手把手教你理解支持向量机(SVM):从“分界线”到“核魔法”
通过本文,我们进一步理解了SVM背后的几何直觉,还亲手实现了分类模型。记住,参数调节就像调整望远镜——需要耐心找到清晰的焦点。下次当你遇到复杂的分类问题时,不妨试试这把“机器学习中的瑞士军刀”
在前面文章中,我们学习了逻辑回归如何通过S形函数实现分类。
但你是否想过,当两类数据像两军对垒般整齐排列时,是否存在一条最安全的“楚河汉界”?这就是支持向量机(SVM)的绝妙之处——它不仅找分界线,还要找到让双方都最安全的“缓冲带”。今天,我们将揭开这个被称为“分类算法中的装甲车”的神秘面纱。
目录
一、直观理解:如何找到最安全的边界?
1.1 生活中的类比
想象你在两堆不同颜色的气球(红/蓝)之间画分隔线:
-
普通分界线:可能随意画一条线,结果红色或蓝色气球可能离这条线非常近(下图左)
-
SVM的分界:则是找出一条“黄金中线”,使得左右两侧离该线的最近气球距离最大,形成一个安全的缓冲带(下图右)
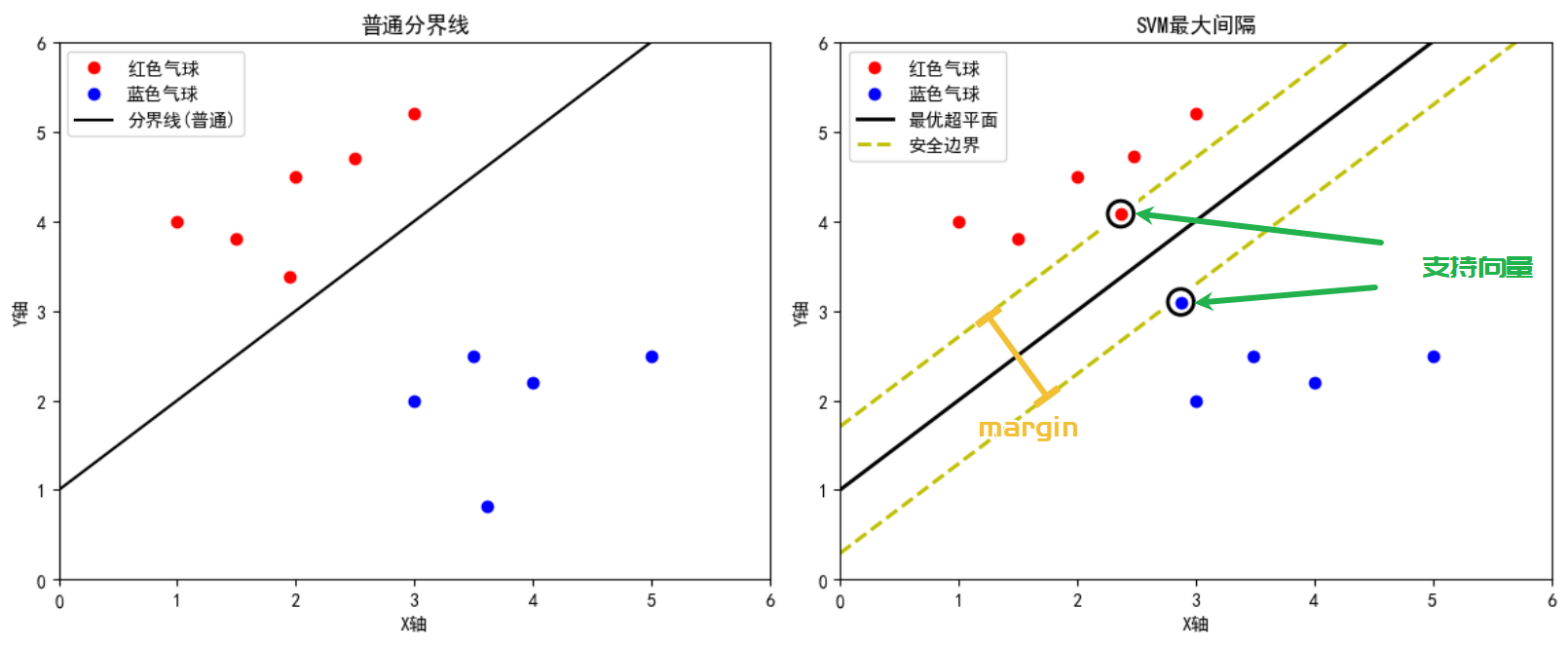
上图对比两种分界方式,右图中黄色虚线表示最大间隔范围,黑色实线为最优超平面
1.2 关键概念解析
-
支持向量:离分界线最近的“哨兵”样本(图中被圈出的气球),这些点决定了超平面的最终位置和方向。
-
间隔(Margin):分界线到两侧最近样本的距离之和,SVM 目标是最大化这个间隔,以提高模型的泛化能力。
-
超平面:在二维空间中就是一条直线,三维空间中为平面,依此类推。超平面将样本空间划分成两个部分。
1.3详细图解
-
蓝色和红色点 表示两个类别的数据;
-
黑色直线 表示分类超平面;
-
两条平行的虚线 表示间隔边界;
-
靠近虚线的点 为支持向量。
二、 SVM 的数学原理
2.1 线性可分情形
首先了解一下什么是线性可分,在二维平面中,线性可分就是指两类点可以被一条直线完全分开
假设我们的训练数据集为 ,其中
。
也就是我们有一组训练样本,每个样本是一个特征向量 以及对应的类别标签
,其中
只能取两种值:+1 或 -1。一个线性分类器,即一个超平面,能够把两类数据分开。这个超平面可以表示为:
其中,w 是一个权重向量,b 是偏置项。
对于正确分类的样本,我们需要满足:
为什么不写作 >0 呢?
