【长尾学习】Context-rich Minority Oversampling for Long-tailed Classification 论文阅读
The Majority Can Help the Minority: Context-rich Minority Oversampling for Long-tailed Classification 论文笔记
·
目录
| Title | The Majority Can Help the Minority: Context-rich Minority Oversampling for Long-tailed Classification |
|---|---|
| Authors | Seulki Park, Youngkyu Hong, et.al. 首尔国立大学、NAVER AI Lab |
| Publication | CVPR 2022 |
| Tag | Transfer Learning + Data Augmentation |
| Code | https://github.com/naver-ai/cmo |
| Contribution | 多张多数类充当一张少数类图片的背景来扩充少数类样本的数量 |
1. Abstract
1.1 先前的问题
-
重复地对少数类进行超采样会加剧过拟合,这是因为重复选择的样本不够具有多样性,而且图片上下文背景几乎相同。如下图所示:

-
先前的重新采样策略都忽略了多数类中蕴含的丰富的上下文背景信息,本文就是要充分利用多数类中的这些上下文背景信息来生成更多新的少数类图片。
1.2 解决方案
-
核心思想:提出一种全新的少数类超采样策略 Context-rich Minority Oversampling (CMO) 。把少数类的一张图片 “粘贴” 到多张上下文背景丰富 (rich-context) 的多数类图片上,让这些多数类的图片充当背景。这样,一张少数类图片就能超采样成背景不一样的多张新图片了。
-
如下图所示,一张少数类的白鹅生成了 4 张背景不同的新样本:

-
优点:方法简单,易于与现有的长尾识别方法结合;
2. 研究灵感来源
-
论文原文:CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features (ICCV, 2019)
-
原文缺点:直接套用 CutMix 到长尾学习中会加剧多数类的过拟合。这是因为该策略可能会生成更多以多数类为中心的图片,而 ”粘贴“ 到上面的少数类反而容易成了背景。
-
优化方案:本文通过对不同分布的背景图片和前景块进行采样来解决这个问题。
3. Details
3.1 算法

3.2 一些由CMO生成的少数类图片

4. Experience
4.1 实验条件
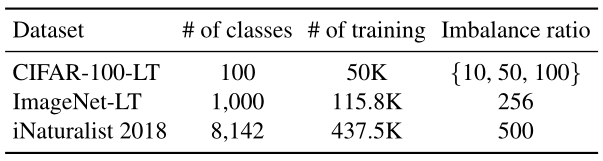
① 数据集
| 数据集名称 | 描述 |
|---|---|
| CIFAR-100-LT | 基于 CIFAR-100 人工制作成长尾分布的数据集 |
| ImageNet-LT | 基于 ImageNet-2012 人工制作成长尾分布的数据集 |
| iNaturalist 2018 | 大规模的真实世界数据集,天然地表现出长尾的不平衡性 |
② 评价指标
-
使用 top-1 准确率;
-
同时还划分了三个子集的准确率:
评价指标 描述 头部类准确率 训练样本数量在100个以上的类别的平均精度 中部类准确率 训练样本数量在20 ~100个的类别的平均精度 尾部类准确率 训练样本数量在20个以下的类别的平均精度
③ 实验参数
| 数据集 | CIFAR-100-LT | ImageNet-LT | iNaturalist 2018 |
|---|---|---|---|
| 主干网络 | ResNet-32 | ResNet-50 | ResNet-{50, 101, 152} 和 Wide ResNet50 |
| epochs | 200 | 100 | 200 |
| 学习率 | 0.1,在60和80epoch衰减 | 0.1,在60和80epoch衰减 | 0.1,在75和160epoch衰减 |
| 权重更新策略 | SGD | SGD | SGD |
| momentum | 0.9 | 0.9 | 0.9 |
4.2 三个长尾基准的有效性
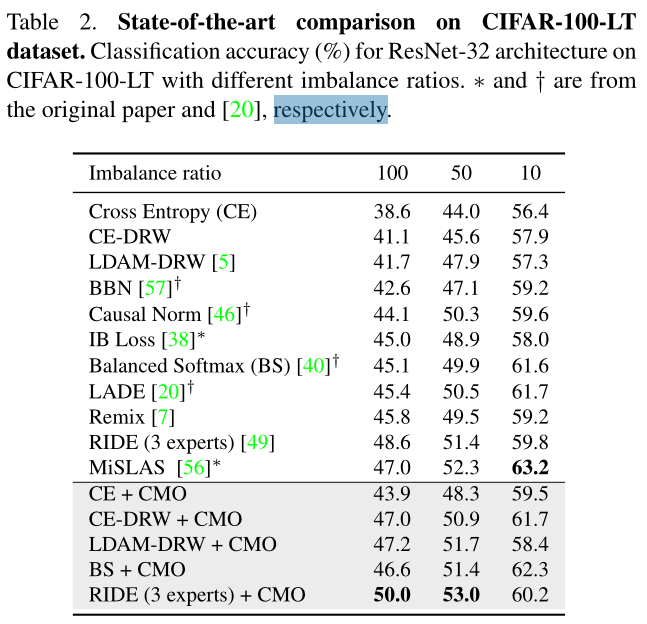
① CIFAR-100-LT

