word2vec模型
如果w1和w2两个单词词义相近,那么w1和w2两个单词的向量表达应该是类似或相近的。word2vec尝试去表达单词之间的关系。
一、word2vec概述
1.1 外在表现
如果w1和w2两个单词词义相近,那么w1和w2两个单词的向量表达应该是类似或相近的。word2vec尝试去表达单词之间的关系。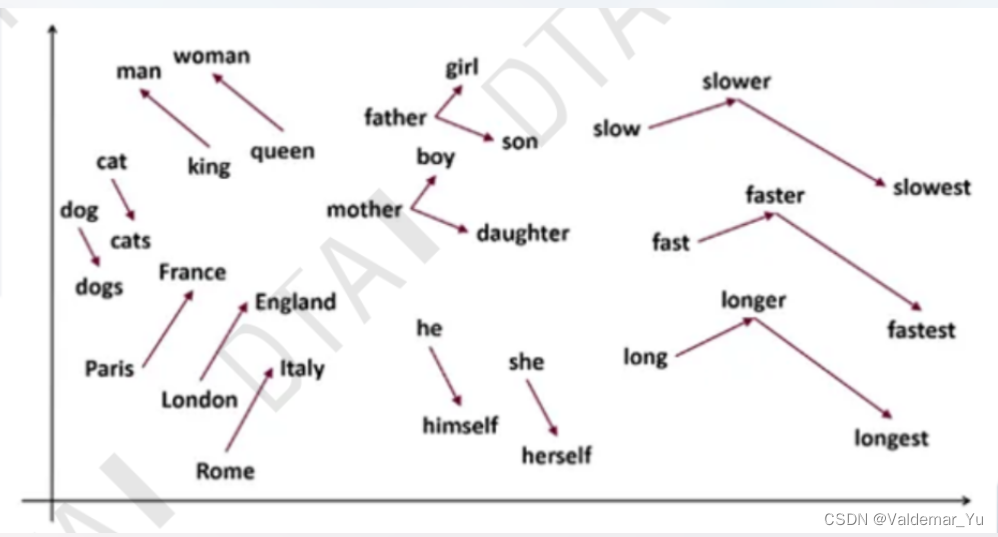
- w1 = ‘man’
- w2 = ‘woman’
- w3 = ‘king’
- w4 = ‘queen’
V k i n g − V m a n ≈ V q u e e n − V w o m a n V_{king}-V_{man}\approx V_{queen}-V_{woman} Vking−Vman≈Vqueen−Vwoman
1.2 内在
- 输入:大语料库/文本簇
- 基于语料库创造字典
- 为每一个字典中的文本创建一个向量
- 可以手动创建word2vec语料库,也可以使用训练好的word2vec语料库
- word2vec创建的向量都是高维向量,维度越多能够表达的信息越多
- 创建的向量是密集向量
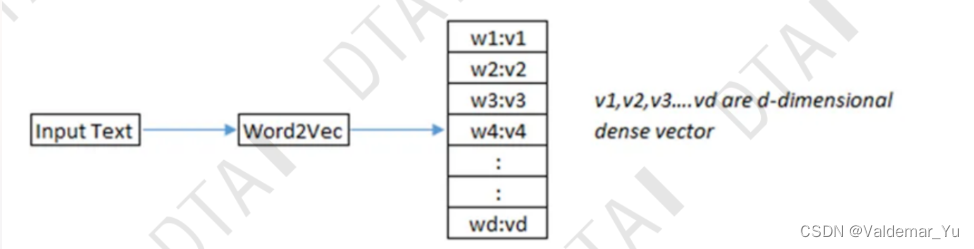
1.3 Personality Embedding
性格嵌入,或者说是特征嵌入![![[Pasted image 20230612145226.png]]](https://i-blog.csdnimg.cn/blog_migrate/77fa35657d9acb51d42b0ff882755d9d.png)
每一项的分数对结果的影响不光有正向,也有负面的影响,所以需要将其映射到[-1,1]的区间(tanh),既减少了计算,也可以反映出对结果的正负影响以及影响程度。![![[Pasted image 20230612150234.png]]](https://i-blog.csdnimg.cn/blog_migrate/59a30aa89fbbbb5cbf8ab937ff412df7.png)
将不同维度的分数组成向量,这样就能很好分析不同样本之间的相似度。![![[Pasted image 20230612151608.png]]](https://i-blog.csdnimg.cn/blog_migrate/84bc415d2da7d6e59063e7cf820f8daf.png)
余弦语义相似度计算公式 c o s i n e s i m i l a r i t y = S C ( A , B ) : = c o s ( θ ) = A ⋅ B ∣ ∣ A ∣ ∣ ⋅ ∣ ∣ B ∣ ∣ = ∑ i = 1 n A i B i ∑ i = 1 n A i 2 ⋅ ∑ i = 1 n B i 2 \begin{aligned} cosine \quad similarity=S_C(A,B):&=cos(\theta)=\frac {\bf A·B}{\bf ||A||·||B||} \\ \\ &=\frac{\sum^n_{i=1}A_iB_i}{\sqrt{\sum^n_{i=1}A_i^2}·\sqrt{ \sum^n_{i=1}B_i^2}} \end{aligned} cosinesimilarity=SC(A,B):=cos(θ)=∣∣A∣∣⋅∣∣B∣∣A⋅B=∑i=1nAi2⋅∑i=1nBi2∑i=1nAiBi示例如下
语义相似度是评估向量A和B的相似程度,用于寻找语义相近的词。![![[Pasted image 20230612152031.png]]](https://i-blog.csdnimg.cn/blog_migrate/943ff85a2181e94c9f6e793f61765cc8.png)
就像这张图,将予以相似度用于评估Person #1 ,Person #2 与 Jay 的性格相似程度。显然Person #1 语义相似度+0.66优于Person #2 的-0.37,所以跟Jay更为相像。
1.4 词向量矩阵
下面给出一个训练好的词向量可视化矩阵。![![[Pasted image 20230612152304.png]]](https://i-blog.csdnimg.cn/blog_migrate/e14c83169b9c354748d58be3051a7235.png)
