M2FT rans: Modality-Masked Fusion T ransformer for Incomplete Multi-Modality Brain T umor Segmentati
一种Transformer融合策略,用于处理具有更丰富全局信息的脑肿瘤分割的不完整多模态场景具有可学习融合令牌的Modality-masked fusion transformers,用于有效的特征融合,同时最大限度地减少缺失模态的负面影响空间注意力和通道融合Transformer自适应地重新加权模态,以避免在不完整/缺失模态问题下的主导模态跨模态的全局特征、屏蔽缺失模态的负面影响、减少模态特定特
M2FTrans: Modality-Masked Fusion T ransformer for Incomplete Multi-Modality Brain T umor Segmentation
M2FT-trans:用于不完全多模态脑肿瘤分割的模态掩蔽融合变换器
背景
脑肿瘤分割往往依赖多模态数据,但是临床中会有某些模态缺失的问题,现有的不完整模态的脑肿瘤融合、分割,精度不理想。旨在探索、融合跨模态特征
贡献、总结
- 一种Transformer融合策略,用于处理具有更丰富全局信息的脑肿瘤分割的不完整多模态场景
- 具有可学习融合令牌的Modality-masked fusion transformers,用于有效的特征融合,同时最大限度地减少缺失模态的负面影响
- 空间注意力和通道融合Transformer自适应地重新加权模态,以避免在不完整/缺失模态问题下的主导模态
跨模态的全局特征、屏蔽缺失模态的负面影响、减少模态特定特征中的冗余,加权每个模态及其模态内特征
实验
BRATS2018、2020,四种模态数据,随即裁剪808080,随即旋转、强度变化、镜像翻转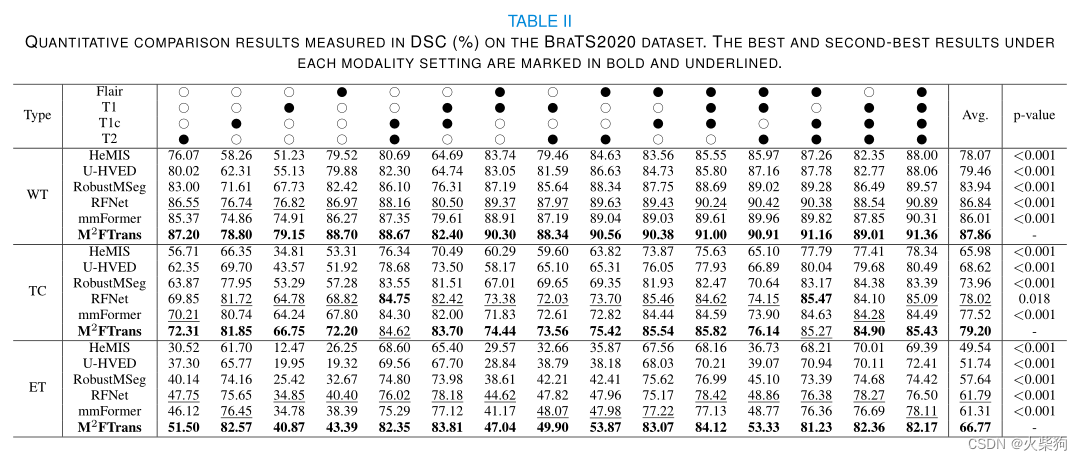
丰富的实验,每个模态的组合都做了一次实验
方法
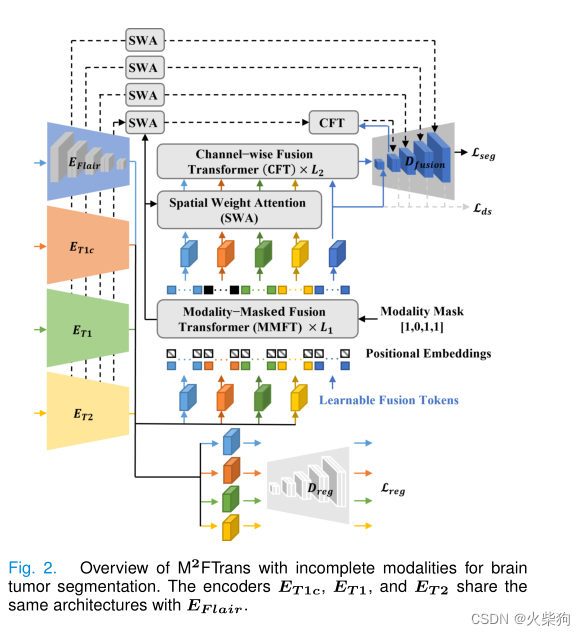
Modality-Specific Feature Extraction(不共享的4个编码器)
传统的多模态框架中,不同模态的特征直接融合提供给解码器进行分割,而解码器倾向于选择最具有判别能力的模态作为脑肿瘤分割的主要模态,而主模态缺失的时候,性能会严重退化,为了避免这种模态偏差、平衡不同模态,用了Dreg进行正则化(我感觉和RFNet差不多)减少缺失模态的负面影响。
Modality-Masked Fusion Transformer(模态掩码)
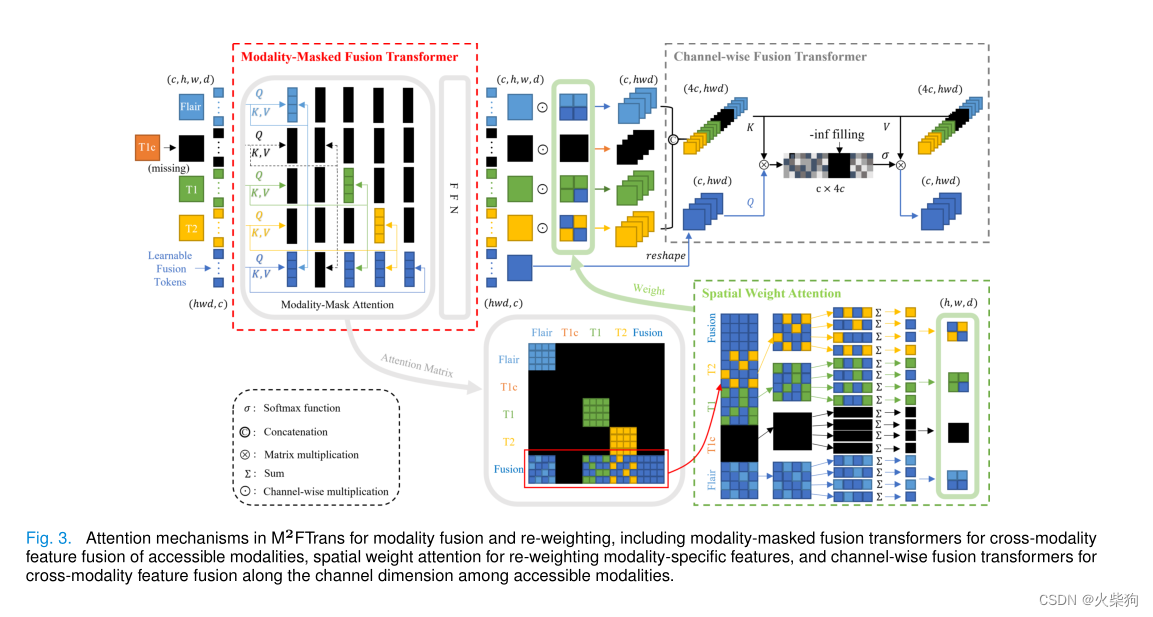
