residual connection, 残差链接
背景更深的网络理论上会有更强的表达能力, 但实际训练中遇到的问题是层数加深后, 训练集误差不降反升.图: layer-20 与 layer-56 的比较, 后者训练集误差更大residual-connection标准实现图: 维度一样, 可以直接相加, 可以是 a+b, 或 tf.add(a,b), 是 element-wise 的op.维度变化论文给出了3中选择.A: ze...
背景
更深的网络理论上会有更强的表达能力, 但实际训练中遇到的问题是层数加深后, 训练集误差不降反升. 这是因为网络变深后, 梯度消失隐患也会增大, 模型性能会不升反降.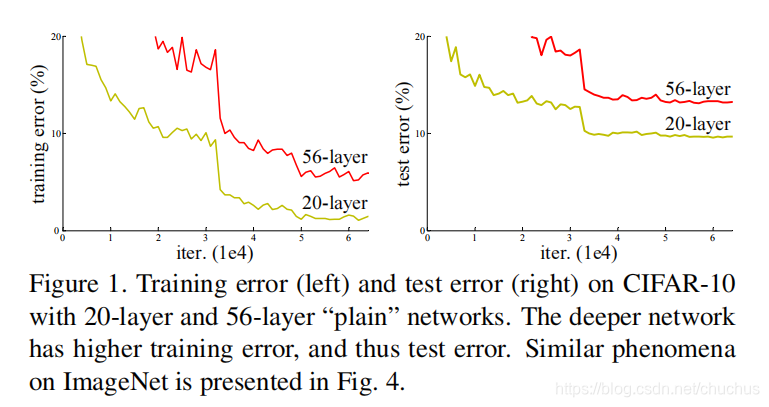
图: layer-20 与 layer-56 的比较, 后者训练集误差更大
residual-connection
为了应对梯度消失挑战, ResNet 的设计理念是允许低层的原始信息直接传到后续的高层, 让高层专注残差的学习, 避免模型的退化.
假设理论
一个假设是, 若干个 non-linear layers 可以渐进地逼近于 一个复杂的函数 H ( x ) H(x) H(x). 那么同理, 我们也可以让这些 layers 只学习残差函数,
residual function F ( x ) : = H ( x ) − x F(x) := H(x) - x F(x):=H(x)−x, 所以学习的任务由 H(x) 变成了 F(x), 学习难度也会有变化.
后续模块的输入依旧是 F ( x ) + x F(x)+x F(x)+x.
标准实现
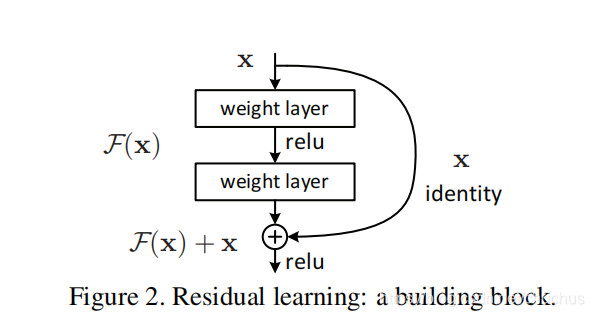
图: 维度一样, 可以直接相加, 可以是 a+b, 或 tf.add(a,b), 是 element-wise 的op.
注意: 残差相加之前, 又经过了一次 linear 投影, 一般不会把x直接加载 激活层之后,像 x + σ ( ⋅ ) x+\sigma (\cdot) x+σ(⋅) 这样, 而是 x + w ( σ ( ⋅ ) ) x+w(\sigma (\cdot)) x+w(σ(⋅)) .
再之后, 是 激活层还是 norm 处理似乎不太重要, 可对比 transformer 中的 FeedForward.
维度不等
论文给出了3中选择.
- A: zero-padding for increasing dimensions, and all shortcuts are parameter free.
- B: projection shortcuts for increasing dimensions, , and other shortcuts are identity.
- C: all shorts are projection
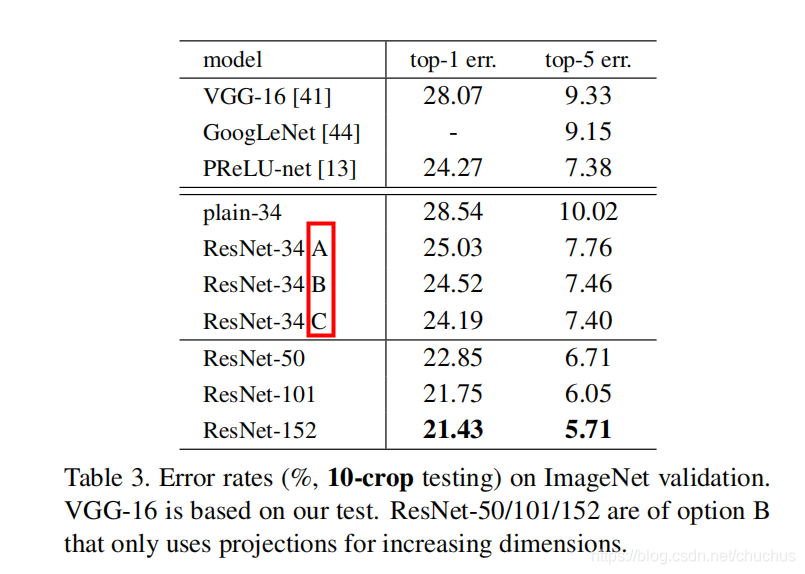
图: A/B/C 三种选择的实验对比, 效果相差不大, 为了降低复杂度, 论文选用了B.
layer response 分析
按照上文的假设理论, 残差网络中的输出F(x)( 即 H(x)-x, 把它叫 response ) 相较 普通网络中 的输出H(x), response strength 会变小. 论文中用标准差去衡量响应强度, 见图 figure 7.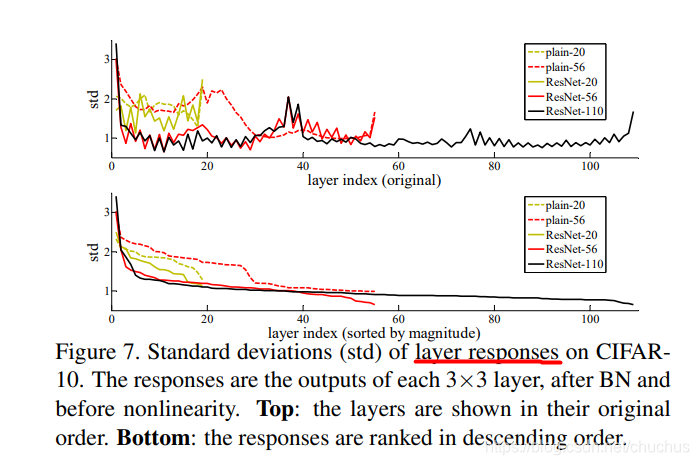
参考
- paper,Deep Residual Learning for Image Recognition
- 他人blog,深度残差网络RESNET

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)