【X3 input_layout_rt】地平线X3开发板 模型转换期间config.yaml文件中的input_layout_rt踩坑记录
文章目录1 问题描述2 问题分析3 hb_model_verifier验证 quanti onnx 和 bin模型 的一致性4 网络模型本身有问题?5 模型转换工具链使用的问题?6 思考与建议7 附上一些很好的踩坑文章仅以此文感谢师弟 闪电侠的右手,并记录bug调试过程。1 问题描述之前有写过文章:将pytorch生成的onnx模型转换成.bin模型,其中,在获取.bin模型时,把yaml文件中i
文章目录
仅以此文感谢师弟 闪电侠的右手,并记录bug调试过程。
1 问题描述
之前有写过文章:将pytorch生成的onnx模型转换成.bin模型,其中,在获取.bin模型时,把yaml文件中input_parameters:下的input_layout_rt参数设置为NCHW,因为在注释指导中说NHWC与NCHW都可以,但经验证发现,这儿只能是NHWC!
5分类任务,rgb图片输入,pytorch训练,板子部署亦采用rgb作为颜色空间,layout均设置为NCHW,模型转换后,在docker中验证quantized_model.onnx模型,精度正常,但上板运行.bin模型,准确率极低。
2 问题分析
在转换成onnx模型之后,hb_mapper makertbin会自动执行optimize和quantize的操作,最后生成可以运行在开发板上的的.bin异构模型。
对于hb_mapper makertbin生成.bin模型期间的中间产物:optimized_float_model.onnx和quantized_model.onnx,不需要在图片preprocessing的时候写normalize(减均值、除方差==乘scale)了,经过确认,hb_mapper makertbin会在输入层创建一个normalization层(因为在yaml文件中添加了norm_type、mean_value、scale_value三个参数),保存到model.onnx文件中。
注意: 生成的model.onnx文件,输入数据范围是0~255。
了解到这些点,推测不是代码前后处理的问题。
那要么是网络模型本身有问题(见第4节),要么是模型转换的工具链出了问题(见第5节)。
