InvertedPendulum-v4 环境上,RL结果验证
使用DDPG,REINFORCE,SAC实验DDPGDDPG参数颇多,不好调参结果(V4上环境的最高得分上限就是1000)提高隐层数量256挑选最好的模型测试,表现结果还不错降低 batchsize结果:REINFORCEGym官方提供版本中:Gym官方代码发现:价值是有不断提升的,但是方差很大,需要训练时间长尝试一:修改奖励函数结果,一开始稳定提升,后来开始波动,使用最好和最新的网络测试,结果很
·
使用DDPG,REINFORCE,SAC实验
DDPG
DDPG参数颇多,不好调参
配置一:
self.mu = 0.0 #使用OU噪声
self.theta = 0.15
self.sigma = 0.2
self.current_noise = 0.0
actor_lr = 5e-4
critic_lr = 3e-3
num_episodes = 500
hidden_dim = 128
gamma = 0.98
tau = 0.005 # 软更新参数
buffer_size = 10000
minimal_size = 1000
batch_size = 128结果(V4上环境的最高得分上限就是1000)
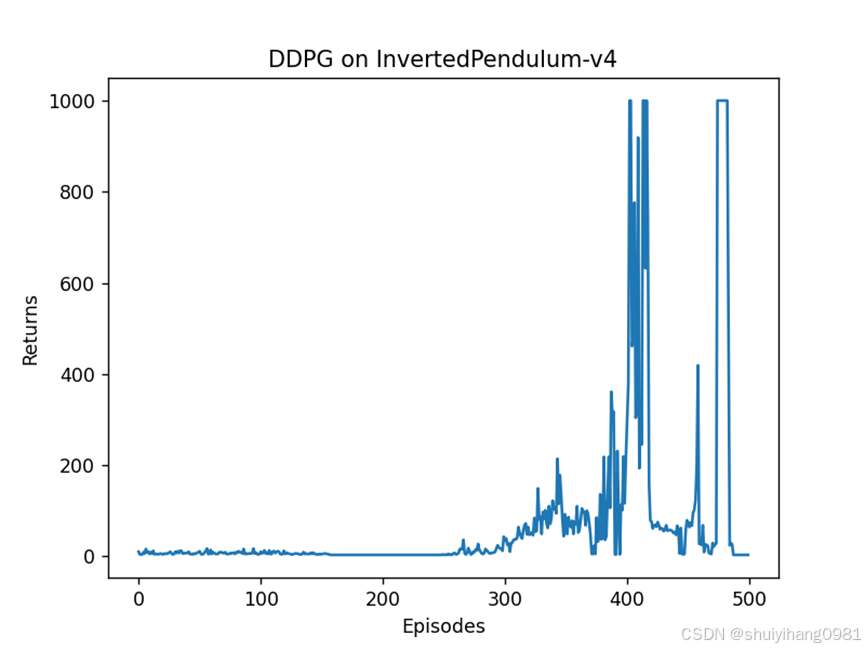
提高隐层数量256
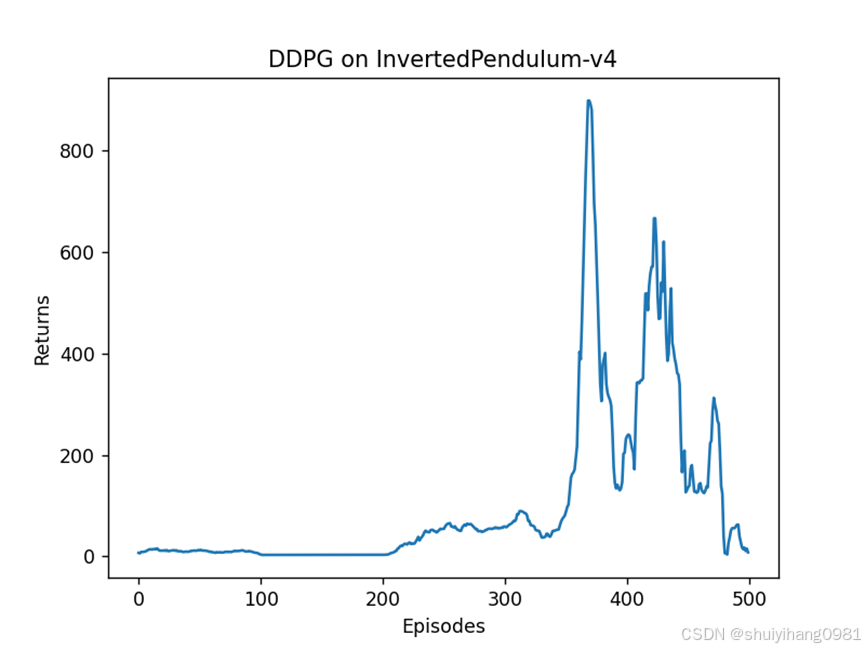
挑选最好的模型测试,表现结果还不错
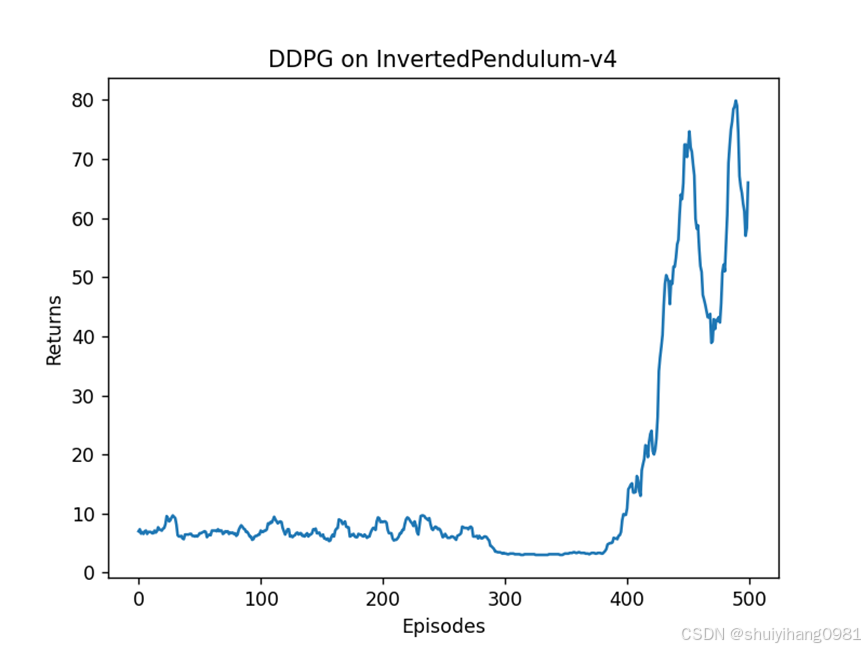
降低 batchsize结果:
REINFORCE
 https://gymnasium.farama.org/tutorials/training_agents/reinforce_invpend_gym_v26/#sphx-glr-tutorials-training-agents-reinforce-invpend-gym-v26-py
