穿越神经网络的迷雾:深度学习前馈神经网络实验(手动+torch.nn)揭秘
穿越神经网络的迷雾:深度学习前馈神经网络实验揭秘
深度学习,作为人工智能的先锋之一,其背后的神经网络技术一直是学术界和工业界的焦点。而其中的前馈神经网络(Feedforward Neural Network)更是深度学习的基石之一,为计算机实现了从感知到认知的巨大飞跃。在这篇博客中,我们将一同踏足深度学习的迷雾,揭开前馈神经网络的神秘面纱,通过实验一窥其奥妙。
一、任务1:线性回归
1.1 任务内容
-
任务具体要求
- 手动生成回归任务的数据集,要求:
- 生成单个数据集
- 数据集的大小为10000且训练集大小为7000,测试集大小为3000
- 数据集的样本特征维度p为500,且服从如下的高维线性函数:y=0.028+∑i=1p0.0056xi+εy=0.028+\sum_{i=1}^{p} 0.0056x_i + \varepsilony=0.028+i=1∑p0.0056xi+ε
- 手动实现前馈神经网络解决上述回归任务
- 利用torch.nn实现前馈神经网络解决上述回归任务
- 手动生成回归任务的数据集,要求:
-
任务目的
- 通过手动生成回归任务的数据集,实践数据集构建的基本技能,并确保数据集满足指定要求,以便后续训练和测试神经网络模型
- 通过手动实现前馈神经网络,掌握基本的神经网络构建和训练过程,加深对神经网络原理的理解
- 利用PyTorch中的torch.nn模块,通过现有工具和框架更便捷地构建和训练前馈神经网络,提高效率并验证手动实现的结果
-
任务算法或原理介绍
由于任务的标签为连续值,故采用线性回归算法。线性回归是一种常见的统计学习方法,用于建立自变量(特征)与因变量(目标)之间的线性关系模型,使得模型能够对新的自变量进行预测。
- 数学模型:线性回归模型可以表示为 y=∑i=1pWixi+by = \sum_{i=1}^{p} W_ix_i+ b y=i=1∑pWixi+b 其中 yyy 是因变量(标签),xix_ixi 是自变量(特征),ppp为特征的维度,WiW_iWi 是模型的参数
- 学习准则:最小化 1N∑i=1N(yi−yi^)2\frac{1}{N}\sum_{i=1}^{N} (y_i - \hat{y_i})^2N1∑i=1N(yi−yi^)2,其中 NNN 是样本数量,yiy_iyi 为真实标签,yi^\hat{y_i}yi^ 是模型的预测值
- 模型评估:使用均方误差(Mean Squared Error,MSE)即损失函数值作为评价指标。均方误差取值范围大于0,在泛化性能一定的条件下,越接近0表示模型拟合效果越好