虽然 就能保证样本被正确分类,但我们这里额外要求每个样本与超平面之间至少有一个单位距离(通过约定“1”作为标准),这样可以统一尺度,便于后续推导“间隔”的概念。
再回来看间隔的概念
-
间隔的定义:对于一个超平面,其到某个点的距离计算公式是
-
支持向量:离超平面最近的那些点(刚好满足
的点)称为支持向量。
-
间隔大小:对于支持向量来说,距离就是
这说明如果我们想让间隔更大,就需要使
更小。
为了数学上处理方便,通常将问题写为最小化 (加个1/2对求导更简洁):
同时还需要满足对所有样本都正确分类的约束条件:
直接求解这个优化问题比较困难,所以我们引入拉格朗日乘子,将约束条件合并到目标函数中。引入每个约束对应的拉格朗日乘子 后,可以构造出一个拉格朗日函数。
通过求解这个拉格朗日函数的极值(通常先对 w 和 b 求偏导设为 0,再转化为对偶问题求解),我们最终能得到一个只依赖于支持向量的表达式。也就是说,只有那些恰好位于间隔边界上的数据点(支持向量)对最终决策边界起决定作用。
2.2 非线性与核技巧
现实问题中数据往往是非线性可分的,SVM 提出了软间隔概念,引入松弛变量 ξi\xi_iξi 允许一定的分类错误:
此外,通过核技巧,可以将数据映射到高维空间,在高维空间中寻找线性决策边界,从而解决非线性问题。常见的核函数有线性核、多项式核、高斯径向基核(RBF)等。
三、 Python 案例讲解
下面我们结合一个完整的案例,详细讲解如何使用 Python 中的 scikit-learn 库实现 SVM 分类。
3.1 数据准备与探索
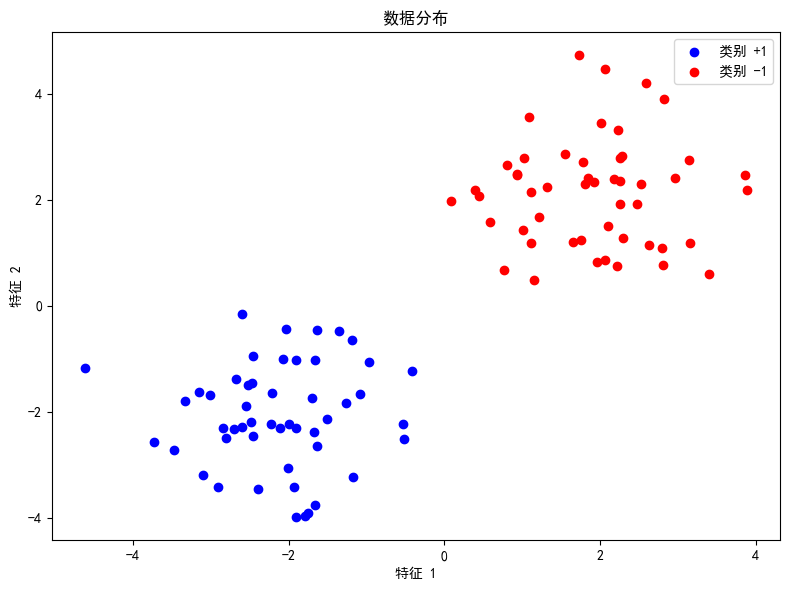
在本例中,我们使用人工生成的数据集来模拟两个类别的分布情况。首先对数据进行可视化,以便更直观地理解数据分布情况。
import numpy as np
import matplotlib.pyplot as plt
# 设置随机种子
np.random.seed(42)
# 生成数据
X1 = np.random.randn(50, 2) - [2, 2] # 类别 +1
X2 = np.random.randn(50, 2) + [2, 2] # 类别 -1
X = np.vstack((X1, X2))
y = np.hstack((np.ones(50), -np.ones(50)))
