机器学习-线性回归
正则化回归是解决。
在机器学习与统计建模中,线性回归是最基础且广泛使用的算法之一。然而,传统的普通最小二乘法(OLS) 回归存在两个主要问题:
-
过拟合:当特征数量(p)接近或超过样本量(n)时,模型容易过度拟合噪声。
-
多重共线性:当特征高度相关时,OLS估计的系数可能不稳定,甚至无法计算。
为了解决这些问题,统计学家提出了正则化回归方法,包括:
-
岭回归(Ridge Regression)(L2正则化)
-
Lasso回归(Lasso Regression)(L1正则化)
-
弹性网络(Elastic Net)(L1 + L2组合)
本文将深入探讨它们的数学原理、优缺点、适用场景及应用,并通过对比帮助读者选择最合适的回归方法。
1. 线性回归回顾
1.1线性回归模型构建
在数据分析中,若存在一个包含 n 个观测样本 的数据集,且每个样本对应 p 个自变量 。假设因变量 y 与这 个自变量
之间存在 线性关系 ,则第 i 个样本(i=1,2,⋯,n)的线性回归模型可表示为:
- 因变量观测值:
代表第 i 个样本的实际观测值。
- 自变量取值:
表示第 i 个样本中第 j 个自变量的具体数值。
- 回归系数:
是待求解的参数。其中,
为截距项,意味着所有自变量取值为 0 时因变量的值;
衡量了第 j 个自变量每变动一个单位,对因变量 y 产生的平均影响程度。
- 随机误差项:
涵盖了模型未考虑到的因素及测量误差。
1.2 OLS 的优化目标与数学表达
OLS 的核心任务是确定一组最优的回归系数向量 ,使 观测值 与 预测值 之间的 误差平方和(RSS) 达到最小。
- 预测值计算:对于第 i 个样本,模型预测值
通过公式得到。
- 残差定义:残差
表示观测值与预测值的差值,即
。
- 残差平方和(RSS):将所有样本的残差平方求和,得到
。
为简化计算,将上述公式转化为矩阵形式。具体步骤如下:
设 为因变量观测向量;
是一个
的自变量特征矩阵,其具体形式为:
其中第一列全为 1,对应截距项 ,后续各列依次为各样本的自变量取值;
为回归系数向量。根据矩阵乘法规则,
计算如下:
可以看到,得到的结果向量中的每个元素,恰好是线性回归模型对各样本的预测值
。
那么观测值向量 与预测值向量
的差为:
根据向量 L2 范数平方的定义,,其展开形式为:
因此,OLS 的优化目标:最小化观测值与预测值之间的误差平方和,可写成矩阵形式:
其中,通过求解该最小化问题,就能得到最优的回归系数向量 ,实现对因变量的最佳线性拟合。
1.3 回归系数的求解与统计性质
通过对目标函数 关于 β 进行 矩阵求导 并令导数为 0,可推导出回归系数 β 的估计值
。在满足 误差项独立同分布、均值为 0 且方差恒定 等假设条件下,OLS 估计具备 无偏性(估计值的期望等于真实参数)和 有效性(在所有线性无偏估计中,方差最小)。
1.4 OLS 在实际应用中的局限性
1.4.1 特征数量大于等于样本数量时无解或不唯一
- 数学层面:根据回归系数计算公式
,当特征数量 p≥样本量 n 时,
是 (p+1)×(p+1) 的矩阵,且其秩 rank(
。
- 数据层面:样本数量不足,难以准确识别每个自变量对因变量的独特影响,此时模型易 过度拟合 训练数据中的噪声,在新数据上预测效果差。
1.4.2 多重共线性导致系数估计不稳定
当自变量间存在高度相关性(如研究房价时,“房屋面积” 和 “房间数量” 高度正相关),尽管 可逆,但其 行列式值极小 ,使得
的元素值大幅增大。在计算
时,样本数据或误差项的微小波动,会因
的放大作用,导致回归系数
