RSDet:学习用于旋转目标检测损失
RSDet:学习用于旋转目标检测损失
目录
📝论文下载地址
👨🎓论文作者
📦模型讲解
[背景介绍]
根据目标框的方向,目标检测通常可以分为水平检测和旋转检测。具体来说,水平边界框检测通常更适合于一般自然场景图像,例如COCO和Pascal VOC。在场景文本,遥感图像,面部检测和车牌检测中,通常需要更精确的定位,并且需要有效的旋转目标检测模型。现有的基于区域的旋转目标检测通常会回归五个参数(中心点的坐标,宽度,高度,旋转角度)描述旋转边界框,并使用L1作为损失函数。但是,这种方法在实践中存在两个基本问题:
角度参数引起损失不连续性
举个例子,某次运行的情况如下表。预选框是一步网络中预先生成的anchors,或者是二步网络生成的proposal。网络预测的偏移量为 [ 0 , 0 , 0 , 0 , 1 ° ] [0,0,0,0,1°] [0,0,0,0,1°],将预选框转为预测框。网络训练的目标是 [ 0 , 0 , 50 , − 50 , 89 ° ] [0,0,50,-50,89°] [0,0,50,−50,89°],目标与网络预测的偏移量很多,所以损失会很大,但是网络输出的结果与真实结果是差不多的(只差2°)。这就是角度的周期性导致的损失不连续。
| 框 | x_center | y_center | w | h | θ \theta θ |
|---|---|---|---|---|---|
| 预选框/蓝色 | 0 | 0 | 50 | 100 | -90° |
| 真实框/红色 | 0 | 0 | 100 | 50 | -1° |
| 预测框/绿色 | 0 | 0 | 50 | 100 | -89° |
参数单位不同影响网络性能 在五参数系统中,角度,宽度,高度和中心点坐标具有不同的测量单位,并且它们与IoU显示出相当不同的关系,如下图所示。简单地将它们加起来会导致不一致的回归性能。八参数可以使用相同单位的角点坐标来缓解此问题。
| 回归模型 | 损失不连续问题 | 回归不一致问题 |
|---|---|---|
| 五参数回归 | ✅ | ✅ |
| 八参数回归 | ❌ | ✅ |
✅表示存在❌表示不存在。
[模型解读]
[旋转框参数化]
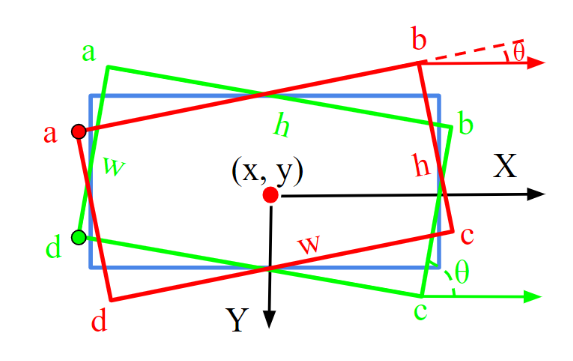
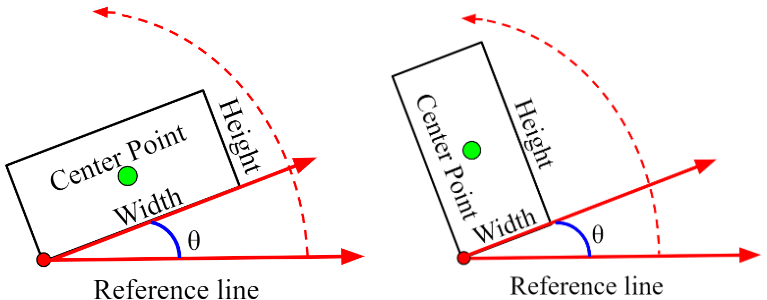
作者的五参数定义与OpenCV中的定义一致,如下图所示:
①沿水平方向定义参考线,该垂直线位于具有最小垂直坐标的顶点处。
②旋转参考线逆时针方向,与参考线接触的第一个矩形边的宽度被定义为宽 w w w,而与另一边为高 h h h。
③中心点坐标为 ( x , y ) (x,y) (x,y),旋转角度为 θ \theta θ。
八个参数的定义更为简单:旋转边界框的四个顺时针顶点 ( a , b , c , d ) (a,b,c,d) (a,b,c,d)用于描述其位置。八参数回归方法具有参数一致性,这种方法可以描述任意四边形,可以在更复杂的应用场景中使用。