可以看出,词向量矩阵是为字典中每一个文本创建一个向量,每一列都表示某一种隐藏特征,很显然列数越多词向量所能表达的语义信息就越丰富,相对应的内存占用也就会特别大,后续计算复杂度也会很高,而且词向量矩阵明显更加密集,不像One-hot Encoding向量甚至于共现矩阵那样稀疏,词向量之间的关系一般都是用相似度来衡量,类比于分类问题中表达任意两类之间的相似度就是通过距离的概念来表达相似度,如欧拉距离,曼哈顿距离等,那么词向量之间的相似度我们就可以使用上面的余弦相似度来衡量两个词之间的相似度。
c o s i n e s i m i l a r i t y = S C ( A , B ) : = c o s ( θ ) = A ⋅ B ∣ ∣ A ∣ ∣ ⋅ ∣ ∣ B ∣ ∣ = ∑ i = 1 n A i B i ∑ i = 1 n A i 2 ⋅ ∑ i = 1 n B i 2 \begin{aligned} cosine \quad similarity=S_C(A,B):&=cos(\theta)=\frac {\bf A·B}{\bf ||A||·||B||} \\ \\ &=\frac{\sum^n_{i=1}A_iB_i}{\sqrt{\sum^n_{i=1}A_i^2}·\sqrt{ \sum^n_{i=1}B_i^2}} \end{aligned} cosinesimilarity=SC(A,B):=cos(θ)=∣∣A∣∣⋅∣∣B∣∣A⋅B=∑i=1nAi2⋅∑i=1nBi2∑i=1nAiBi
基于以上词向量的特性,我们可以对词向量进行矢量运算来探究不同单词之间的关系。![![[Pasted image 20230612152812.png]]](https://i-blog.csdnimg.cn/blog_migrate/e97be280c37d8ca1770dc742716ddb1d.png)
1.5 句向量Sentence Vector构建思路
当然,除了词向量之外,更具有重要作用的是词向量可以合成句向量Sentence Vector来表示一句话的语义信息,自然而然地句向量应该也具有词向量的运算特性,正式由于这样的特性才能让后面基于神经网络的语言模型探究不同句子之间的关系。
使用词向量构建Sentence Vector有两种思路,一种是加权平均句向量,另一种是TF-IDF的加权句向量,原因在于对所有单词一视同仁的平均化显然不符合我们的语言习惯,平均的方式可能对句子的含义表示存在特征丢失,因为我们说话一定会有一个中心,也就是一句话的key。由于TF-IDF表达的就是词对这个句子的重要程度,因此TF-IDF用于强化句子中重要单词的特征。下面是两种不同句向量的数学公式
V s e n t e n c e = V w 1 + V w 2 + ⋅ ⋅ ⋅ + V w n n V s e n t e n c e = t 1 ⋅ V w 1 + t 2 ⋅ V w 2 + ⋅ ⋅ ⋅ + t n ⋅ V w n t 1 + t 2 + ⋅ ⋅ ⋅ + t n = ∑ i = 1 n t i ⋅ V w i ∑ i = 1 n t i \begin{aligned} V_{sentence}&=\frac{V_{w_1}+V_{w_2}+···+V_{w_n}}n\\ V_{sentence}&=\frac{t_1·V_{w_1}+t_2·V_{w_2}+···+t_n·V_{w_n}}{t_1+t_2+···+t_n}=\frac{\sum^n_{i=1}t_i·V_{w_i}}{\sum^n_{i=1}t_i} \end{aligned} VsentenceVsentence=nVw1+Vw2+⋅⋅⋅+Vwn=t1+t2+⋅⋅⋅+tnt1⋅Vw1+t2⋅Vw2+⋅⋅⋅+tn⋅Vwn=∑i=1nti∑i=1nti⋅Vwi
- 平均化句向量
![![[Pasted image 20230612211422.png]]](https://i-blog.csdnimg.cn/blog_migrate/cb50f384cbf06a0a322aae39273f12f8.png)
