[实战]如何使用主成分分析法(PCA)进行数据降维
本文将通过 Python 代码实现 PCA 降维,并使用波士顿房价数据集进行演示。我们将从数据加载、模型训练到 PCA 降维和数据可视化全方位地展示 PCA 的作用和原理。以期读者对 PCA 有更深入的理解。
1、引言
随着数据量的不断增加和数据维度的不断扩展,如何进行高效的数据降维处理成为了一个热门话题。在数据分析领域,PCA算法作为一种常用的数据降维方法,可以对多个特征进行降维,提高计算效率和降低存储空间需求。本文以波士顿房价数据集为例,探讨如何利用PCA算法对房屋价格进行降维。
本文将通过 Python 代码实现 PCA 降维,并使用波士顿房价数据集进行演示。我们将从数据加载、模型训练到 PCA 降维和数据可视化全方位地展示 PCA 的作用和原理。以期读者对 PCA 有更深入的理解。
本期内容『数据+代码』已上传百度网盘。有需要的朋友可以关注公众号【小Z的科研日常】,后台回复关键词[PCA降维]获取。
2、加载和处理数据
我们将使用 Pandas 库加载波士顿房价数据集,并通过插值法填充缺失值,从而为后续的降维做好准备。首先,我们使用 pd.read_csv() 函数加载了名为 'HousingData.csv' 的数据集。接着,我们使用 isnull() 和 any() 函数检查数据集中是否有缺失值。若存在缺失值,则使用 interpolate() 函数进行插值法填充。然后,我们创建特征矩阵 X 和目标向量 y,同时对特征矩阵进行标准化,以方便后续的模型训练。
3、模型训练
我们需要将数据集分成训练集和测试集,并使用交叉验证选择最优的降维数量。我们使用 train_test_split() 函数将特征矩阵 X 和目标向量 y 分成训练集和测试集(test_size=0.2 表示训练集占80%,测试集占20%)。接着,我们使用 range() 函数建立了一个 range 对象,其中包括了从 1 到特征数的所有整数值。我们将用这个 range 对象控制循环的次数,以便逐渐增加主成分的数量。
对于每个 n_components 值,我们都训练了一个 PCA 模型,并在交叉验证下计算了模型的 R2(即得分)。最后,我们可视化了 R2 分数与使用的主成分数量之间的关系。图表展示出降维数量与其得分的关系,为后续的PCA降维做好准备。