[旋转灵敏度误差]
如前所述,旋转灵敏度误差主要是由两个原因引起的:
①角度参数的采用以及由此引起的高度-宽度交换(在OpenCV中流行的五参数描述中)导致突然的损耗变化(增加)在边界情况下。
②五参数模型中存在度量单位的回归不一致。
[损失不连续性]
如上图所示,在五参数回归方法中,假设真实框为绿色信息为 [ 0 , 0 , 25 , 100 , − 10 ° ] [0,0,25,100,-10°] [0,0,25,100,−10°],预选框为蓝色信息为 [ 0 , 0 , 100 , 25 , − 90 ° ] [0,0,100,25,-90°] [0,0,100,25,−90°],经过网络的回归后对预选框进行逆时针旋转生成的预测框为红色 [ 0 , 0 , 100 , 25 , − 100 ° ] [0,0,100,25,-100°] [0,0,100,25,−100°],但是这个角度并不在范围之内,虽然这个过程在物理上是连续的,但是对于损失计算将会很大。对于网络来说,网络会学习讲将预选框进行顺时针旋转,也就是灰色的过程,这是一个相对于逆时针变化更复杂的回归,增加了训练难度。
[回归不一致]
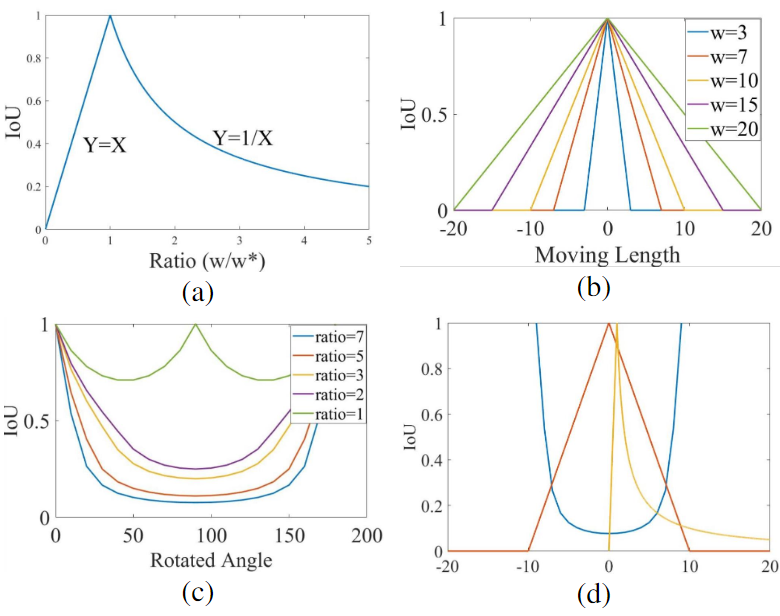
五参数的不同测量单位会使回归不一致。下图中研究了所有参数与IoU之间的关系。IoU和宽度(高度)之间的关系是线性函数和反比例函数的组合。中心点与IoU之间的关系是对称的线性函数,如b所示。角度参数和IoU之间的关系是一个多项式函数。这种回归不一致很可能使训练收敛性和检测性能恶化。
[五参数旋转损失]
损耗不连续仅在边界情况下发生,如下图a所示。
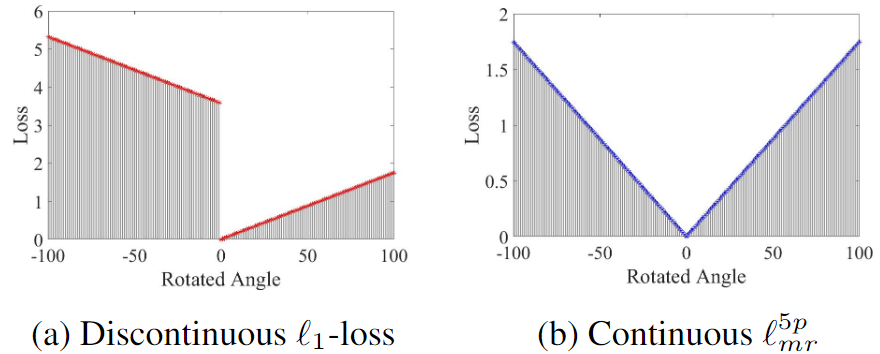
在本文中,作者设计了以下边界约束损失,以旋转损失 l m r l_{mr} lmr表示:
l c p = ∣ x 1 − x 2 ∣ + ∣ y 1 − y 2 ∣ l m r 5 p = min { l c p + ∣ w 1 − w 2 ∣ + ∣ h 1 − h 2 ∣ + ∣ θ 1 − θ 2 ∣ , l c p + ∣ w 1 − h 2 ∣ + ∣ h 1 − w 2 ∣ + ∣ 90 − ∣ θ 1 − θ 2 ∣ ∣ } l_{cp}=|x_1-x_2|+|y_1-y_2|\\l_{mr}^{5p}=\min \{l_{cp}+|w_1-w_2|+|h_1-h_2|+|\theta_1-\theta_2|,\\l_{cp}+|w_1-h_2|+|h_1-w_2|+|90-|\theta_1-\theta_2||\} lcp=∣x1−x2∣+∣y1−y2∣lmr5p=min{lcp+∣w1−w2∣+∣h1−h2∣+∣θ1−θ2∣,lcp+∣w1−h2∣+∣h1−w2∣+∣90−∣θ1−θ2∣∣}
