基于孤立森林的异常点检测
孤立森林算法是一种适用于连续数据的无监督异常检测方法。与其他异常检测算法通过距离,密度等量化指标来刻画样本间的疏离程度不同,孤立森林算法通过对样本点的孤立来检测异常值。同时相对于K-means等传统算法,孤立森林对高维数据有较好的鲁棒性。
·
⚠申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址。 全文共计3077字,阅读大概需要10分钟
🌈更多学习内容, 欢迎👏关注👀【文末】我的个人微信公众号:不懂开发的程序猿
⏰个人网站:https://jerry-jy.co/❗❗❗知识付费,🈲止白嫖,有需要请后台私信或【文末】个人微信公众号联系我
基于孤立森林的异常点检测
基于孤立森林的异常点检测
实验目录
- 基于孤立森林的异常点检测
实验内容
- 基于孤立森林的异常点检测
知识点
- 孤立森林算法是一种适用于连续数据的无监督异常检测方法。与其他异常检测算法通过距离,密度等量化指标来刻画样本间的疏离程度不同,孤立森林算法通过对样本点的孤立来检测异常值。同时相对于K-means等传统算法,孤立森林对高维数据有较好的鲁棒性。
实验目的
- 利用python,sklearn完成利用孤立森林的异常点检测
实验环境
- Oracle Linux 7.4
- Python 3
任务实施过程
1.打开Jupyter,并新建python工程
-
桌面空白处右键,点击Konsole打开一个终端
-
切换至
/experiment/jupyter目录
cd experiment/jupyter
- 启动Jupyter,root用户下运行需加
–allow-root
jupyter notebook --ip=127.0.0.1 --allow-root


- 依次点击右上角的 New,Python 3新建python工程


- 点击Untitled,在弹出框中修改标题名,点击Rename确认

2.数据准备
- 输入代码后,使用shift+enter执行,下同。
- 导入所需库
- 本实验采用随机生成数据集
import numpy as np #用于数学操作及随机数生成
import pandas as pd #用于生成DataFrame数据格式
import matplotlib.pyplot as plt #用于可视化
from pylab import savefig
from sklearn.ensemble import IsolationForest #引入Isolation Forest

3.数据生成
# 设定可视化默认参数
plt.rcParams['figure.dpi'] = 100
plt.rcParams['figure.figsize'] = [15, 10]

# 生成数据
rng = np.random.RandomState(42) #设定随机数种子

# 生成训练集数据
X_train = 0.2 * rng.randn(1000, 2)
X_train = np.r_[X_train + 3, X_train]
X_train = pd.DataFrame(X_train, columns = ['x1', 'x2']) #生成DataFrame格式数据

# 生成非异常值测试集数据
X_test = 0.2 * rng.randn(200, 2)
X_test = np.r_[X_test + 3, X_test]
X_test = pd.DataFrame(X_test, columns = ['x1', 'x2']) #生成DataFrame格式数据

# 生成异常值
X_outliers = rng.uniform(low=-1, high=5, size=(50, 2))
X_outliers = pd.DataFrame(X_outliers, columns = ['x1', 'x2']) #生成DataFrame格式数据

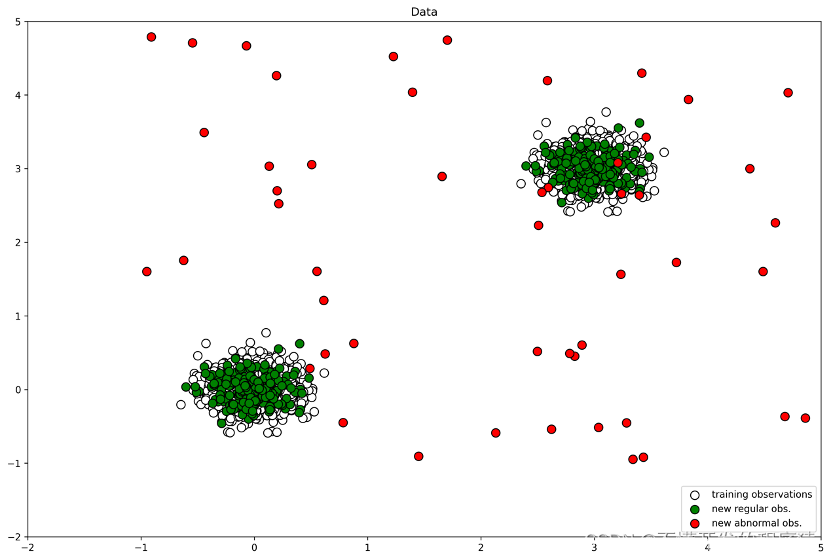
4.数据可视化
# 对生成数据可视化
plt.title("Data")
p1 = plt.scatter(X_train.x1, X_train.x2, c='white',
s=20*4, edgecolor='k') #设置散点图白色点
p2 = plt.scatter(X_test.x1, X_test.x2, c='green',
s=20*4, edgecolor='k') #设置散点图绿色点
p3 = plt.scatter(X_outliers.x1, X_outliers.x2, c='red',
s=20*4, edgecolor='k') #设置散点图红色点
plt.axis('tight')
plt.xlim((-2, 5)) #X轴范围
plt.ylim((-2, 5)) #Y轴范围
plt.legend([p1, p2, p3],
["training observations",
"new regular obs.", "new abnormal obs."],
loc="lower right")
plt.show() #可视化

