机器学习——主成成分分析(PCA)
优点:PCA能够保留数据集的大部分信息,通过选择少量的主成分来实现数据的降维,同时尽量减少信息损失。PCA能够找到数据中的主要方向,减少特征之间的相关性,有助于提高模型的性能。PCA的计算过程相对简单直观,能够快速处理大规模数据集。降维后的主成分具有很强的可解释性,有助于理解数据的结构和关系。缺点:即使PCA能够保留大部分信息,但在降维过程中仍然会存在一定程度的信息损失,特别是在选择较少主成分时。
目录
基本概念
主成分分析(Principal Component Analysis,PCA)是一种常用的降维技术,它可以将高维数据集转换为低维数据集,同时保留数据集中的主要特征。PCA的基本思想是通过找到数据中最大方差的方向,即主成分,来实现降维。
为什么做PCA
- 在很多场景中需要对多变量数据进行观测,在一定程度上增加了数据采集的工作量。并且多变量之间存在相关性,从而增加了问题分析的复杂性
- 对每个指标单独分析 ——> 分析结果是孤立的(不能完全利用数据的信息)
- 盲目减少指标 ——> 损失有用的信息,得出错误结论
- 在减少分析指标的同时,尽量减少原指标的信息的损失
- 可以考虑将关系紧密的变量变成尽可能少的新变量,使这些新变量是两两不相关的,那么就可以用较少的综合指标分别代表存在于各个变量中的各类信息
PCA的思想
假如我们的数据集是n维的,共有m个数据(x(1)(1),x(2)(2),...,x(m)(𝑚))。我们希望将这m个数据的维度从n维降到k维,希望这m个k维的数据集尽可能的代表原始数据集。我们知道数据从n维降到k维肯定会有损失,但是我们希望损失尽可能的小。那么如何让这k维的数据尽可能表示原来的数据呢?
我们先看看最简单的情况,也就是n=2,K=1,也就是将数据从二维降维到一维。数据如下图。我们希望找到某一个维度方向,它可以代表这两个维度的数据。图中列了两个向量方向,u1和u2,那么哪个向量可以更好的代表原始数据集呢?从直观上也可以看出,u1比u2好。
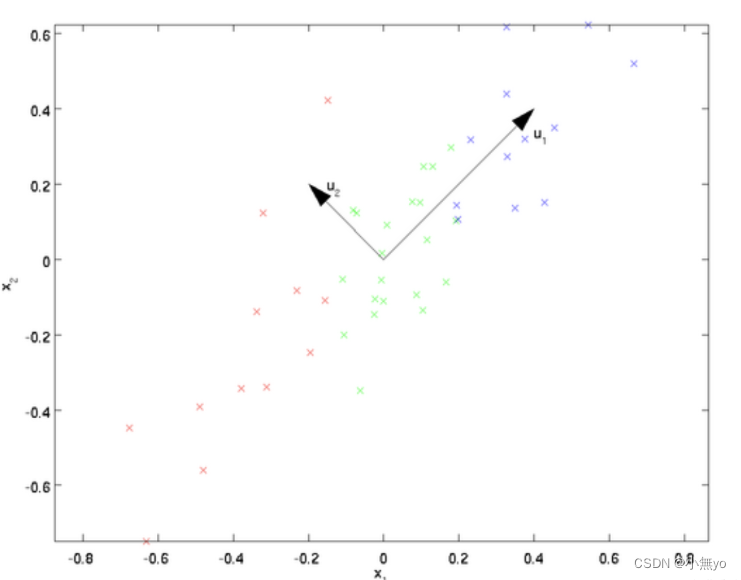
为什么u1比u2好呢?