l c p l_{cp} lcp是中心点损失。 l m r l_{mr} lmr的第一项是L1损失。第二项是通过消除角度周期性以及高度和宽度的交换性校正损失使其连续。当其未达到角度参数的范围边界时,该校正项大于L1损失。当L1损失突然发生不连续时,这种校正变得正常。换句话说,这种校正可以看作是对突变位置的L1-损失进行对称。最后,损失为最小的L1-损失和校正损失。 l m r l_{mr} lmr曲线是连续的,如上图b所示。
实际上,通常使用预测框回归的相对值来避免由不同比例尺上的对象引起的误差。
∇ l c p = ∣ t x 1 − t x 2 ∣ + ∣ t y 1 − t y 2 ∣ l m r 5 p = min { ∣ t w 1 − t w 2 ∣ + ∣ t h 1 − t h 2 ∣ + ∣ t θ 1 − t θ 2 ∣ + ∇ l c p ∣ t w 1 − t h 2 − log ( r ) ∣ + ∣ t h 1 − t w 2 + l o g ( r ) ∣ + ∣ ∣ t θ 1 − t θ 2 ∣ − π 2 ∣ + ∇ l c p } \nabla l_{cp}=|t_{x1}-t_{x2}|+|t_{y1}-t_{y2}|\\l_{mr}^{5p}=\min\{|t_{w_1}-t_{w_2}|+|t_{h_1}-t_{h_2}|+|t_{\theta1}-t_{\theta2}|+\nabla l_{cp}\\|t_{w_1}-t_{h_2}-\log(r)|+|t_{h_1}-t_{w_2}+log(r)|+||t_{\theta1}-t_{\theta2}|-\frac{\pi}{2}|+\nabla l_{cp}\} ∇lcp=∣tx1−tx2∣+∣ty1−ty2∣lmr5p=min{∣tw1−tw2∣+∣th1−th2∣+∣tθ1−tθ2∣+∇lcp∣tw1−th2−log(r)∣+∣th1−tw2+log(r)∣+∣∣tθ1−tθ2∣−2π∣+∇lcp}其中, t x = ( x − x a ) / w a t y = ( y − y a ) / h a t w = log ( w / w a ) t h = log ( h / h a ) r = w h t θ = θ π 180 t_x=(x-x_a)/w_a\\t_y=(y-y_a)/h_a\\t_w=\log(w/w_a)\\t_h=\log(h/h_a)\\r=\frac{w}{h}\\t_\theta=\frac{\theta\pi}{180} tx=(x−xa)/waty=(y−ya)/hatw=log(w/wa)th=log(h/ha)r=hwtθ=180θπ其中角度参数的度量单位为弧度, r r r表示宽高比。 x x x和 x a x_a xa分别是预测框和预选框。
