机器学习之--梯度下降算法
貌似机器学习最绕不过去的算法,是梯度下降算法。这里专门捋一下。1. 什么是梯度有知乎大神已经解释的很不错,这里转载并稍作修改,加上自己的看法。先给出链接,毕竟转载要说明出处嘛。为什么梯度反方向是函数值局部下降最快的方向?因为高等数学都忘光了,先从导数/偏倒数/方向导数,慢慢推出梯度吧。1.1 导数导数的几何意义可能很多人都比较熟悉: 当函数定义域和取值都在实数域中的时候,导...
貌似机器学习最绕不过去的算法,是梯度下降算法。这里专门捋一下。
1. 什么是梯度
有知乎大神已经解释的很不错,这里转载并稍作修改,加上自己的看法。先给出链接,毕竟转载要说明出处嘛。为什么梯度反方向是函数值局部下降最快的方向?
因为高等数学都忘光了,先从导数/偏倒数/方向导数,慢慢推出梯度吧。
1.1 导数
导数的几何意义可能很多人都比较熟悉: 当函数定义域和取值都在实数域中的时候,导数可以表示函数曲线上的切线斜率。 除了切线的斜率,导数还表示函数在该点的变化率。
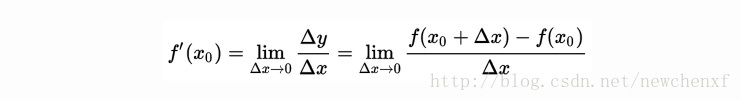
用图可表示为 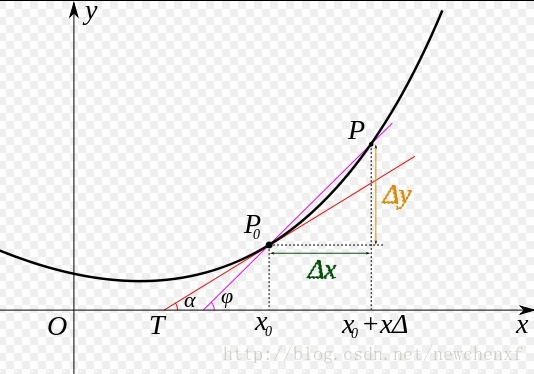
直白的来说,导数代表了在自变量变化趋于无穷小的时候,函数值的变化与自变量变化的比值代表了导数,几何意义有该点的切线。物理意义有该时刻的(瞬时)变化率…
注意在一元函数中,只有一个自变量变动,也就是说只存在一个方向的变化率,这也就是为什么一元函数没有偏导数的原因。
1.2 偏导数
既然谈到偏导数,那就至少涉及到两个自变量,以两个自变量为例,z=f(x,y) 。从导数到偏导数,也就是从曲线来到了曲面. 曲线上的一点,其切线只有一条。但是曲面的一点,切线有无数条。
而我们所说的偏导数就是指的是多元函数沿坐标轴的变化率:
fx(x,y) f x ( x , y ) <script type="math/tex" id="MathJax-Element-9265">f_{x} (x,y)</script>指的是函数在y方向不变,函数值沿着x轴方向的变化率
fy(x,y) f y ( x , y ) <script type="math/tex" id="MathJax-Element-9266">f_{y} (x,y)</script>指的是函数在x方向不变,函数值沿着y轴方向的变化率
对应的图像形象表达如下: 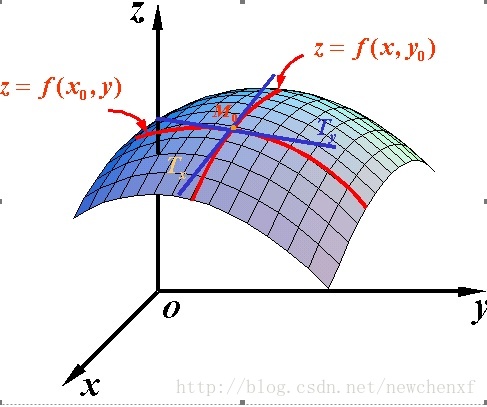
可能到这里,读者就已经发现偏导数的局限性了,原来我们学到的偏导数指的是多元函数沿坐标轴的变化率,但是我们往往很多时候要考虑多元函数沿任意方向的变化率,那么就引出了方向导数。
1.3 方向导数
假设你站在山坡上,想知道山坡的坡度(倾斜度)
山坡图如下: 
假设山坡表示为 z=f(x,y) z = f ( x , y ) <script type="math/tex" id="MathJax-Element-10507">z=f(x,y)</script>,你应该已经会做主要俩个方向的斜率:
y方向的斜率可以对y偏微分得到。同样的,x方向的斜率也可以对x偏微分得到。
那么我们可以使用这俩个偏微分来求出任何方向的斜率(类似于一个平面的所有向量可以用俩个基向量来表示一样)