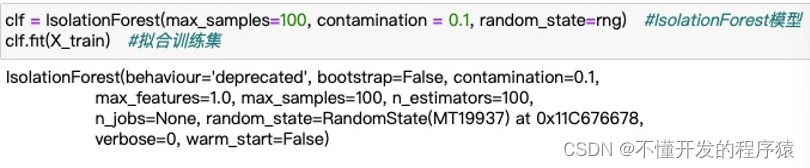
5.建立孤立森林进行异常点检测
clf = IsolationForest(max_samples=100, contamination = 0.1, random_state=rng) #IsolationForest模型
clf.fit(X_train) #拟合训练集
y_pred_train = clf.predict(X_train) #对训练集预测
y_pred_test = clf.predict(X_test) #对测试集预测
y_pred_outliers = clf.predict(X_outliers) #对异常值预测

# 查看对非异常值的检测准确率
print("Accuracy:", list(y_pred_test).count(1)/y_pred_test.shape[0])

# 查看对异常点检测准确率
print("Accuracy:", list(y_pred_outliers).count(-1)/y_pred_outliers.shape[0])

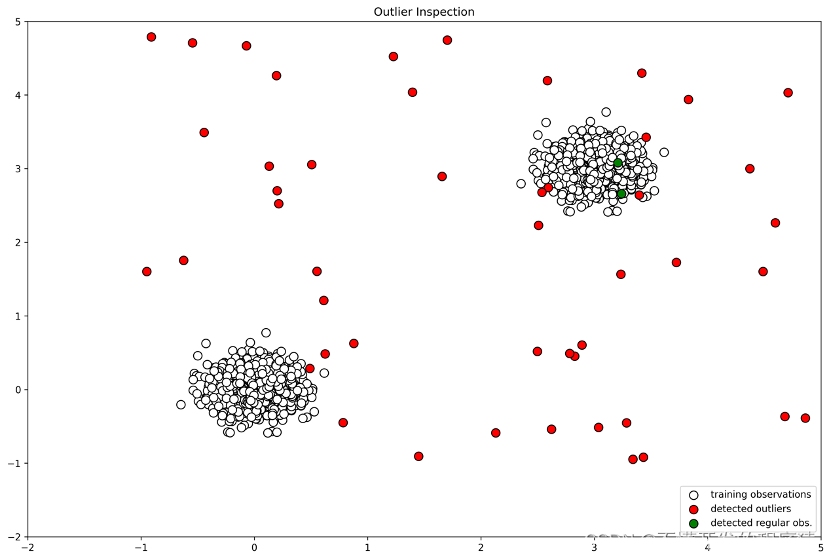
6.检测效果可视化
#检测异常值
# 加入异常值标签
X_outliers = X_outliers.assign(y = y_pred_outliers)
plt.title("Outlier Inspection") #设定图像名称
p1 = plt.scatter(X_train.x1, X_train.x2, c='white',
s=20*4, edgecolor='k') #设置散点图白色点
p2 = plt.scatter(X_outliers.loc[X_outliers.y == -1, ['x1']],
X_outliers.loc[X_outliers.y == -1, ['x2']],
c='red', s=20*4, edgecolor='k') #设置散点图红色点
p3 = plt.scatter(X_outliers.loc[X_outliers.y == 1, ['x1']],
X_outliers.loc[X_outliers.y == 1, ['x2']],
c='green', s=20*4, edgecolor='k') #设置散点图绿色点
plt.axis('tight')
plt.xlim((-2, 5)) #X轴范围
plt.ylim((-2, 5)) #Y轴范围
plt.legend([p1, p2, p3],
["training observations",
"detected outliers",
"detected regular obs."],
loc="lower right")
plt.show() #可视化

–end–
说明
本实验(项目)/论文若有需要,请后台私信或【文末】个人微信公众号联系我

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)