但是这里可能存在问题,通过未归一化的公式可以看出。第一种情况下 w 1 = w 2 w_1=w_2 w1=w2与 h 1 = h 2 h_1=h_2 h1=h2是最好的。第二种情况下 w 1 = h 2 w_1=h_2 w1=h2与 h 1 = w 2 h_1=w_2 h1=w2是最好的。在作者的公式中推导可以得出第一种情况: ∣ t w 1 − t w 2 ∣ + ∣ t h 1 − t h 2 ∣ = ∣ log w 1 − log w 2 ∣ + ∣ log h 1 − log h 2 ∣ |t_{w_1}-t_{w_2}|+|t_{h_1}-t_{h_2}|=|\log w_1-\log w_2|+|\log h_1-\log h_2| ∣tw1−tw2∣+∣th1−th2∣=∣logw1−logw2∣+∣logh1−logh2∣也就是 w 1 = h 2 w_1=h_2 w1=h2与 h 1 = w 2 h_1=w_2 h1=w2是没问题的,与未归一化公式的目的相同。但是第二种情况应该修改为以下:
r = w a h a l m r 5 p = min { ∣ t w 1 − t w 2 ∣ + ∣ t h 1 − t h 2 ∣ + ∣ t θ 1 − t θ 2 ∣ + ∇ l c p ∣ t w 1 − t h 2 + log ( r ) ∣ + ∣ t h 1 − t w 2 − l o g ( r ) ∣ + ∣ ∣ t θ 1 − t θ 2 ∣ − π 2 ∣ + ∇ l c p } r=\frac{w_a}{h_a}\\l_{mr}^{5p}=\min\{|t_{w_1}-t_{w_2}|+|t_{h_1}-t_{h_2}|+|t_{\theta1}-t_{\theta2}|+\nabla l_{cp}\\|t_{w_1}-t_{h_2}+\log(r)|+|t_{h_1}-t_{w_2}-log(r)|+||t_{\theta1}-t_{\theta2}|-\frac{\pi}{2}|+\nabla l_{cp}\} r=hawalmr5p=min{∣tw1−tw2∣+∣th1−th2∣+∣tθ1−tθ2∣+∇lcp∣tw1−th2+log(r)∣+∣th1−tw2−log(r)∣+∣∣tθ1−tθ2∣−2π∣+∇lcp}
∣ t w 1 − t h 2 + log ( r ) ∣ + ∣ t h 1 − t w 2 − log ( r ) ∣ = ∣ log w 1 − log h 2 ∣ + ∣ log h 1 − log w 2 ∣ |t_{w_1}-t_{h_2}+\log(r)|+|t_{h_1}-t_{w_2}-\log(r)|=|\log w_1-\log h_2|+|\log h_1-\log w_2| ∣tw1−th2+log(r)∣+∣th1−tw2−log(r)∣=∣logw1−logh2∣+∣logh1−logw2∣也就是在 w 1 = h 2 w_1=h_2 w1=h2与 h 1 = w 2 h_1=w_2 h1=w2最好。
[八参数旋转损失]
