sklearn.linear_model import LogisticRegression
lr_model = LogisticRegression()
lr_model.fit(X_train, y_train)
# 预测概率与类别
y_prod_lr = rf_model.predict_proba(X_test)[:, 1]
y_pred_lr = rf_model.predict(X_test)
#7、SVM模型初始化并训练模型
from sklearn.svm import SVC
svm_model = SVC(probability=True)
svm_model.fit(X_train, y_train)
# 预测概率与类别
y_prod_svm = rf_model.predict_proba(X_test)[:, 1]
y_pred_svm1 = rf_model.predict(X_test)4. 初始模型评估
在测试集上进行预测,计算并分析混淆矩阵,同时绘制ROC曲线并计算AUC值,评估模型整体性能。
#8、绘制 ROC 曲线与混淆矩阵
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
models = [rf_model, xgb_model, lr_model, svm_model]
model_names = ['rf_Model', 'xgb_Model', 'lr_Model', 'svm_Model']
plt.figure(figsize=(8,6))
for model, name in zip(models, model_names):
y_pred_prob = model.predict_proba(X_test)[:, 1]
fpr, tpr, _ = roc_curve(y_test, y_pred_prob)
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, lw=2, label='{} (AUC = {:.2f})'.format(name, roc_auc))
plt.plot([0, 1], [0, 1], color='navy', linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()
from sklearn.metrics import confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
for model, name in zip(models, model_names):
y_pred = model.predict(X_test)
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(5,4))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title('{} Confusion Matrix'.format(name))
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()输出结果如下:
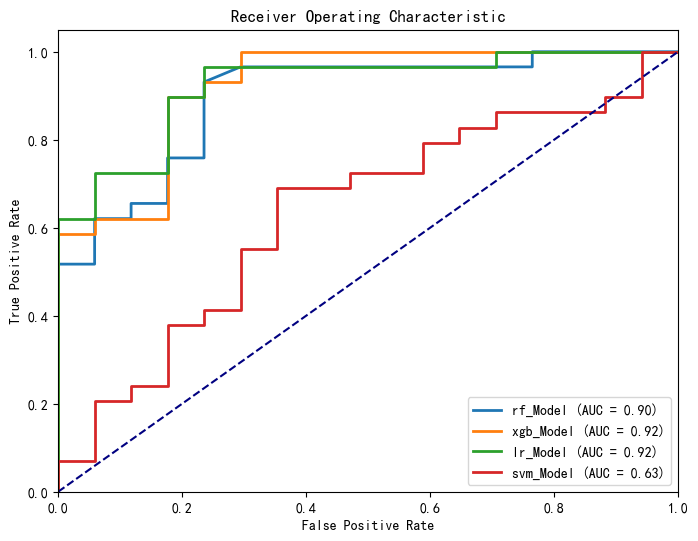
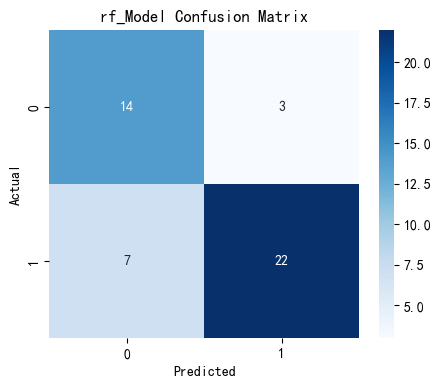
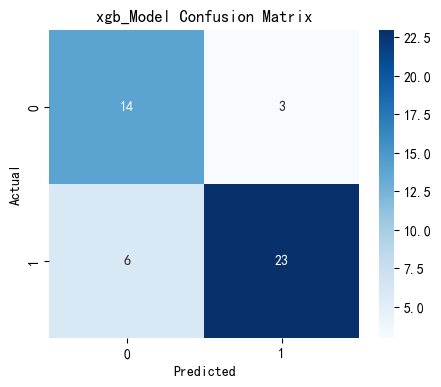
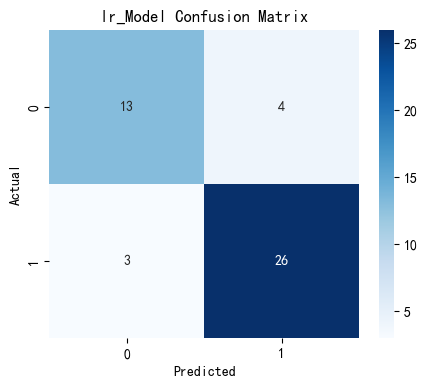
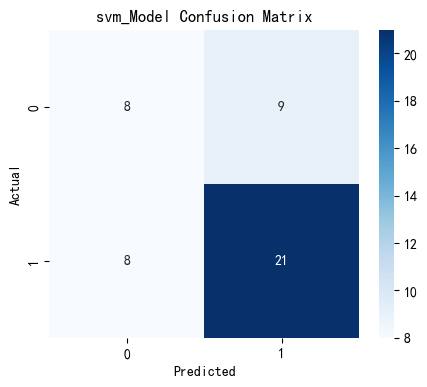
可以看出,除支持向量机以外,每个模型都以较高高的准确度完成了预测,但各个模型任存在优化空间,故对模型进行参数调优。
5. 参数调优
采用网格搜索搜寻各个模型的最优参数。
#9、参数调优
from sklearn.model_selection import GridSearchCV
param_grid_rf = {
'n_estimators': [50, 100, 200],
'max_depth': [None, 10, 20],
'min_samples_split': [2, 5],
