word2vec原理(四):word2vec训练流程
目录1. 基于负例采样的Skipgram:训练过程2. 窗口大小和负样本数量2.1 窗口大小2.2 负样本数量1. 基于负例采样的Skipgram:训练过程在训练过程开始之前,我们预先处理我们正在训练模型的文本。在这一步中,我们确定一下词典的大小(我们称之为vocab_size,比如说10,000)以及哪...
目录
1. 基于负例采样的Skipgram:训练过程
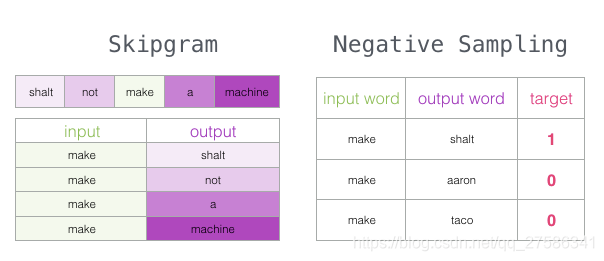
在训练过程开始之前,我们预先处理我们正在训练模型的文本。在这一步中,我们确定一下词典的大小(我们称之为vocab_size,比如说10,000)以及哪些词被它包含在内。
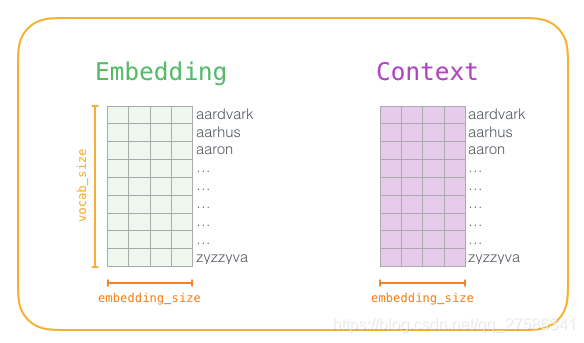
在训练阶段的开始,我们创建两个矩阵——Embedding矩阵和Context矩阵。这两个矩阵在我们的词汇表中嵌入了每个单词(所以vocab_size是他们的维度之一)。第二个维度是我们希望每次嵌入的长度(embedding_size——300是一个常见值,但我们在前文也看过50的例子):行数=词汇表的大小,列数=词向量的维度
在训练过程开始时,我们用随机值初始化这些矩阵。然后我们开始训练过程。在每个训练步骤中,我们采取一个相邻的例子及其相关的非相邻例子。我们来看看我们的第一组:
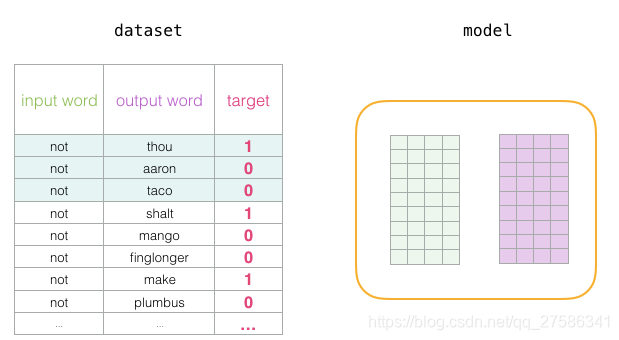
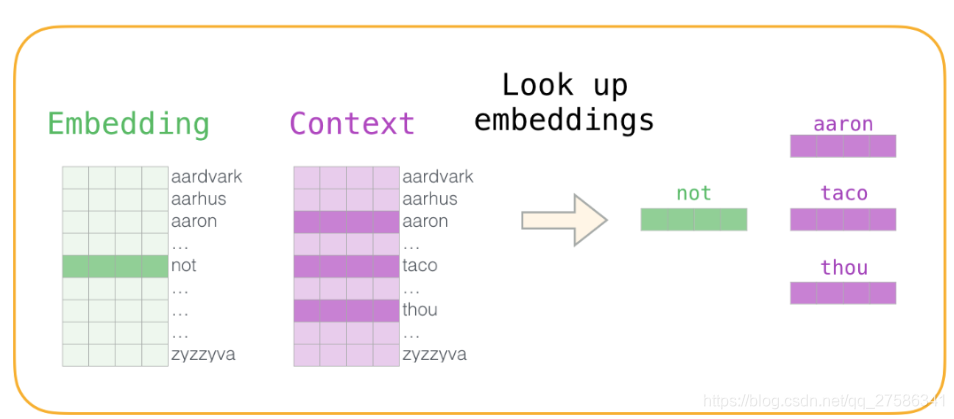
现在我们有四个单词:输入单词not和输出/上下文单词: thou(实际邻居词),aaron和taco(负面例子)。我们继续查找它们的嵌入:将单词转换为向量表示形式
对于输入词,我们查看Embedding矩阵;
对于上下文单词,我们查看Context矩阵。(即使两个矩阵都在我们的词汇表中嵌入了每个单词)
Embedding矩阵和Context矩阵:将单词转换为向量表示形式
然后,我们计算输入嵌入与每个上下文嵌入的点积(向量之间的点积)。在每种情况下,结果都将是表示输入和上下文嵌入的相似性的数字。
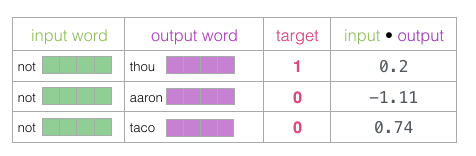
现在我们需要一种方法将这些分数转化为看起来像概率的东西——我们需要它们都是正值,并且 处于0到1之间。sigmoid这一逻辑函数转换正适合用来做这样的事情啦。
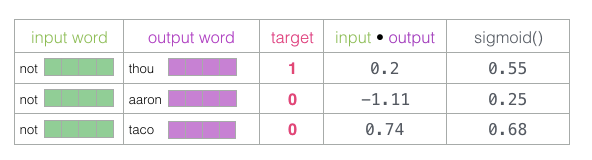
