Meta-RL之Learning to Reinforcement Learn
广泛认为2016年由JX Wang发表的Learning to Reinforcement Learn是Meta-RL最早提出的版本。本论文将Meta-Learning的思想用到了强化学习上,目标是使DRL方法可以快速迁移到新的tasks中。RNN可以处理监督学习的Meta-learning问题,作者将方法用到强化学习的Meta-learning中。作者在原有任务的强化学习(指的是在固定MDP的R
广泛认为2016年由JX Wang发表的Learning to Reinforcement Learn是Meta-RL最早提出的版本。
本论文将Meta-Learning的思想用到了强化学习上,目标是使DRL方法可以快速迁移到新的tasks中。RNN可以处理监督学习的Meta-learning问题,作者将方法用到强化学习的Meta-learning中。作者在原有任务的强化学习(指的是在固定MDP的RL任务中使用的标准RL算法)中加入第二个强化学习过程,该过程使用RNN模型自动学习不同任务的知识,从而使得新的tasks可以利用RNN中的知识加快训练。
作者发表这篇文章旨在阐明和验证Meta-RL的通用基础框架,是有待后续发展的。
Meta-RL需要注意的三个地方(by LiI’Log):
参考列表:
①原文翻译
②Meta-RL之Learning to Learn Using Gradient Descent
③LiI’Log或其简要版中文
简介
- RL的一大缺陷就是产生样本能力有限,也就是说Agent想要达到很不错的表现需要很高的采样效率,但遗憾的是现在的RL标准算法都无法保证能做到这一点。而Few-shot Learning正好可以解决这个问题,Few-shot Learning是Meta-learning在监督学习领域的应用,因此本文的目的就是将Meta-Learning应用到RL上来,名曰Deep Meta-reinforcement Learning,简称Meta-RL。
- 标准的Meta-Learning设置分为2级:Meta-Learner和Learner。元学习器用于调节和改善学习器,形成一套学习算法;学习器就是具体的分类回归算法,用于快速适应到新task上。
- 2001年Hochreiter提出了一种比较不错的Meta-Learning配置,通过加入RNN来实现Gradient Descent,从而产生一套学习算法。
- 遗憾的是,Hochreiter当时提出的Meta-Learning训练方式只是针对监督学习的,故本文作者将采用相同的方法在RL结构中实现,即Meta-RL。因此Meta-RL和Hochreiter提出的模型很相似。
- Meta-RL的训练集由许多相关的环境组成。
主要内容
简而言之,Meta-RL做的事就是在多个相似不同的环境中进行训练得到学习算法,然后在新任务上快速适应。
核心思想
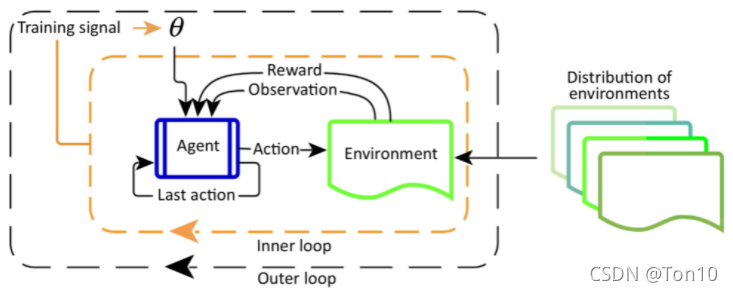
如上图所示,每一个MDP环境(task) m m m都有 m ∼ D m\sim\mathcal{D} m∼D,Meta-RL的训练步骤如下:
- 采样一个 m i ∼ M m_i\sim\mathcal{M} mi∼M。
- 重置LSTM中的隐藏状态。
- 让Agent和环境交互产生多条轨迹,并以此来更新模型。需要注意的是,在交互过程中,动作 a t a_t at的输出取决于先前的轨迹—— H = { x 0 , a 0 , r 1 , ⋯ x t − 1 , a t − 1 , r t , x t } \mathcal{H}=\{x_0,a_0,r_1,\cdots x_{t-1},a_{t-1},r_t,x_t\} H={x0,a0,r1,⋯xt−1,at−1,rt,xt},即当前episode的状态集 { x s } 0 ≤ s ≤ t \{x_s\}_{0\leq s\leq t} {xs}0≤s≤t,动作集 { a s } 0 ≤ s ≤ t \{a_s\}_{0\leq s\leq t} {as}0≤s≤t以及回报集 { r s } 1 ≤ s ≤ t \{r_s\}_{1\leq s\leq t} {rs}1≤s≤t。
- 重复步骤1。
Note:
- 因为学习到的策略网络是历史依赖的,即需要过去的状态动作回报集,所以当众多MDP具有某种相似性的时候,那对于一个新的task,就比较容易去适应,这也就是为什么任务 τ ∼ p ( τ ) \tau\sim p(\tau) τ∼p(τ)的原因,即不能随意哪一个task来训练,而是要满足某种相似性(同一个分布下)。
- 由于涉及到历史状态的输入,故需要用的RNN(LSTM),从这一点来看,Meta-RL和Hochreiter提出的基于LSTM的Meta-Learning有相似的思想。
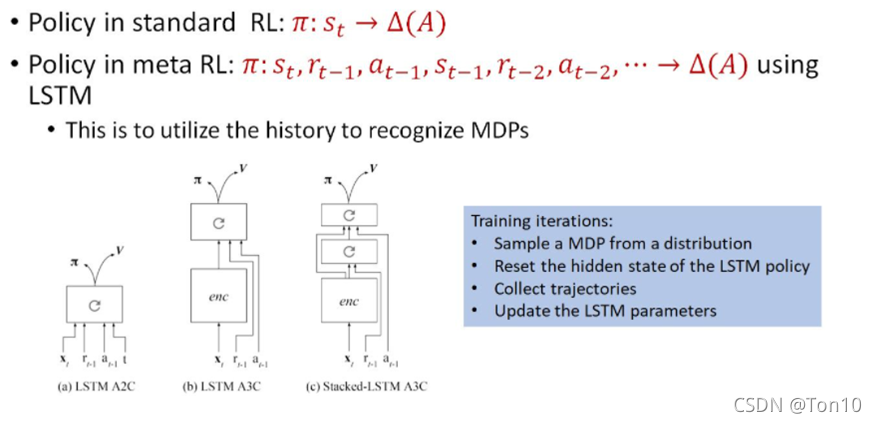
上图就是作者针对7次实验设置的3种不同的策略网络结构。
Note:
- 网络的输入比标准的RL算法多了过去时刻的回报和动作。
- enc是组合层,由卷积神经网络层和全连接层组成。“带循环箭头标志”的是循环神经网络。
- 在本论文中,作者采用标准的A3C(A2C)算法作为Learner。
总结
Deep meta-RL涉及三种必要的成分:
- 使用
标准的DRL算法去训练RNN。 - 训练集涉及一系列
相互关联的任务。 - 网络的输入比标准的RL算法增加了
过去时间的动作和回报。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)