https://gymnasium.farama.org/tutorials/training_agents/reinforce_invpend_gym_v26/#sphx-glr-tutorials-training-agents-reinforce-invpend-gym-v26-py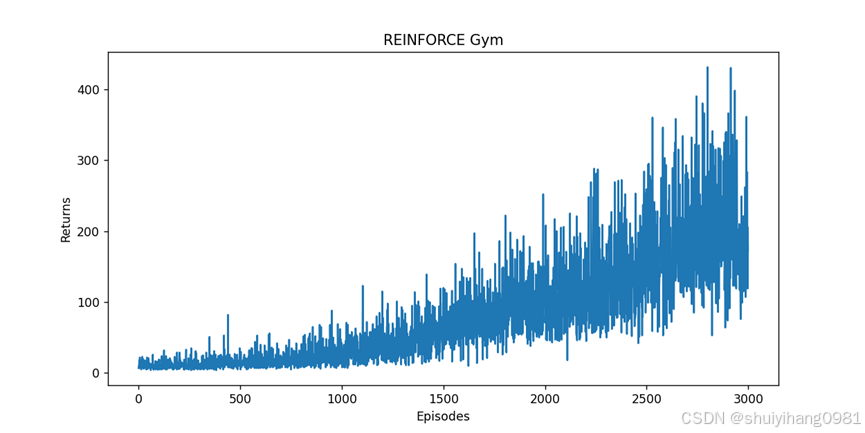
发现:价值是有不断提升的,但是方差很大,需要训练时间长
尝试一:修改奖励函数
# [小车的位置,杆的垂直角度,小车的线速度,杆子的角速度]
# 重新计算reward(float类型)
car_pos,pole_angle,car_vel,pole_ang_vel = next_state