'min_samples_leaf': [1, 2]
}
grid_search_rf = GridSearchCV(RandomForestClassifier(random_state=7), param_grid_rf, cv=5)
grid_search_rf.fit(X_train, y_train)
best_rf = grid_search_rf.best_estimator_
#print("Best Random Forest Parameters:", grid_search_rf.best_params_)
best_y_prod_rf = best_rf.predict_proba(X_test)[:, 1]
best_y_pred_rf = best_rf.predict(X_test)
param_grid_xgb = {
'n_estimators': [50, 100, 200],
'learning_rate': [0.01, 0.1],
'max_depth': [3, 6],
'subsample': [0.8, 1.0],
'colsample_bytree': [0.8, 1.0]
}
grid_search_xgb = GridSearchCV(XGBClassifier(use_label_encoder=False, eval_metric='logloss'), param_grid_xgb, cv=5)
grid_search_xgb.fit(X_train, y_train)
best_xgb = grid_search_xgb.best_estimator_
#print("Best XGBoost Parameters:", grid_search_xgb.best_params_)
best_y_prod_xgb = best_xgb.predict_proba(X_test)[:, 1]
best_y_pred_xgb = best_xgb.predict(X_test)
param_grid_lr = {
'C': [0.1, 1, 10],
'penalty': ['l1', 'l2'],
'solver': ['liblinear']
}
grid_search_lr = GridSearchCV(LogisticRegression(), param_grid_lr, cv=5)
grid_search_lr.fit(X_train, y_train)
best_lr = grid_search_lr.best_estimator_
#print("Best Logistic Regression Parameters:", grid_search_lr.best_params_)
best_y_prod_lr = best_lr.predict_proba(X_test)[:, 1]
best_y_pred_lr = best_lr.predict(X_test)
param_grid_svm = {
'C': [0.1, 1, 10],
'kernel': ['linear', 'rbf'],
'gamma': ['scale', 'auto']
}
grid_search_svm = GridSearchCV(SVC(probability=True), param_grid_svm, cv=5)
grid_search_svm.fit(X_train, y_train)
best_svm = grid_search_svm.best_estimator_
#print("Best SVM Parameters:", grid_search_svm.best_params_)
best_y_prod_svm = best_svm.predict_proba(X_test)[:, 1]
best_y_pred_svm = best_svm.predict(X_test)6. 最优模型评估
· 在参数调优阶段,实验同时完成了最优参数在模型中的应用并在测试集上进行了预测,现进行各个最优参数模型的效果评估。
final_models = [best_rf, best_xgb, best_lr, best_svm]
plt.figure(figsize=(8,6))
for model, name in zip(final_models, model_names):
