Transformer相关学习资料整理
最近频繁看到论文中用到transformer,于是又回头看了看曾经经典的大作。以前只知道大致流程,本次死磕一波,好好梳理细节和内容,因网上大部分资料讲的内容都不错,遂做整理。1. Transformer相关内容变形金刚——Transformer入门刨析详解【Transformer】一文搞懂Transformer | CV领域中Transformer应用图解Transformer | The Ill
最近频繁看到论文中用到transformer,于是又回头看了看曾经经典的大作。以前只知道大致流程,本次死磕一波,好好梳理细节和内容,因网上大部分资料讲的内容都不错,遂做整理。
1. self-Attention
再更新整理一波,借用博主的一张图。我们很多时候看不懂transformer,是因为整理看了逻辑,懂了架构,却不理解细节,因此有时候印象不深,因此从计算过程中再进行整理分析一波,加深印象。
参考链接:Transformer中Self-Attention以及Multi-Head Attention详解
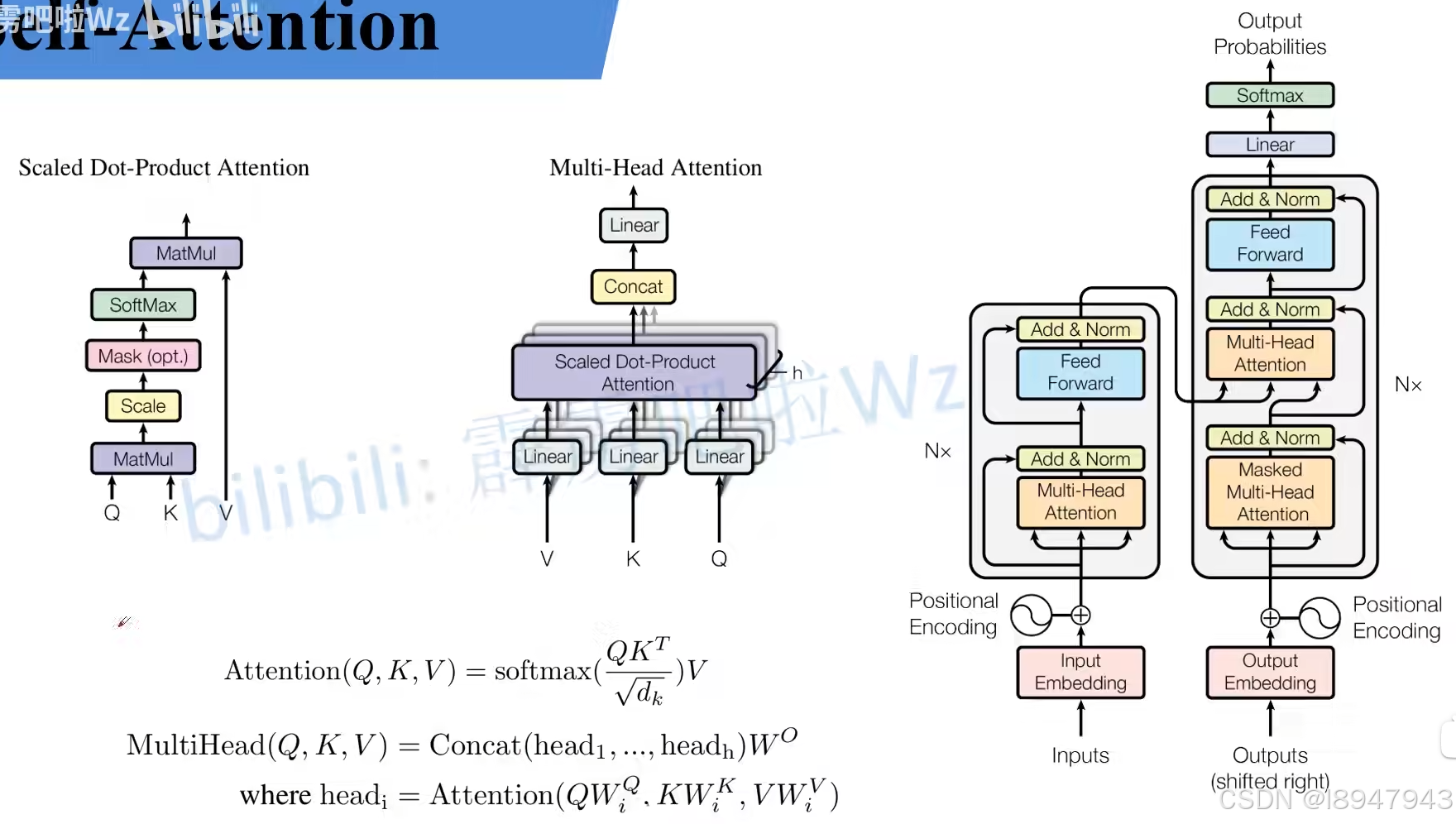
针对计算公式:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V)=softmax(\frac{QK^{T}}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V
- 首先计算q,k,v向量,将词向量通过参数矩阵得到。计算过程如图:
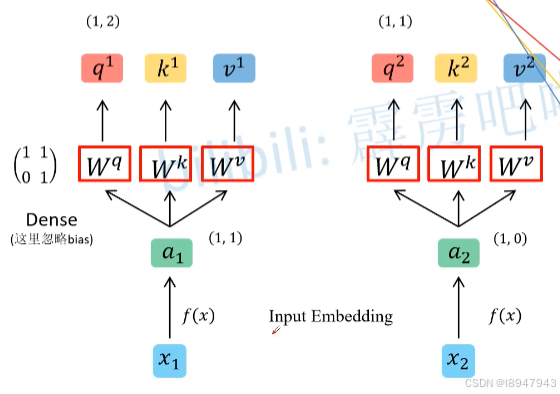
在执行过程中, x 1 x_1 x1, x 2 x_2 x2是输入的时序数据,
- 首先会将 x x x通过Embedding层得到词向量 a 1 a_1 a1, a 2 a_2 a2,假设向量为 ( 1 , 1 ) (1,1) (1,1), ( 1 , 0 ) (1,0) (1,0)。