reward = 0.5*reward - (abs(pole_angle) + abs(pole_ang_vel) + 0.5*abs(action[0]) + 0.5*abs(car_pos))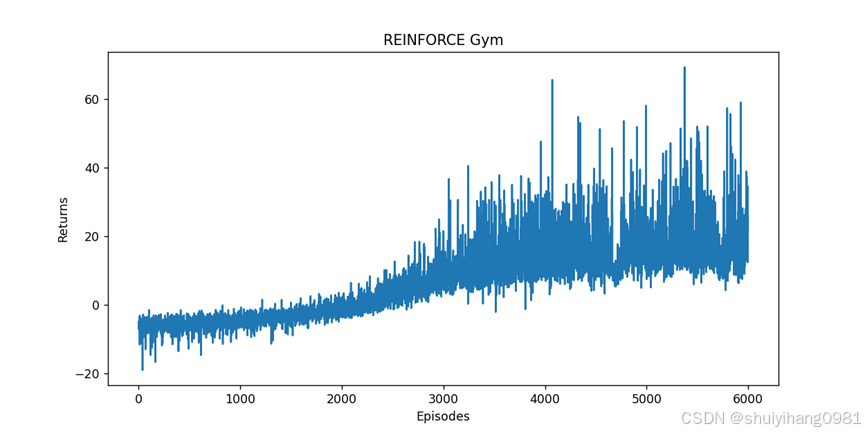
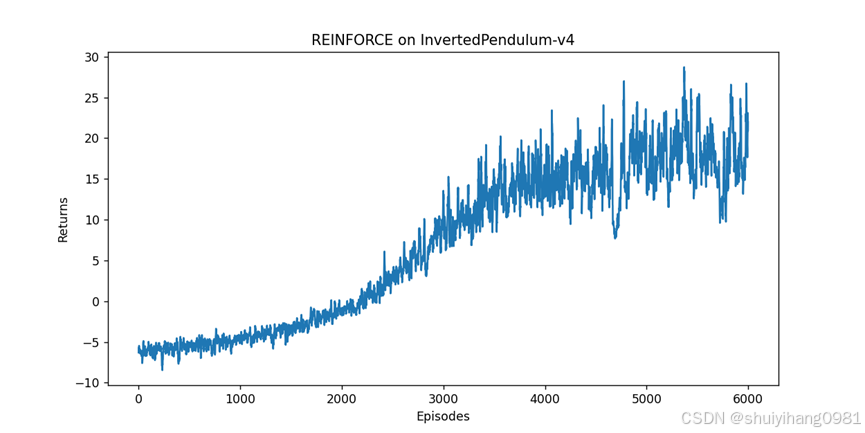
结果,一开始稳定提升,后来开始波动,使用最好和最新的网络测试,结果很差
SAC
测试结果:
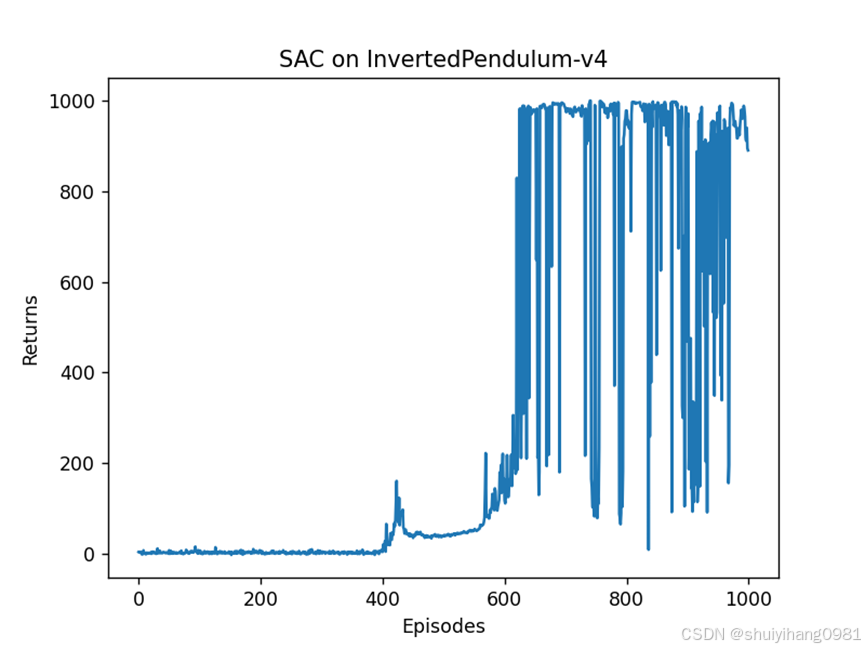
可以发现模型在650轮左右,已经能够屹立不倒,模型测试结果也很好。
降低用于随机探索的目标熵为原来0.1
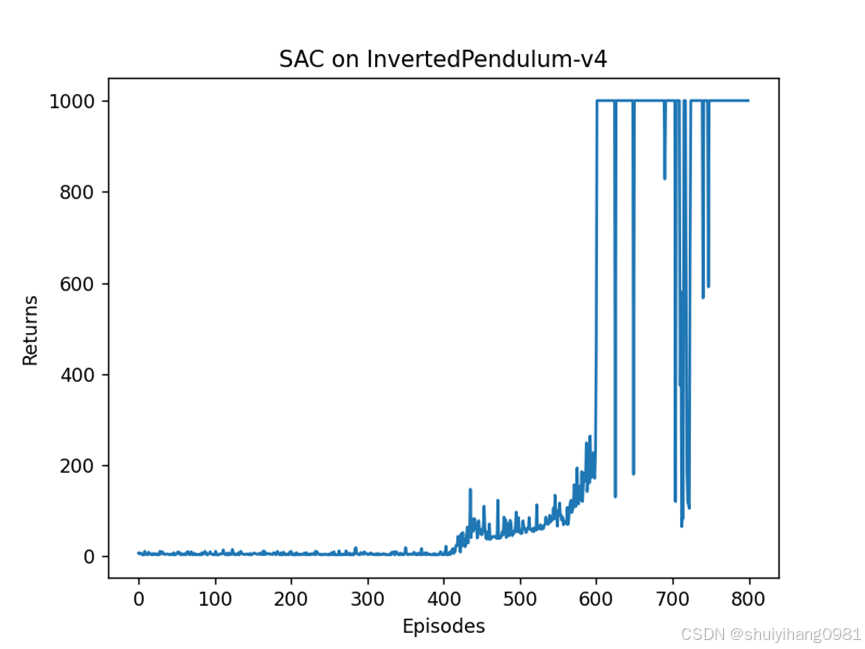
但是后续训练过程不断震荡,根据知乎上的回答:
做两个尝试:
1. 修改奖励函数为上面的
2. 对当前状态做归一化处理
其中 ,归一化操作为:
