【论文】nextvlad论文阅读笔记
nextvlad论文地址:netvlad
NextVLAD: 第二届Youtube-8M竞赛第三名,效果最优单模型,参数量<80M, GAP: 0.87。 NextVLAD尽管最终成绩是第三名,但是其最终模型只用了3个NeXtVLAD进行ensemble,单模型就能达到很好的效果,更适合应用到实际的项目中。
演变史:vlad、netvlad、nextvlad
vlad

netvlad
VLAD作为特征提取的一种方式,有效性得到证实。vlad的第二步聚类中心是通过k均值计算得到,netvlad希望通过网络训练得到聚类中心,由于vlad公式不可导,netvlad将vlad平滑为可导函数。

网络图中,虚线框内C代表 ,FC的softmax部分对应
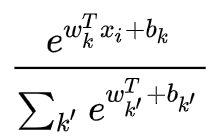 ,然后把这两部分相乘,即
,然后把这两部分相乘,即
nextVlad
netvlad虽然得到比较高的GAP,但是模型参数太多,nextvlad 参考resnext先分组再聚合的思想,在降低参数量的同时提高了GAP。
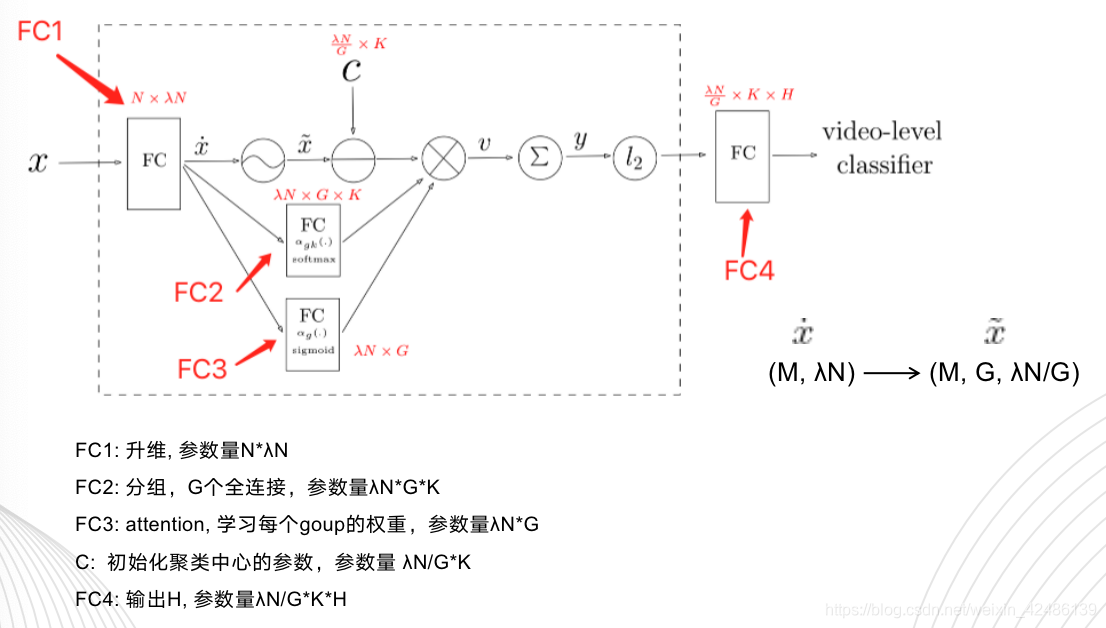
但是resnext相较于resnet并没有降低参数量,只是增加了更多的非线性,提高精度。nextvlad是如何做到降低参数量的?如下图,虚线框内是分组再聚合的过程,这个过程参数量并没有降低,真正对降低参数量做贡献的是框外的全连接层,由于分组,全连接的输入参数变为netvlad的倍(论文中
设定2,G设定为8, 参数量下降大约为netvlad的1/4,组数G越大,参数量越小。
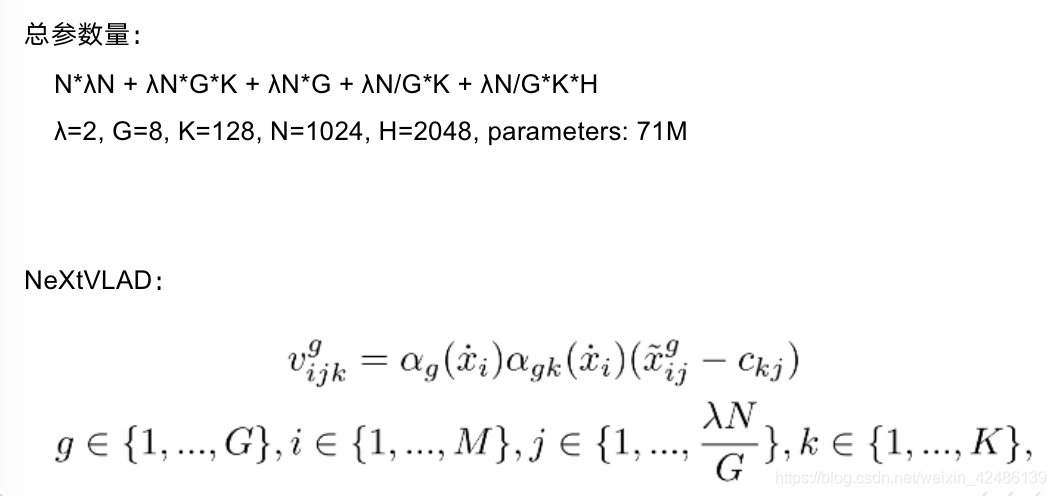