现在我们有这个需求,想求出u方向的斜率怎么办?假设 z=f(x,y) z = f ( x , y ) <script type="math/tex" id="MathJax-Element-10508">z=f(x,y)</script>为一个曲面, p(x0,y0) p ( x 0 , y 0 ) <script type="math/tex" id="MathJax-Element-10509">p(x_{0} ,y_{0} )</script>为函数定义域中一个点,单位向量可表示为 u=cosθi+sinθj u = c o s θ i + s i n θ j <script type="math/tex" id="MathJax-Element-10510">u =cos\theta i+sin\theta j</script>,其中 θ θ <script type="math/tex" id="MathJax-Element-10511">\theta </script>是此向量与x轴正向夹角.单位向量u可以表示对任何方向导数的方向.如下图:
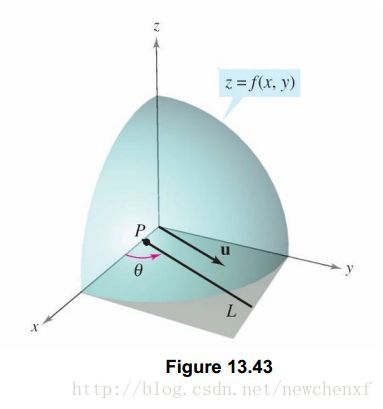
那么我们来考虑如何求出,曲面沿着 u u <script type="math/tex" id="MathJax-Element-10512">u</script> 方向的斜率,可以类比于前面导数定义,得出如下:
设 <script type="math/tex" id="MathJax-Element-10513">f(x,y)</script>为一个二元函数, u=cosθi+sinθj u = c o s θ i + s i n θ j <script type="math/tex" id="MathJax-Element-10514">u =cos\theta i+sin\theta j</script>为一个单位向量,如果下列的极限值存在
limt→0f(x0+tcosθ,y0+tsinθ)−f(x0,y0)t lim t → 0 f ( x 0 + t c o s θ , y 0 + t s i n θ ) − f ( x 0 , y 0 ) t <script type="math/tex" id="MathJax-Element-10515">\lim_{t \rightarrow 0}{\frac{f(x_{0}+tcos\theta ,y_{0}+tsin\theta )-f(x_{0},y_{0})}{t} } </script>
此方向导数记为 Duf D u f <script type="math/tex" id="MathJax-Element-10516">D_{u}f</script>
则称这个极限值是 f f <script type="math/tex" id="MathJax-Element-10517">f</script>沿着 <script type="math/tex" id="MathJax-Element-10518">u</script>方向的方向导数,那么随着 θ θ <script type="math/tex" id="MathJax-Element-10519">\theta</script> 的不同,我们可以求出任意方向的方向导数。这也表明了方向导数的用处,是为了给我们考虑函数对任意方向的变化率.
在求方向导数的时候,除了用上面的定义法求之外,我们还可以用偏微分来简化我们的计算.
