ADASYN算法总结
ADASYN 算法根据少数类样本的分布自适应地改变不同少数类样本的,自动地确定每个少数类样本需要合成新样本的数量,,从而补偿偏态分布。
ADASYN 算法根据少数类样本的分布自适应地改变不同少数类样本的权重,自动地确定每个少数类样本需要合成新样本的数量,为较难学习的样本合成更多的新样本,从而补偿偏态分布。
一、算法步骤
1、计算类别不平衡的程度

ms是少数类的数量,ml是多数类的数量
2、定义dth为目前类别不平衡程度的最大阈值
如果 d < dth(即发生不平衡)
①、计算需要为少数类生成的合成数据样本的数量:
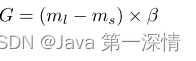
β∈[0,1]是用于指定生成合成数据后所需的平衡水平的参数。
β=1表示在泛化过程之后创建完全平衡的数据集。
②、对少数类中的每个样本Xi,根据欧式距离找出其K个最近邻样本,计算ri

其中Δi是xi的K个最近邻中属于多数类的样本
③、计算ri均值

④、计算每个Xi需要生成的样本数

其中G是如第一步公式中定义的需要为少数类生成的合成数据样本的总数。
⑤、从1循环到gi,生成xi的新样本
从数据的K个最近邻居中随机选择一个少数类样本xzi,参与新样本si的计算。λ是一个随机数

二、未来研究点
ADASYN与基于集成的学习算法相结合。为此,需要使用Bootstrap采样技术对原始训练数据集进行采样,然后将ADASYN嵌入到每个采样集以训练假设。最后,可以使用类似于AdaBoost.M1[35][36]的加权组合投票规则来组合来自不同假设的所有决策,以获得最终预测输出。
ADASYN也可以推广到多类不平衡学习问题
还可以对ADASYN算法进行修改,以便于增量学习应用。在这种情况下,学习算法应该有能力积累以前的经验,并使用这些知识来学习额外的新信息,以帮助预测和未来的决策过程。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)