剧烈变动。同时,自变量间的相互干扰使 OLS 无法准确区分各自对因变量的贡献,可能出现 系数符号错误 或 解释与实际相悖 的情况 ,例如本应正相关的自变量,估计系数却为负。
2. 岭回归(Ridge Regression)
2.1 原理
岭回归在OLS的基础上引入L2正则化项,目标函数变为:
其中:
-
λ≥0 是正则化强度参数(λ越大,系数收缩越强)
-
是L2范数,即回归系数向量。
2.2 特点
✅ 优点:
-
解决多重共线性问题(即使
不可逆,岭回归仍有解)。
-
系数整体收缩,但不会归零(保留所有特征)。
-
对异常值比Lasso更稳健。
❌ 缺点:
-
不会进行特征选择(所有变量都保留)。
-
可能会过度收缩其系数。
2.3 适用场景
-
特征数量多,但大部分都有贡献。
-
存在高度相关特征(如基因数据、金融因子分析)。
3. Lasso回归(Lasso Regression)
3.1 原理
Lasso(Least Absolute Shrinkage and Selection Operator)采用L1正则化:
其中:
-
是L1范数,即回归系数向量
3.2 特点
✅ 优点:
-
能自动进行特征选择(部分系数归零)。
-
适用于高维数据(p >> n),最多选择n个变量。
-
相比岭回归,能更好地剔除无关变量。
❌ 缺点:
-
如果多个特征高度相关,Lasso可能随机选择其中一个,不稳定。
-
对异常值敏感(L1损失不如L2稳健)。
3.3 适用场景
-
特征数量远大于样本量(如文本分类、基因数据)。
-
希望自动筛选重要变量(如特征工程)。
4. 弹性网络(Elastic Net)
4.1 原理
弹性网络结合L1和L2正则化:
其中:
-
λ 控制正则化强度
-
α∈[0,1] 控制L1/L2混合比例:
-
α=0 → 退化成岭回归,此时目标函数中只有 L2 正则化项,主要起到对系数整体收缩的作用。
-
α=1 → 退化成Lasso,目标函数中只有 L1 正则化项,从而具有自动特征选择的能力。
-
4.2 特点
✅ 优点:
-
兼具Lasso的特征选择和岭回归的稳定性。
-
适用于高度相关特征(不会随机丢弃)。
-
在 p≫n 时表现优于Lasso。
5. 三者对比总结
| 方法 | 正则化类型 | 特征选择 | 适用场景 | 缺点 |
|---|---|---|---|---|
| 岭回归 | L2 | ❌ 无 | 多重共线性、所有特征重要 | 不进行变量筛选 |
| Lasso | L1 | ✅ 有 | 高维数据、稀疏建模 | 对相关特征不稳定 |
| 弹性网络 | L1 + L2 | ✅ 有 | 高维+相关特征、稳健特征选择 | 调参复杂 |
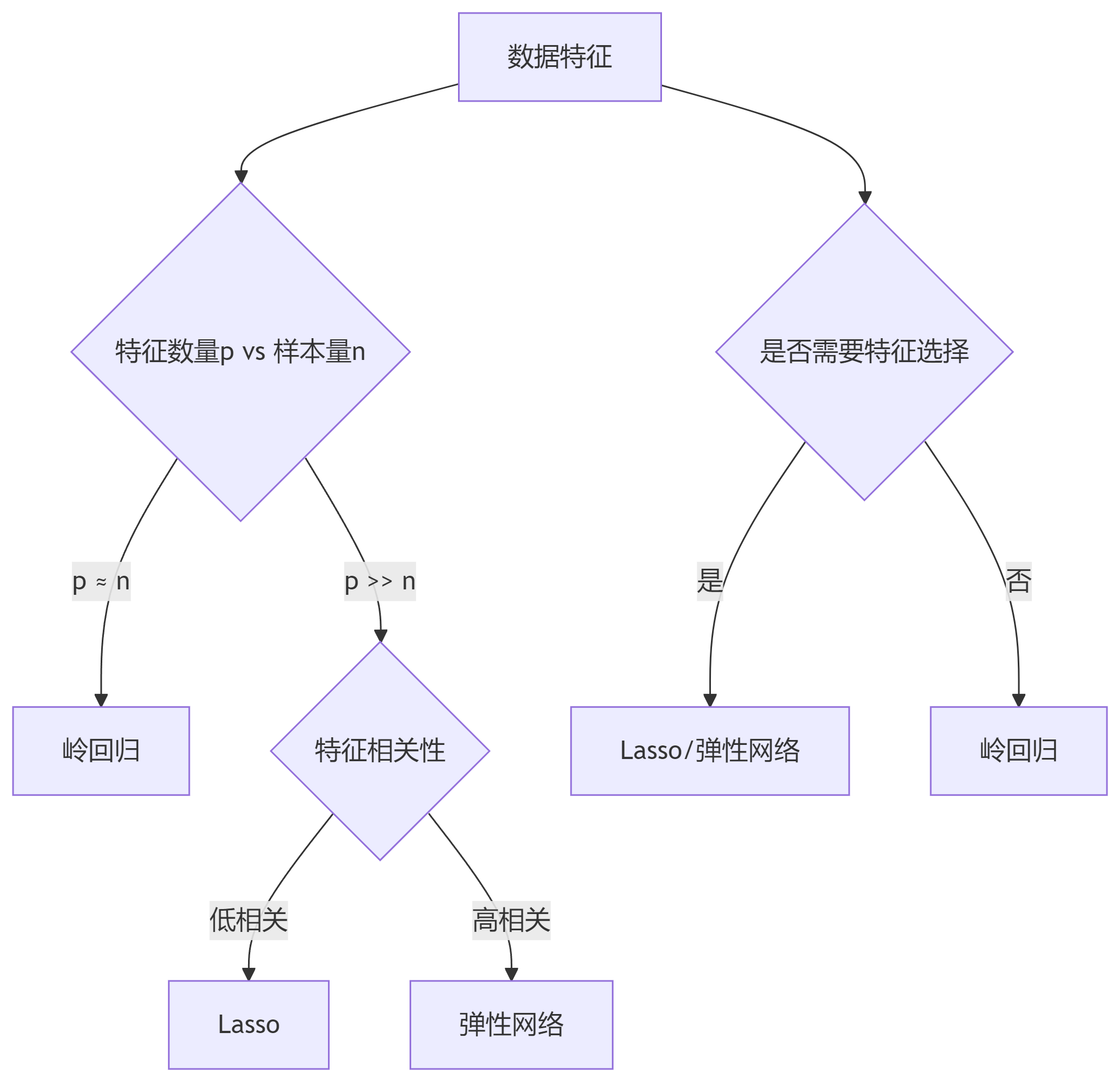
6. 如何选择?
-
如果特征数量不多且无共线性 → OLS(无正则化)。
-
如果特征多且需要保留所有变量 → 岭回归。
-
如果特征非常多且需要自动筛选 → Lasso。
-
如果特征多且相关性强 → 弹性网络(推荐默认选择)
7. 总结
正则化回归是解决过拟合、高维数据、多重共线性的强大工具:
-
岭回归:稳定但保留所有变量。
-
Lasso:自动特征选择,但对相关特征不稳定。
-
弹性网络:综合两者优势,适用于复杂数据。
在实际应用中,建议通过交叉验证比较不同方法,选择最佳模型。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 44
44 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)