上面讨论完词向量的相关信息,后面就需要讨论词向量是怎么得到的,接下来学习一种基于神经网络的文本表示模型——word2vec模型。
二、word2vec训练
2.1 一般化训练流程 normal procedure
![![[Pasted image 20230612212730.png]]](https://i-blog.csdnimg.cn/blog_migrate/34e0ae7bfc4aeffe43249119ba9628a9.png)
- 任务:预测下一个位置的词
- 逐词输入,在字典中找到对应词的词向量
- 对下一个词进行预测,选择概率较大的结果输出,但不代表概率最大的结果即是正确结果,示例如下,通过滑动窗口的模式,将词送入模型,完成对下一个词的预测。
![![[Pasted image 20230612213213.png]]](https://i-blog.csdnimg.cn/blog_migrate/8ebb1f2351f39465142c39e33a786b70.png)
2.2 词向量训练方式
word2vec训练词向量的方式有两种,一种叫C-BOW,另一个叫Skip-Gram
2.2.1 C-BOW
- 思想:将单词的上下文作为输入,尝试预测与上下文对应的单词
- 例如从一句话中抽取出一个词,并使用上下文预测该词,一种MLM(多对多)任务,由于预测的不一定是一个单词,可能是多个单词,因此下面仅考虑一个词作为上下文的特殊场景(字典长度V)
-
一个上下文输入时的C-BOW结构如下:
![![[Pasted image 20230612214615.png]]](https://i-blog.csdnimg.cn/blog_migrate/ebf462f887c8356e4b8cf278b7ba8b91.png)
- 上下文只有一个文本时,window_size = 1
- 输入是长度为V(字典大小)的one-hot encoding向量
- 输出也是长度为V的one-hot encoding向量
- W V ∗ N W_{V*N} WV∗N 是将输入x映射到隐藏层的权重矩阵,输出的是输入x这个词在词向量矩阵中的词向量(长度为N)
- W N ∗ V ′ W_{N*V}' WN∗V′ 是将隐藏层输出映射到最终输入层的权重矩阵,输出的是预测出来的词向量(长度为V)
-
多个上下文输入时的C-BOW:
![![[Pasted image 20230612222449.png]]](https://i-blog.csdnimg.cn/blog_migrate/2835f2fd3112ca0f97982be2785f6c44.png)
- 当上下文存在多个文本时, window_size = context
- Hidden layer 则会采用对多个输入的矩阵相乘结果进行加权平均。实际上就是每一个输入x对应词向量矩阵中的词向量(长度为N)取出来然后做一个加权平均,结果就是Hidden layer 的词向量(长度为N)
- 隐藏层通过 W N ∗ V ′ W_{N*V}' WN∗V′ 转化成长度为V的向量y
- 获得预测的词向量y之后对其进行softmax处理,得到预测词的概率分布
- 使用交叉熵损失计算loss,交叉熵的输入就是Softmax得到的概率分布与真实词的One-hot Encoding向量之间的差值对比
- 最后,进行反向传播,更新词向量矩阵 W V ∗ N W_{V*N} WV∗N 和 W N ∗ V ′ W_{N*V}' WN∗V′
- 使用 W V ∗ N W_{V*N} WV∗N 作为当前词向量的输出
2.2.2 Skip-Gram
另一种训练词向量矩阵的思路就是Skip-Gram,它的思想就是拥有相同上下文的单词更可能持有相似的语义。因此可以使用目标词与上下文的文本对,而不是上下文与目标词的文本对,通过神经网络的训练逐步得到目标词的词向量。很明显这个结构和C-BOW的结构是相反的。![![[Pasted image 20230612223348.png]]](https://i-blog.csdnimg.cn/blog_migrate/f7516e66926f28a3231605f37b637452.png)
- 特点