此时 大佬勇哥 建议我用hb_model_verifier工具验证一下 quanti onnx 和 bin模型的一致性对齐,先去验证一下。
3 hb_model_verifier验证 quanti onnx 和 bin模型 的一致性
运行时,开发机和开发板用网线连接,且处于同一网段内。
对于单模型输入,参照 hb_mapper_tools_guide 中 hb_model_verifier 工具使用方式,在docker中运行如下命令:
在运行过程中,出现以下产物:
最后提示的错误为:error arm result does not exist, program halted
是什么原因导致没有找到板端结果文件?无法验证模型一致性的问题。
回答:原因是实验室的开发机使用docker后,无法ping通开发板。
4 网络模型本身有问题?
怀疑是resnet的relu出了问题,因为量化时relu的正方向的最大值是没有限制的,量化可能会有溢出,所以考虑用带relu6的mobilenetv2网络重新训练。
重新部署后问题依旧存在。
5 模型转换工具链使用的问题?
问题锁定到工具链上,有一个位置让我和师弟都非常困惑,明明设置所有涉及到NCHW/NHWC的地方,都设置为NCHW,为什么还会显示compile出来的网络是NHWC的?
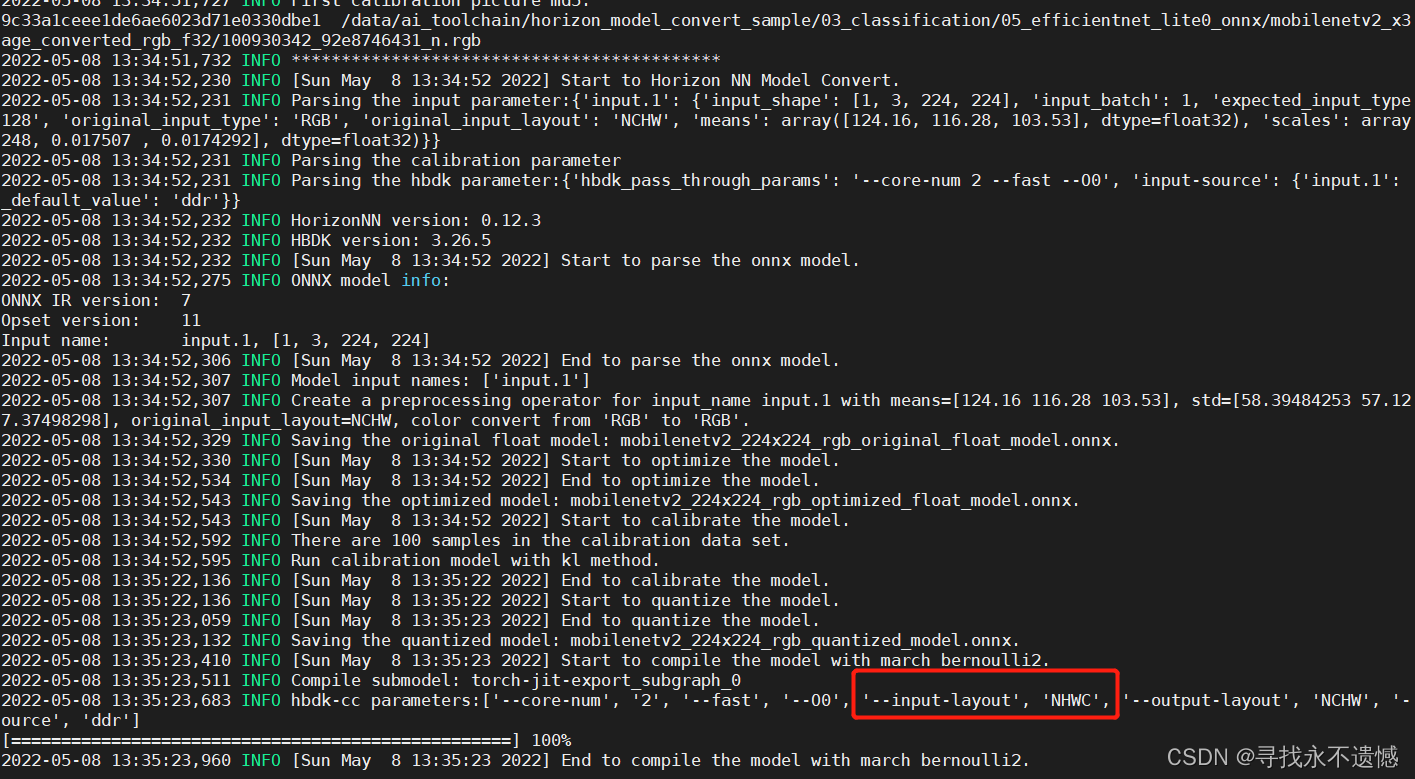
config.yaml文件中compiler_parameters并没有列出input-layout设置情况,但是这里却打印出来了,那我手动指定成NCHW是不是可以解决这个问题?
结果非常的显而易见,报错了。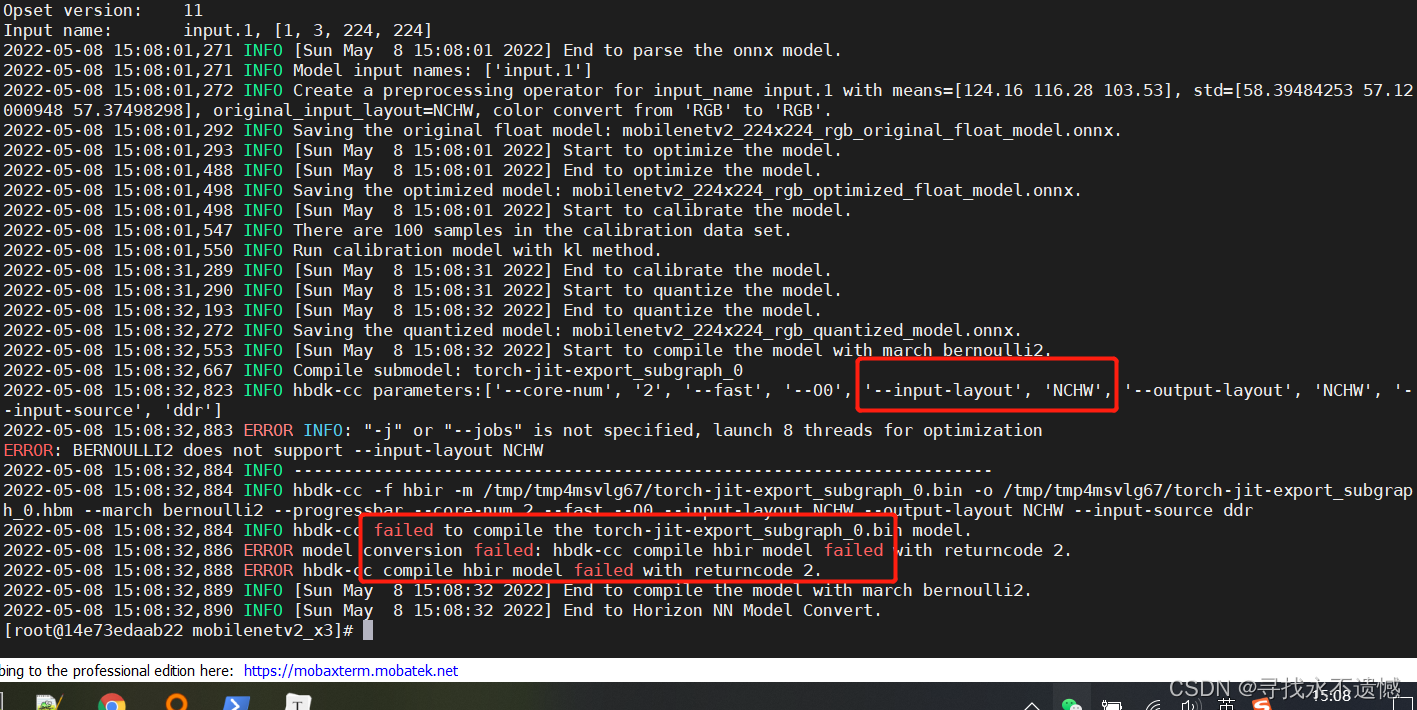
那与bin的input-layout直接相关的参数有什么?查看了整个config文件以及user guide,发现只有一个config.yaml中的input_parameters的input_layout_rt。
在指导手册horizon_ai_toolchain_user_guide/chapter_3_model_conversion.html#model-conversion中,很清晰的描述了input_layout_rt的含义。
而且写了X/J3平台建议使用NHWC格式!虽然我还是头铁。
问题大概知道了,直接将config文件的input_layout_rt改为NHWC,重新编译,执行,bug解决!