y_pred_prob = model.predict_proba(X_test)[:, 1]
fpr, tpr, _ = roc_curve(y_test, y_pred_prob)
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, lw=2, label='{} (AUC = {:.2f})'.format(name, roc_auc))
plt.plot([0, 1], [0, 1], color='navy', linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()
for model, name in zip(final_models, model_names):
y_pred = model.predict(X_test)
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(5,4))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title('{} Confusion Matrix'.format(name))
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()输出结果如下:
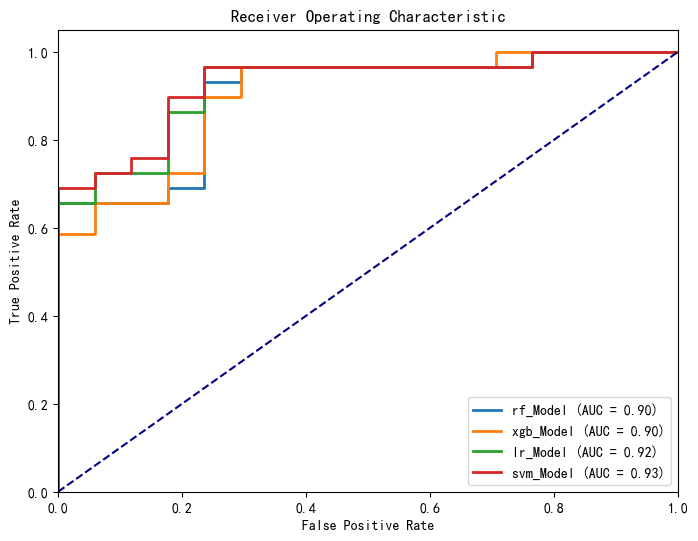
![]()
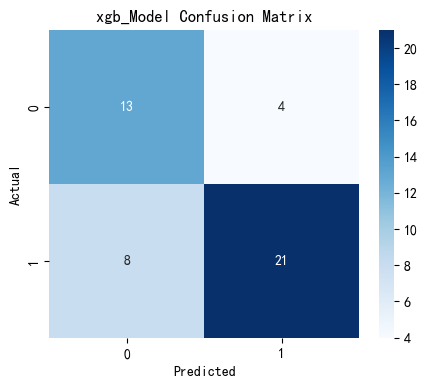
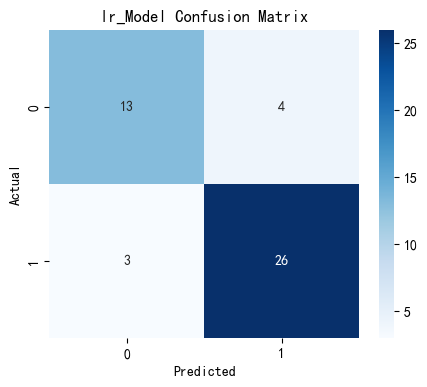
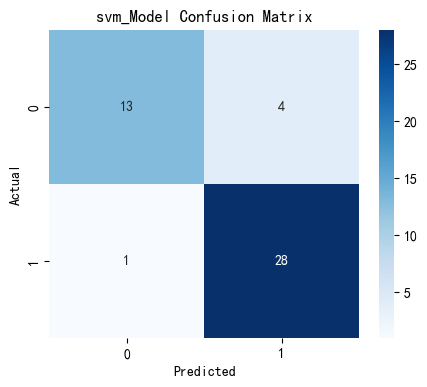
可以看到,经过网格搜索参数调优,支持向量机模型的准确率提升显著,且分类效果明显提高,最终以支持向量机分类器作为心脏病预测模型。
7. 特征重要性分析
使用SHAP值解释模型预测,并分析各特征对预测结果的影响程度,从而识别对心脏病预测最重要的特征。
import shap
from sklearn.inspection import PartialDependenceDisplay
plt.rcParams['font.sans-serif'] = ['DejaVu Sans']
tree_models = [best_xgb]
Kernel_models = [best_lr, best_svm, best_rf]
# 创建一个解释器对象的列表
explainers = []
for model in tree_models:
# 使用 TreeExplainer 支持基于树的模型 (XGBoost)
explainer = shap.TreeExplainer(model)
explainers.append(explainer)
for model in Kernel_models:
# 使用 KernelExplainer 支持任意模型 (逻辑回归,SVM, 随机森林)
explainer = shap.KernelExplainer(model.predict, data = X_train)
explainers.append(explainer)
# 计算 SHAP 值
shap_values_list = [explainer.shap_values(X_test) for explainer in explainers]
# 绘制 SHAP 摘要图
for i, name in enumerate(model_names):
print(f"Model: {name}")
shap.summary_plot(shap_values_list[i], X_test, plot_type="bar")
shap.summary_plot(shap_values_list[i], X_test)输出结果如下:
随机森林模型: xgboost模型:
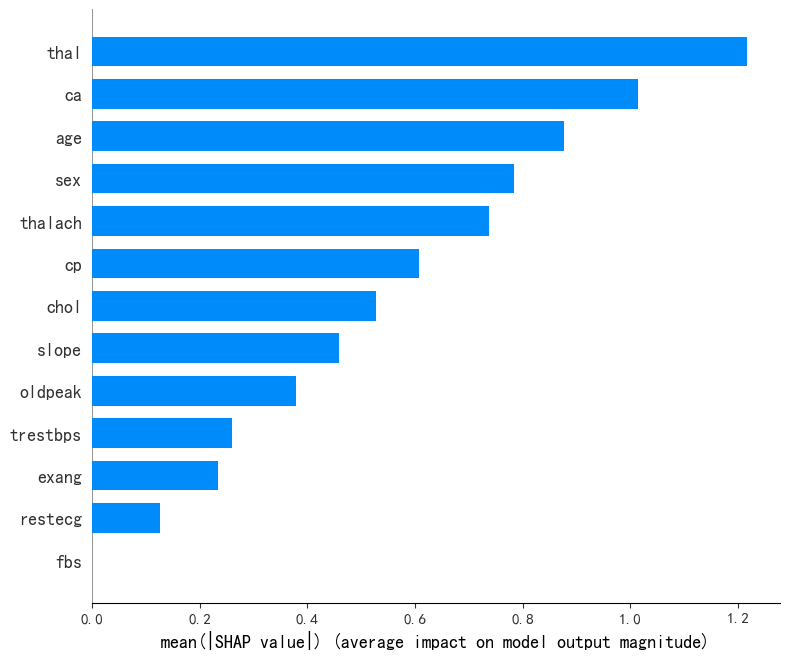
决策树模型: 支持向量机模型:
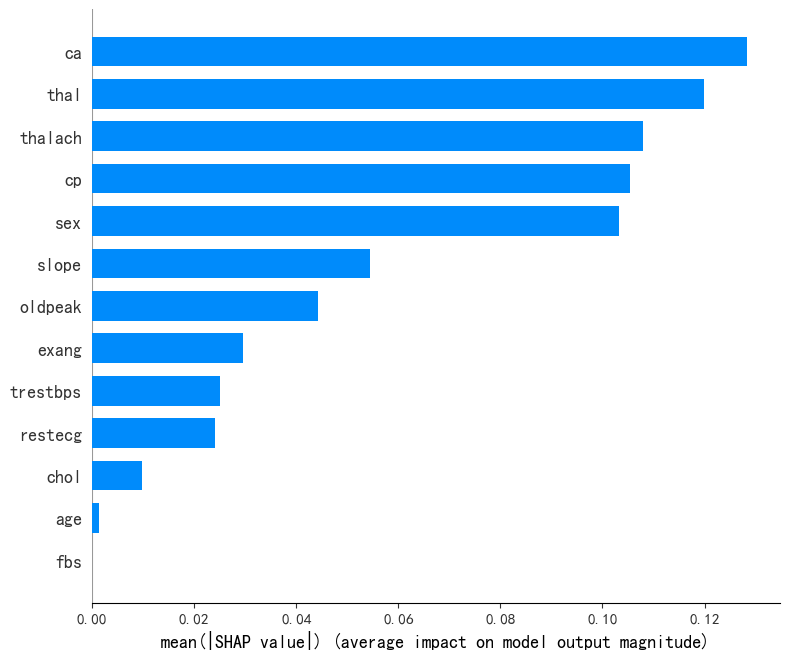
可以看出,在随机森林模型中,“thal”、“ca”、“age”为前3重要的特征,“fbs”特征则未被随机森林模型采用;
