21.损失函数与反向传播
torch.nn 里的 loss function 衡量误差,在使用过程中根据需求使用,注意输入形状和输出形状即可loss 衡量实际神经网络输出 output 与真实想要结果 target 的差距,越小越好计算实际输出和目标之间的差距为我们更新输出提供一定的依据(反向传播):给每一个卷积核中的参数提供了梯度 grad,采用反向传播时,每一个要更新的参数都会计算出对应的梯度,优化过程中根据梯度对参数
损失函数与反向传播
损失函数
损失函数(Loss Function)是用来度量模型预测值与真实标签之间差异的函数。它接受模型的输出和真实标签作为输入,并输出一个数值,该数值表示模型预测的错误程度或差异程度。损失函数通常被设计成非负的,当模型预测值与真实标签完全一致时,损失函数达到最小值。
损失函数大致可以分成两类:回归(Regression)和分类(Classification)。
常见的损失函数:
交叉熵损失函数(Cross-Entropy Loss):
用于多分类任务,特别是在类别互斥的情况下;
均方误差损失函数(Mean Squared Error Loss):
用于回归任务;
计算模型输入与真实标签之间的平方差;
平均绝对误差损失函数(Mean Absolute Error Loss):
用于回归任务;
计算模型输出与真实标签之间的绝对差;
反向传播
反向传播(Backpropagation):反向传播是深度学习中的一种核心算法,用于计算损失函数对模型每一个参数的梯度。在优化模型参数(例如使用梯度下降算法)的过程中,我们需要知道模型每一项参数的梯度方向,以此来更新参数。
反向传播算法工作流程如下:
前向传播(Forward Pass):数据沿着从输入层至输出层的方向进行传播,经过每一层的操作,最终在输出层产生预测值。
损失计算:根据模型的预测值和真实值,使用损失函数计算损失。
反向传播(Backward Pass):根据链式法则(Chain Rule),从输出层开始,沿着网络的结构向反方向(输入层方向)回传,计算损失函数对每一层参数的梯度。
反向传播能够有效地计算损失函数关于每一个参数的梯度,结合优化算法(如SGD,Adam等),这使得我们可以通过梯度下降法更新模型的参数,进而训练我们的模型。(上面说的训练的目标就是找到一组参数可以最小化损失函数,这里更新参数就是为了这个目的)
总结
torch.nn 里的 loss function 衡量误差,在使用过程中根据需求使用,注意输入形状和输出形状即可
loss 衡量实际神经网络输出 output 与真实想要结果 target 的差距,越小越好
作用:
- 计算实际输出和目标之间的差距
- 为我们更新输出提供一定的依据(反向传播):给每一个卷积核中的参数提供了梯度 grad,采用反向传播时,每一个要更新的参数都会计算出对应的梯度,优化过程中根据梯度对参数进行优化,最终达到整个 loss 进行降低的目的
梯度下降法:
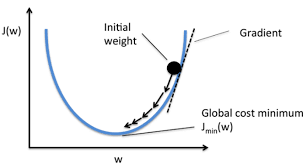
1. L1LOSS

input:(N,*) N是batch_size,即有多少个数据;*可以是任意维度
CLASS torch.nn.L1Loss(size_average=None, reduce=None, reduction='mean')
小例子:

代码
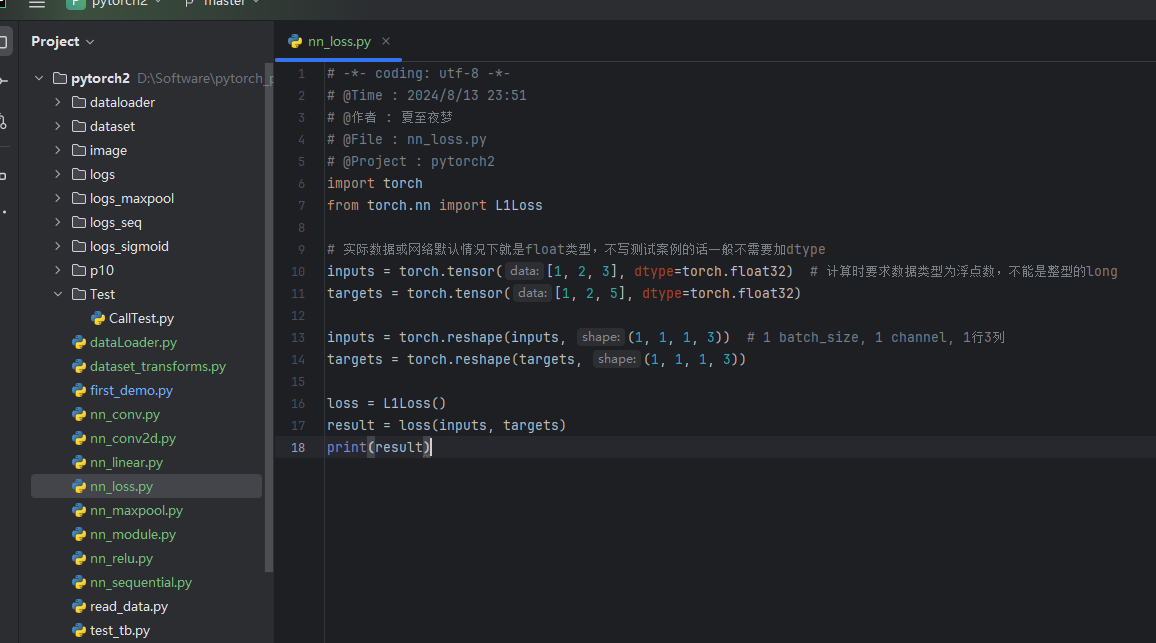
import torch
from torch.nn import L1Loss
# 实际数据或网络默认情况下就是float类型,不写测试案例的话一般不需要加dtype
inputs = torch.tensor([1,2,3],dtype=torch.float32) # 计算时要求数据类型为浮点数,不能是整型的long
targets = torch.tensor([1,2,5],dtype=torch.float32)
inputs = torch.reshape(inputs,(1,1,1,3)) # 1 batch_size, 1 channel, 1行3列
targets = torch.reshape(targets,(1,1,1,3))
#L1Loss默认求均值的方式
loss = L1Loss()
#L1Loss改成求和的方式
#loss = L1Loss(reduction='sum')
result = loss(inputs,targets)
print(result)
运行结果:
tensor(0.6667)
L1Loss可以选择计算的方式,修改成求和的方式:
修改上述代码中的一句即可
loss = L1Loss(reduction='sum')
运行结果:
tensor(2.)
2.MSELOSS(均方误差)
input:(N,*) N是batch_size,即有多少个数据;*可以是任意维度
CLASS torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')

添加如下几行代码:
from torch import nn
#MSELOSS(均方误差)
loss_mse = nn.MSELoss()
result_mse = loss_mse(inputs, targets)
print(result_mse)

结果:
tensor(1.3333)
上述代码的例子:

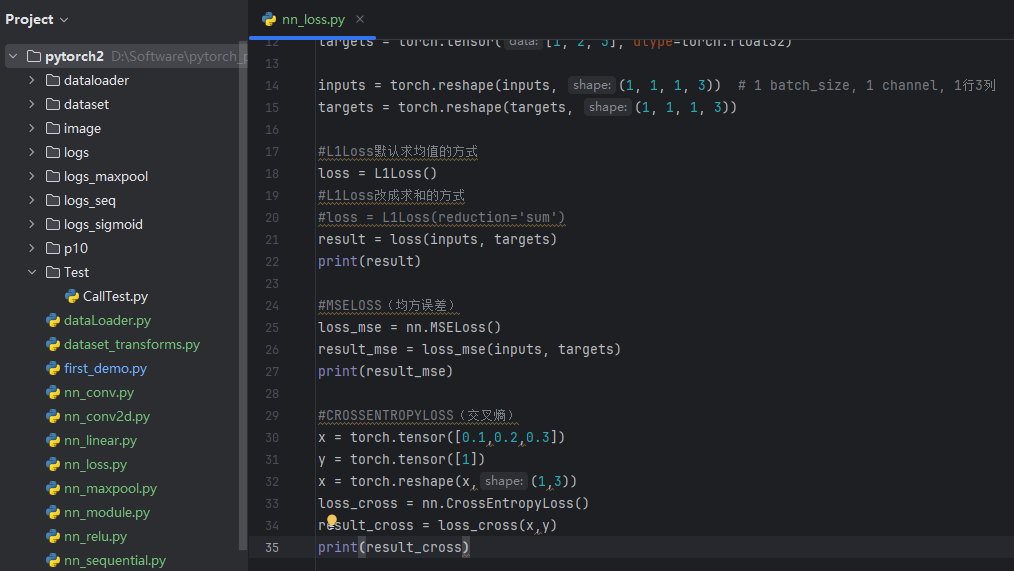
3. CROSSENTROPYLOSS(交叉熵)
适用于训练分类问题,有C个类别
**例:**三分类问题,person,dog,cat