# 数据散点图
plt.figure(figsize=(8,6))
plt.scatter(X1[:, 0], X1[:, 1], color='blue', label='类别 +1')
plt.scatter(X2[:, 0], X2[:, 1], color='red', label='类别 -1')
plt.xlabel('特征 1')
plt.ylabel('特征 2')
plt.title('数据分布')
plt.legend()
plt.tight_layout()
plt.show()
3.2 训练 SVM 模型
接下来,我们利用 scikit-learn 中的 SVC 类来训练 SVM 模型。这里我们使用线性核函数,针对线性可分数据进行训练。
from sklearn.svm import SVC
# 构造 SVM 模型,C 值很大表示我们希望硬间隔分类(尽量不允许错误分类)
svm_model = SVC(kernel='linear', C=1e5)
svm_model.fit(X, y)
# 输出模型参数
print("模型权重向量 w:", svm_model.coef_)
print("模型偏置 b:", svm_model.intercept_)

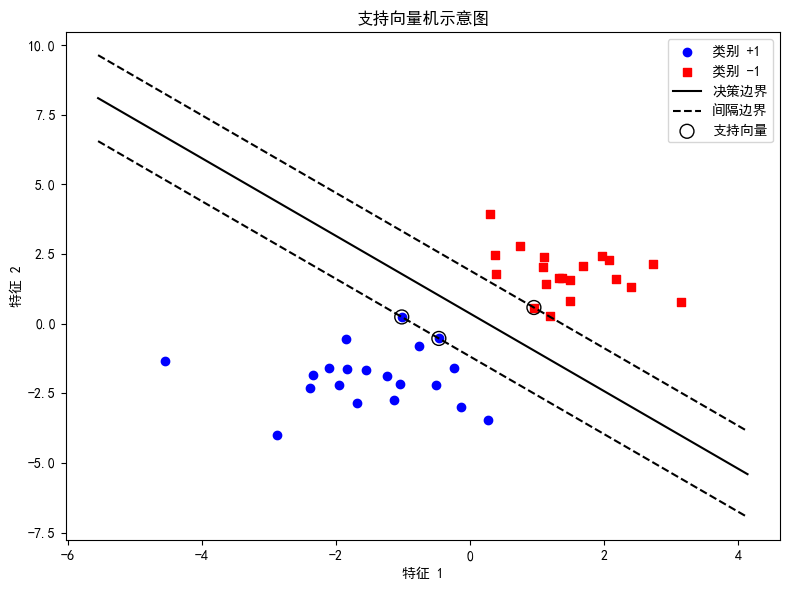
3.3 可视化决策边界和支持向量
我们对决策边界进行绘制,同时标记出支持向量。
# 获取模型参数
w = svm_model.coef_[0]
b = svm_model.intercept_[0]
# 绘制决策边界
xx = np.linspace(np.min(X[:, 0]) - 1, np.max(X[:, 0]) + 1, 100)
yy = -(w[0] * xx + b) / w[1]
margin = 1 / np.linalg.norm(w)
yy_down = yy - np.sqrt(1 + (w[0]/w[1])**2) * margin
yy_up = yy + np.sqrt(1 + (w[0]/w[1])**2) * margin
plt.figure(figsize=(8,6))