-
任务所用数据集
人工构造数据集
1.2 任务思路及代码
-
手动生成回归任务的数据集
使用Pytorch的randn函数生成随机的特征维度为500的数据(X),该函数生成来自标准正态分布的样本,然后使用Pytorch的torch.normal函数生成均值为0,标准差为0.01噪声(epsilon),该函数生成来自正态(高斯)分布的样本,基于一个高维线性函数和添加噪声,创建目标变量(y)
-
手动实现前馈神经网络:
- 设置超参数:BATCHSIZE(每个批次的样本数量)、INPUT_DIM:(输入特征的维度)、HIDDEN_DIM(隐藏层的维度)、OUTPUT_DIM(输出的维度)、LR(学习率)、EPOCH(训练的轮数)
- 数据处理:使用 PyTorch 的 TensorDataset 和 DataLoader 构建数据迭代器,然后分别创建训练集和测试集的数据迭代器,用于训练和评估模型
- 定义手动实现的回归模型类Regression_Net1:首先初始化模型参数(权重和偏置),然后定义模型的结构,包括输入层、隐藏层(使用 ReLU 激活函数)、输出层,其中还需要手动实现的 ReLU 激活函数,最后实现包含前向传播方法 forward
- 定义自定义的随机梯度下降优化函数 mySGD:用于手动更新模型参数
- 定义均方误差损失函数 mse:用于计算模型预测值与真实值之间的均方误差
- 模型训练:实例化化模型 Regression_Net1,使用均方误差作为损失函数,然后遍历训练集,进行前向传播、损失计算、反向传播和参数更新,记录每个 epoch 的训练集和测试集上的损失,输出每 10 个 epoch 的训练和测试损失以及训练时间
-
torch.nn实现前馈神经网络
使用了 PyTorch 的高级接口 nn.Module 构建了一个前馈神经网络,包括输入层、隐藏层(包含 ReLU 激活函数)、输出层,使用均方误差损失函数 nn.MSELoss 作为模型的损失函数,使用优化器 torch.optim.SGD 对模型参数进行优化,通过随机梯度下降进行训练,并记录了训练和测试过程中的损失值
手动生成回归任务数据集
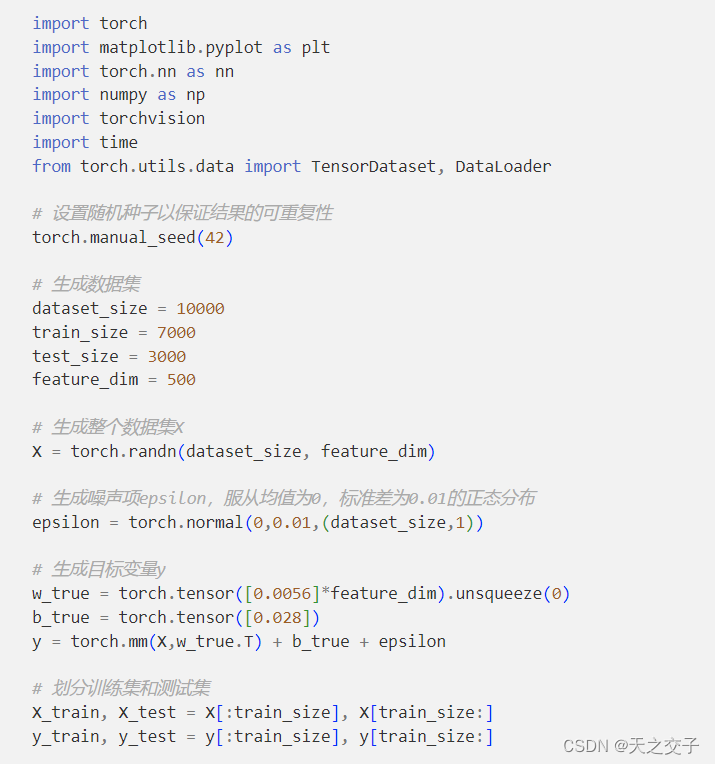
1.3 实验结果分析
1.3.1 实验结果分析1
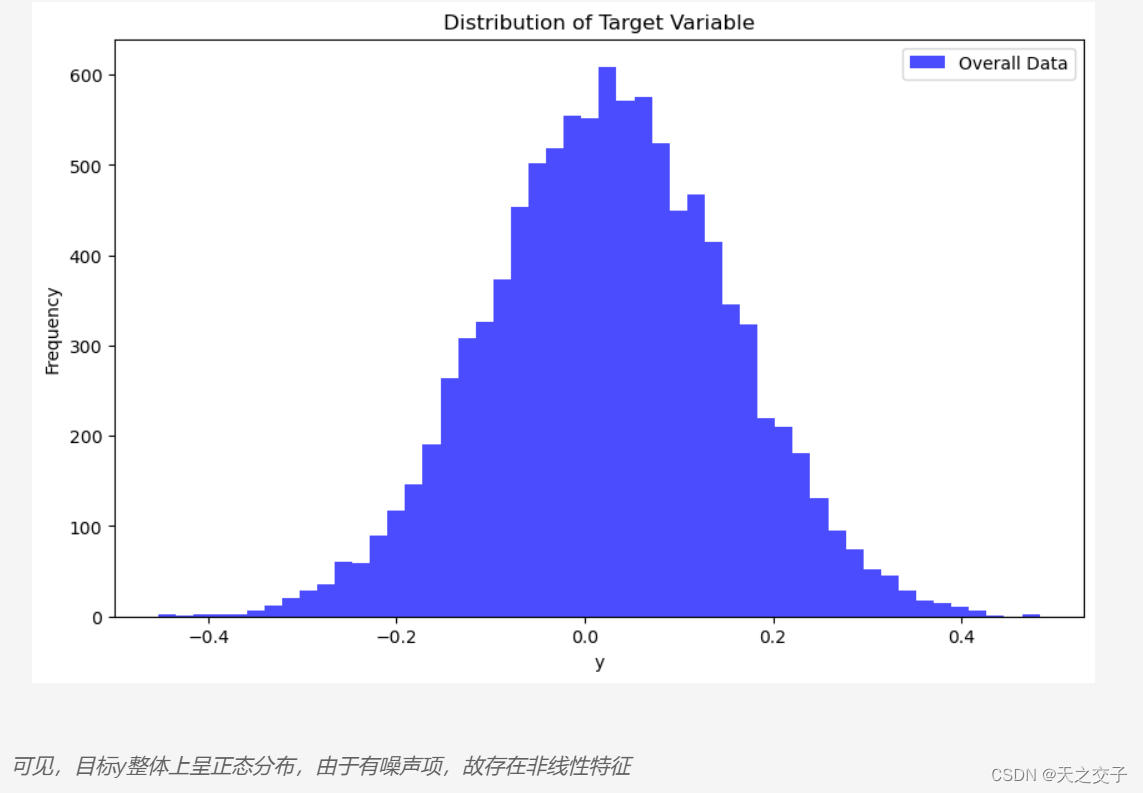
1.3.2 实验结果分析2
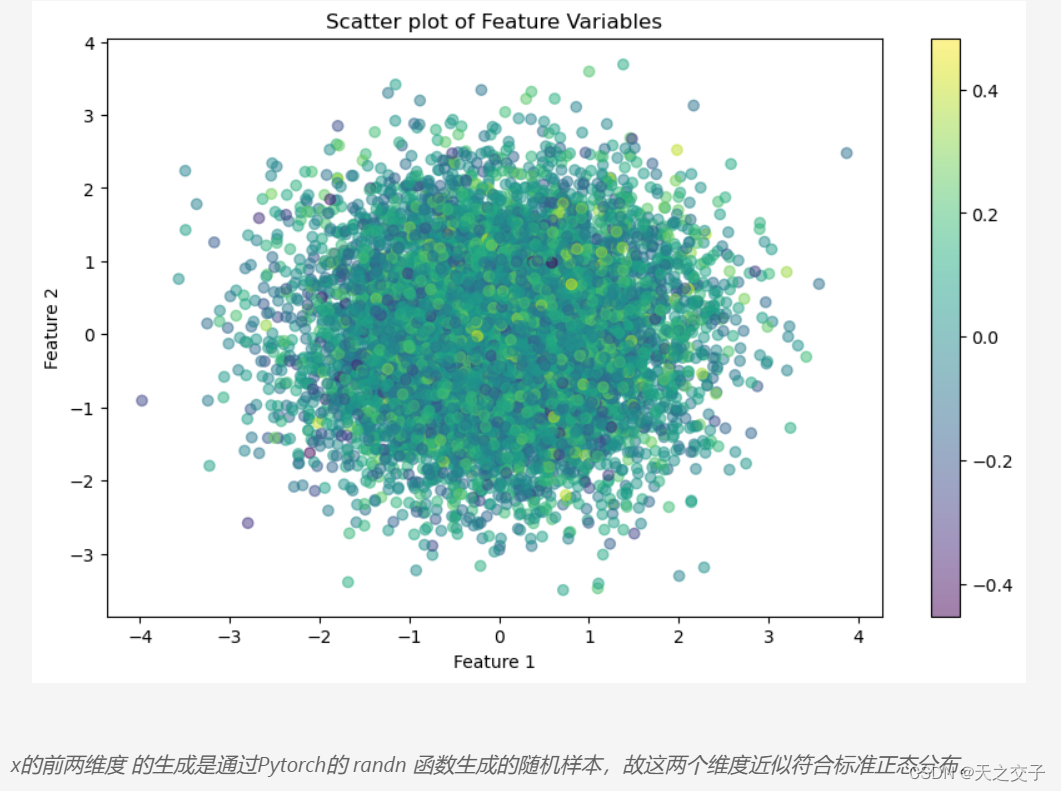
手动实现前馈神经网络
# 超参数
BATCHSIZE = 64