为了避免固有的回归不一致,最近八参数表示法比较流行。基于八参数回归的检测直接使对象的四个点回归,因此预测是四边形的。四边形回归的关键步骤是预先对四个角点进行排序。对于顶点顺序,作者采用基于叉积的算法来获得四个顶点的序列,算法如下所示。该算法仅适用于凸四边形,此处使用顺时针顺序进行输出。
向量叉积的特点就是: A B × A C > 0 AB\times AC>0 AB×AC>0时,AC在AB的逆时针方向上; A B × A C = 0 AB\times AC=0 AB×AC=0时,AC在AB同线; A B × A C < 0 AB\times AC<0 AB×AC<0时,AC在AB的顺时针方向上。当找到最左边的点时,只有相对的点才满足 C r o s s P r o d u c t ( s 1 − p 1 ′ , s 2 − p 1 ′ ) × C r o s s P r o d u c t ( s 1 − p 1 ′ , s 3 − p 1 ′ ) < 0 CrossProduct(s_1−p_1^\prime,s_2−p_1^\prime)×CrossProduct(s_1−p_1^\prime,s_3−p_1^\prime)<0 CrossProduct(s1−p1′,s2−p1′)×CrossProduct(s1−p1′,s3−p1′)<0,四边形的对角线两边的边一定与对角线是一个顺时针一个逆时针。

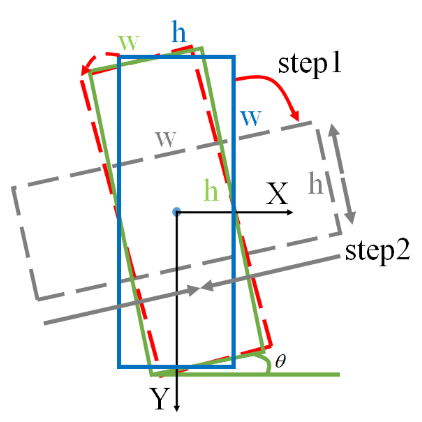
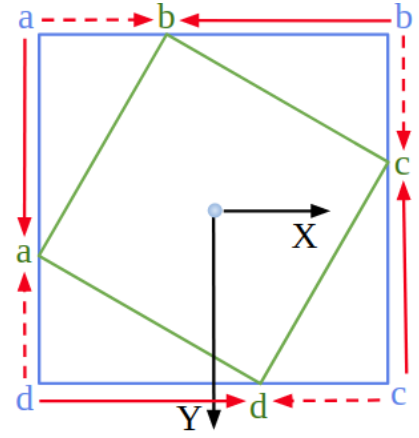
但是,损失不连续性在八参数回归模型中仍然存在。例如,假设用四个点顺序 a → b → c → d a\rightarrow b\rightarrow c\rightarrow d a→b→c→d(参见下图中的红色框)来描述一个真实框。当真实框稍微顺时针旋转一个小角度时,四点顺序变为 d → a → b → c d\rightarrow a\rightarrow b\rightarrow c d→a→b→c(请参见下图中的绿色框)。
如下图所示,从蓝色预选框到实际位置的回归过程。绿色真实框为 { ( a → a ) , ( b → b ) , ( c → c ) , ( d → d ) } \{(a\rightarrow a),(b\rightarrow b),(c\rightarrow c),(d\rightarrow d)\} {(a→a),(b→b),(c→c),(d→d)},但显然理想的回归过程应为 { ( a → b ) , ( b → c ) , ( c → d ) , ( d → a ) } \{(a\rightarrow b),(b\rightarrow c),(c\rightarrow d),(d\rightarrow a)\} {(a→b),(b→c),(c→d),(d→a)}。这种情况也导致模型训练困难和回归不平滑。
作者设计了旋转损失的八参数版本,由三个部分组成:
①将预选框的四个顶点顺时针移动一个位置;
②保持预选框顶点的顺序不变;