- 将需要被预测的文本作为上下文, window_size = context
- 结构与C-BOW镜像相反
- 输入文本的one-hot encoding通过词向量矩阵 W V ∗ N W_{V*N} WV∗N 转化为中间向量h。
- h向量可训练矩阵 W N ∗ V ′ W_{N*V}' WN∗V′ 转化为多个输出向量y(对应多个输出且训练相同,参数共享)
- 上一步中转化的结果虽然是相同的,但是每一个输出对应的标签是不同的。对每一个词向量y进行Softmax得到对应的概率分布,因此C个y可以得到C个概率分布。
- 使用不同的目标文本One-hot Encoding进行损失计算和反向传播,然后更新参数矩阵,这里操作指的是将每一个概率分布和它对应的目标文本的One-hot Encoing向量取差值对比作为损失函数的输入,预测出来的词向量与真实的词向量之间的差值越小,损失越小,结果就越好,并且不断根据损失来更新词向量矩阵W和隐藏层矩阵W’!
![[[Pasted image 20230612223312.png]]](https://i-blog.csdnimg.cn/blog_migrate/05813355f060a3242174f001d4231823.png)
2.2.3 关于C-BOW和Skip-Gram的讨论
- 由于C-BOW用多个词预测一次,而Skip-Gram用一个词预测多次,也就是说C-BOW训练时的词向量仅仅关注一次目标词汇与上下文文本的关系,对于目标词只进行一次训练,Skip-Gram在训练时目标词会多次关注上下文的文本与目标词之间的关系,对目标词进行了多次的训练,直观上就会感觉Skip-Gram对词向量的训练效果会更好,当然缺点自然也是做了这么多次预测,会有更大的时间成本,例如训练一个C-BOW需要花费8h,而一个Skip-Gram需要32h。
- 假设我们通过300dims的维度表达词向量,字典的长度为10000,则参数矩阵过于庞大,W和W‘这两个可训练矩阵的大小为300 * 10000 = 3 * 10^6,因此对这样两个可训练矩阵进行梯度下降和反向传播会变得十分困难,除此之外,参数量太大很容易因其模型与数据集不适配的问题,导致模型出现过拟合问题,因此需要的文本数据集大小也是非常大的。
因此,科学家们提出了优化Skip-Gram加速训练模型训练的两种方法。
3 优化方法
- 下采样:对频率高的词进行下采样操作,减少训练样本
- 负采样:每次更新过程中仅迭代更新部分的模型权重
3.1 下采样
对高频词进行抽样
![![[Pasted image 20230612234252.png]]](https://i-blog.csdnimg.cn/blog_migrate/4182ef699a9610ab6e8111dd216ffd8b.png)
如果我们设置window_size=2,则上下文文本对如上图右侧所示,但是对于高频词“the”,这样的处理会产生下面两个问题:
1. 当我们得到成对的单词训练样本时,(’fox‘,’the‘)这样的训练样本不会给我们提供关于‘fox’(‘fox’是目标词)更多的语义信息,因为‘the’在每个单词的上下文几乎都会出现。
2. 由于‘the’这个常用词出现的概率很大,那么就会有大量的(‘the’,…)这样的文本对,这些样本数量远远大于我们学习‘the’这个单词的语义信息所需要的样本量。
word2vec通过抽样模式来解决这种高频词问题,既然频率高的词作为训练样本有这么多问题,那么不用其当做训练样本对,只需要作为目标词进行训练就好了。因此,下采样的核心思想就是,对于我们在训练原始文本中遇到的每一个单词,它们都有一定概率被我们从文本中删掉,而这个被删除的概率和单词的频率有关。因此这个一定概率所描述的概率就是我们需要定义的抽样率 P ( w i ) P(w_i) P(wi) ,用来计算词汇表中保留某个单词的概率公式:
- w i w_i wi 是目标词
- Z ( w i ) Z(w_i) Z(wi) 是目标词出现在文本集中的频率
- 一个名为“sample”的参数,它控制发生多少下采样,默认0.01