# 模型的更新函数里
def update(self, transition_dict):
...省略其他操作
#对一个batch的状态做归一化
s_mean = torch.mean(states, dim=0)
s_std = torch.std(states, dim=0)+1e-8
states = (states - s_mean) / s_std1. 只修改奖励函数
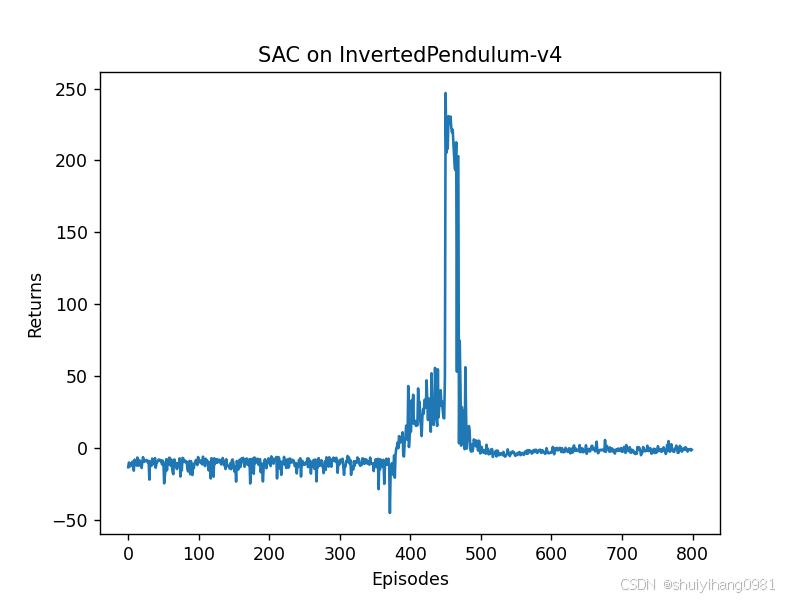
2. 只对状态做归一化
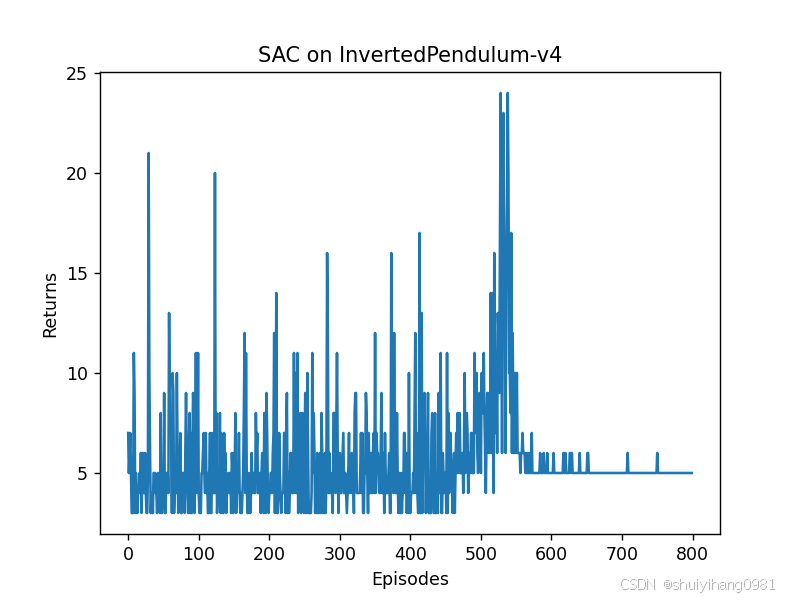
3. 修改奖励函数+对当前状态做归一化
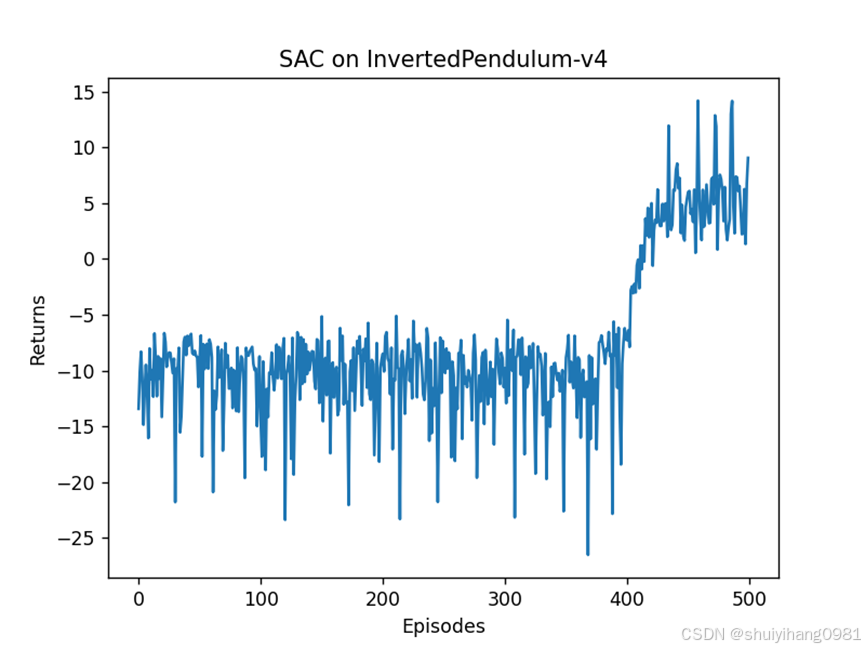
使用最好的模型做测试, 效果很差

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)