(公式中的 log 可以按 ln 算)
这里的output不是概率,是评估分数

添加如下代码:
#CROSSENTROPYLOSS(交叉熵)
x = torch.tensor([0.1,0.2,0.3])
y = torch.tensor([1])
x = torch.reshape(x,(1,3))#把x变成交叉熵要求的input格式(N,C)N为batch_size,C为类别数
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x,y)
print(result_cross)
结果:
tensor(1.1019)
4.如何在之前写的神经网络中用到 Loss Function(损失函数)
import torchvision.datasets
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=1)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x): # x为input
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
tudui = Tudui()
for data in dataloader:
imgs, targets = data # imgs为输入,放入神经网络中
outputs = tudui(imgs) # outputs为输入通过神经网络得到的输出,targets为实际输出
result_loss = loss(outputs, targets)
print(result_loss) # 神经网络输出与真实输出的误差

结果:

5.backward 反向传播
计算出每一个节点参数的梯度
在上述代码result_loss = loss(outputs, targets)后加一行:
result_loss.backward() # backward反向传播,是对计算出来的result_loss,而不是对loss
在这一句代码前打上断点(运行到该行代码的前一行,该行不运行),debug 后: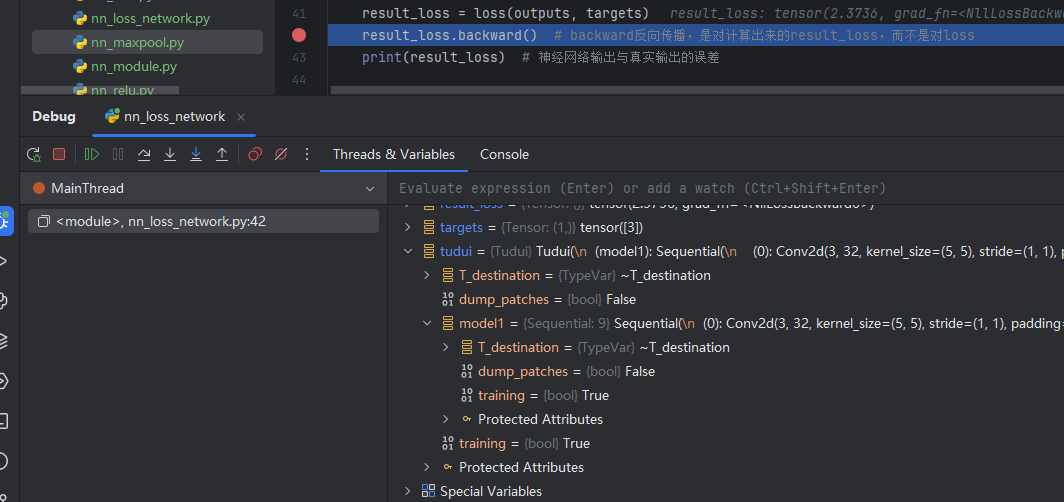
tudui ——> model 1 ——> Protected Attributes ——> _modules ——> ‘0’ ——> bias / weight——> grad(是None)

点击Step into My Code,运行完该行后,可以发现刚刚的None有值了(损失函数一定要经过 .backward() 后才能反向传播,才能有每个需要调节的参数的grad的值)

下一节:选择合适的优化器,利用梯度对网络中的参数进行优化更新,以达到整个 loss最低的目的
one)
[外链图片转存中…(img-o6bLsm5T-1724861861970)]
点击Step into My Code,运行完该行后,可以发现刚刚的None有值了(损失函数一定要经过 .backward() 后才能反向传播,才能有每个需要调节的参数的grad的值)
[外链图片转存中…(img-KvOrYXrm-1724861861970)]
下一节:选择合适的优化器,利用梯度对网络中的参数进行优化更新,以达到整个 loss最低的目的

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 27
27 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)