SpringAI如何使用MCP和RAG
如今各种大模型语言是越来越多,SpringAI能够很好的帮助我们对接各种大模型。SpringAI。
文章目录
前言
如今各种AI大模型层出不穷,如上半年爆火的DeepSeek。如何让自己的应用接入AI,SpringAI提供了开箱即用的功能,能够很好的帮助我们对接各种大模型。SpringAI
一、MCP
模型上下文协议(MCP)是一种标准化协议,使AI大模型能够以结构化的方式与外部工具和资源进行交互。也可以简单理解为AI应用提供了连接其他资源的接口,这些接口提供了通用的功能如:天气查询、地理位置坐标。下面介绍如何使用MCP。
假设公司有多个项目对接了AI大模型,但是有些公共数据是需要查询数据库或者调用其他团队的接口获取,为了方便我们想把这些公共的数据抽取出来形成一个MCP Server,AI大模型使用时只需要接入不同的MCP服务即可。
1.MCP Server
依赖引入
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-server-webmvc</artifactId>
</dependency>
</dependencies>
假如有一个查询TOP5 TPS接口作为MCP工具。代码如下
@Service
public class To5InterfaceService {
@SuppressWarnings("unused")
@Tool(description = "查询高tps接口,会返回调用量最大的前5个接口")
public List<String> to5Interface() {
//System.out.println("To5InterfaceService ...");
//相关数据可以查询数据库等
return List.of("接口1", "接口2", "接口3", "接口4", "接口5");
}
}
@Configuration
public class McpToolConfig {
@Bean
public ToolCallbackProvider to5Interface(To5InterfaceService to5InterfaceService) {
return MethodToolCallbackProvider
.builder()
.toolObjects(to5InterfaceService)
.build();
}
}
2.MCP Client
依赖引入
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--连接MCP服务-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-client</artifactId>
</dependency>
<!--阿里AI-->
<!-- <dependency>-->
<!-- <groupId>com.alibaba.cloud.ai</groupId>-->
<!-- <artifactId>spring-ai-alibaba-starter-dashscope</artifactId>-->
<!-- <version>1.0.0.2</version>-->
<!-- </dependency>-->
<!--智谱AI-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-zhipuai</artifactId>
</dependency>
<!--向量库-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>
<!--RAG支持-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-rag</artifactId>
</dependency>
<!--PDF解析器-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>
</dependencies>
ChatClient配置
@Bean
public ChatClient chatClient(ChatClient.Builder builder, ToolCallbackProvider toolCallbackProvider) {
return builder
.defaultToolCallbacks(toolCallbackProvider)
.build();
}
配置方式一:直接配置mcp服务的地址
spring:
ai:
mcp:
client:
#是否启用
enabled: true
request-timeout: 30s
sse:
connections:
server1:
# mcp server启动后的地址
url: http://localhost:8081
配置方式二:脚本方式连接
spring:
ai:
mcp:
client:
#是否启用
enabled: true
request-timeout: 30s
#sse:
# connections:
# server1:
# url: http://localhost:8081
stdio:
servers-configuration: classpath:mcp-servers.json
mcp-servers.json
{
"mcpServers": {
"custom-mcp-server1": {
"command": "java",
"args": [
"-Dspring.ai.mcp.server.stdio=true",
"-Dspring.main.web-application-type=none",
"-Dspring.main.banner-mode=off",
"-Dlogging.level.root=off",
"-jar",
"C:\\Users\\Administrator\\Desktop\\mcp\\mcp-server.jar"
],
"env": {
"key1": "value1"
}
}
}
}
脚本中参数含义
mcpServers:json第一层key的名字,所有的mcp服务都放在这个key下面,名称可以任意
custom-mcp-server1:自定义mcp服务名,多个mcp服务层级相同
command:需要执行的命令,这里用java命令来启动mcp服务的jar文件
args:启动命令需要的参数
spring.ai.mcp.server.stdio:开启mcp服务的sdtio模式(sdtio模式实际上是读取标准的输入输出流来实现的,所以输出不能有任何无关数据,要关闭banner图打印和日志输出,以及代码中不能有用System.out.println输出的内容)
spring.main.web-application-type:作为一个非web项目启动
env:环境变量
AI问答效果
二、RAG
检索增强生成(RAG),可以克服大语言模型在长篇内容、事实准确性和上下文感知方面的局限性。
RAG的使用首先要配置向量库,嵌入模型会把数据转成数字向量存储起来,在检索时通过计算向量之间的相似度(一般会使用余弦相似度、欧式距离等算法)来查询出想要的数据。相关依赖在MCP Client配置中都已经包含。AI模型这里选择智谱AI,因为其支持嵌入模型。SpringAI目前对接了多种嵌入模型,如OpenAI、Ollama等,以及国产的MiniMax、千帆和智谱,目前DeepSeek暂时不支持嵌入模型。
向量存储代码配置
@Bean
public VectorStore vectorStore(EmbeddingModel embeddingModel) {
//基于内存存储的向量库,目前springAI支持多种向量数据据库Redis、Milvus等等,可以自行尝试
SimpleVectorStore simpleVectorStore = SimpleVectorStore
.builder(embeddingModel)
.build();
//simpleVectorStore.add(getInstructions());
//向量库中添加数据(假如数据存储在PDF中),目前SpringAI支持多种格式的数据加载,如JSON、Text、HTML、Markdown、PDF等
simpleVectorStore.add(getDocsFromPdf());
return simpleVectorStore;
}
private List<Document> getDocsFromPdf() {
PagePdfDocumentReader documentReader = new PagePdfDocumentReader("file:C:\\Users\\Administrator\\Desktop\\中共中央办公厅国务院办公厅印发《育儿补贴制度实施方案》_中央有关文件_中国政府网.pdf",
PdfDocumentReaderConfig.builder()
.withPageTopMargin(0)
//文档内容格式化
.withPageExtractedTextFormatter(ExtractedTextFormatter.builder()
.withNumberOfTopTextLinesToDelete(0)
.build())
//一个document放一页pdf
.withPagesPerDocument(1)
.build());
return documentReader.get();
}
Controller配置
@GetMapping(value = "/ai/rag", produces = "text/html;charset=UTF-8")
public Flux<String> call(@RequestParam("msg") String msg) {
// 配置文档检索器(从配置的向量库中查询数据)
DocumentRetriever retriever = VectorStoreDocumentRetriever.builder()
//配置好的向量存储
.vectorStore(vectorStore)
// 设置相似度阈值
.similarityThreshold(0.5)
// 返回前5个最相关的文档
.topK(5)
.build();
//RetrievalAugmentationAdvisor能够个性化定制Advisor
Advisor advisor = RetrievalAugmentationAdvisor.builder()
//允许模型上下文为空
.queryAugmenter(ContextualQueryAugmenter.builder()
.allowEmptyContext(true)
.build())
.documentRetriever(retriever)
.build();
return ragChatClient.prompt()
.user(msg)
.advisors(advisor)
.stream()
.content();
}
让AI根据《育儿补贴制度实施方案》中的内容进行回答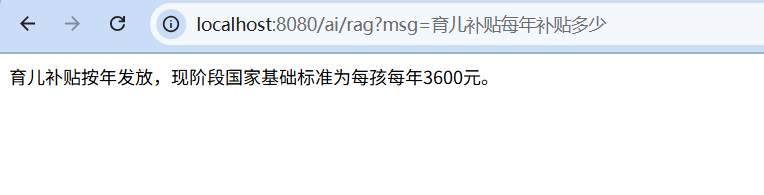

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)