INPUT_DIM = 500
HIDDEN_DIM = 256
OUTPUT_DIM = 1
LR = 0.01 #学习率
EPOCH = 100
# 数据迭代器
train_dataset = TensorDataset(X_train, y_train)
test_dataset = TensorDataset(X_test , y_test)
train_loader = DataLoader(dataset=train_dataset, batch_size=BATCHSIZE, shuffle=True, num_workers=0)
test_loader = DataLoader(dataset=test_dataset , batch_size=BATCHSIZE, shuffle=False, num_workers=0)
## 手动实现回归模型及其前向传播过程
class Regression_Net1():
def __init__(self):
# 定义并初始化模型参数
W1 = torch.tensor(torch.normal(0, 0.01, (HIDDEN_DIM, INPUT_DIM)), dtype=torch.float32,requires_grad=True)
b1 = torch.zeros ((1,HIDDEN_DIM), dtype=torch.float32,requires_grad=True)
W2 = torch.tensor(torch.normal(0, 0.01, (OUTPUT_DIM, HIDDEN_DIM)), dtype=torch.float32,requires_grad=True)
b2 = torch.zeros ((1,OUTPUT_DIM), dtype=torch.float32,requires_grad=True)
self.params=[W1,b1,W2,b2]
# 定义模型的结构
self.inputs_layer = lambda x: x.view(x.shape[0],-1)
self.hiddens_layer = lambda x: self.my_ReLU(torch.matmul(x, W1.t())+ b1)
self.outputs_layer = lambda x: torch.matmul(x, W2.t())+ b2
@staticmethod
def my_ReLU(x):
return torch.where(x>0,x,0)
def forward(self, x):