现在我们可以将sigmoid操作的输出视为这些示例的模型输出。您可以看到taco得分最高,aaron最低,无论是sigmoid操作之前还是之后。
既然未经训练的模型已做出预测,而且我们确实拥有真实目标标签来作对比,那么让我们计算模型预测中的误差吧。为此我们只需从目标标签中减去sigmoid分数。
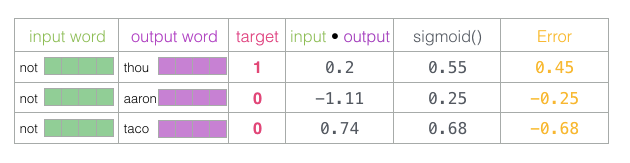
error = target - sigmoid_scores (标签值 - 模型预测值)
这是“机器学习”的“学习”部分。现在,我们可以利用这个错误分数来调整not、thou、aaron和taco的嵌入,使我们下一次做出这一计算时,结果会更接近目标分数。
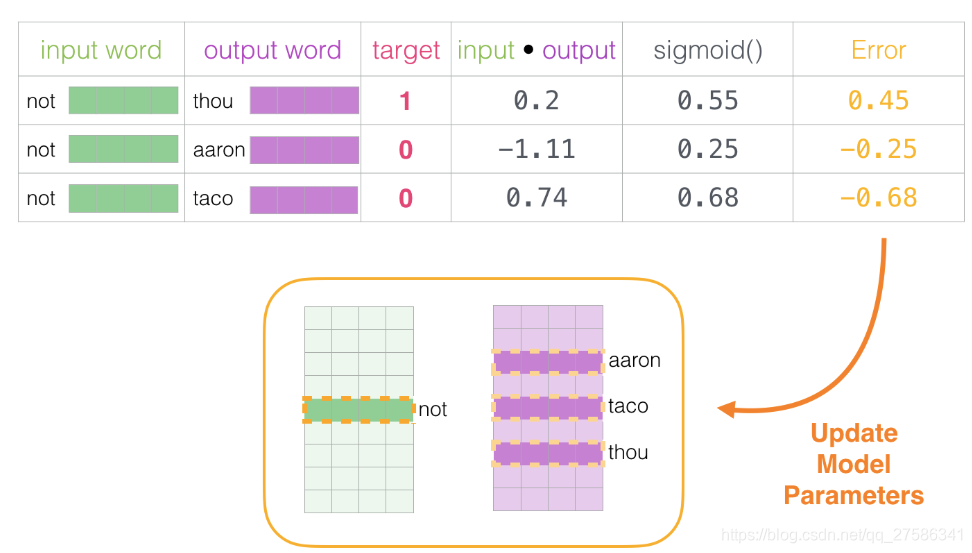
第一组的训练步骤到此结束。我们从中得到了这一步所使用词语更好一些的嵌入(not,thou,aaron和taco)。我们现在进行下一步(下一组相邻样本及其相关的非相邻样本),并再次执行相同的过程。
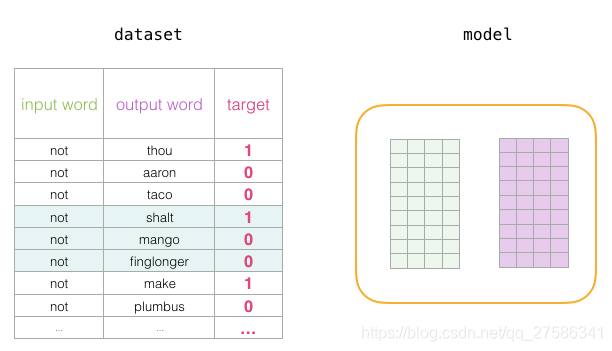
训练结果:当我们循环遍历整个数据集多次时,嵌入会继续得到改进。然后我们就可以停止训练过程,丢弃Context矩阵,并使用Embeddings矩阵作为下一项任务的已被训练好的嵌入。
2. 窗口大小和负样本数量
word2vec训练过程中的两个关键超参数是窗口大小和负样本的数量。
2.1 窗口大小

不同的任务适合不同的窗口大小。一种启发式方法是:
(1)使用较小的窗口大小(2-15)会得到这样的嵌入:两个嵌入之间的高相似性得分表明这些单词是可互换的(注意,如果我们只查看附近距离很近的单词,反义词通常可以互换——例如,好的和坏的经常出现在类似的语境中)。
(2)使用较大的窗口大小(15-50,甚至更多)会得到相似性更能指示单词相关性的嵌入。
在实际操作中,你通常需要对嵌入过程提供指导以帮助读者得到相似的”语感“。Gensim默认窗口大小为5(除了输入字本身以外还包括输入字之前与之后的两个字)。
2.2 负样本数量
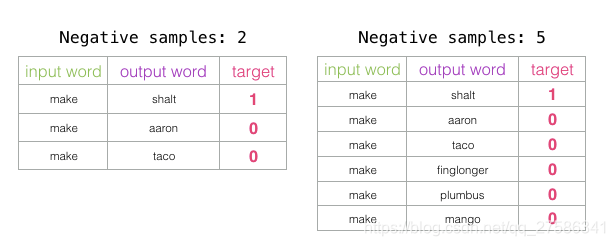
负样本的数量是训练训练过程的另一个因素。原始论文认为5-20个负样本是比较理想的数量。它还指出,当你拥有足够大的数据集时,2-5个似乎就已经足够了。Gensim默认为5个负样本。
参考:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)