- 假设有参数矩阵 W q W^q Wq、 W k W^k Wk、 W v W^v Wv,初始状态为 ( 1 1 0 1 ) \begin{pmatrix} 1 & 1 \\ 0 & 1\end{pmatrix} (1011)(
此处的初始化Q、K、V是共享的,这三个参数是可训练的) - 通过参数矩阵,分别得到 q 1 q^1 q1, k 1 k^1 k1, v 1 v^1 v1和 q 2 q^2 q2, k 2 k^2 k2, v 2 v^2 v2。计算出的 q 1 q^1 q1为 ( 1 , 2 ) (1,2) (1,2), q 2 q^2 q2为 ( 1 , 1 ) (1,1) (1,1)
该过程用公式表示如下:
这里的q、k、v到底指的是啥?可以理解为:
- q是用于匹配其他的词向量表示
- k是用于被匹配的词向量表示
- v是用于表示从输入词向量中学习到的信息
为什么这么用,其实说白了学习的都是自身的特征向量,用于关联或者匹配相关词,为后续decoder做准备,此处看不懂没关系,多梳理几遍就能理解了。
站在矩阵乘法的角度,如图所示: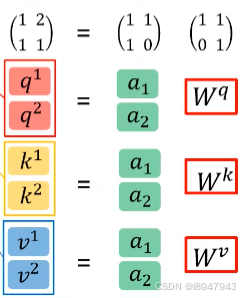
2. 接着计算q,k,v之间的点积关系,如图: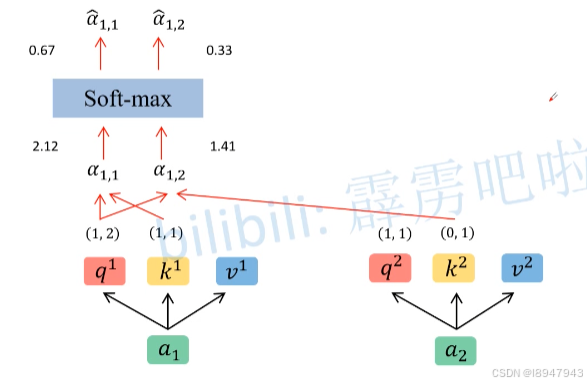
他们怎么进行匹配?如图:
说白了就是计算点积,其中d为k的维度,在本例中k维度为2。具体计算过程如下:
- 首先对 q 1 q^1 q1进行计算, q 1 ∗ k i / d q^1 * k^i / \sqrt{d} q1∗ki/d,分别得到每个k对应的匹配结果向量。例如: q 1 ∗ k 1 / d = ( 1 , 2 ) ( 1 , 1 ) / 2 = 3 / 2 = 2.12 q^1*k^1/ \sqrt{d}=(1,2)(1,1)/ \sqrt{2}=3 / \sqrt{2} = 2.12 q1∗k1/d=(1,2)(1,1)/2=3/2=2.12,其他同理。