flatten_input = self.inputs_layer(x)
hidden_output = self.hiddens_layer(flatten_input)
final_output = self.outputs_layer(hidden_output)
return final_output
手动实现损失函数和优化器
def mySGD(params, lr):
for param in params:
param.data -= lr * param.grad
def mse(y_hat,y):
loss = torch.mean((y_hat-y)**2)
return loss
模型训练与评估
输出如下:
1.3.3 实验结果分析3(LOSS)
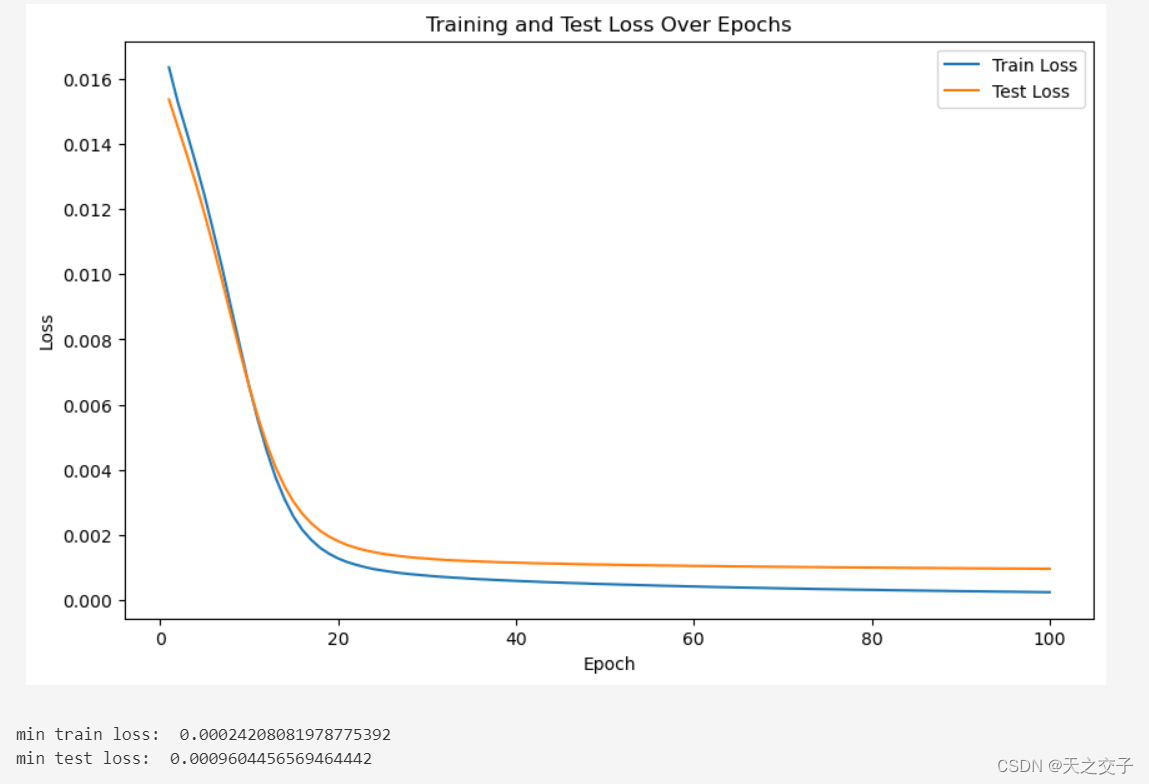
结果将从以下六个方面进行分析:
- 变化趋势:
随着训练轮数(epoch)的增加,训练集和测试集上的损失都呈现逐渐减小的趋势。这表明模型在学习过程中逐渐提高了对训练和测试数据的拟合能力。 - 最小值:
最终的训练损失和测试损失都非常小,接近于零。这说明模型在训练集和测试集上都能够取得很好的拟合效果。 - 模型性能:
由于损失是回归任务中模型性能的度量,最小化损失意味着模型在训练数据和测试数据上都取得了较好的性能。训练损失和测试损失的趋势相似,说明模型没有出现过拟合的情况,即在测试集上的表现与在训练集上的表现一致。 - 收敛速度:
初始阶段,损失下降较为迅速,随着训练的进行,下降速度逐渐减缓。这是一个正常的训练现象,模型在初始阶段更容易学到数据的一般特征,而随着训练的进行,学习到的信息逐渐变得更加细致和复杂。 - 训练集和测试集上的损失:
在整个训练过程中,训练损失一般会小于测试损失,因为模型是根据训练数据进行优化的。然而,两者的趋势是一致的,而不是出现训练集上损失下降而测试集上损失升高的情况。 - 训练时间:
训练时间基本保持在每10个epoch用时3s的速度左右
总体来说,曲线的变化趋势表明模型在训练中逐渐学到了数据的模式,取得了良好的性能。最终的极小化的损失值表明模型在训练集和测试集上都取得了很好的拟合效果。
torch.nn实现前馈神经网络
class Regresssion_Net2(nn.Module):
def __init__(self):
super().__init__()
self.input_layer=lambda x:x.view(x.shape[0],-1)
self.hidden_layer=nn.Sequential(
nn.Linear(INPUT_DIM,HIDDEN_DIM),