在xgboost模型中,“ca”、“thal”、“thalach”为前3重要的特征,在随机森林模型有较高贡献率的“age”特征在xgboost模型的重要性接近为0,“fbs”特征则同样未被xgboost模型采用;
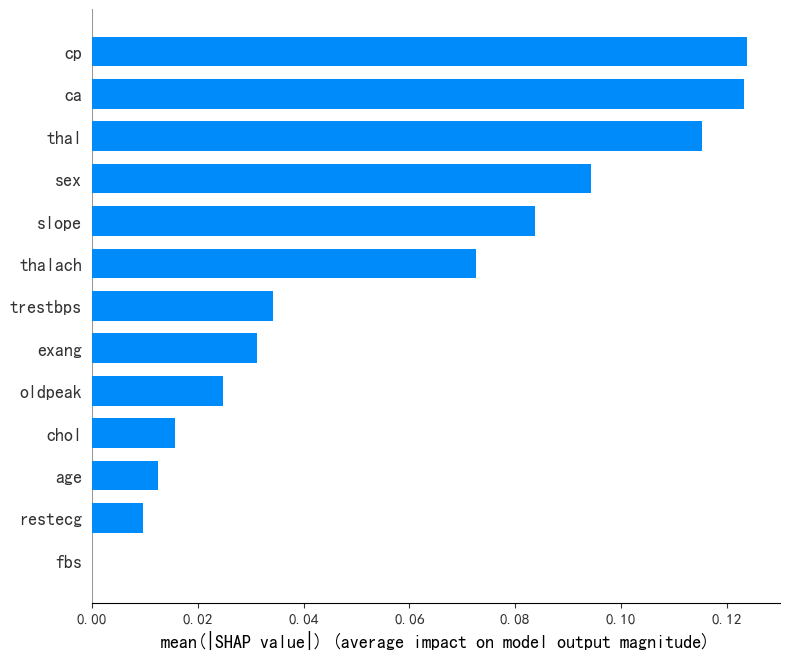
在逻辑回归模型中,“cp”、“ca”、“thal”为前3重要的特征,在随机森林模型有较高贡献率的“age”特征在逻辑回归模型的重要性较低,“fbs”特征则同样未被逻辑回归模型采用;
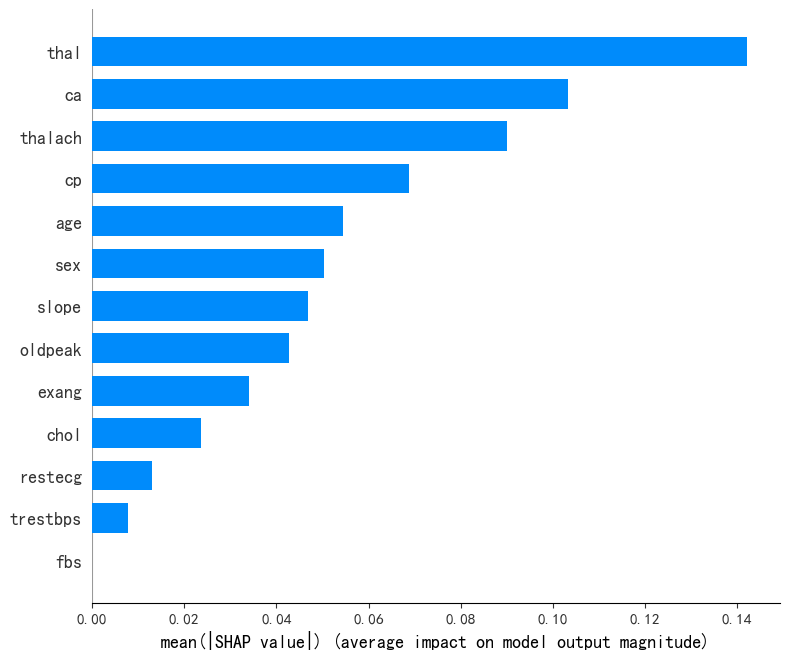
在支持向量机模型中,“thal”、“ca”、“thalach”为前3重要的特征,与xgboost模型SHAP库结果输出较为相似;“fbs”特征则同样未被支持向量机模型采用。
总结:“fbs”特征未被所有模型采用,“thal”、“ca”、“cp”在所有模型均有较大重要性。
三、总代码实现
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_curve, auc, confusion_matrix, classification_report
import matplotlib.pyplot as plt
import seaborn as sns
import shap
#1、加载数据
df = pd.read_csv('heart.csv')
X = df.drop('target', axis=1)
y = df['target']
#2、数据预处理
from scipy import stats
import numpy as np
# 检测缺失值
print("Missing values in test data:\n", df.isnull().sum())
#数据异常值检测(使用Z-score方法)
z_scores_X = stats.zscore(X)
z_scores_y = stats.zscore(y)
abs_z_scores_X = np.abs(z_scores_X)
abs_z_scores_y = np.abs(z_scores_y)
for col in X.columns:
plt.figure(figsize=(6, 4))
sns.boxplot(x=X[col])
plt.title(f'Boxplot of {col}')
plt.show()
plt.rcParams['font.family'] = 'SimHei'
plt.figure(figsize=(12, 8))
sns.boxplot(data=y)
plt.title('用于异常检测的y的箱线图')
plt.show()
#处理异常值
def remove_outliers_iqr(df, factor=1.5):
df_cleaned = df.copy()
for col in df.columns:
Q1 = df[col].quantile(0.25)
Q3 = df[col].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - factor * IQR
upper_bound = Q3 + factor * IQR
df_cleaned = df_cleaned[(df_cleaned[col] >= lower_bound) & (df_cleaned[col] <= upper_bound)]
return df_cleaned
cleaned_df_X = remove_outliers_iqr(X)
cleaned_df_y = y[cleaned_df_X.index]
print("原始样本数量:", len(X))
print("清洗后样本数量:", len(cleaned_df_X))
#3、划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(cleaned_df_X, cleaned_df_y, test_size=0.2, random_state=7)# 按照 80% 训练集,20% 测试集划分
print("训练集特征维度:", X_train.shape)
print("测试集特征维度:", X_test.shape)