plt.scatter(X[y==1, 0], X[y==1, 1], color='blue', marker='o', label='类别 +1')
plt.scatter(X[y==-1, 0], X[y==-1, 1], color='red', marker='s', label='类别 -1')
plt.plot(xx, yy, 'k-', label='决策边界')
plt.plot(xx, yy_down, 'k--', label='间隔边界')
plt.plot(xx, yy_up, 'k--')
plt.scatter(svm_model.support_vectors_[:, 0], svm_model.support_vectors_[:, 1],
s=100, facecolors='none', edgecolors='k', label='支持向量')
plt.xlabel('特征 1')
plt.ylabel('特征 2')
plt.title('SVM 分类结果与支持向量')
plt.legend()
plt.tight_layout()
plt.show()
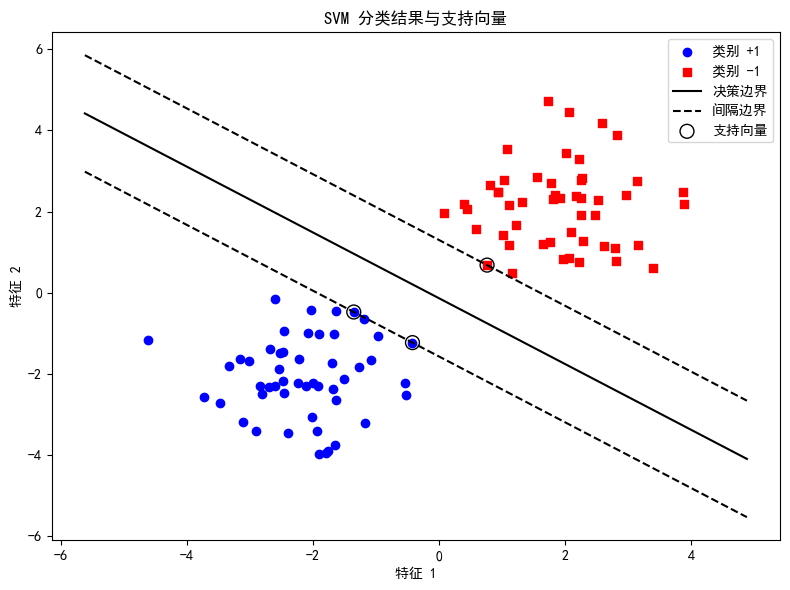
通过上面代码,可以直观看出SVM是如何划分数据,哪些点成了支持向量,以及决策边界如何确定
四、非线性问题与核函数
前面我们也提到过,对于一些比较复杂的数据,若无法用一条直线分隔开两类数据,那么就需要使用核函数
| 核类型 | 公式 | 适用场景 |
|---|---|---|
| 线性核 | 线性可分 | |
| 多项式核 | 适度非线性 | |
| RBF核 | 复杂非线性 |
代码示例:使用RBF核处理复杂数据
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC
# 生成月亮型数据集
from sklearn.datasets import make_moons
def plot_svc_boundary(model, X, y):
# 创建网格
x_min, x_max = X[:,0].min()-1, X[:,0].max()+1
y_min, y_max = X[:,1].min()-1, X[:,1].max()+1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