表达式是:
Duf(x,y)=fx(x,y)cosθ+fy(x,y)sinθ D u f ( x , y ) = f x ( x , y ) c o s θ + f y ( x , y ) s i n θ <script type="math/tex" id="MathJax-Element-10520">D_{u}f(x,y)=f_{x}(x,y)cos\theta +f_{y}(x,y)sin\theta </script>
(至于为什么成立,很多资料有,不是这里讨论的重点,其实很好理解, θ θ <script type="math/tex" id="MathJax-Element-10521">\theta</script>为0,就是x轴方向,偏导数不就是 fx(x,y) f x ( x , y ) <script type="math/tex" id="MathJax-Element-10522">f_{x}(x,y)</script> 嘛)
那么一个平面上无数个方向,函数沿哪个方向变化率最大呢?
目前我不管梯度的事,我先把表达式写出来:
Duf(x,y)=fx(x,y)cosθ+fy(x,y)sinθ D u f ( x , y ) = f x ( x , y ) c o s θ + f y ( x , y ) s i n θ <script type="math/tex" id="MathJax-Element-10523">D_{u}f(x,y)=f_{x}(x,y)cos\theta +f_{y}(x,y)sin\theta </script>
设有这样两个向量: A=(fx(x,y),fy(x,y)),I=(cosθ,sinθ) A = ( f x ( x , y ) , f y ( x , y ) ) , I = ( c o s θ , s i n θ ) <script type="math/tex" id="MathJax-Element-10524">A=(f_{x}(x,y) ,f_{y}(x,y)),I=(cos\theta ,sin\theta )</script>
那么我们可以得到:
Duf(x,y)=A∙I=|A|∗|I|cosα D u f ( x , y ) = A ∙ I = | A | ∗ | I | c o s α <script type="math/tex" id="MathJax-Element-10525">D_{u}f(x,y)=A\bullet I=\left| A \right| *\left| I \right| cos\alpha </script> (向量的点乘的基本公式。 α α <script type="math/tex" id="MathJax-Element-10526">\alpha</script> 为向量A与向量I之间的夹角)
那么此时如果 Duf(x,y) D u f ( x , y ) <script type="math/tex" id="MathJax-Element-10527">D_{u}f(x,y)</script>要取得最大值,也就是当 α α <script type="math/tex" id="MathJax-Element-10528">\alpha </script>为0度的时候,也就是向量 I I <script type="math/tex" id="MathJax-Element-10529">I</script>(这个方向是一直在变,在寻找一个函数变化最快的方向)与向量 <script type="math/tex" id="MathJax-Element-10530">A</script>(这个方向当点固定下来的时候,它就是固定的)平行的时候,方向导数最大。方向导数最大,也就是单位步伐,函数值朝这个反向变化最快。
好了,现在我们已经找到函数值变化最快的方向了,这个方向就是和 A A <script type="math/tex" id="MathJax-Element-10531">A</script>向量相同的方向。那么此时我把 <script type="math/tex" id="MathJax-Element-10532">A</script>向量命名为梯度(当一个点确定后,梯度方向是确定的),也就是说明了为什么梯度方向是函数变化率最大的方向了!!!(因为本来就是把这个函数变化最大的方向命名为梯度)
1.4 梯度
由上面,总结一下梯度的结论。
梯度是一个向量,表示某一函数在该点处的方向导数沿着该方向(向量)取得最大值。(导数是一个值)
梯度所指的方向就是函数增长最快的方向(负梯度则指向函数下降最快的方向)。
假设二元函数在平面区域D上具有一阶连续偏导数,则对于每一个点 P(x,y) P ( x , y ) <script type="math/tex" id="MathJax-Element-10608">P(x,y)</script>都可定义:
向量 A=(fx(x,y),fy(x,y)) A = ( f x ( x , y ) , f y ( x , y ) ) <script type="math/tex" id="MathJax-Element-10609">A=(f_{x}(x,y) ,f_{y}(x,y))</script>,该向量就称为函数在点 P(x,y) P ( x , y ) <script type="math/tex" id="MathJax-Element-10610">P(x,y)</script>的梯度。
