BP神经网络模拟一元二次函数【手写推导!!】
文章目录
题目要求:
请设计一个5层全连接网络,损失函数自由,激励函数使用sigmoid/tanh/relu,反向传播过程自己写,不可使用pytorch自动求导机制,
目标函数为:
y = x ∗ x + 6 ∗ x − 6 ∗ 2 = x 2 + 6 x − 12 y=x*x + 6*x - 6*2=x^2+6x-12 y=x∗x+6∗x−6∗2=x2+6x−12
逻辑:
-
线性变换:
z ( l ) = a ( l − 1 ) W ( l ) + b ( l ) z^{(l)} = a^{(l-1)} W^{(l)} + b^{(l)} z(l)=a(l−1)W(l)+b(l) -
激活函数(ReLU):
a ( l ) = f ( l ) ( z ( l ) ) = max ( 0 , z ( l ) ) a^{(l)} = f^{(l)}(z^{(l)}) = \max(0, z^{(l)}) a(l)=f(l)(z(l))=max(0,z(l)) -
采用均方误差(MSE)损失:
L = 1 2 n ∑ i = 1 n ( y pred ( i ) − y ( i ) ) 2 \mathcal{L} = \frac{1}{2n} \sum_{i=1}^n (y_{\text{pred}}^{(i)} - y^{(i)})^2 L=2n1i=1∑n(ypred(i)−y(i))2
反向传播损失梯度计算
∂ L ∂ y pred = 1 n ( y pred − y ) \frac{\partial \mathcal{L}}{\partial y_{\text{pred}}} = \frac{1}{n} (y_{\text{pred}} - y) ∂ypred∂L=n1(ypred−y)
从输出层到输入层依次计算梯度:
-
第 5 层(输出层):
∂ L ∂ z ( 5 ) = ∂ L ∂ y pred ⋅ I ( z ( 5 ) > 0 ) ∂ L ∂ W ( 5 ) = ( a ( 4 ) ) ⊤ ∂ L ∂ z ( 5 ) ∂ L ∂ b ( 5 ) = ∑ ∂ L ∂ z ( 5 ) \frac{\partial \mathcal{L}}{\partial z^{(5)}} = \frac{\partial \mathcal{L}}{\partial y_{\text{pred}}} \cdot \mathbb{I}(z^{(5)} > 0) \\ \frac{\partial \mathcal{L}}{\partial W^{(5)}} = (a^{(4)})^\top \frac{\partial \mathcal{L}}{\partial z^{(5)}} \frac{\partial \mathcal{L}}{\partial b^{(5)}} = \sum \frac{\partial \mathcal{L}}{\partial z^{(5)}} ∂z(5)∂L=∂ypred∂L⋅I(z(5)>0)∂W(5)∂L=(a(4))⊤∂z(5)∂L∂b(5)∂L=∑∂z(5)∂L -
第 4 层至第 1 层:
∂ L ∂ z ( l ) = ( ∂ L ∂ z ( l + 1 ) W ( l + 1 ) ⊤ ) ⋅ I ( z ( l ) > 0 ) ∂ L ∂ W ( l ) = ( a ( l − 1 ) ) ⊤ ∂ L ∂ z ( l ) ∂ L ∂ b ( l ) = ∑ ∂ L ∂ z ( l ) \frac{\partial \mathcal{L}}{\partial z^{(l)}} = \left( \frac{\partial \mathcal{L}}{\partial z^{(l+1)}} W^{(l+1)\top} \right) \cdot \mathbb{I}(z^{(l)} > 0) \\ \frac{\partial \mathcal{L}}{\partial W^{(l)}} = (a^{(l-1)})^\top \frac{\partial \mathcal{L}}{\partial z^{(l)}} \\ \frac{\partial \mathcal{L}}{\partial b^{(l)}} = \sum \frac{\partial \mathcal{L}}{\partial z^{(l)}} ∂z(l)∂L=(∂z(l+1)∂LW(l+1)⊤)⋅I(z(l)>0)∂W(l)∂L=(a(l−1))⊤∂z(l)∂L∂b(l)∂L=∑∂z(l)∂L
参数更新
W ( l ) ← W ( l ) − η ∂ L ∂ W ( l ) b ( l ) ← b ( l ) − η ∂ L ∂ b ( l ) 其中 η 为学习率 W^{(l)} \leftarrow W^{(l)} - \eta \frac{\partial \mathcal{L}}{\partial W^{(l)}}\\ b^{(l)} \leftarrow b^{(l)} - \eta \frac{\partial \mathcal{L}}{\partial b^{(l)}}其中 \eta 为学习率 W(l)←W(l)−η∂W(l)∂Lb(l)←b(l)−η∂b(l)∂L其中η为学习率
代码实现:
import numpy as np
import matplotlib.pyplot as plt
class LinearLayer:
def __init__(self, input_dim, output_dim):
self.W = 0.1 * np.random.randn(input_dim, output_dim)
self.b = np.zeros((1, output_dim))
self.grad_W = None
self.grad_b = None
def forward(self, X):
self.X = X # 缓存输入用于反向传播
# Z = XW + b
return X @ self.W + self.b
def backward(self, grad):
# 计算权重梯度:dL/dW = X^T @ δ
self.grad_W = self.X.T @ grad
# 计算偏置梯度:dL/db = Σδ
self.grad_b = np.sum(grad, axis=0, keepdims=True)
# 计算输入梯度:dL/dX = δ @ W^T
return grad @ self.W.T
def update(self, lr):
# 更新W和b
self.W -= lr * self.grad_W
self.b -= lr * self.grad_b
class ReLU:
def forward(self, X):
# 向前传播的时候如果是负数直接输出0
self.mask = (X > 0) # 缓存mask用于反向传播
return X * self.mask
def backward(self, grad):
return grad * self.mask # 负数直接输出0
class MyBPNet:
def __init__(self, layer_dims, activations):
"""
参数说明:
layer_dims: [输入维度, 隐藏层1维度,..., 输出层维度]
activations: 每层激活函数列表,长度比layer_dims少1
"""
assert len(activations) == len(layer_dims) - 1
self.layers = []
self.activations = []
for i in range(len(layer_dims) - 1):
