损失函数、梯度下降、优化器
优化器
损失函数、梯度下降、优化器
参考:
https://blog.csdn.net/KeKe_L/article/details/144118233
https://zhuanlan.zhihu.com/p/416979875
1、损失函数、梯度下降、优化器
损失函数:损失函数是一个衡量模型预测值与真实值之间差异的函数。
梯度下降:最核心的就是对函数求偏导,损失函数的偏导找到最小值
优化器:优化学习率,不采用固定学学率,优化梯度下降固定学习率
-
常见损失函数的简介:
损失函数是用来衡量模型预测结果与真实结果之间差异的函数。在机器学习和深度学习中,模型的目标是最小化这个差异,从而使模型能够更好地拟合数据。
均方误差(MSE):常用于回归问题,计算预测值和真实值差的平方的平均值。
交叉熵损失(Cross-Entropy Loss):常用于分类问题,度量的是两个概率分布之间的差异。
对数损失(Log Loss):是交叉熵损失的另一种形式,常用于二分类问题。
绝对误差损失(MAE):计算预测值和真实值差的绝对值平均。 -
梯度下降三种不同形式:(样本数区别,每次参数更新时计算的样本数据量不同)
随机梯度下降,只用一个样本更新权重参数。
小批量梯度下降,只用一组样本更新权重参数,对组内所有样本偏导和求均值。
批量梯度下降,只用全部样本更新权重参数,对组内所有样本偏导和求均只。
批量梯度下降法(BGD, Batch Gradient Descent)
随机梯度下降法(SGD, Stochastic Gradient Descent)
小批量梯度下降法(Mini-batch Gradient Descent)多样本参数估计参考《数理统计》的参数估计、最小二乘、最大似然。


https://blog.csdn.net/KeKe_L/article/details/144118233
梯度下降过程
1.初始化参数:权重:W,偏置:b
2.求梯度:利用损失函数求出权重W的导数。
3.参数更新:按照梯度下降公式求出新的W。
4.循环迭代:按照设定的条件或次数循环更新W。-
梯度下降存在的问题:
收敛速度慢:BGD和MBGD使用固定学习率,太大会导致震荡,太小又收敛缓慢。
局部最小值和鞍点问题:SGD在遇到局部最小值或鞍点时容易停滞,导致模型难以达到全局最优。
训练不稳定:SGD中的噪声容易导致训练过程中不稳定,使得训练陷入震荡或不收敛。 -
原始的梯度下降方法有以下问题:
在梯度平缓的维度下降非常慢,在梯度险峻的维度容易抖动,容易陷入局部极小值或鞍点。Zero gradient,gradient descent gets stuck (在高维空间中,鞍点比局部极小值更容易出现)选择一个合适的学习率可能是困难的。学习率太小会导致收敛的速度很慢,学习率太大会妨碍收敛,导致损失函数在最小值附近波动甚至偏离最小值。学习率调整试图在训练的过程中通过例如退火的方法调整学习率,即根据预定义的策略或者当相邻两代之间的下降值小于某个阈值时减小学习率。然而,策略和阈值需要预先设定好,因此无法适应数据集的特点对所有的参数更新使用同样的学习率。
在使用梯度下降时,需要进行调优,哪些地方需要调优呢?
(1)算法的步长选择(学习率)。在前面的算法描述中,我提到取步长为1,但是实际上取值取决于数据样本,可以多取一些值,从大到小,分别运行算法,看看迭代效果,如果损失函数在变小,说明取值有效,否则要增大步长。前面说了。步长太大,会导致迭代过快,甚至有可能错过最优解。步长太小,迭代速度太慢,很长时间算法都不能结束。所以算法的步长需要多次运行后才能得到一个较为优的值。很难选择一个合适的学习率,如果学习率太小,将会导致收敛非常缓慢;如果学习率太大,也会阻碍收敛,导致损失函数值在最小值附近波动甚至发散。
(2)算法参数的初始值选择。 初始值不同,获得的最小值也有可能不同,因此梯度下降求得的只是局部最小值;当然如果损失函数是凸函数则一定是最优解。由于有局部最优解的风险,需要多次用不同初始值运行算法,关键损失函数的最小值,选择损失函数最小化的初值。
(3)归一化。由于样本不同特征的取值范围不一样,可能导致迭代很慢,为了减少特征取值的影响,可以对特征数据归一化,也就是对于每个特征x,求出它的期望x和标准差std(x),然后转化为同一范围内的值。
-
-
优化器作用:

2、优化器
https://zhuanlan.zhihu.com/p/416979875
-
动量优化和自适应学习率
动量优化法(Momentum):根据训练次数调节梯度导数大小(学习率是固定的),一介动量。
自适应学习率优化算法:对每个训练参数设置不同的学习率,二介动量。Momentum 使用指数加权平均计算当前的梯度值、AdaGrad、RMSProp 使用自适应的学习率,Adam 结合了 Momentum、RMSProp 的优点,使用:移动加权平均的梯度和移动加权平均的学习率。使得能够自适应学习率的同时,也能够使用 Momentum 的优点。
-
动量优化法(Momentum)
动量优化法引入了物理之中的概念。动量 p=mv,当一个小球从山顶滚下,速度越来越快,动量越来越大,开始加速梯度下降,当跨越了山谷,滚到对面的坡上时,速度减小,动量减小。带动量的小球不仅可以加速梯度;还可以借着积累的动量,冲过小的山坡,以避免落入局部最优点。Momentum,梯度下降法容易被困在局部最小的沟壑处来回震荡,可能存在曲面的另一个方向有更小的值;有时候梯度下降法收敛速度还是很慢。动量法就是为了解决这两个问题提出的 -
自适应学习率优化算法
传统的优化算法要么将学习率设置为常数要么根据训练次数调节学习率。往往忽视了学习率其他变化的可能性。然而,学习率对模型的性能有着显著的影响,因此需要采取一些策略来想办法更新学习率,从而提高训练速度。
先来看一下使用统一的全局学习率的缺点可能出现的问题
对于某些参数,通过算法已经优化到了极小值附近,但是有的参数仍然有着很大的梯度。
如果学习率太小,则梯度很大的参数会有一个很慢的收敛速度; 如果学习率太大,则已经优化得差不多的参数可能会出现不稳定的情况。 解决方案:
对每个参与训练的参数设置不同的学习率,在整个学习过程中通过一些算法自动适应这些参数的学习率。 如果损失与某一指定参数的偏导的符号相同,那么学习率应该增加; 如果损失与该参数的偏导的符号不同,那么学习率应该减小。
自适应学习率算法主要有:AdaGrad算法,RMSProp算法,Adam算法以及AdaDelta算法等
-
-
一阶动量和二阶动量
梯度的一阶矩(均值)和二阶矩(方差)的估计是通过指数加权平均计算的。
一阶矩估计(动量):梯度的指数加权平均。
二阶矩估计(方差):梯度平方的指数加权平均。
动量法:通过一阶动量(即梯度的指数加权平均)来加速收敛,尤其是在有噪声或梯度稀疏的情况下。
RMSProp:通过二阶动量(即梯度平方的指数加权平均)来调整学习率,使得每个参数的学习率适应其梯度的变化。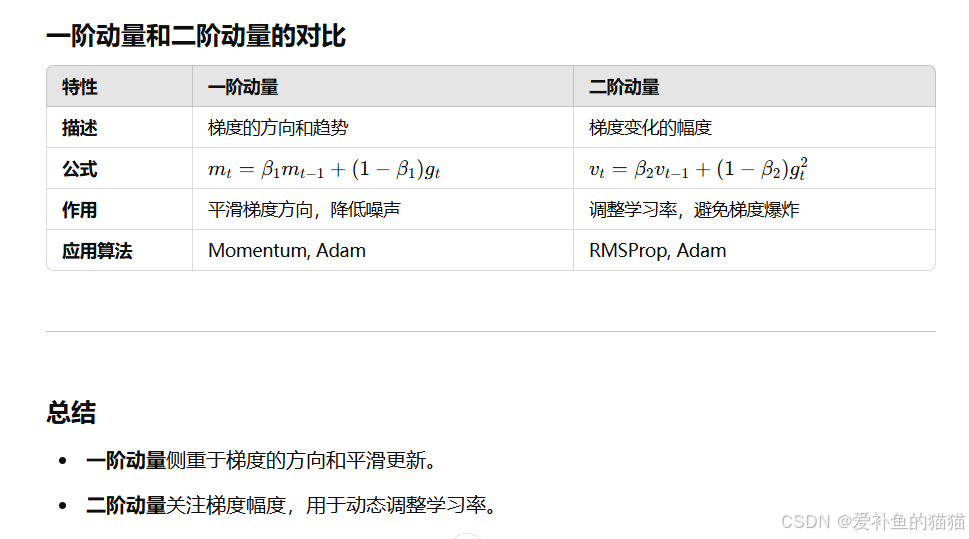