函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)。
2. 梯度下降算法
这里就从一个不成熟但能用的例子开始讲。
假设有一堆根据衣着判定男女的数据(training set),( x1,x2 x 1 , x 2 <script type="math/tex" id="MathJax-Element-16891">x_{1}, x_{2}</script>)代鞋码和裤头码的数据, x1 x 1 <script type="math/tex" id="MathJax-Element-16892">x_1</script>是鞋码, x2 x 2 <script type="math/tex" id="MathJax-Element-16893">x_2</script>是裤头码,y是类标号,y=1表示这条数据是男生,y=-1表示这条数据是女生。我们希望能学习出一个函数 f(x) f ( x ) <script type="math/tex" id="MathJax-Element-16894">f(x)</script>,使得 f(x) f ( x ) <script type="math/tex" id="MathJax-Element-16895">f(x)</script>能够尽可能准确地描述这些数据,如果能求出这个 f(x) f ( x ) <script type="math/tex" id="MathJax-Element-16896">f(x)</script>,那么任给一组数据,就能预测出这人是男生还是女生。
那么 f(x) f ( x ) <script type="math/tex" id="MathJax-Element-16897">f(x)</script>长什么样?它的形式需要我们来指定,算法只帮我们训练出其中的参数。为了方便讲解,我设 f(x) f ( x ) <script type="math/tex" id="MathJax-Element-16898">f(x)</script>为下面的形式,也就是一个线性的函数(一般来说,非线性的要比线性的函数的拟合能力要强,这里暂不讨论线性与非线性的问题):
f(x)=θ1x1+θ2x2+θ3 f ( x ) = θ 1 x 1 + θ 2 x 2 + θ 3 <script type="math/tex" id="MathJax-Element-16899"> f(x)=\theta_{1} x_{1} + \theta_{2} x_{2} + \theta_{3} </script>
我们希望 f(x) f ( x ) <script type="math/tex" id="MathJax-Element-16900">f(x)</script>能够尽可能准确地描述training set中的样本,但毕竟是猜的,不可能百分百准确,肯定或多或少会有误差。于是对于一个training set,总的误差函数(也称为损失函数)(cost function)可以定义如下:
L(θ)=12∑ni=1[f(Xi)−Yi]2 L ( θ ) = 1 2 ∑ i = 1 n [ f ( X i ) − Y i ] 2 <script type="math/tex" id="MathJax-Element-16901">L(\theta) = \frac{1}{2} \sum_{i=1}^n [f(X_{i}) - Y_{i}]^2</script>
其中 Xi=(x1,x2) X i = ( x 1 , x 2 ) <script type="math/tex" id="MathJax-Element-16902">X_i = (x_1, x_2)</script>表示第 i 个样本, Yi Y i <script type="math/tex" id="MathJax-Element-16903">Y_i</script>表示第 i 个样本对应的类标号(值为1或-1)。
现在的目标是,找到最优参数 (θ1,θ2,θ3) ( θ 1 , θ 2 , θ 3 ) <script type="math/tex" id="MathJax-Element-16904">(\theta_1, \theta_2, \theta_3)</script>,使得函数 L(θ) L ( θ ) <script type="math/tex" id="MathJax-Element-16905">L(\theta) </script> 取得最小值。因为损失最小,代表模拟出的函数 f(x) f ( x ) <script type="math/tex" id="MathJax-Element-16906">f(x)</script> 越准确。
回忆上文的结论:
梯度所指的方向就是函数增长最快的方向(负梯度则指向函数下降最快的方向)。
我们先随机取一个参数值 (θ1,θ2,θ3) ( θ 1 , θ 2 , θ 3 ) <script type="math/tex" id="MathJax-Element-16907">(\theta_1, \theta_2, \theta_3)</script>,然后沿着负梯度的方向调整参数(注意在cost function中,自变量是参数,而不是X,X是已知的样本数据),就可以使我们的损失函数下降得最快,直到无法再降,就是最小值,那时候的参数,就是我们要的参数。