- P ( w i ) P(w_i) P(wi) 决定保留当前词的概率,它就是抽样率 P ( w i ) = ( z ( w i ) 0.001 + 1 ) ⋅ 0.001 z ( w i ) P(w_i)=\bigg(\sqrt{\frac{z(w_i)} {0.001}}+1 \bigg)·\frac{0.001}{z(w_i)} P(wi)=(0.001z(wi)+1)⋅z(wi)0.001
- 当sample=0.001时,每个词被删掉的概率是上述公式,下面是通用公式 P ( w i ) = ( z ( w i ) s a m p l e + 1 ) ⋅ s a m p l e z ( w i ) P(w_i)=\bigg(\sqrt{\frac{z(w_i)} {sample}}+1 \bigg)·\frac{sample}{z(w_i)} P(wi)=(samplez(wi)+1)⋅z(wi)sample
可以发现,当sample大,单词 w i w_i wi 被删掉的概率就会变大,因此sample通过控制单个单词被删掉的概率来间接控制整个corpus中,有多少样本会发生下采样。
但是下采样只是尽可能减少训练样本的数量,一定程度上加快模型训练,但模型的大量参数的更新问题依然没有解决,因此又提出了负采样来解决这一问题。
3.2 负采样
神经网络每经过一个训练样本就要更新一次网络参数,在word2vec中的参数矩阵 W V ∗ N W_{V*N} WV∗N 的维度是由词汇表的长度V和超参数N决定的,因此在海量文本数据下,它的词汇表Vocabulary长度会很大,因此也会导致参数矩阵很大,每一次需要更新的参数量也很多。
负采样解决的就是这个问题,用来提法哦训练速度并且改善得到的词向量质量的一种方法,不同于原本每一个训练样本更新所有权重参数,负采样让每一个训练样本仅仅更新一小部分的权重参数,这样就会显著降低梯度下降过程中的计算量。这时出现了新的问题,更新谁的参数?由负采样的名字就可以知道,我们将随机选择一小部分的negative words进行更新对应的权重。
- negative words:当我们用(input word:fox,output word:quick)来训练我们的神经网络时,fox和qucik都是one-hot encoding向量,如果我们词汇表大小为10000时,这两个词对应的词向量也应该是10000维的词向量,在输出层时,我们生成一个10000维的词向量送进Softmax得到一个概率分布,概率最大的那个词是预测的词,那么我们很自然地期望对应quick这个正确的单词的那个神经元结点输出1,其余9999个结点都应该输出0,而这9999个我们期望输出0的神经元结点就被我们称为negative words
因此,当我们使用负采样时,我们就会随机选择一小部分negative words(非目标词的词)来更新对应的权重参数,当然我们也会对positive words(目标词)的权重进行更新。
如果我们的Hidden layer到output layer拥有一个300 * 10000的权重矩阵 W N ∗ V ′ W_{N*V}' WN∗V′ ,如果我们使用负采样的方法,仅仅去更新我们的positive words——quick,和我们选择的其他5个negative words(这里选择的是5个,论文指出选择5~20个negative words效果最好)的结点对应的权重,共6个词的词向量也就 300 * 6=1800个权重而已,比起原来的300 * 10000=3000000的权重来说,相当于只计算了0.6%的权重而已,这样计算效率就大幅提高了。
现在还剩下一个问题,就是这n个负样本究竟应该选择谁呢,结合上面介绍的下采样,我们认为频率更高的词更有可能被选中,但通过实现发现使用纯随机的变体可以获得更好的效果,因此又倾向于增加出现频率较低的词的概率,并降低出现频率较高的词的概率以达到均匀随机抽取的效果,数学公式如下: P ( w i ) = f ( w i ) 3 4 ∑ j = 0 n f ( w j ) 3 4 P(w_i)=\frac{f(w_i)^{\frac3 4}}{\sum^n_{j=0}f(w_j)^{\frac 34}} P(wi)=∑j=0nf(wj)43f(wi)43
代码实现 | Kaggle

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)