指数加权平均数(指数移动平均值)
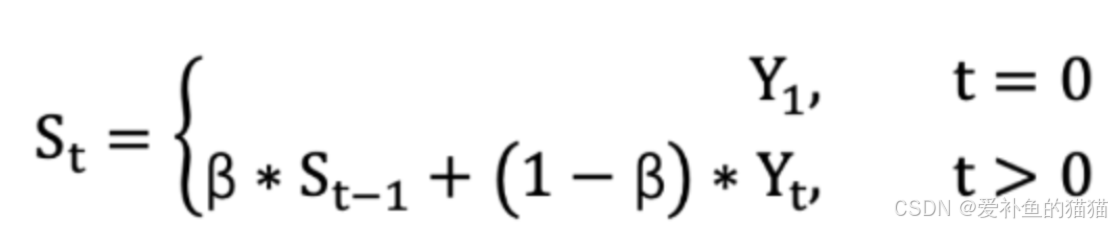

3、优化器相关公式算法
参考:https://zhuanlan.zhihu.com/p/416979875
梯度下降法 (Gradient Descent)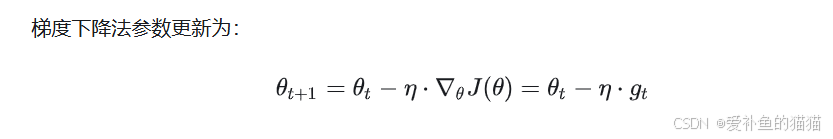
1)随机梯度下降(Stochastic Gradient Descent, SGD)一个样本

2)小批量梯度下降法(Mini-batch Gradient Descent, MBGD or SGD)部分样本

3)批量梯度下降法 (Batch Gradient Descent, BGD)全部样本

4)动量优化法(Momentum)
动量优化法引入了物理之中的概念。动量 p=mv,当一个小球从山顶滚下,速度越来越快,动量越来越大,开始加速梯度下降,当跨越了山谷,滚到对面的坡上时,速度减小,动量减小。带动量的小球不仅可以加速梯度;还可以借着积累的动量,冲过小的山坡,以避免落入局部最优点。
4.1Momentum
梯度下降法容易被困在局部最小的沟壑处来回震荡,可能存在曲面的另一个方向有更小的值;有时候梯度下降法收敛速度还是很慢。动量法就是为了解决这两个问题提出的
momentum算法思想:参数更新时在一定程度上保留之前更新的方向,同时又利用当前batch的梯度微调最终的更新方向,简言之就是通过积累之前的动量来 (previous_sum_of_gradient) 加速当前的梯度。
4.2NAG(Nesterov accelerated gradient)