self.layers.append(LinearLayer(layer_dims[i], layer_dims[i + 1]))
# 添加激活函数
act = activations[i]
if act == 'relu':
self.activations.append(ReLU())
def forward(self, X):
a = X
for layer, act in zip(self.layers, self.activations):
z = layer.forward(a)
a = act.forward(z) if act else z
return a
def backward(self, grad):
# 反向传播梯度
for i in reversed(range(len(self.layers))):
if self.activations[i]:
grad = self.activations[i].backward(grad)
grad = self.layers[i].backward(grad)
def update_params(self, lr):
for layer in self.layers:
layer.update(lr)
# 训练函数
def train_model():
# 生成训练数据
x = np.arange(-10, 6).reshape(-1, 1)
y = x ** 2 + 6 * x - 12
# 网络参数
net = MyBPNet(
layer_dims=[1, 10, 10, 10, 10, 1],
activations=['relu', 'relu', 'relu', 'relu', 'relu']
)
epochs = 5000
lr = 1e-3
loss_history = []
for epoch in range(epochs):
# 前向传播
y_pred = net.forward(x)
# 计算损失
loss = 0.5 * np.mean((y_pred - y) ** 2)
loss_history.append(loss)
# 反向传播
grad = (y_pred - y) / y.size
net.backward(grad)
net.update_params(lr)
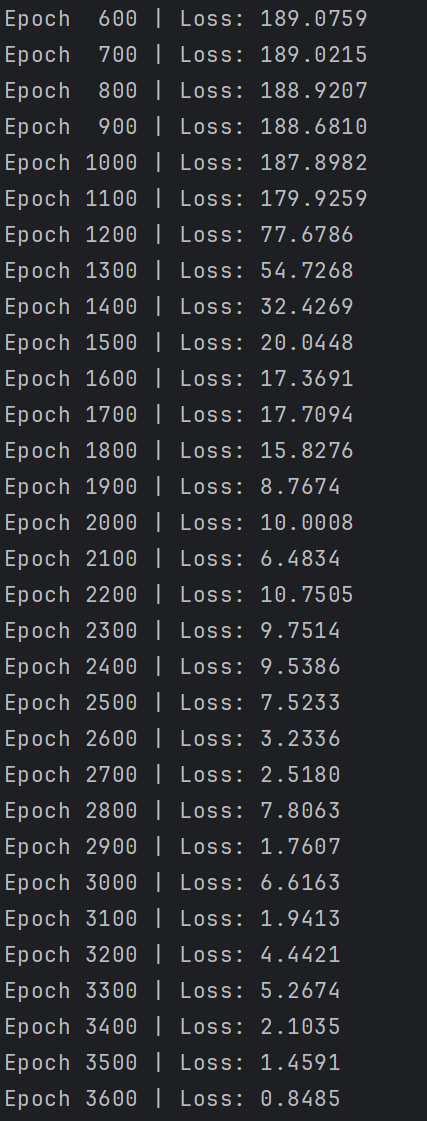
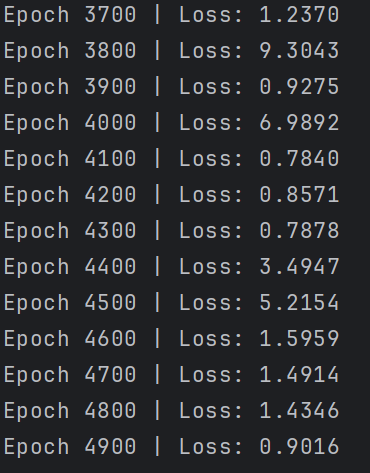
if epoch % 100 == 0:
print(f"Epoch {epoch:4d} | Loss: {loss:.4f}")
if loss < 0.1:
print("训练达标,提前终止")
break
# 可视化结果
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
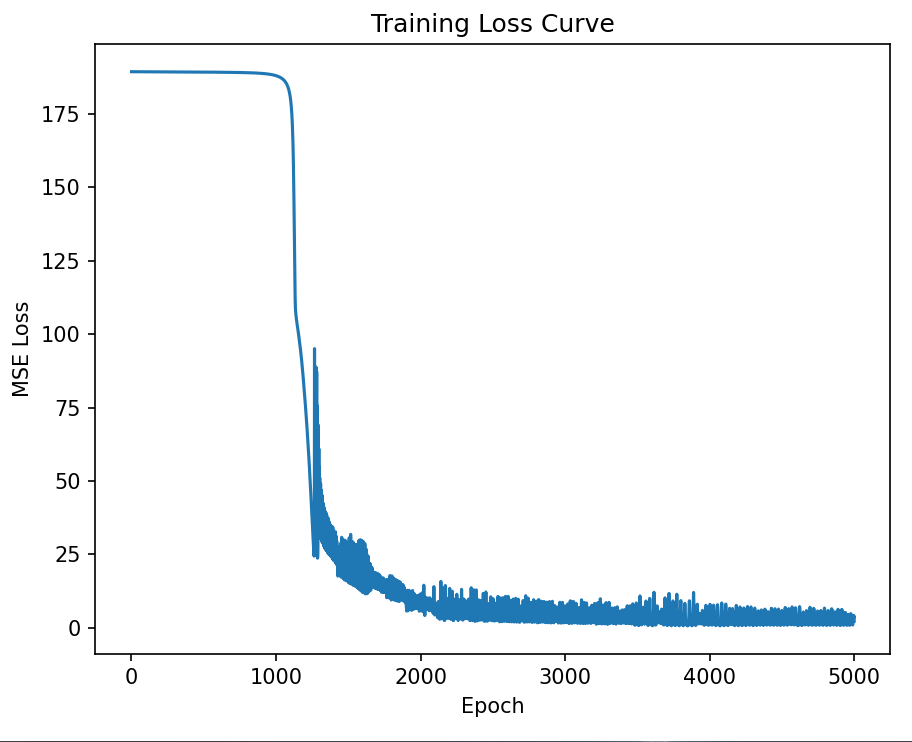
plt.plot(loss_history)
plt.title("Training Loss Curve")
plt.xlabel("Epoch")
plt.ylabel("MSE Loss")
plt.subplot(1, 2, 2)
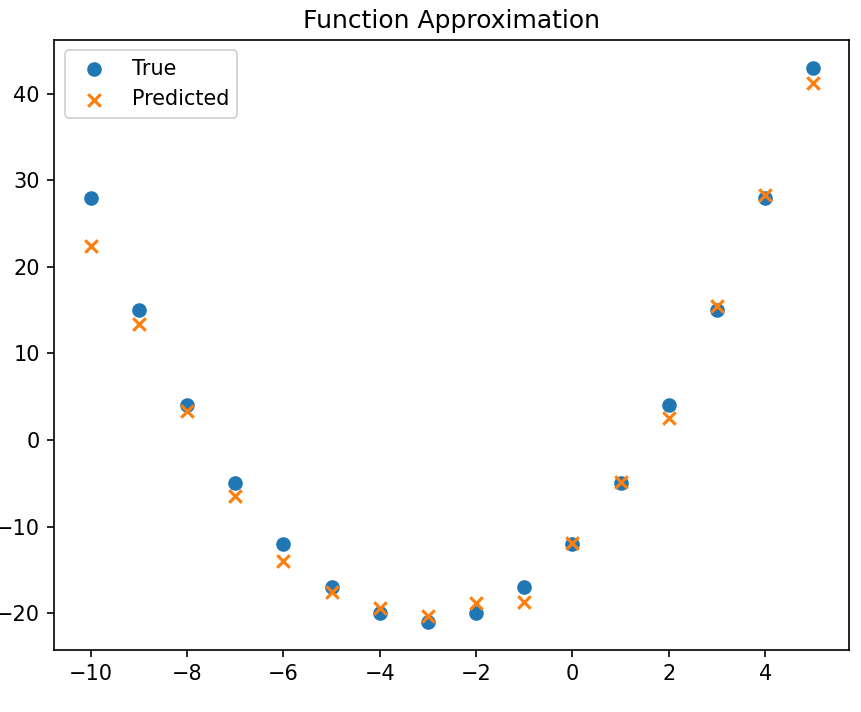
plt.scatter(x, y, label="True")
plt.scatter(x, net.forward(x), marker='x', label="Predicted")
plt.title("Function Approximation")
plt.legend()
plt.tight_layout()
plt.show()
train_model()
运行结果:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)