可以有两种解释,第一种解释是样本点到这个直线的距离足够近,第二种解释是样本点在这个直线上的投影能尽可能的分开。
假如我们把K从1维推广到任意维,我们希望降维的标准为:样本点到这个超平面的距离足够近,或者说样本点在这个超平面上的投影能尽可能的分开。
简单实现降维操作
在Python中,可以使用scikit-learn库来实现PCA
import numpy as np
from sklearn.decomposition import PCA
# 创建示例数据集
X = np.array([[1, 2], [2, 3], [3, 4], [4, 5], [5, 6]])
# 实例化PCA对象并指定降维后的维度
pca = PCA(n_components=1)
# 拟合数据并转换
X_transformed = pca.fit_transform(X)
print("原始数据集形状:", X.shape)
print("降维后的数据集形状:", X_transformed.shape)
print(X_transformed)运行结果:
原始数据集形状: (5, 2)
降维后的数据集形状: (5, 1)
[[ 2.82842712]
[ 1.41421356]
[-0. ]
[-1.41421356]
[-2.82842712]]
算法分析
1.数据中心化
PCA依赖于协方差矩阵,而中心化数据可以确保协方差矩阵更好地反映数据的真实结构。
设原始数据矩阵为 (维度为
,其中
是样本数,
是特征数),中心化后的数据矩阵
计算如下:
其中, 是数据矩阵
的均值向量。
2.计算协方差矩阵
协方差矩阵用于衡量特征之间的相关性。协方差矩阵 的计算公式如下:
3. 计算特征值和特征向量
协方差矩阵的特征值和特征向量用于确定数据的主要方向和重要性。通过计算协方差矩阵的特征值和特征向量,我们可以找到数据在不同方向上的方差。
特征值(eigenvalue)表示主成分的重要性,而特征向量(eigenvector)表示主成分的方向。设协方差矩阵的特征值为 (从大到小排列),对应的特征向量为 。
4. 选择主成分
选择前 个最大的特征值对应的特征向量,构成新的低维空间。这里的 通常是通过累积解释方差(cumulative explained variance)来确定的。
累积解释方差定义为:
当累积解释方差达到某个阈值(例如95%)时,我们认为选取的主成分已经足够解释数据中的大部分信息。
5. 数据投影
将原始数据投影到选择的主成分方向上,得到降维后的数据。降维后的数据矩阵 ZZZ 计算如下:
其中, 是包含前
个特征向量的矩阵。
PCA的目标是找到数据在新的坐标系下的最优表示,使得数据在该坐标系下的投影方差最大化。通过选择最大的特征值对应的特征向量,PCA能够最大限度地保留数据的主要变化趋势,从而实现降维和去噪的目的。
代码实现
对图片进行降维处理:
当需要处理大量JPEG图像时,我们通常会面临到将它们转换为灰度图像、调整大小等操作。在这种情况下,PCA可以帮助我们降低数据的维度,同时保留图像的关键信息。通过选择适当数量的主成分,我们可以实现数据的压缩和降维,而不丢失太多有用的信息。
具体到实现上,我们可以加载一系列JPEG图像并将它们转换为灰度图像,然后调整大小以满足我们的需求。接着,利用PCA算法对这些图像进行降维处理,并选择合适数量的主成分进行重建。这样,我们就可以观察到降维后的效果,看看图像的重建是否保留了大部分原始信息。