Momentum和Nexterov都是为了使梯度更新更灵活。但是人工设计的学习率总是有些生硬,下面介绍几种自适应学习率的方法。
5)自适应学习率优化算法
传统的优化算法要么将学习率设置为常数要么根据训练次数调节学习率。往往忽视了学习率其他变化的可能性。然而,学习率对模型的性能有着显著的影响,因此需要采取一些策略来想办法更新学习率,从而提高训练速度。
- 先来看一下使用统一的全局学习率的缺点可能出现的问题:
对于某些参数,通过算法已经优化到了极小值附近,但是有的参数仍然有着很大的梯度。
如果学习率太小,则梯度很大的参数会有一个很慢的收敛速度; 如果学习率太大,则已经优化得差不多的参数可能会出现不稳定的情况。 解决方案:
对每个参与训练的参数设置不同的学习率,在整个学习过程中通过一些算法自动适应这些参数的学习率。 如果损失与某一指定参数的偏导的符号相同,那么学习率应该增加; 如果损失与该参数的偏导的符号不同,那么学习率应该减小。
自适应学习率算法主要有:AdaGrad算法,RMSProp算法,Adam算法以及AdaDelta算法等
5.1AdaGrad((Adaptive Gradient))


5.2Adadelta

5.3RMSprop
RMSProp(Root Mean Square Propagation)在时间步中,不是简单地累积所有梯度平方和,而是使用指数加权平均来逐步衰减过时的梯度信息。这种方法专门用于解决AdaGrad在训练过程中学习率过度衰减的问题。
RMSprop 和 Adadelta 都是为了解决 Adagrad 学习率急剧下降问题的,但是RMSProp算法修改了AdaGrad的梯度平方和累加为指数加权的移动平均,使得其在非凸设定下效果更好。
指数加权平均,旨在消除梯度下降中的摆动,与Momentum的效果一样,某一维度的导数比较大,则指数加权平均就大,某一维度的导数比较小,则其指数加权平均就小,这样就保证了各维度导数都在一个量级,进而减少了摆动。
另外,指数衰减平均的方式可以淡化遥远过去的历史对当前步骤参数更新量的影响,衰减率表明的是只是最近的梯度平方有意义,而很久以前的梯度基本上会被遗忘。
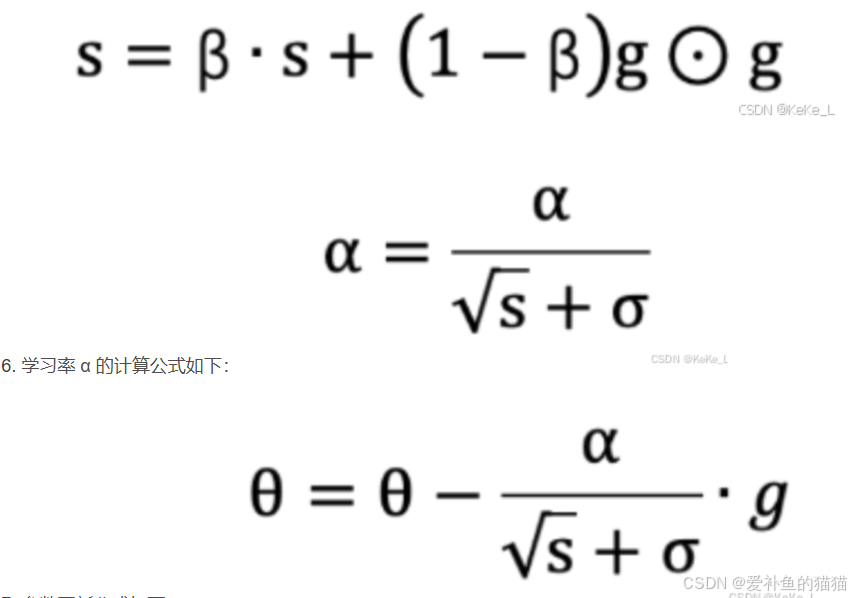

5.4Adam(Adaptive Moment Estimation)




5.5Nadam

5.6AdamW




有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 26
26 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)