③将预选框的四个顶点逆时针移动一个位置;
④在上述三种情况下取最小值。因此, l m r 8 p l_{mr}^{8p} lmr8p表示为: ℓ m r 8 p = min { ∑ i = 0 3 ( ∣ x ( i + 3 ) % 4 − x i ∗ ∣ + ∣ y ( i + 3 ) % 4 − y i ∗ ∣ ) ∑ i = 0 3 ( ∣ x i − x i ∗ ∣ + ∣ y i − y i ∗ ∣ ) ∑ i = 0 3 ( ∣ x ( i + 1 ) % − x i ∗ ∣ + ∣ y ( i + 1 ) % 4 − y i ∗ ∣ ) \begin{array}{l} \qquad \ell_{m r}^{8 p}=\min \left\{\begin{array}{l}\sum_{i=0}^{3}\left(\left|x_{(i+3) \% 4}-x_{i}^{*}\right|+\left|y_{(i+3) \% 4}-y_{i}^{*}\right|\right) \\\sum_{i=0}^{3}\left(\left|x_{i}-x_{i}^{*}\right|+\left|y_{i}-y_{i}^{*}\right|\right) \\ \sum_{i=0}^{3}\left(\left|x_{(i+1) \%}-x_{i}^{*}\right|+\left|y_{(i+1) \% 4}-y_{i}^{*}\right|\right)\end{array}\right.\end{array} ℓmr8p=min⎩⎨⎧∑i=03(∣∣x(i+3)%4−xi∗∣∣+∣∣y(i+3)%4−yi∗∣∣)∑i=03(∣xi−xi∗∣+∣yi−yi∗∣)∑i=03(∣∣x(i+1)%−xi∗∣∣+∣∣y(i+1)%4−yi∗∣∣)
其中 x i x_i xi和 y i y_i yi分别表示预选框的第 i i i个顶点和参考框的第 i i i个顶点之间的坐标偏移。
[结果分析]
[数据集]
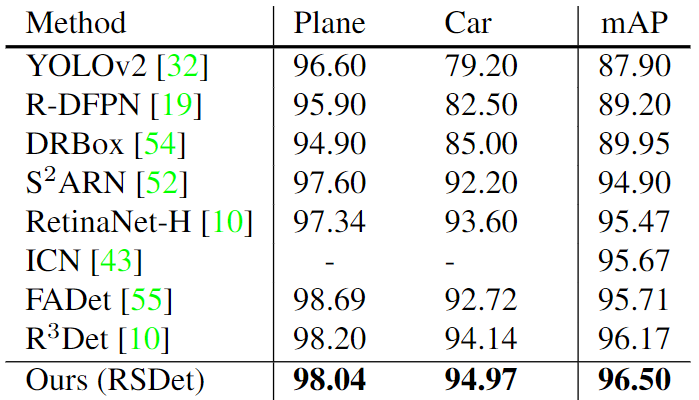
作者使用DOTA、ICDAR2015、HRSC2016、UCAS-AOD数据集进行有关实验。
[训练细节]
[损失消融研究]
作者使用RetinaNet进行有关实验。另外,作者得出八参数比五参数更容易回归。

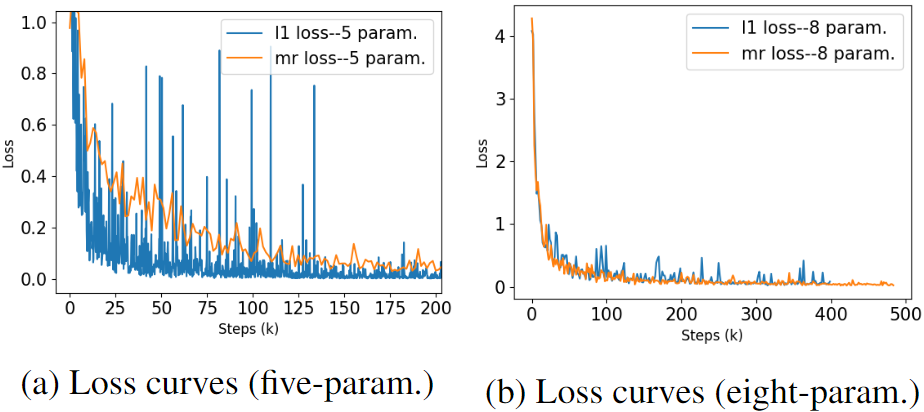
[不同损失对比]

[DOTA数据集上不同方法对比]
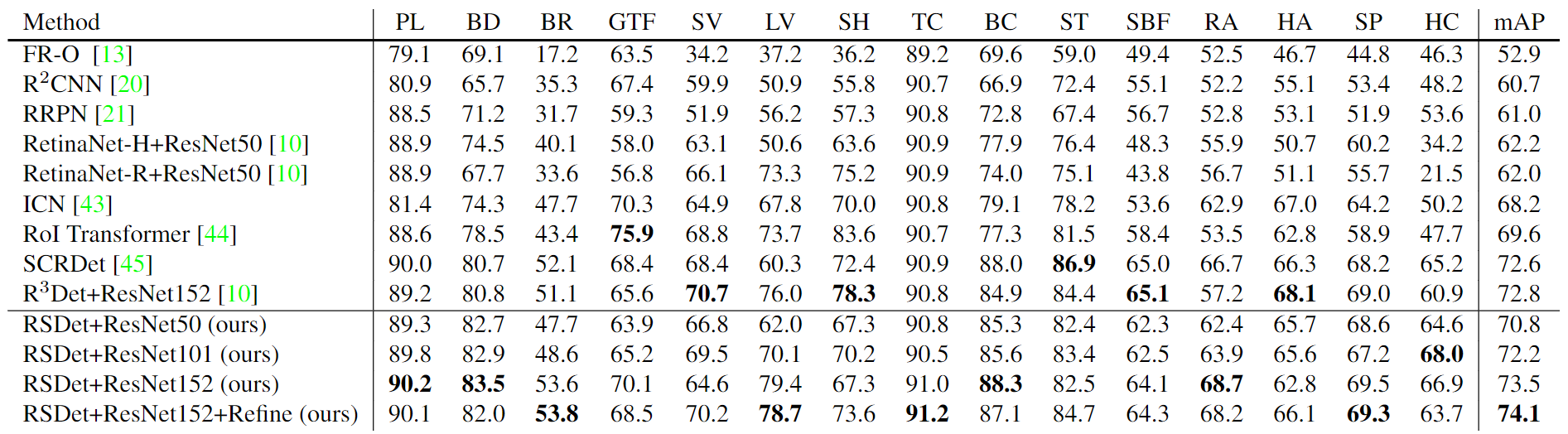
作者使用数据增强操作包括随机水平翻转,随机垂直翻转,随机图像变灰和随机旋转。数据平衡是样本数少于10000的类别将其扩充至10000。

[ICDAR2015与HRSC2016数据集上性能对比]

[UCAS-AOD数据集上性能对比]


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)