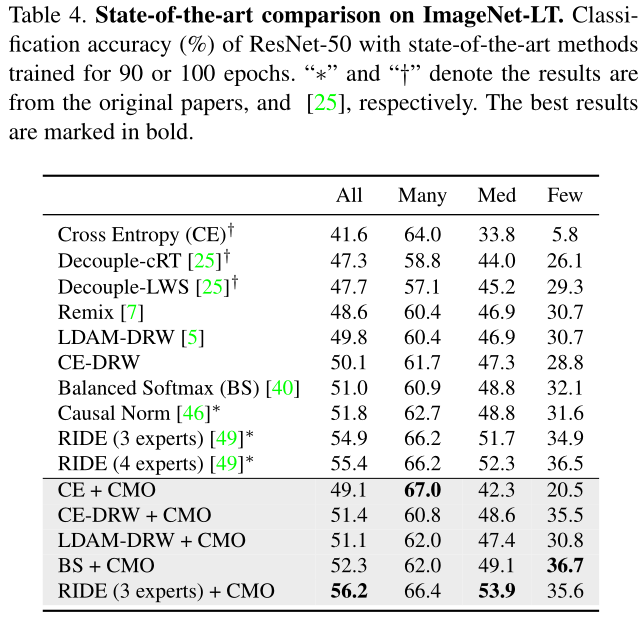
② ImageNet-LT

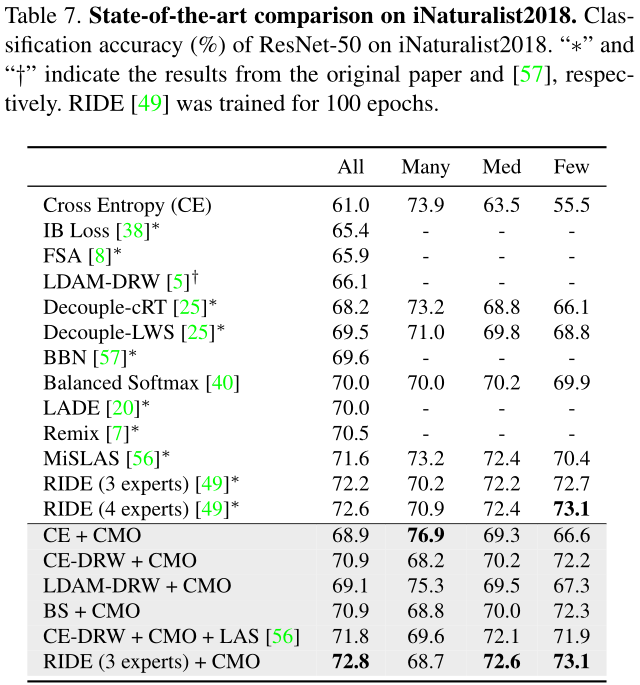
③ iNaturalist 2018

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)