L和T的识别
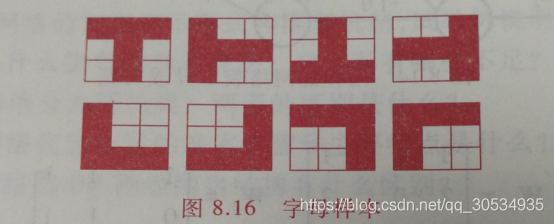
题目:如图所示,每个字母用3×3的二维二值图表示,令黑方格为1,白方格为0,每个字母有四个样本,包括正常字母位置及旋转90°,180°和270°的图像。希望输入不同位置下的T时,网络输出为1,而输入不同位置的L时,网络的输出为0。用BP算法求出权系数和阈值。(建议:选择网络结构为9-3-1。隐单元非线性函数为,输出单元非线性函数为)步骤:1、网络结构选定此题使用较为简单的双层神经网络即可...
题目:
如图所示,每个字母用3×3的二维二值图表示,令黑方格为1,白方格为0,每个字母有四个样本,包括正常字母位置及旋转90°,180°和270°的图像。希望输入不同位置下的T时,网络输出为1,而输入不同位置的L时,网络的输出为0。用BP算法求出权系数和阈值。(建议:选择网络结构为9-3-1。隐单元非线性函数为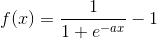 ,输出单元非线性函数为
,输出单元非线性函数为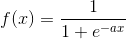 )
)
步骤:
1、网络结构选定
此题使用较为简单的双层神经网络即可解决问题。在输入层,我们需要将3×3的二维二值图转换为9维的函数输入,所以输入层神经元数目为9;输出层的结果为0或1,则输出层神经元数目为1;隐藏层根据建议拟定为3。则最终的网络结构是:9-3-1。
2、单元层函数
①线性函数
隐藏层: 输出层:
②非线性函数
隐藏层: 输出层:
3、网络参数设定
网络节点9-3-1。
优化器选用随机梯度下降算法。
优化器自适应学习率设置为:0.001。
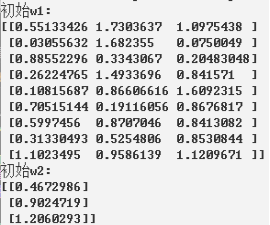
初始权值为0.0均值1.0方差的正态分布。
损失函数设定为均方差函数。
训练集和测试集均选用如图所示的八个字母样本。
每个batch的大小设置为8。
用50000个epochs,每1000次计算并打印测试集损失函数。
实验结果:
1、线性函数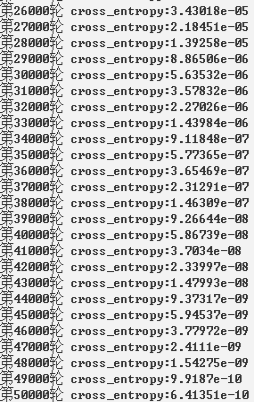
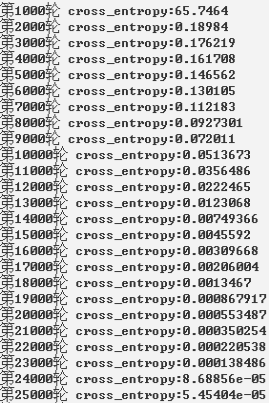
2、非线性函数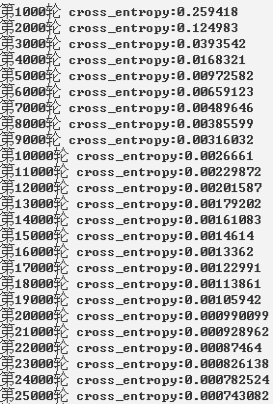
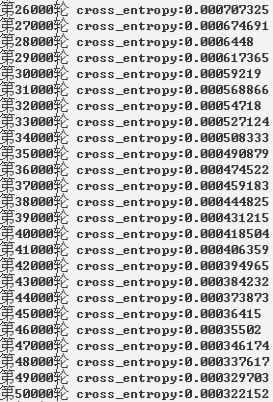

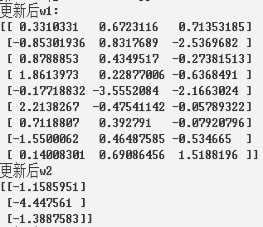
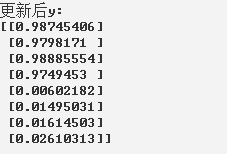
代码:
1、LT_linear
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 训练集X和对应的label Y,也就是零件的次品为0,正常零件为1
X_data = [[1,1,1,0,1,0,0,1,0],[1,0,0,1,1,1,1,0,0],[0,1,0,0,1,0,1,1,1],[0,0,1,1,1,1,0,0,1], [1,0,0,1,0,0,1,1,1],[0,0,1,0,0,1,1,1,1],[1,1,1,0,0,1,0,0,1],[1,1,1,1,0,0,1,0,0]]
X_data = np.array(X_data)
Y_data = [[1.,1.,1.,1.,0.,0.,0.,0.]]