print("训练集目标维度:", y_train.shape)
print("测试集目标维度:", y_test.shape)
#4、随机森林初始化并训练模型
rf_model = RandomForestClassifier(n_estimators=100, random_state=7)
rf_model.fit(X_train, y_train)
# 预测概率与类别
y_prod_rf = rf_model.predict_proba(X_test)[:, 1]
y_pred_rf = rf_model.predict(X_test)
#5、xgboost模型初始化并训练模型
from xgboost import XGBClassifier
xgb_model = XGBClassifier(use_label_encoder=False, eval_metric='logloss')
xgb_model.fit(X_train, y_train)
# 预测概率与类别
y_prod_xgb = rf_model.predict_proba(X_test)[:, 1]
y_pred_xgb = rf_model.predict(X_test)
#6、luogistic回归模型初始化并训练模型
from sklearn.linear_model import LogisticRegression
lr_model = LogisticRegression()
lr_model.fit(X_train, y_train)
# 预测概率与类别
y_prod_lr = rf_model.predict_proba(X_test)[:, 1]
y_pred_lr = rf_model.predict(X_test)
#7、SVM模型初始化并训练模型
from sklearn.svm import SVC
svm_model = SVC(probability=True)
svm_model.fit(X_train, y_train)
# 预测概率与类别
y_prod_svm = rf_model.predict_proba(X_test)[:, 1]
y_pred_svm1 = rf_model.predict(X_test)
#8、绘制 ROC 曲线与混淆矩阵
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
models = [rf_model, xgb_model, lr_model, svm_model]
model_names = ['rf_Model', 'xgb_Model', 'lr_Model', 'svm_Model']
plt.figure(figsize=(8,6))
for model, name in zip(models, model_names):
y_pred_prob = model.predict_proba(X_test)[:, 1]
fpr, tpr, _ = roc_curve(y_test, y_pred_prob)
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, lw=2, label='{} (AUC = {:.2f})'.format(name, roc_auc))
plt.plot([0, 1], [0, 1], color='navy', linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()
from sklearn.metrics import confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
for model, name in zip(models, model_names):
y_pred = model.predict(X_test)
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(5,4))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title('{} Confusion Matrix'.format(name))