import os
from PIL import Image
import numpy as np
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
image_dir = 'E:\\picture\\' # 替换为您的图像目录
# 加载多个图像样本
images = []
for filename in os.listdir(image_dir):
if filename.endswith('.jpg'): # 假设你的图像是jpg格式的
img_path = os.path.join(image_dir, filename)
img = Image.open(img_path).convert('L').resize((32, 32)) # 转换为灰度并调整大小
images.append(np.array(img).flatten())
# 将图像列表转换为NumPy数组
X = np.array(images)
# 选择一个图像来重建,索引第一个图像
image_index = 0
# 应用PCA
pca = PCA(n_components=4, svd_solver='randomized', whiten=True)
# 拟合PCA模型并转换所有图像样本
X_transformed = pca.fit_transform(X)
# 重建选定的图像
reconstructed_image = pca.inverse_transform(X_transformed[image_index:image_index + 1]).reshape(32, 32)
# 绘制重建的图像
plt.imshow(reconstructed_image, cmap='gray')
plt.title('Reconstructed Image with 4 Components')
plt.axis('off')
plt.show()
运行结果:
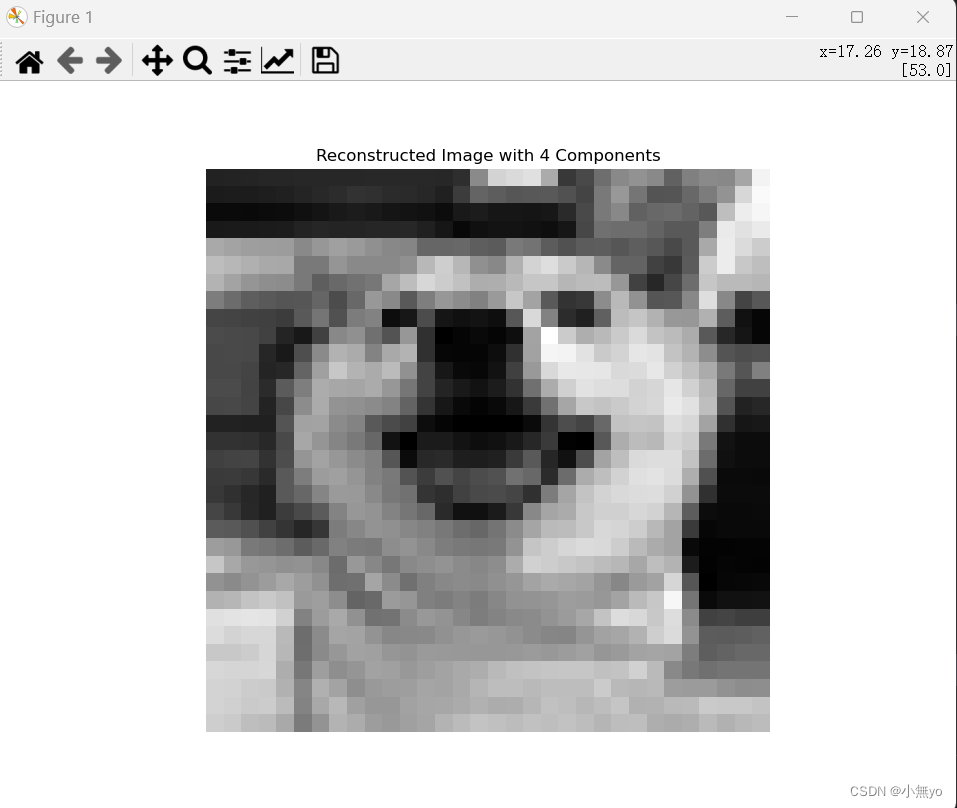
原图:

总结
优点:
- 降维效果好: PCA能够保留数据集的大部分信息,通过选择少量的主成分来实现数据的降维,同时尽量减少信息损失。
- 去相关性: PCA能够找到数据中的主要方向,减少特征之间的相关性,有助于提高模型的性能。
- 计算简单: PCA的计算过程相对简单直观,能够快速处理大规模数据集。
- 可解释性强: 降维后的主成分具有很强的可解释性,有助于理解数据的结构和关系。
缺点:
- 信息损失: 即使PCA能够保留大部分信息,但在降维过程中仍然会存在一定程度的信息损失,特别是在选择较少主成分时。
- 对异常值敏感: PCA对数据中的异常值比较敏感,可能会影响降维结果。
- 线性假设: PCA基于对数据的线性变换,因此对于非线性数据的降维效果可能不佳。
- 计算复杂度: 对于非常大的数据集,PCA的计算复杂度可能会变得较高,需要较多的计算资源和时间。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 30
30 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)