day15python打卡
尝试找到一个kaggle或者其他地方的结构化数据集,用之前的内容完成一个全新的项目,这样你也是独立完成了一个专属于自己的项目。仔细回顾一下之前14天的内容,没跟上进度的同学补一下进度。有数据地址的提供数据地址,没有地址的上传网盘贴出地址即可。尽可能与他人不同,优先选择本专业相关数据集。探索一下开源数据的网站有哪些?
·
复习日
仔细回顾一下之前14天的内容,没跟上进度的同学补一下进度。
作业:
尝试找到一个kaggle或者其他地方的结构化数据集,用之前的内容完成一个全新的项目,这样你也是独立完成了一个专属于自己的项目。
data:学生考试成绩![]() https://www.kaggle.com/datasets/spscientist/students-performance-in-exams/data
https://www.kaggle.com/datasets/spscientist/students-performance-in-exams/data
要求:
- 有数据地址的提供数据地址,没有地址的上传网盘贴出地址即可。
- 尽可能与他人不同,优先选择本专业相关数据集
- 探索一下开源数据的网站有哪些?
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
from scipy import stats
# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
df = pd.read_csv('./StudentsPerformance.csv')
df.replace([np.inf, -np.inf], np.nan, inplace=True)
print(df.isnull().sum()) # 检查缺失值
print(df.columns)
df.columns = df.columns.str.replace(' ', '_')
print(df.columns)
# 描述性统计
print(df.describe())
median_math = df['math_score'].median()
iqr_math = stats.iqr(df['math_score'])
print(f"Math Median: {median_math}, IQR: {iqr_math}")
sns.boxplot(df['math_score'])
plt.title('数学成绩箱线图')
plt.show()
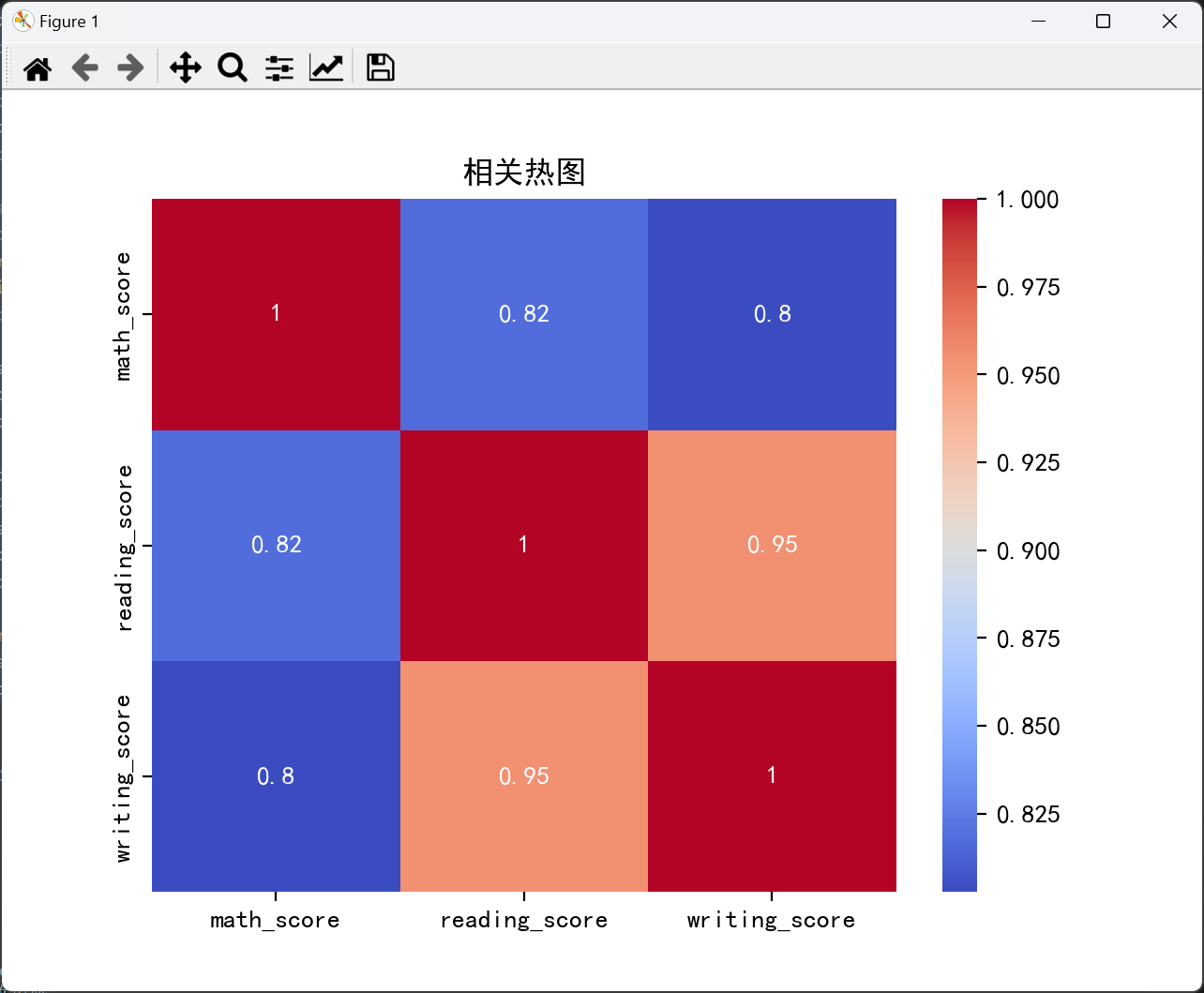
corr = df[['math_score', 'reading_score', 'writing_score']].corr()
print("相关系数矩阵:\n", corr)
sns.heatmap(corr, annot=True, cmap='coolwarm')
plt.title('相关热图')
plt.show()
