【论文阅读】RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds
一种语义分割的神经网络,采用局部空间编码、注意力池化和扩张残块进行取样的增强
上岸以后第一次做这种读论文的任务,该怎么读、怎么学都还在一点一点摸索,这里记录一下看论文的过程中的一些思考以及不明白的地方。
一、简介
在大规模的3D点云识别中,想要做到高效的语义分析是一个不简单的任务,现有的技术主要是依赖于复杂的取样技术以及包含有繁重计算的预处理和后处理,而这篇论文提出的RandLA-Net是一种高效而且轻量级的技术,最主要的是可以用在大型的点云中。这个技术的关键是用随机点取样来代替其它复杂的取样技术,由于随机取样可能会带来关键信息的丢失,所以为了防止丢失有引入了局部特征聚合这一关键技术,通过这两个技术的配合使用,能够兼顾高效和数据量。
也就是说,整个算法的关键是在不损失局部特征的前提下,通过随机取样来代替其它复杂的取样方式,从而实现数据量和效率的提高。
二、取样
前面提到了,整个算法的第一个要点是取样,毕竟点云那么多点,每个点都用数据量实在是大得惊人,所以需要通过取样,选取一部分点进行计算,这样在不影响判断的情况下简化数据。
现有的取样方式主要是分为两类,即启发式和基于学习的取样,下面简单翻译一下论文里面的关键信息:
①启发式采样
a-最远点采样(Farthest Point Sampling)
这种采样方式,给我最直观的感受就是一个反向的dijkstra算法,这个算法并不难,首先选择一个初始点a,之后初始化一个距离数组,记录剩下点到这个初试点的距离,选择里面最远的点加入集合,假设加入的点为b,那么现在集合里面有点a和b,之后计算b到所有点的距离,如果这个距离小于距离数组中记录的值,就更新为到b的值,全部更新完之后,将距离最大的点加入集合,重复操作知道采样的数目达到要求。
可见这个距离数组记录的实际上是剩下所有点到集合的最短距离,每次加入集合的点都是最远的点,所以叫最远点采样。这种采样方式在小范围的点云中应用比较广泛,但是如果放在大范围的点云中,缺点也很直观,基本就是一个暴力的运算,这个算法的时间复杂度可以达到o(N2),所以点一旦多了起来,耗时会特别大。所以在大范围的点云中,并不能采用这种方式
b-反密度重要性采样(Inverse Density Importance Sampling)
这种采样方式是不是这么叫我也不确定,百度没找到正确的名字,有道机翻的。这种采样方式和名字一样,就是根据密度进行选择,而选择的方式是选择密度低的点。对于这种采样方式,相比于FPS时间复杂度的提升是很明显的,但是由于需要计算密度,对噪音比较敏感。此外尽管时间复杂度已经有了一定的改善,但是对于实时系统而言,仍然是达不到标准。
在论文最后的appendices部分中补充了这里密度计算的方法,给出一个点,密度并不是像物理上那样计算,而是利用距离,这里的密度其实是一个距离和,计算这个点周围的最近的t个点的距离之和作为密度,然后选择点的时候,根据密度的倒数来进行选点,也就是选择密度小的点。
c-随机采样(Random Sampling)
这种采样方式是这片论文所采用的方式,随机采样公平地从所有点中选择一定数目的点,由于是等概率的随机选择,所以时间复杂度是O(1),其计算量与输入点云的总数并没有关系,只与要采样的点的数目有关,在实时性和扩展性上都表现不错,尽管在数据量上还是有一点限制,但是时间复杂度的性能已经优于FPS和IDIS太多。