此时得到了 α 1 , 1 = 2.12 \alpha_{1,1}=2.12 α1,1=2.12, α 1 , 2 = 1.41 \alpha_{1,2}=1.41 α1,2=1.41
- 接着对 q 2 q^2 q2进行计算, q 2 ∗ k i / d q^2 * k^i / \sqrt{d} q2∗ki/d,分别得到每个k对应的匹配结果向量
- 最后对计算出来的 α \alpha α使用 s o f t m a x softmax softmax,得到 α ^ 1 , 1 = 0.67 \hat\alpha_{1,1}=0.67 α^1,1=0.67、 α ^ 1 , 2 = 0.33 \hat\alpha_{1,2}=0.33 α^1,2=0.33
为啥除以 d \sqrt{d} d?论文解释是为了计算的稳定,为什么要进行softmax,是因为点积后数值大,softmax可以让梯度减小。经过softmax后的数值,表示了针对每个v对应的权重,这权重越大,说明词向量中学习到的信息越重要。
同理衍生其他计算,如图: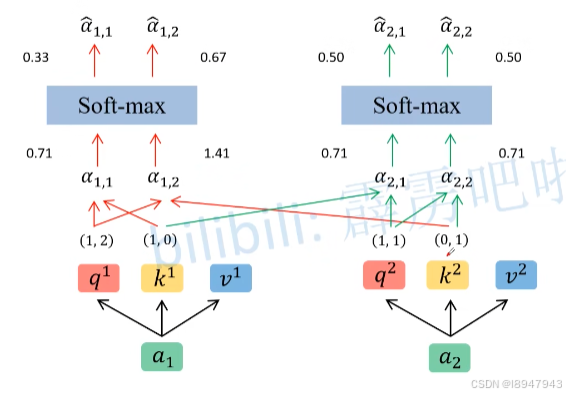
为了提高计算并行效率,我们将其向量化,计算如图: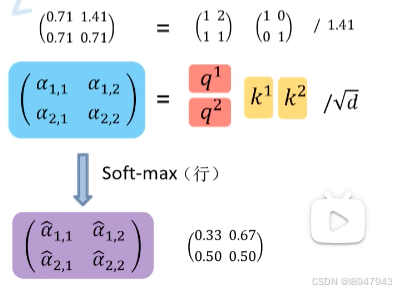
3. 接着计算与V之间的点积,如图: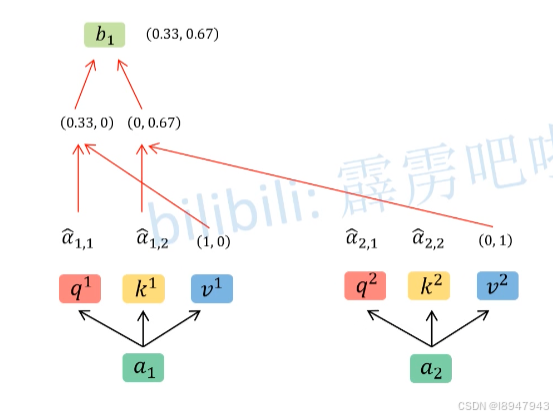
具体计算过程如下:
- 计算 α ^ 1 , 1 \hat\alpha_{1,1} α^1,1与 v 1 v1 v1向量的点积
- 计算 α ^ 1 , 2 \hat\alpha_{1,2} α^1,2与 v 2 v2 v2向量的点积