nn.ReLU()
)
self.output_layer=nn.Linear(HIDDEN_DIM,OUTPUT_DIM)
# 初始化参数
for h_param in self.hidden_layer.parameters():
torch.nn.init.normal_(h_param,mean=0,std=0.01)
for o_param in self.output_layer.parameters():
torch.nn.init.normal_(o_param,mean=0,std=0.01)
def forward(self,x):
x=self.input_layer(x)
h=self.hidden_layer(x)
out=self.output_layer(h)
return out
# 模型实例化、确定损失函数和优化器
model=Regresssion_Net2()
criterion = nn.MSELoss()
optimizer=torch.optim.SGD(model.parameters(),lr=LR)
train_all_loss2, test_all_loss2 = [], [],
begin = time.time()
for epoch in range(EPOCH):
train_l,test_loss = 0.0,0.0
# 训练模型
for x,y in train_loader: # x和y分别是小批量样本的特征和标签
y_hat = model(x)
loss=criterion(y_hat,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_l += loss.item()
train_all_loss2.append(train_l/len(train_loader))
# 测试模型
with torch.no_grad():
for x,y in test_loader:
y_hat=model(x)
loss=criterion(y_hat,y)
test_loss+=loss.item()
test_all_loss2.append(test_loss/len(test_loader))
# 每10步打印loss和time
if epoch==0 or (epoch+1)%10==0:
print('epoch %d, train loss: %f, test loss: %f, time: %.1f sec'%(epoch+1,train_all_loss2[-1],test_all_loss2[-1],time.time() - begin))