既然是调整参数,那肯定要对他们求导了。
参数 (θ1,θ2,θ3) ( θ 1 , θ 2 , θ 3 ) <script type="math/tex" id="MathJax-Element-16908">(\theta_1, \theta_2, \theta_3)</script>的偏导数:
∂L∂θ1=∑ni=1xi1(f(Xi)−Yi) ∂ L ∂ θ 1 = ∑ i = 1 n x 1 i ( f ( X i ) − Y i ) <script type="math/tex" id="MathJax-Element-16909">\frac{\partial L}{\partial \theta_1} = \sum_{i=1}^n x_1^i (f(X^{i}) - Y^{i})</script>
∂L∂θ2=∑ni=1xi2(f(Xi)−Yi) ∂ L ∂ θ 2 = ∑ i = 1 n x 2 i ( f ( X i ) − Y i ) <script type="math/tex" id="MathJax-Element-16910">\frac{\partial L}{\partial \theta_2} = \sum_{i=1}^n x_2^i (f(X^{i}) - Y^{i})</script>
∂L∂θ3=∑ni=1xi3(f(Xi)−Yi) ∂ L ∂ θ 3 = ∑ i = 1 n x 3 i ( f ( X i ) − Y i ) <script type="math/tex" id="MathJax-Element-16911">\frac{\partial L}{\partial \theta_3} = \sum_{i=1}^n x_3^i (f(X^{i}) - Y^{i})</script>
可能直接看到这个有点懵逼,没事,推导一下。
L(θ)=12∑ni=1[f(Xi)−Yi]2 L ( θ ) = 1 2 ∑ i = 1 n [ f ( X i ) − Y i ] 2 <script type="math/tex" id="MathJax-Element-16912">L(\theta) = \frac{1}{2} \sum_{i=1}^n [f(X_{i}) - Y_{i}]^2</script>
=12∑ni=1[(θ1x1+θ2x2+θ3)−Yi]2 = 1 2 ∑ i = 1 n [ ( θ 1 x 1 + θ 2 x 2 + θ 3 ) − Y i ] 2 <script type="math/tex" id="MathJax-Element-16913">=\frac{1}{2} \sum_{i=1}^n [(\theta_1 x_1 + \theta_2 x_2 + \theta_3) - Y_{i}]^2</script>
既然是对 θ1 θ 1 <script type="math/tex" id="MathJax-Element-16914">\theta_1</script>求偏导,那其他值就相当于常数。且假设 T=θ2x2+θ3−Yi T = θ 2 x 2 + θ 3 − Y i <script type="math/tex" id="MathJax-Element-16915">T = \theta_2 x_2 + \theta_3 - Y_{i}</script>是一个常数。
L(θ)=12∑ni=1[θ1x1+T]2 L ( θ ) = 1 2 ∑ i = 1 n [ θ 1 x 1 + T ] 2 <script type="math/tex" id="MathJax-Element-16916">L(\theta) = \frac{1}{2} \sum_{i=1}^n [\theta_1 x_1 +T]^2 </script>
=12∑ni=1(θ1)2(x1)2+2(θ1)(x1)T+T2 = 1 2 ∑ i = 1 n ( θ 1 ) 2 ( x 1 ) 2 + 2 ( θ 1 ) ( x 1 ) T + T 2 <script type="math/tex" id="MathJax-Element-16917">= \frac{1}{2} \sum_{i=1}^n (\theta_1)^2 (x_1)^2 + 2 (\theta_1) (x_1) T + T^2 </script>
对 θ1 θ 1 <script type="math/tex" id="MathJax-Element-16918">\theta_1</script>求偏导
∂L∂θ1=12∑ni=1[2(θ1)(x1)2+2(x1)T] ∂ L ∂ θ 1 = 1 2 ∑ i = 1 n [ 2 ( θ 1 ) ( x 1 ) 2 + 2 ( x 1 ) T ] <script type="math/tex" id="MathJax-Element-16919">\frac{\partial L}{\partial \theta_1} = \frac{1}{2} \sum_{i=1}^n [2 (\theta_1) (x_1)^2 + 2 (x_1)T]</script>