红框里面是模态掩码融合注意力,为了处理丢失模态(T1c) ,深蓝色是可学习的融合Token,分别与每个模态进行模态内注意力计算,与当前模态融合的时候,其它都mask掉,最后得到模态内注意力,然后通过空间Attention,通道Fusion Transformer
Spatial Weight Attention(空间注意力)
模态掩码融合注意力得到的4个特征图是模态内注意力,也就是说,这时候4个模态之间是同等重要的,接下来计算各个模态的重要程度。给定一个自注意矩阵,列向量可以在一定程度上反映单个标记的重要性,按行求和之后逐元素乘原始特征,减少了Token的冗余,且得到了模态的重要程度。空间维度的冗余减少了,接下来减少通道维度的冗余(每个Token的特征图之间的冗余)。
Channel-wise Fusion Transformer(通道融合)
需要注意的是,这里的QKV得到的方式 是用分组卷积(按模态分组)得到的,可以防止原始空间信息丢失。减少了通道维度的冗余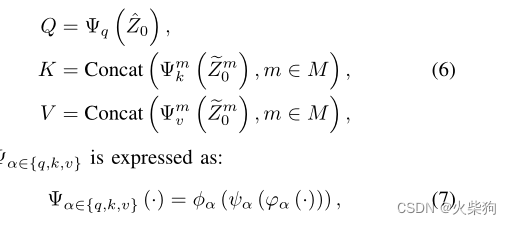
那个符号是,逐点卷积、深度可分离卷积、逐点卷积
Decoding with Deep Supervision(深度监督)
用于分割的解码器和用于正则化的解码器一样,只不过加上了跳跃连接,每个解码器层输出的特征都用来计算损失(深度监督)
损失函数

分割损失和RFNet差不多,加权交叉熵和Dice,加了个深度监督,Lds,每一层都计算损失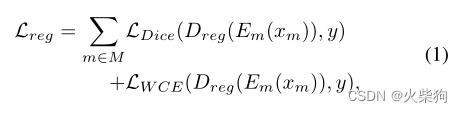
Lreg是正则化损失,和RFNet异曲同工,用于避免模态偏差并平衡不同的模态的重要程度。
Thinking
这些模型主要框架都和3D MRI brain tumor segmentation using autoencoder regularization(BraTs2018第一名方案)差不多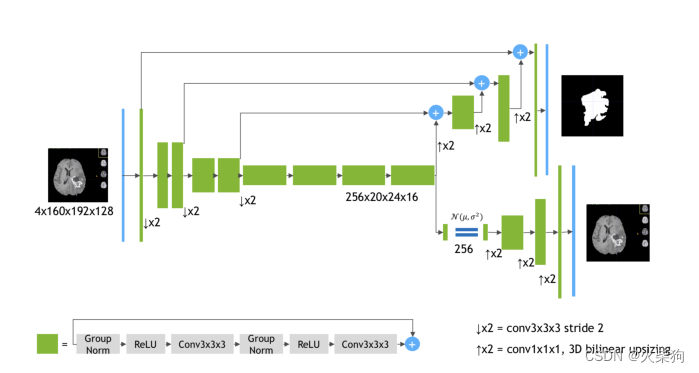
编码器,两个解码器,一个有跳跃连接 用于分割,一个无跳跃连接 用于融合,这个融合用的是VAE(变分自编码器,一个生成模型)编码器是共享的。
本文的优化,考虑到了模态缺失和不同模态的重要性(用了4个不共享的编码器),加入种种注意力机制,掩码机制,降低了模态缺失带来的负面影响,可以说是 模态内注意力,模态间注意力。good idea

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 2
2 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)