# 预测并绘制
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.3)
plt.scatter(X[:,0], X[:,1], c=y, edgecolors='k')
# 标出支持向量
plt.scatter(model.support_vectors_[:,0],
model.support_vectors_[:,1],
s=100, facecolors='none', edgecolors='k')
plt.xlabel('Sepal Length')
plt.ylabel('Sepal Width')
X, y = make_moons(n_samples=100, noise=0.15, random_state=42)
# 使用RBF核训练
svm_rbf = SVC(kernel='rbf', gamma=0.7, C=1.0)
svm_rbf.fit(X, y)
# 可视化决策边界
plt.figure(figsize=(10,6))
plot_svc_boundary(svm_rbf, X, y)
plt.title('RBF Kernel SVM on Moons Dataset')
五、关键参数解析:C与γ的博弈
5.1 正则化参数C
-
C值大:严格分类,间隔窄(可能过拟合)
-
C值小:允许误分类,间隔宽(提高泛化性)
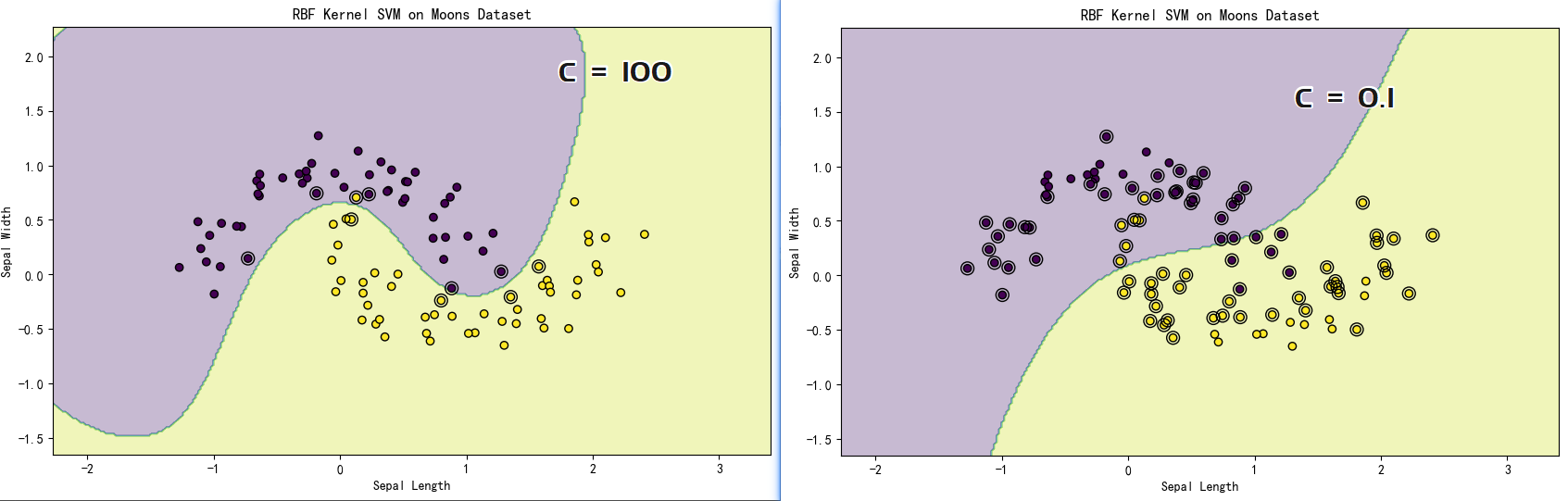
5.2 RBF核参数γ
-
γ值大:单个样本影响范围小,决策边界崎岖
-
γ值小:影响范围大,边界平滑
通常可以使用交叉验证(Cross Validation)等方法对这些参数进行调优,找到模型在验证集上的最佳表现。
结语:从理论到实践的跨越
通过本文,我们进一步理解了SVM背后的几何直觉,还亲手实现了分类模型。记住,参数调节就像调整望远镜——需要耐心找到清晰的焦点。下次当你遇到复杂的分类问题时,不妨试试这把“机器学习中的瑞士军刀”
如果这篇文章对你有所启发,期待你的点赞关注,我会继续努力写出更加优质的文章!


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)