R语言-相关性和回归
文章目录一、常规函数1.1 中位数 median( )1.2 平均值 mean( )1.3 最小值 min( )1.4 最大值 max( )1.5 方差1.6 标准差1.7 四分位距1.8 数据范围1.9 数据统计二、复杂函数2.1 相关性检验 cor.test( )2.2 协方差系数 cor( )2.3 线性回归方程 lm( )2.4 预测函数 predict( )总结一、常规函数读取数据car
·
一、常规函数
读取数据
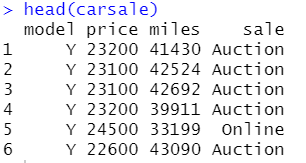
- carsale 是关于二手车的车型、售卖价格、驾驶距离、售卖形式的Data Frame
- 我们要对carsale进行数据的处理,探究车型、驾驶距离、售卖价格、售卖形式之间的关系
carsale=read.csv(file.choose())

1.1 中位数 median( )
求carsale中price列的中位数
median(carsale$price)

1.2 平均值 mean( )
求carsale中price列的平均数
mean(carsale$price)

1.3 最小值 min( )
求carsale中price列的最小值
min(carsale$price)

1.4 最大值 max( )
求carsale中price列的最大值
max(carsale$price)
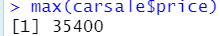
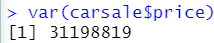
1.5 方差 var( )
求carsale中price列的方差
var(carsale$price)
1.6 标准差 sd( )
求carsale中price列的标准差
sd(carsale$price)

1.7 四分位距 IQR( )
求carsale中price列的四分位距
IQR(carsale$price)

1.8 数据范围 range( )
求carsale中price列的数据范围,返回的是一个两位数数组,前一个是最小值,后一个是最大值
range(carsale$price)

1.9 数据统计 summary( )
求carsale中price列的数据统计
- 包含:最小值、四分之一位数、中位数、平均值、四分之三位数、最大值
summary(carsale$price)

二、复杂函数
2.1 相关性检验 cor.test( )
- 函数功能:对成对数据进行相关性检验(即检验成对数据之间的相关程度)。
- 有3种方法可供使用,分别是Pearson检验、Kendall检验和Spearman检验。
函数格式:
cor.test(x, y,
alternative = c(“two.sided”, “less”, “greater”),
method = c("pearson", "kendall", "spearman"),
conf.level = 0.95)
- x、y是供检验的样本
- alternative指定是双侧检验还是单侧检验
- method为检验的方法
- conf.level为检验的置信水平
举例:
# 取carsale中所有model是X类型的数据,即车型为X的数据,赋值给carX
carX=carsale[carsale$model=="X",]
# 求X车型中售卖价格和驾驶距离的相关性检验
cor.test(carX$price,carX$miles)

结果显示:
- data: carX p r i c e a n d c a r X price and carX priceandcarXmiles:数据源自 carX p r i c e 和 c a r X price 和 carX price和carXmiles
- p-value < 2.2e-16:检验 p 值小于2.2e-16
- alternative hypothesis: true correlation is not equal to 0:替代假设:真实相关性不等于0
- 95 percent confidence interval -0.7094746 -0.5885133:95%的置信区间为:-0.7094746 ~ -0.5885133
- sample estimates: cor -0.6531409:样本估计:二者相关性系数为 -0.6531409
其余详情可参考:http://blog.sina.com.cn/s/blog_78c5f0530101btv3.html
2.2 协方差系数 cor( )
求carX的pirce、miles两列数据的协方差系数
cor(carX$price,carX$miles)

2.3 线性回归分析 lm( )
2.3.1 过滤函数 filter( )
将carsale里,车型为X的数据赋值给SaleX
library("dplyr")
SaleX=filter(carsale,model=="X")
与这种语法形成的结果一样
carX=carsale[carsale$model=="X",]
2.3.2 线性回归分析
m=lm(carX$price~carX$miles)
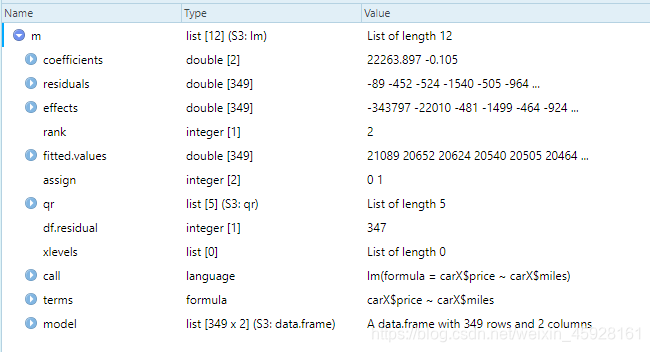
简单解读:
- coefficients(系数):是一个两位的数组,第一个数是截距b,第二个数是斜率a,即回归方程里y=b+ax里对应的b、a
- residuals:残差
2.3.3 线性回归绘图 stat_smooth()
ggplot(carX,aes(x=miles,y=price,colour=sale))+
geom_point(size=3,alpha=0.5)+
stat_smooth(method=lm,se=F,aes(x=miles,y=price),
inherit.aes = F)# 平滑曲线
- stat_smooth(method=lm,se=F,aes(x=miles,y=price), inherit.aes = F):即以miles为自变量 x ,以price为因变量 y ,利用线性回归分析方法lm( )确定线性回归方程,并绘制该平滑曲线
2.4 正态性检验:shapiro.test( )
检验carX中residual列数据的正态性,即是否满足正太分布(但即使满足也不能肯定一定是正态分布,只能说不可排除是正太分布的可能性)
st=shapiro.test(carX$residual)

2.5 预测函数 predict( )(未懂)
在线性回归分析的结果上,对新的样本进行预测,预测其对应的结果
得到线性回归分析结果:
m=lm(carX$price~carX$miles)
预测miles=6000时的sale值
predict(m,data.frame(miles=6000))
预测多个值
predict(m,data.frame(miles=c(6000,12000,350000)))
还有:
predict(m,data.frame(miles=c(6000,12000,350000)),
interval = "confidence",level=0.95)
predict(m,data.frame(miles=c(6000,12000,350000)),
interval = "prediction",level=0.95)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)