=∑ni=1(x1)[θ1x1+T] = ∑ i = 1 n ( x 1 ) [ θ 1 x 1 + T ] <script type="math/tex" id="MathJax-Element-16920">= \sum_{i=1}^n (x_1)[\theta_1 x_1 + T]</script>
因为 f(Xi)−Yi=θ1x1+T f ( X i ) − Y i = θ 1 x 1 + T <script type="math/tex" id="MathJax-Element-16921">f(X_{i}) - Y_{i} = \theta_1 x_1 + T</script>
故而
∂L∂θ1=∑ni=1x1(f(Xi)−Yi) ∂ L ∂ θ 1 = ∑ i = 1 n x 1 ( f ( X i ) − Y i ) <script type="math/tex" id="MathJax-Element-16922">\frac{\partial L}{\partial \theta_1} = \sum_{i=1}^n x_1 (f(X^{i}) - Y^{i})</script>
有严格来说, x1 x 1 <script type="math/tex" id="MathJax-Element-16923">x_1</script>是样本数据,根据 i 变化,所以加个上标比较准确。于是公式如下:
∂L∂θ1=∑ni=1xi1(f(Xi)−Yi) ∂ L ∂ θ 1 = ∑ i = 1 n x 1 i ( f ( X i ) − Y i ) <script type="math/tex" id="MathJax-Element-16924">\frac{\partial L}{\partial \theta_1} = \sum_{i=1}^n x_1^i (f(X^{i}) - Y^{i})</script>
好了,偏导都知道怎么求了,如上文所说,我们先随机取一组参数值,接下来让参数沿着负梯度方向走,也就是每个分量沿着对应的梯度反方向的分量走,因此参数在每次迭代的更新规则如下:
θ1new=θ1−η⋅∂L∂θ1 θ 1 n e w = θ 1 − η ⋅ ∂ L ∂ θ 1 <script type="math/tex" id="MathJax-Element-16925">\theta_{1 new} = \theta_1 - \eta \centerdot \frac{\partial L}{\partial \theta_1}</script>
θ2new=θ2−η⋅∂L∂θ2 θ 2 n e w = θ 2 − η ⋅ ∂ L ∂ θ 2 <script type="math/tex" id="MathJax-Element-16926">\theta_{2 new} = \theta_2 - \eta \centerdot \frac{\partial L}{\partial \theta_2}</script>
θ3new=θ3−η⋅∂L∂θ3 θ 3 n e w = θ 3 − η ⋅ ∂ L ∂ θ 3 <script type="math/tex" id="MathJax-Element-16927">\theta_{3 new} = \theta_3 - \eta \centerdot \frac{\partial L}{\partial \theta_3}</script>
η η <script type="math/tex" id="MathJax-Element-16928">\eta</script>是学习率,一般取值为0到1之间,它可以控制参数每步调整的大小,太大的话,有可能走到临近极佳点时,下一步就跨过去了,这样就不收敛了,走得太慢的话,会迭代很多次才收敛。
ps: 网上总是说,大部分人做机器学习,都是调参工程师,说的一个参,就是这个 η η <script type="math/tex" id="MathJax-Element-16929">\eta</script>,哈哈^^
anyway,经过多次迭代之后,我们就得到了的 (θ1,θ2,θ3) ( θ 1 , θ 2 , θ 3 ) <script type="math/tex" id="MathJax-Element-16930">(\theta_1, \theta_2, \theta_3)</script>最优值,也就是在这些个参数下, f(x) f ( x ) <script type="math/tex" id="MathJax-Element-16931">f(x)</script>对于training set的样本的识别误差最小。这样,我们就训练出了函数 f(x) f ( x ) <script type="math/tex" id="MathJax-Element-16932">f(x)</script>(机器学习领域,可称这个函数为模型),以后随意输入一组样本 (x1,x2) ( x 1 , x 2 ) <script type="math/tex" id="MathJax-Element-16933">(x_1,x_2)</script>, 我们都可以直接输出结果。
参考

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)