自然语言处理——语义向量
将文本的符号表示转换为语义空间中的向量表示是现在量化比较语义的通用做法,这类方法通常都基于Harris的分布式假设,即在相似上下文中的词通常都有着相似的语义.
下面首先会对已有的一些文本语义表示模型进行介绍.
表示形式
Term-Document Matrix
这种是最原始的一种语义衡量方法,主要用于文档检索,比较不同文档间的语义,其核心就是Term-Document Matrix,如下图所示,可以很明显看到,每一行代表着一个词,每一列代表着一个文档,矩阵中的元素就是统计某个词在某个文档中出现的频次.

如何衡量文档的相似性,可以在下图看的一清二楚了.
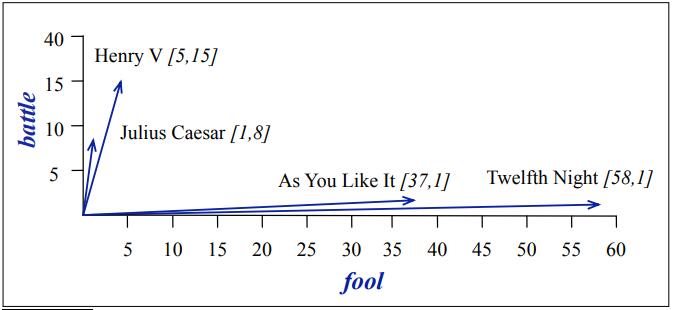
Term-Context Matrix
像词-文档矩阵一样,词-上下文矩阵如下图所示,只是统计的对象变成了词-上下文.通常来说,这种表示粒度更小,对于语义的比较也更为有利.

如果对语义向量空间的表示原理想了解得更加清楚,可以参看文献[1].
但是对于应用来说,这类直接通过统计得到的矩阵表示,虽然能够一定程度上展示之间的差异性,但是对于语义比较来说,仍然没有足够的区分度.因此后续会在此基础上,引入更多的处理方法.
PMI
点互信息(PMI,Pointwise Mutual Information)就是这样一个工具,
首先需要提到互信息的表示方式,互信息用于衡量
点互信息定义为,
但是由于 PMI P M I <script type="math/tex" id="MathJax-Element-7">PMI</script>的值可能为负,因此通常都不会用PMI,而是使用一个剪切版——PPMI(非负PMI),即 PPMI(w,c)=max{PMI(w,c),0} P P M I ( w , c ) = max { P M I ( w , c ) , 0 } <script type="math/tex" id="MathJax-Element-8">PPMI(w,c)=\max\{PMI(w,c),0\}</script>,还有更进一步的 PPMIα P P M I α <script type="math/tex" id="MathJax-Element-9">PPMI_{\alpha}</script>,文献[3]中取 α=0.75 α = 0.75 <script type="math/tex" id="MathJax-Element-10">\alpha=0.75</script>
另外一个解决PMI为负的方法是Laplace平滑法.
表示形式再加工
tf-idf
这种方法主要是
tf(term frequency)就是文档中该词的出现频次.重点是idf(inverse document frequency),就经验上来说,如果一个词出现在很多文档中,那么这个词对于该文档就很没有辨识度,也就是信息量太少,如“是,我”这一类的词.因此应该考虑量化该词所负载的信息量,也就是idf,在所有文档中出现的频次不是很高,即 idf=log(Ndfi) i d f = log ( N d f i ) <script type="math/tex" id="MathJax-Element-12">idf=\log({{N}\over{df_i}})</script>.
这种方法主要用于信息检索方面.
还有更多的一些衡量方法,如t-检验等.
距离度量
这里就要对上面提到的那些方法得到的结果进行具体的距离度量.直接的方法就是求两个表示向量的点积,但是这样的话,得到的点积结果很有可能会很大,同时,词的频次大小会直接影响最后的结构,因此使用最多的就是 cosine c o s i n e <script type="math/tex" id="MathJax-Element-697">cosine</script>距离度量,也就是标准化后的距离 cos(v⃗ ,w⃗ ) cos ( v → , w → ) <script type="math/tex" id="MathJax-Element-698">\cos(\vec{v},\vec{w})</script>.
也有一些替代方案,如Jaccard(最早用于二进制向量)
以及 Dice度量方式
如果向量表示一个概率分布(向量和为1),那么比较两个概率分布相似性的度量方法就也可以使用了,如KL散度.
但是由于有限的语料,带来的稀疏性,上式的分母可能为零,因此改为使用Jensen-Shannon散度
总结如下图所示,

资料来源:
[1]. Turney P D, Pantel P. From frequency to meaning: Vector space models of semantics[J]. Journal of artificial intelligence research, 2010, 37: 141-188.
[2]. Levy O, Goldberg Y, Dagan I. Improving distributional similarity with lessons learned from word embeddings[J]. Transactions of the Association for Computational Linguistics, 2015, 3: 211-225.
[2].《speech and language processing》,https://web.stanford.edu/~jurafsky/slp3/15.pdf

本作品采用知识共享署名-非商业性使用-相同方式共享 3.0 中国大陆许可协议进行许可。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)