其中 ( α ^ 1 , 1 α ^ 1 , 2 α ^ 2 , 1 α ^ 2 , 2 ) \begin{pmatrix} \hat\alpha_{1,1} & \hat\alpha_{1,2} \\ \hat\alpha_{2,1} & \ \hat\alpha_{2,2} \end{pmatrix} (α^1,1α^2,1α^1,2 α^2,2) = ( 0.33 0.67 0.5 0.5 ) \begin{pmatrix} 0.33 & 0.67 \\ 0.5 & 0.5 \\ \end{pmatrix} (0.330.50.670.5)
其他同理,如图: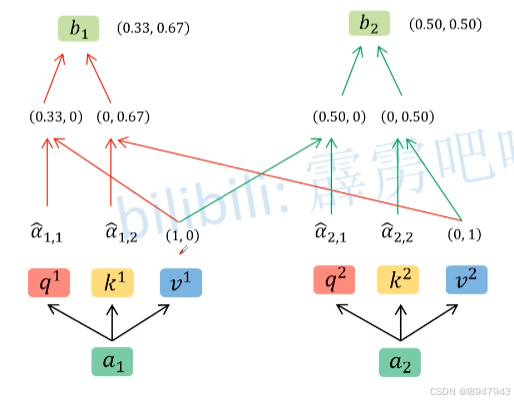
并行化计算公式如图:
经过步骤1,2,3,上述公式 A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V)=softmax(\frac{QK^{T}}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V就完成了他的使命。用一张图表示过程,如图: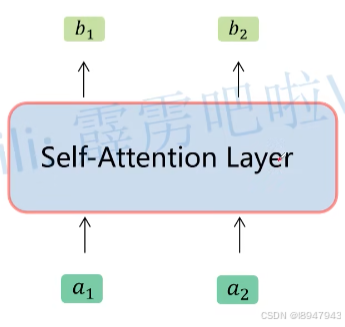
2. Multi-Head Attention
接着再学习Multi-Head Attention,实际使用中基本使用的还是Multi-Head Attention模块。再回头看这张图: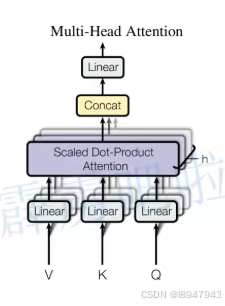
说白了,就是Self-Attention多层的堆叠,放在了一起。但是输入就是一个,维度如何匹配了?首先还是和Self-Attention模块一样将 a i a_i ai分别通过 W q W^q Wq, W k W^k Wk, W v W^v Wv得到对应的 q i q^i qi, k i k^i ki, v i v^i vi,然后再根据使用的head的数目 h h h进一步把得到的 q i q^i qi, k i k^i ki, v i v^i vi均分成 h h h份。