mean_math = df['math_score'].mean()
sem_math = stats.sem(df['math_score'])
ci = stats.t.interval(0.95, len(df['math_score'])-1, loc=mean_math, scale=sem_math)
print(f"数学分数的95%置信区间: {ci}")
male_scores = df[df['gender'] == 'male']['math_score']
female_scores = df[df['gender'] == 'female']['math_score']
t_stat, p_val = stats.ttest_ind(male_scores, female_scores)
print(f"男性和女性数学分数之间的t检验: t={t_stat}, p={p_val}")
df_encoded = pd.get_dummies(df, drop_first=True)
X = df_encoded.drop('math_score', axis=1)
y = df_encoded['math_score']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = LinearRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, y_pred)
print(f"\n模型评估:")
print(f"平方误差 (MSE): {mse}")
print(f"根平方错误 (RMSE): {rmse}")
print(f"R-squared (R2): {r2}")
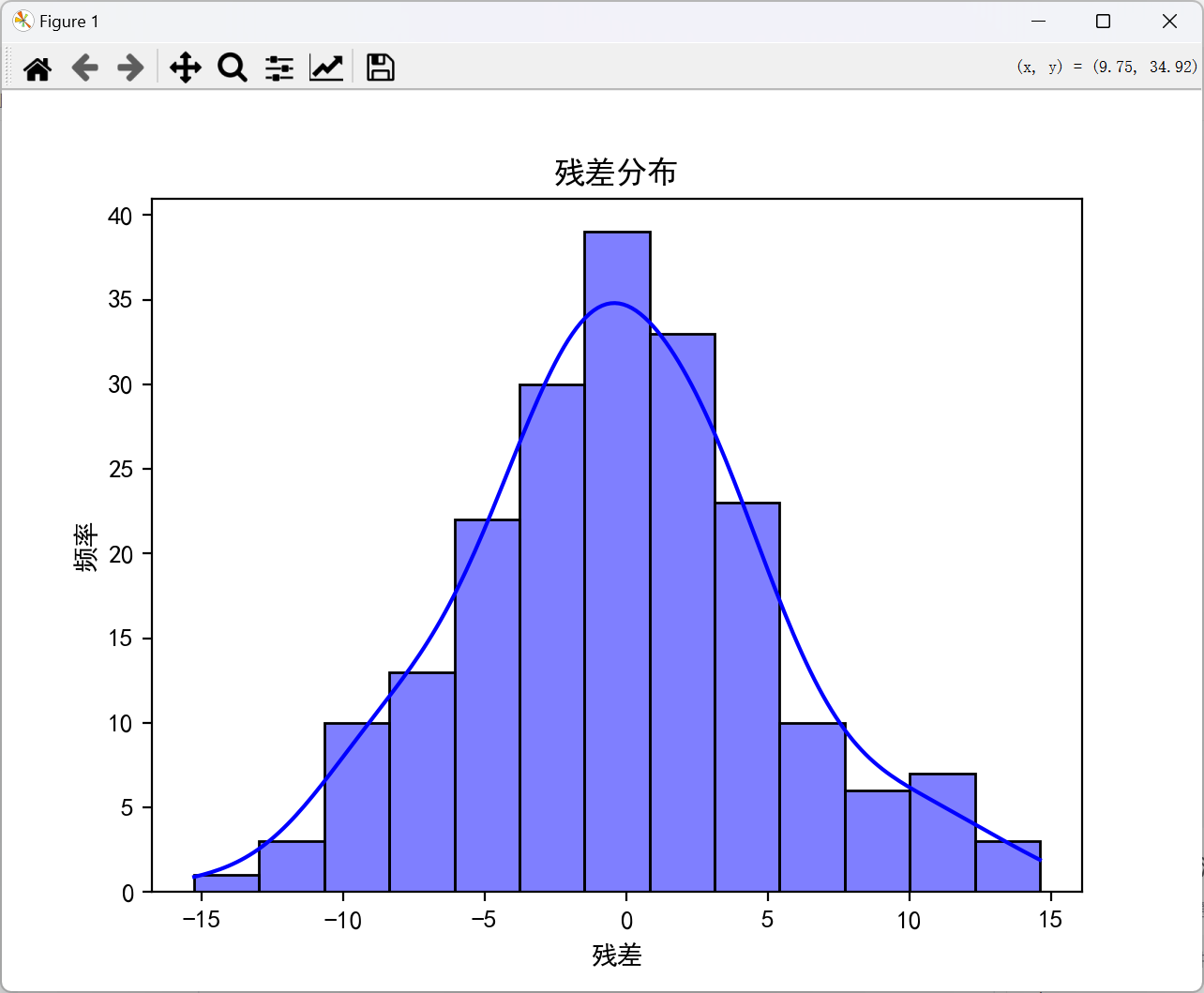
residuals = y_test - y_pred
sns.histplot(residuals, kde=True, color='blue')
plt.title('残差分布')
plt.xlabel('残差')
plt.ylabel('频率')
plt.show()
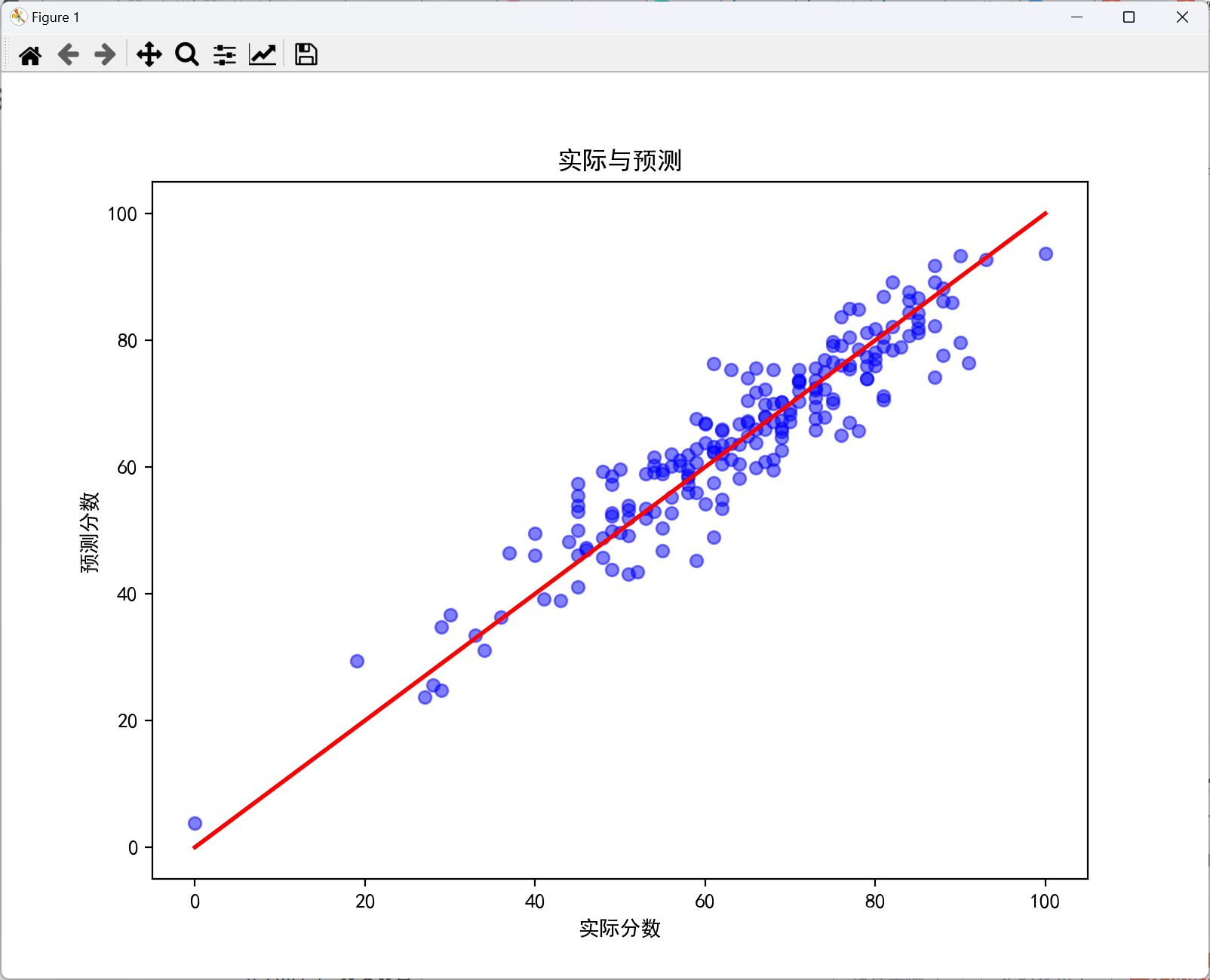
plt.figure(figsize=(8,6))
plt.scatter(y_test, y_pred, color='blue', alpha=0.5)
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], color='red', linewidth=2)
plt.title('实际与预测')
plt.xlabel('实际分数')
plt.ylabel('预测分数')
plt.show()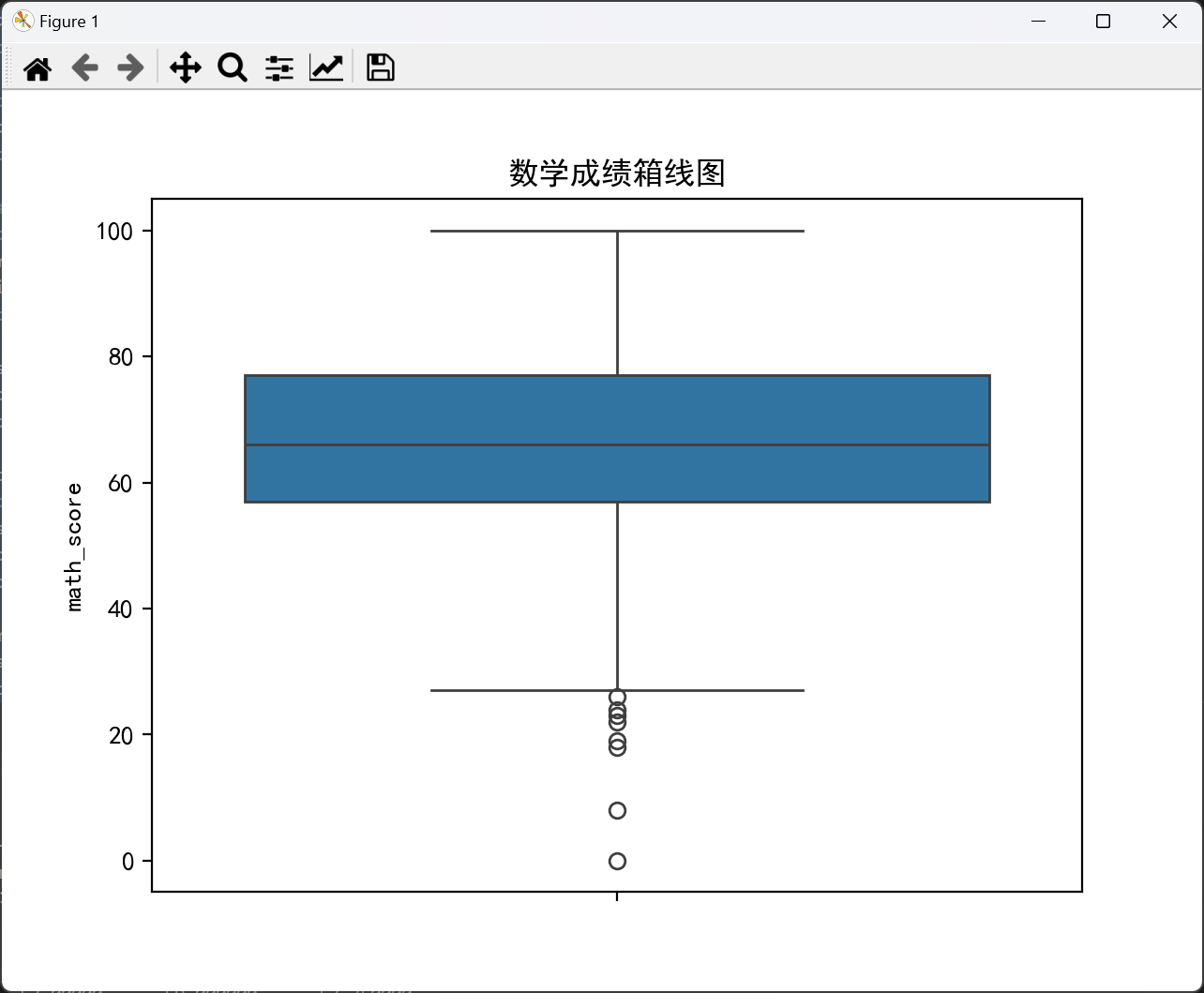

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)