视频分类pipeline
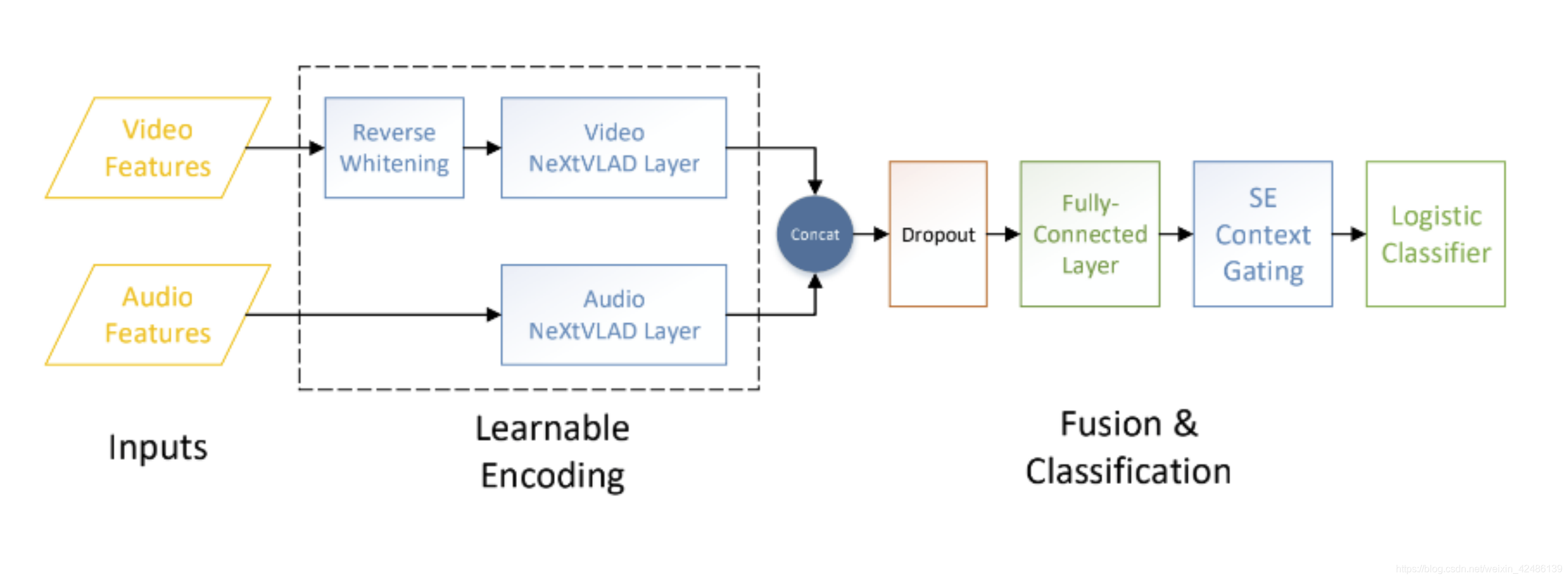
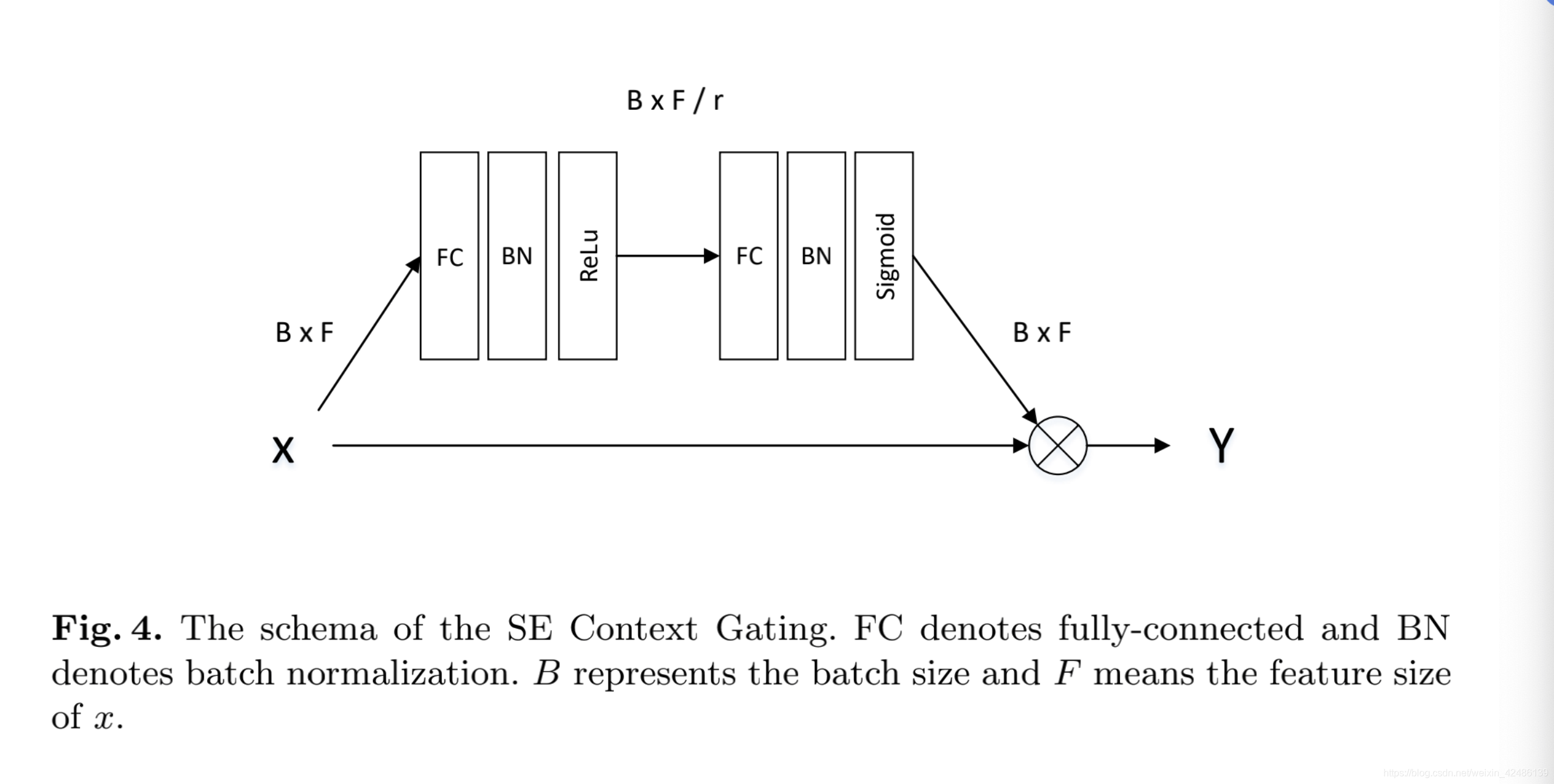
SE Context Gating
全连接输出的特征后接一层SE context gating,结构类似SE。SE context gating的输入即一维向量,免去了SE结构中的global average pooling。 SE CG得到一维方向上的权重,加权到原来的输出上,对输出特征做进一步校准。SE Context Gating代替netvlad中的Context Gating,进一步降低了参数量。
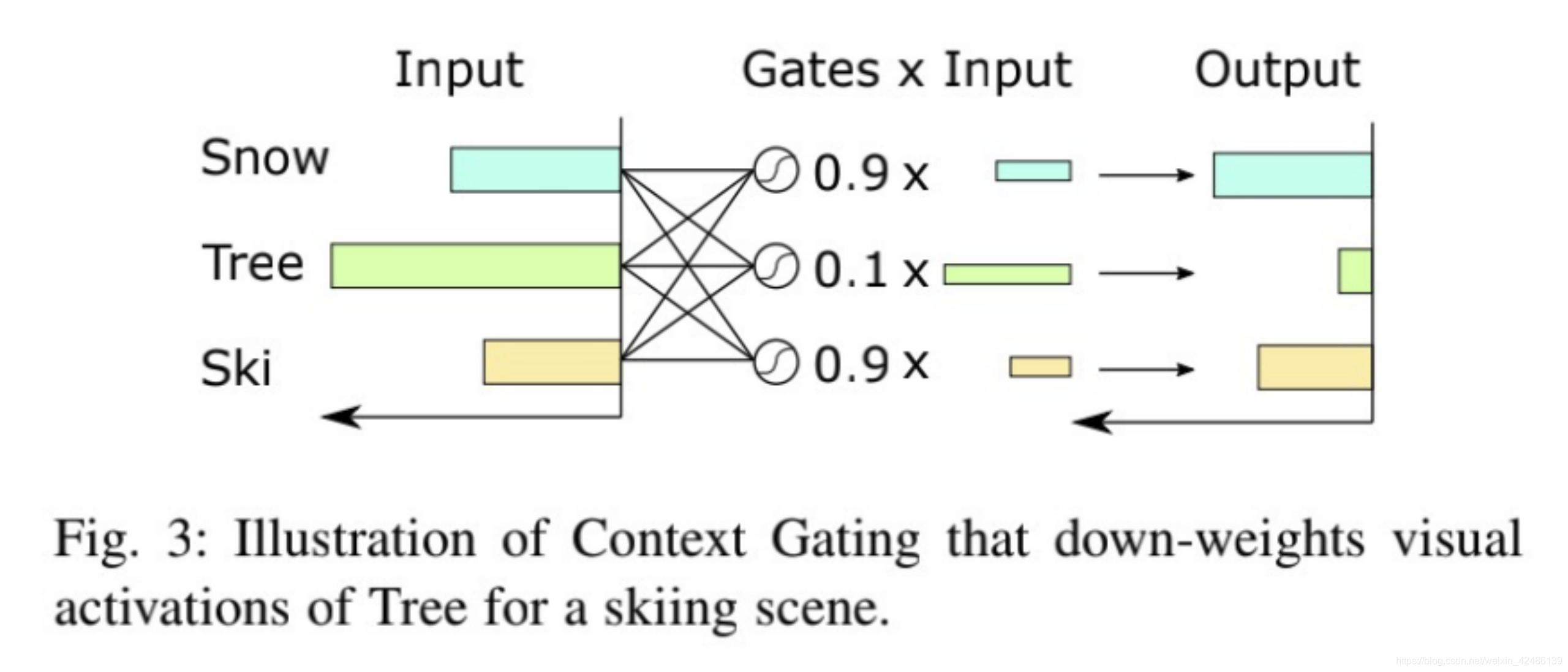
context gating论文中(Learnable pooling with context gating for video classification)举的例子比较贴切,比如滑雪场景,有树、雪、滑雪,树对判定为滑雪的贡献不大,CG可以抑制树的视觉激活。
netvlad论文:NetVLAD: CNN architecture for weakly supervised place recognition
nextvlad论文: NeXtVLAD: An Efficient Neural Network to Aggregate Frame-level Features for Large-scale Video Classification

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)