在下面这张图中体现为,假设 h = 2 h=2 h=2,那么将 q 1 q^1 q1拆分为 q 1 , 1 q^{1,1} q1,1和 q 1 , 2 q^{1,2} q1,2,于是乎 q 1 , 1 q^{1,1} q1,1则属于head1, q 1 , 2 q^{1,2} q1,2属于head2。
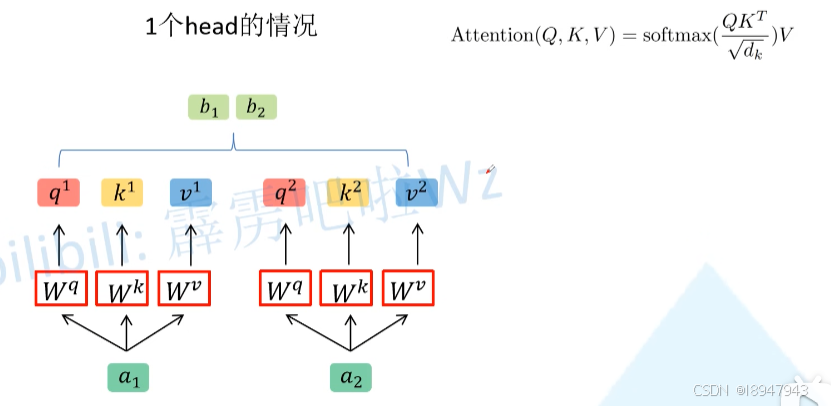
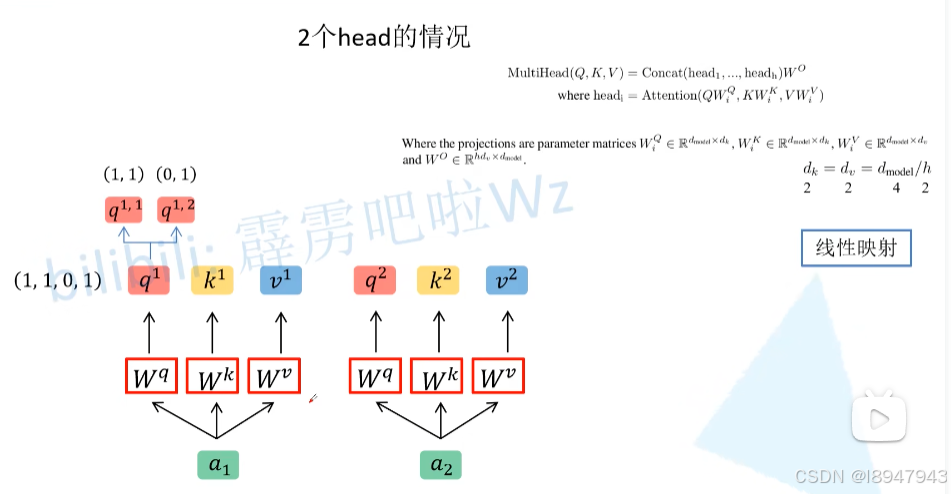
具体的,通过 W Q W^Q WQ矩阵实现对q矩阵的拆分,在这个拆分过程中, q 1 , 1 q^{1,1} q1,1, k 1 , 1 k^{1,1} k1,1, v 1 , 1 v^{1,1} v1,1和 q 2 , 1 q^{2,1} q2,1, k 2 , 1 k^{2,1} k2,1, v 2 , 1 v^{2,1} v2,1的向量都属于head1的内容。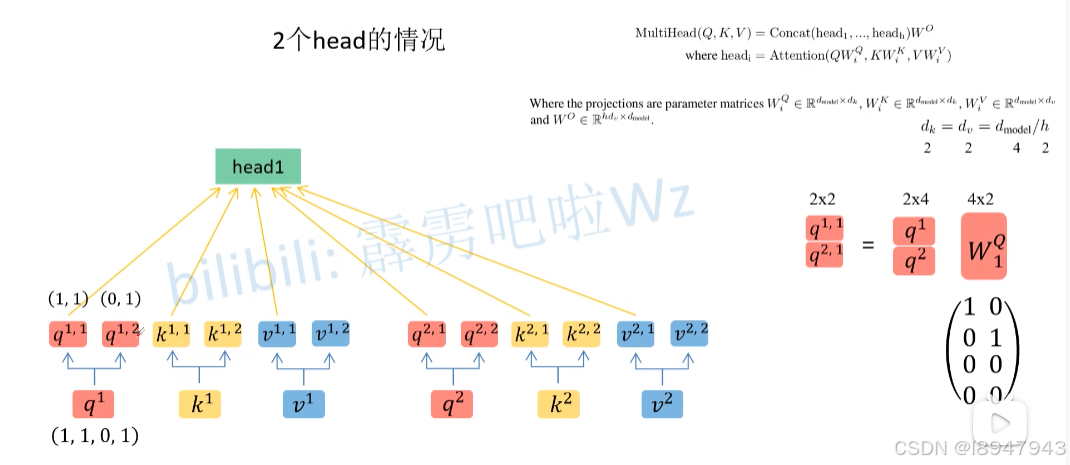
平铺后如图: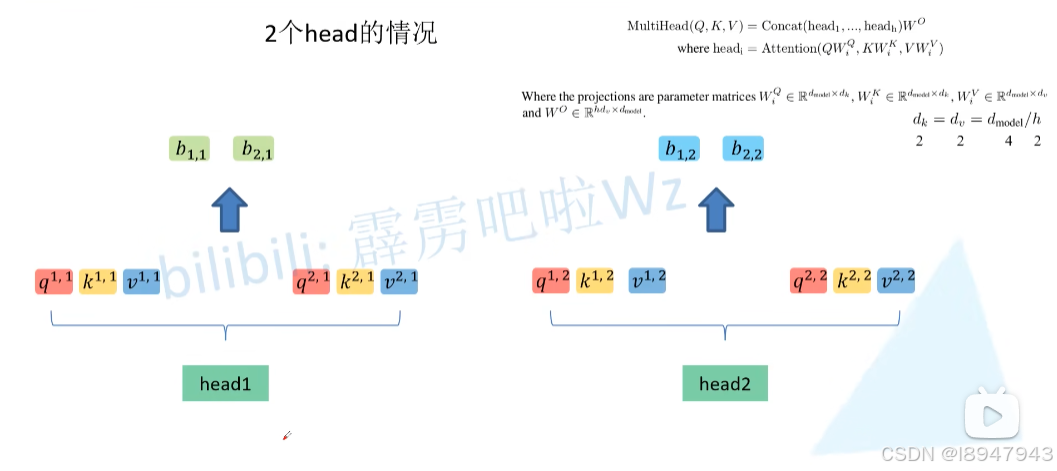
最后,在两个head进行attention结束后,在进行拼接,
最后,对得到的拼接矩阵乘以 W O W^O WO进行融合,得到了最终multiHead的输出
因此,Multi-Head Attention抽取出来结果如图,一目了然
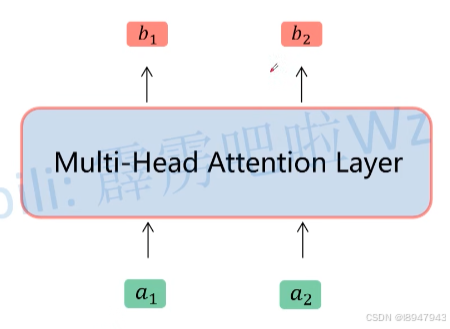
Multi-Head Attention的内容就讲完了。总结下来就是论文中的两个公式:
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , … , h e a d h ) W O w h e r e h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) MultiHead(Q, K, V)=Concat(head_1,\ldots,head_h)W^O \\ where head_i = Attention(QW_i^Q, KW_i^K, VW_i^V) MultiHead(Q,K,V)=Concat(head1,…,headh)WOwhereheadi=Attention(QWiQ,KWiK,VWiV)
3. Transformer相关内容
- 变形金刚——Transformer入门刨析详解
- 【Transformer】一文搞懂Transformer | CV领域中Transformer应用
- 图解Transformer | The Illustrated Transformer,这篇文章做的很用心
- Transformer中Self-Attention以及Multi-Head Attention详解
- 李宏毅2022讲解transformer(上)
- 李宏毅2022讲解transformer(上)
- Transformer(李宏毅2022)
4. Transformer手撕代码
此外,原文一定要精读,完成后,多看博客总结,基本上可以弄清楚,最后手撸一遍代码,加深对内容的理解。
5. 补充精品知识
- 一次一个概念地可视化机器学习,这个大哥对机器学习有些概念进行了可视化呈现,一些主流的内容都可以找到,没事可以充充电。
- RCNN理论合集,transformer出来之前,大都用的RCNN,包含一些对RCNN、Fast-RCNN、Faster-RCNN相关解读,内容不错。
- 层层剖析,让你彻底搞懂Self-Attention、MultiHead-Attention和Masked-Attention的机制和原理 (PS:本文强推,需要出墙,讲解和实现都有,非常nice)
如果大家觉得还有不错的好文,欢迎补充,我持续更新

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)