6 思考与建议
-
地平线的onnx的优化很有趣,其他的推理引擎比如针对arm的tengine并不会把normalize直接写入到模型的层中,猜测是因为BPU可以对这部分进行优化,而其他的推理引擎这里可能使用的是CPU执行的。
-
float的onnx和优化后的onnx是NCHW的,而量化后的onnx的输入layout和bin的输入layout是NHWC的。bin中使用NHWC,可能是为了加快效率,因为opencv读入的shape就是channel last的,这样就不需要用cpu单独执行一次transpose操作了。
-
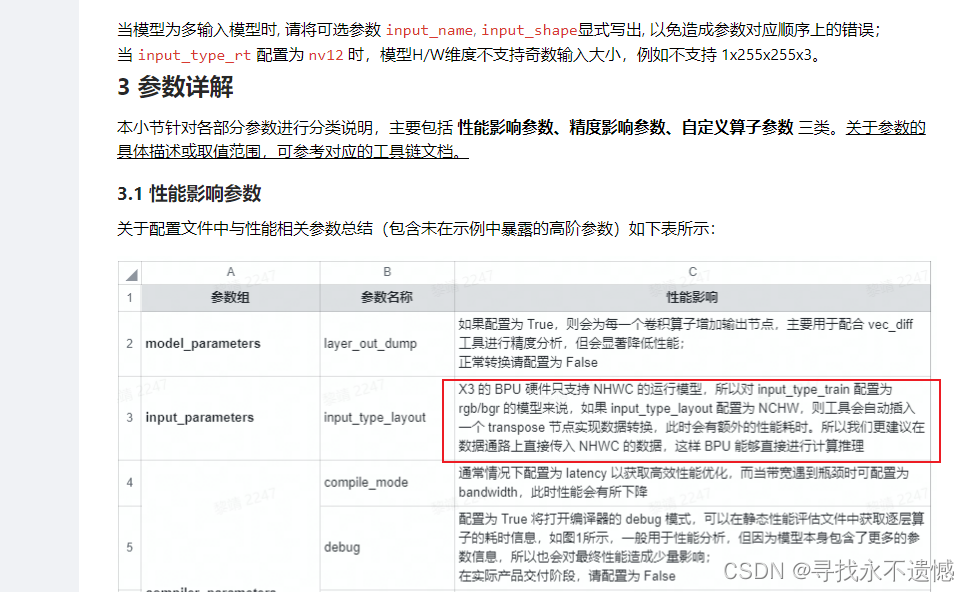
对于新版工具链yaml配置文件参数详解一文中提到的
input_type_layout参数,指出如果我们把input_layout_rt参数设置为NCHW,会因为自动插入transpose节点而耗时,实测时,发现所谓的自动插入transpose节点并没有起到该有的作用,bin模型的准确率骤降!不论板端运行时,是否自己进行transpose变换,预测结果都是错的,因为input_layout_rt参数设置为NCHW时,编译出来的模型是有问题的或者是编译期间的代码逻辑有点问题!(猜测)
只有把input_layout_rt参数设置为NHWC时,编译出来的.bin模型才正常,此时不论在板端传入.bin模型的数据是NCHW还是NHWC,都能正确预测。
故此处不如直接把input_layout_rt参数作为非选择性参数,告诉开发者们这儿是NHWC更好。
7 附上一些很好的踩坑文章

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)