输出如下:
1.3.4 实验结果分析4
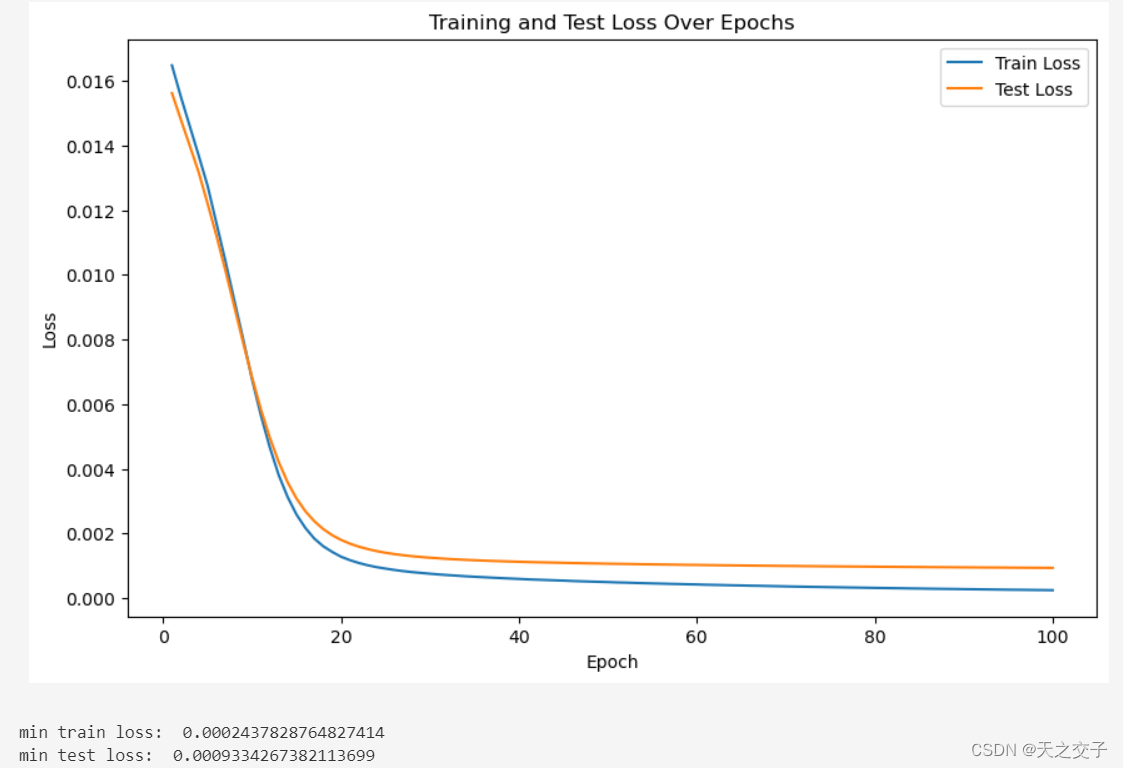
用torch.nn实现的前馈神经网络结果与手动实现的结果比较:
二者变化趋势、最小值、模型性能、收敛速度、训练时间都表现一致,可见手动实现的神经网络模型和训练逻辑没有明显的错误,同时,证明了 PyTorch 框架内部的一致性和可靠性以及 PyTorch 框架在底层实现上的正确性,二者相互印证
两种实现方式的指标记录如下,由表可知,两种方式实现的前馈神经网络经过同样的训练,可以达到几乎一致的性能,不过torch.nn实现的指标略优于手动实现,这可能是由于torch.nn 内部使用了更多的优化和底层操作,可以更好地利用 GPU 进行加速,从而提高训练效率
| min train loss | min test loss | |
|---|---|---|
| 手动实现 | 0.0002420 | 0.0009604 |
| torch.nn实现 | 0.0002437 | 0.0009334 |
二、任务2:二分类任务
2.1 任务内容
-
任务具体要求
- 手动生成二分类任务的数据集,要求:
- 共生成两个数据集
- 两个数据集的大小均为10000且训练集大小为7000,测试集大小为3000
- 两个数据集的样本特征x的维度均为200,且分别服从均值互为相反数且方差相同的正态分布
- 两个数据集的样本标签分别为0和1
- 手动实现前馈神经网络解决上述二分类任务
- 利用torch.nn实现前馈神经网络解决上述二分类任务
- 手动生成二分类任务的数据集,要求:
三、任务3:多分类任务
3.1 任务内容
-
任务具体要求
- 下载MNIST手写体数据集
- 手动实现前馈神经网络解决上述多分类任务
- 利用torch.nn实现前馈神经网络解决上述多分类任务
- 在多分类任务中使用至少三种不同的激活函数,进行对比实验并分析实验结果
- 对多分类任务中的模型评估隐藏层层数和隐藏单元个数对实验结果的影响,使用不同的隐藏层层数和隐藏单元个数,进行对比实验并分析实验结果
代码实在是太多了,下方链接放了完整版代码:
https://www中文.jdmm.cc/file/2709899/(删掉中文)
通过这篇博客,希望读者能够更全面地理解深度学习前馈神经网络,并为进一步的研究和实践打下坚实的基础。愿你在这趟穿越神经网络的旅程中,发现属于自己的探索之路。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)