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()
#9、参数调优
from sklearn.model_selection import GridSearchCV
param_grid_rf = {
'n_estimators': [50, 100, 200],
'max_depth': [None, 10, 20],
'min_samples_split': [2, 5],
'min_samples_leaf': [1, 2]
}
grid_search_rf = GridSearchCV(RandomForestClassifier(random_state=7), param_grid_rf, cv=5)
grid_search_rf.fit(X_train, y_train)
best_rf = grid_search_rf.best_estimator_
#print("Best Random Forest Parameters:", grid_search_rf.best_params_)
best_y_prod_rf = best_rf.predict_proba(X_test)[:, 1]
best_y_pred_rf = best_rf.predict(X_test)
param_grid_xgb = {
'n_estimators': [50, 100, 200],
'learning_rate': [0.01, 0.1],
'max_depth': [3, 6],
'subsample': [0.8, 1.0],
'colsample_bytree': [0.8, 1.0]
}
grid_search_xgb = GridSearchCV(XGBClassifier(use_label_encoder=False, eval_metric='logloss'), param_grid_xgb, cv=5)
grid_search_xgb.fit(X_train, y_train)
best_xgb = grid_search_xgb.best_estimator_
#print("Best XGBoost Parameters:", grid_search_xgb.best_params_)
best_y_prod_xgb = best_xgb.predict_proba(X_test)[:, 1]
best_y_pred_xgb = best_xgb.predict(X_test)
param_grid_lr = {
'C': [0.1, 1, 10],
'penalty': ['l1', 'l2'],
'solver': ['liblinear']
}
grid_search_lr = GridSearchCV(LogisticRegression(), param_grid_lr, cv=5)
grid_search_lr.fit(X_train, y_train)
best_lr = grid_search_lr.best_estimator_
#print("Best Logistic Regression Parameters:", grid_search_lr.best_params_)
best_y_prod_lr = best_lr.predict_proba(X_test)[:, 1]
best_y_pred_lr = best_lr.predict(X_test)
param_grid_svm = {
'C': [0.1, 1, 10],
'kernel': ['linear', 'rbf'],
'gamma': ['scale', 'auto']
}
grid_search_svm = GridSearchCV(SVC(probability=True), param_grid_svm, cv=5)
grid_search_svm.fit(X_train, y_train)
best_svm = grid_search_svm.best_estimator_
#print("Best SVM Parameters:", grid_search_svm.best_params_)
best_y_prod_svm = best_svm.predict_proba(X_test)[:, 1]