Y_data = np.array(Y_data).T
date_size =len(X_data)# 定义训练数据batch的大小
batch_size = 4# 定义变量
w1 = tf.Variable(tf.random_normal([9,3],stddev=1),name="w1")
w2 = tf.Variable(tf.random_normal([3,1],stddev=1),name="w2")
w1 = abs(w1)
w2 = abs(w2)
# 使用placeholder
x = tf.placeholder(tf.float32,shape=[None,9],name="x-input")
y_ = tf.placeholder(tf.float32,shape=[None,1],name="y-input")
a = tf.matmul(x,w1)
y = tf.matmul(a,w2)
cross_entropy = tf.reduce_mean(tf.square(y_-y))
train_step = tf.train.GradientDescentOptimizer(0.001).minimize(cross_entropy)
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
print("初始w1:")
print(sess.run(w1))
print("初始w2:")
print(sess.run(w2))
for i in range(50000):
for k in range(0, date_size, batch_size):
mini_batch = X_data[k:k + batch_size]
train_y = Y_data[k:k + batch_size]
sess.run(train_step,feed_dict={x: mini_batch, y_: train_y})
if i %1000 ==0:
total_cross_entropy = sess.run(cross_entropy,feed_dict={x: X_data, y_: Y_data})
print("第%d轮 cross_entropy:%g" %(i+1000,total_cross_entropy))
yy = sess.run(y,feed_dict={x:X_data})
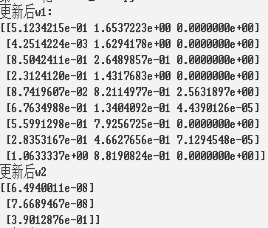
print("更新后w1:")
print(sess.run(w1))
print("更新后w2")
print(sess.run(w2))
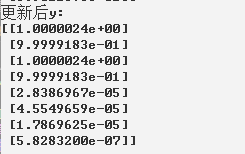
print("更新后y:")
print(sess.run(y,feed_dict={x:X_data}))
2、LT_unlinear
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 训练集X和对应的label Y,也就是零件的次品为0,正常零件为1
X_data = [[1.,1.,1.,0.,1.,0.,0.,1.,0.],[1.,0.,0.,1.,1.,1.,1.,0.,0.],[0.,1.,0.,0.,1.,0.,1.,1.,1.],
[0.,0.,1.,1.,1.,1.,0.,0.,1.],[1.,0.,0.,1.,0.,0.,1.,1.,1.],[0.,0.,1.,0.,0.,1.,1.,1.,1.],
[1.,1.,1.,0.,0.,1.,0.,0.,1.],[1.,1.,1.,1.,0.,0.,1.,0.,0.]]
X_data = np.array(X_data)
Y_data = [[1.,1.,1.,1.,0.,0.,0.,0.]]
Y_data = np.array(Y_data).T
date_size =len(X_data)# 定义训练数据batch的大小
batch_size = 4# 定义变量
w1 = tf.Variable(tf.random_normal([9,3],stddev=1),name="w1")
w2 = tf.Variable(tf.random_normal([3,1],stddev=1),name="w2")
# 使用placeholder
x = tf.placeholder(tf.float32,shape=[None,9],name="x-input")
y_ = tf.placeholder(tf.float32,shape=[None,1],name="y-input")
#a = tf.matmul(x,w1)
#y = tf.matmul(a,w2)
a = tf.subtract(tf.divide(2.,tf.add(1.,tf.exp(-tf.matmul(x,w1)))),1.)
y = tf.divide(1.,tf.add(1.,tf.exp(-tf.matmul(a,w2))))
cross_entropy = tf.reduce_mean(tf.square(y_-y))
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
print("初始w1:")
print(sess.run(w1))
print("初始w2:")
print(sess.run(w2))
for i in range(50000):
for k in range(0, date_size, batch_size):
mini_batch = X_data[k:k + batch_size]
train_y = Y_data[k:k + batch_size]
sess.run(train_step,feed_dict={x: mini_batch, y_: train_y})
if i %1000 ==0:
total_cross_entropy = sess.run(cross_entropy,feed_dict={x: X_data, y_: Y_data})
print("第%d轮 cross_entropy:%g" %(i+1000,total_cross_entropy))
yy = sess.run(y,feed_dict={x:X_data})
print("更新后w1:")
print(sess.run(w1))
print("更新后w2")
print(sess.run(w2))
print("更新后y:")
print(sess.run(y,feed_dict={x:X_data}))

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 5
5 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)