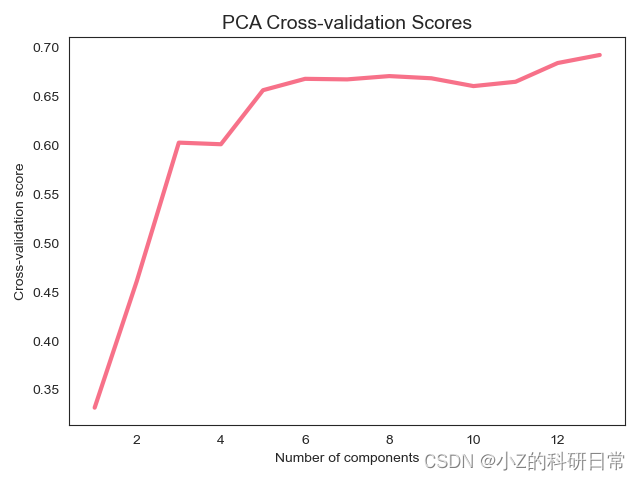
通过上图,横轴为选取特征数量,纵轴为其得分,我们可以根据实际情况选取相应的降维数量。接下来,我们将通过计算协方差矩阵和特征值、特征向量来进行PCA降维。
4、PCA降维
在本节中,我们将通过计算协方差矩阵和特征值、特征向量来进行PCA降维,并选择前k个最大的特征值所对应的特征向量作为主成分。
#关注微信公众号:小Z的科研日常 获取完整代码
# 计算协方差矩阵
cov_matrix = np.cov(X.T)
# 计算特征值和特征向量
eigenvalues, eigenvectors = np.linalg.eig(cov_matrix)
# 特征值从大到小排序
sorted_idx = eigenvalues.argsort()[::-1]
eigenvalues = eigenvalues[sorted_idx]
eigenvectors = eigenvectors[:, sorted_idx]
# 选择前k个最大的特征值所对应的特征向量作为主成分
k = 4 # 根据交叉验证手动选择最优k值
principal_components = eigenvectors[:, :k]
# 将原始数据投影到由选定的主成分构成的新空间中
new_data = np.dot(X, principal_components)首先,我们使用 np.cov() 函数计算出特征矩阵 X 的协方差矩阵。接着,我们使用 np.linalg.eig() 函数计算协方差矩阵的特征值和特征向量。然后,我们按特征值从大到小排序,以便能够选择前k个最大的特征值所对应的特征向量作为主成分。在此例中,我们根据交叉验证手动选择了最优的k值为4。
最后,我们通过 np.dot() 函数将原始数据投影到由选定的主成分构成的新空间中。这样就实现了对数据的降维处理。接下来,我们将通过数据可视化来更好地理解PCA降维的效果。降维后的4个特征平行坐标图如图:
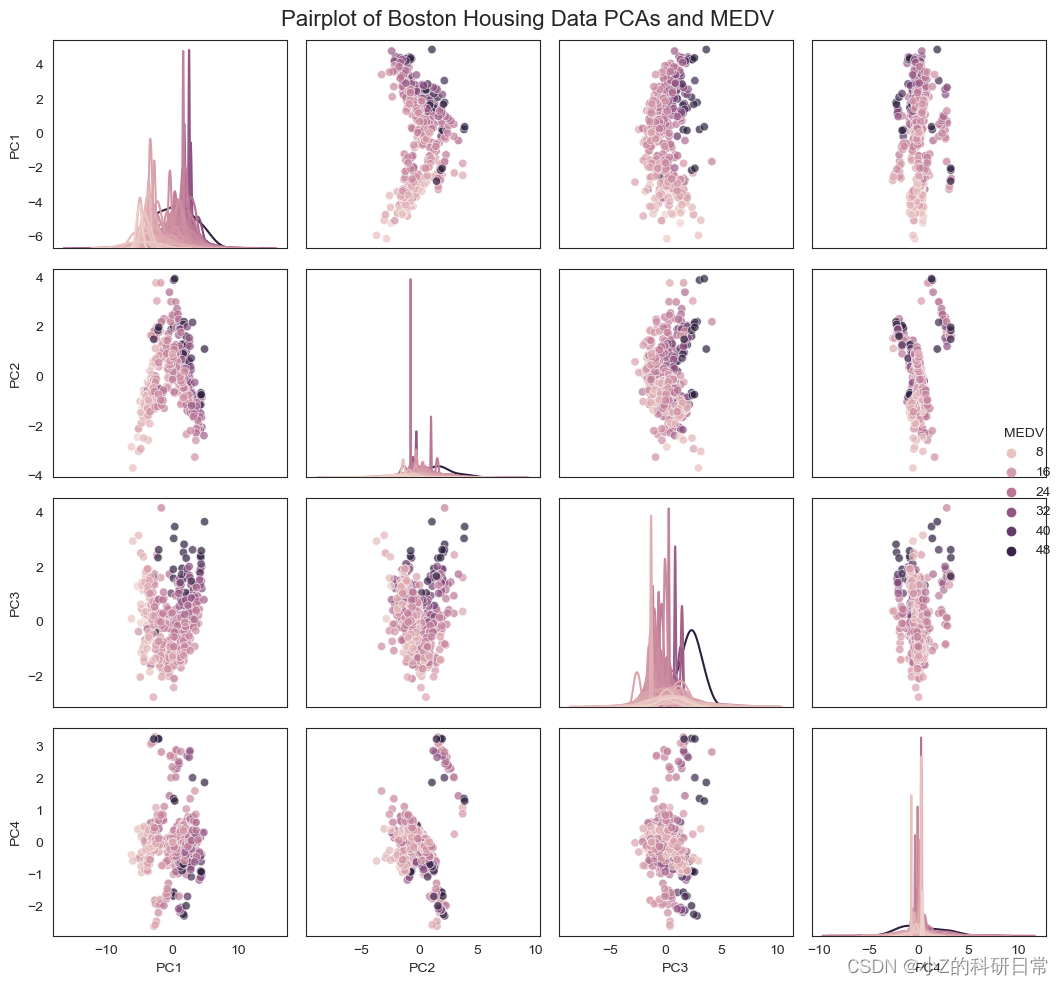
感谢您阅读本篇文章!如果您对降维技术和机器学习等方面感兴趣,欢迎关注我们的微信公众号(小Z的科研日常)。文章完整源码可通过关注公众号回复关键词[PCA降维]获取。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)