best_y_pred_svm = best_svm.predict(X_test)
final_models = [best_rf, best_xgb, best_lr, best_svm]
plt.figure(figsize=(8,6))
for model, name in zip(final_models, model_names):
y_pred_prob = model.predict_proba(X_test)[:, 1]
fpr, tpr, _ = roc_curve(y_test, y_pred_prob)
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, lw=2, label='{} (AUC = {:.2f})'.format(name, roc_auc))
plt.plot([0, 1], [0, 1], color='navy', linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()
for model, name in zip(final_models, model_names):
y_pred = model.predict(X_test)
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(5,4))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title('{} Confusion Matrix'.format(name))
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()
import shap
from sklearn.inspection import PartialDependenceDisplay
plt.rcParams['font.sans-serif'] = ['DejaVu Sans']
tree_models = [best_xgb]
Kernel_models = [best_lr, best_svm, best_rf]
# 创建一个解释器对象的列表
explainers = []
for model in tree_models:
# 使用 TreeExplainer 支持基于树的模型 (XGBoost)
explainer = shap.TreeExplainer(model)
explainers.append(explainer)
for model in Kernel_models:
# 使用 KernelExplainer 支持任意模型 (逻辑回归,SVM, 随机森林)
explainer = shap.KernelExplainer(model.predict, data = X_train)
explainers.append(explainer)
# 计算 SHAP 值
shap_values_list = [explainer.shap_values(X_test) for explainer in explainers]
# 绘制 SHAP 摘要图
for i, name in enumerate(model_names):
print(f"Model: {name}")
shap.summary_plot(shap_values_list[i], X_test, plot_type="bar")
shap.summary_plot(shap_values_list[i], X_test)
四、结论与改进方向
结论:本实验成功构建了一个基于随机森林的心脏病二分类预测模型。通过全面的数据探索、模型训练和评估过程,验证了模型的有效性,并选择支持向量机分类器作为心脏病预测模型。特征重要性分析为理解心脏病风险因素提供了有价值的见解。实验结果展示了机器学习在医疗预测领域的应用潜力,为辅助医生诊断提供了可能的决策支持工具。
未来可改进方向:
-
进行更细致的超参数调优
-
扩大数据集规模以提高模型泛化能力
-
探索更复杂的特征工程方法
总体而言,本实验为心脏病预测提供了一个可行的机器学习解决方案,并为进一步研究奠定了基础。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)