②基于学习的采样
a-基于生成器的采样(Generator-based Sampling)
与传统的采样方式不同,这种采样方式通过学习生成一个子集来近似表征原始的点云,相当于训练了一个替身,但是缺点也很致命,这种方式在匹配子集的时候需要使用FPS,前面也提到了,FPS的时间复杂度特别大,所以相当于是使用了一个特别费时间的工具去完成一个任务,所以引入了更复杂的过程,时间复杂度也上升了。
b-基于连续松弛的采样(Continuous Relaxation based Sampling)
也没有合适的译名,有道机翻的。这种采样方式是用大量的矩阵计算,得到的每个采样点实际上是整个点云的一个加权和。这个方式出发点是好的,但是采用了矩阵去计算,反而导致开销变大了。
c-基于策略梯度的采样(Policy Gradient based Sampling)
本身属于一种马可夫决策过程,采用概率分布去进行采样,但是由于采用了排列组合去产生搜索空间,所以当用于大型点云的时候,网络十分难收敛。
总结一下论文中提到的六种采样方式,FPS/IDIS/GS这三种方式在用于大型点云时时间复杂度都太大,CRS需要额外的存储空间,PGS在大型点云的情况下难以收敛。但是正相反,随机采样一方面时间复杂度有着绝对优势,另一方面也不需要额外的存储空间。因此选择随机采样作为算法的一个关键。
但是随机必然带来了一定的不确定性,也就是说一些关键的信息可能会丢失,为了防止丢失,需要采取一定的方式来留着重要的信息,这也就引出了这个算法另外一个重要的部分:局部特征聚合。
三、局部特征聚合
从名字就可以看出来,聚合的是局部的特征,用来防止采用随机采样而将重要数据丢失。局部特征聚合的总图示如下: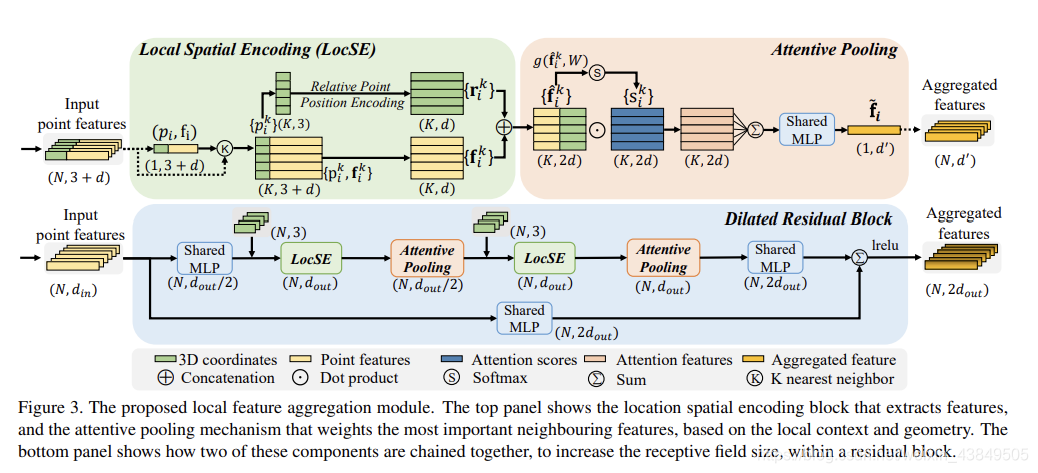
局部特征聚合主要是三个部分:局部空间编码、注意力池化和扩张残块。下面记录一下三个部分:
①局部空间编码
这部分的主要目的个人的理解是将特征进行扩充,首先输入的数据是包含各种特征的向量,输出的结果是扩充后的特征向量。
局部空间编码主要是三步:
a-寻找临近点
给定N个点,对每个点使用一次KNN算法,找出欧式距离最近的K个点。
b-相对位置编码
这一部分最好结合图片去理解,根据上面的图示,绿色部分是局部空间编码,其中选中的点利用KNN算法变成了K个点,每个点有3+d个属性,其中3代表三维空间的位置坐标,d代表特征属性,将三维坐标取出来,就是K个三维向量,这些向量做下面的操作: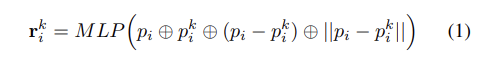
结合上面的图,这个公式的意思就是将中心点的三维坐标、当前点的三维坐标、相对坐标、欧式距离给连接起来,之后利用MLP对维度进行调整,调整成长d的向量。
这一部分关于MLP的部分实在是没有在网上查到对应的解释,下面这部分属于自己的猜测。把里面这几个向量连接起来,长度实在是奇怪,pi长度是k×3,pik长度是k×3,相对位置也是k×3,最后一个欧氏距离就一个数字,连接起来是k×10,而图里面最后得到的是一个k×d的矩阵,网上的解释都是连接起来就可以了,但是连接起来之后的大小不对啊,于是我想会不会差别在这个MLP上,查了一下MLP,在这位大佬的博客里貌似是看懂了一些:
https://blog.csdn.net/Passersby__/article/details/104941591
也就是说MLP有着实现特征转换,信息重组的作用,所以是不是说这里的MLP就是调整维度的意思,将原本的矩阵调整为k×d的矩阵,方便后面的计算。
c-点特征增强
这一步就没什么难理解的地方了,将前面扩充的矩阵和原本剩下的矩阵拼起来就好,最后结果是一个k×2d的矩阵。
对于局部特征编码,个人理解是一个补充信息的过程,假设没有这个过程,送入下一步的数据就是我们一开始选中的N个点的点云信息,完全是单独的点,而没有点周围的信息,所以根本体现不了局部的信息,而引入了这个过程后,对于每个点,我们利用KNN算法扩充成了K个点,而且在这个点的基础上新增了周围点的信息,使得可以处理的信息更多了,也就是说现在这个点具有了代表周围空间的潜力,说白了就是变成了AOE伤害。
②注意力池化
经过前面的局部特征编码,我们将选择的一个点变成了一组扩展细节之后的向量,这组向量代表着周围一定范围的信息,接下来要做的就是对这组向量进行一定的处理,将一组临近点的信息整合为一个特征向量。注意力池化主要分为两个步骤:计算注意力值和加权求和。下面分别记录一下两个步骤。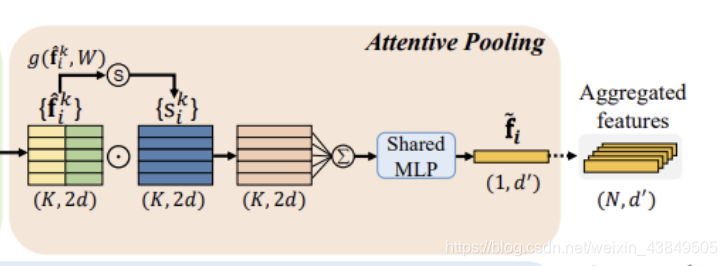
a-计算注意力值
这一部分主要是根据局部特征编码得到的矩阵,计算得到一个新矩阵。论文里面的原话是说需要设计一个共用的函数g(),利用这个函数来学习一个特征向量对应的注意力值,其中在计算过程中需要用到一个共享MLP,所以sik的计算应该是下面的式子: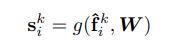
其中W是共享MLP的可学习权重。关于共享MLP,依然是从上面的那位大佬的博客里看的,大佬的原话为:“Shared MLP 是点云处理网络中的一种说法,强调对点云中的每一个点都采取相同的操作。其本质上与普通MLP没什么不同,其在网络中的作用即为MLP的作用:特征转换、特征提取”。基于这个思路,个人感觉计算ski的过程就像是生产猪肉的流水线,质检人员拿着章往猪肉上面戳,戳完以后猪肉就成了检疫合格的猪肉,而对于函数g,它的作用就像是检疫人员,所有送来的fki就是猪肉,用W来盖章,运算后得到的ski就是检疫合格的猪肉。
b-加权求和
这一步主要还是利用前面学习的注意力值来加权求和,论文里面说前面的注意力值可以看做一个可以自动筛选重要信息的soft mask,关于这个翻译,有道翻译的是软膜,个人总感觉奇奇怪怪的,不过仔细想一下确实很形象,用高中化学的膜知识去比喻的话,让符合特征的粒子通过膜而不让不符合特征的粒子通过,换到论文的背景里面,这个soft mask就是一个筛选的作用,将周围点信息进行筛选,得到的就是精简之后的特征向量。特征向量应该按照下面的式子进行计算: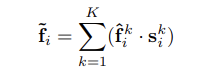
关于这个地方,在阅读的时候迷惑了很久,最终也许是解释通了,记录一下当时的思路。按照图示的流程,我们是利用局部特征编码生成的k×2d的矩阵作为输入,利用函数g计算得到一个矩阵s作为膜,输入矩阵f再和膜矩阵s计算,求和之后作为一个点的特征向量。那么从计算公式来看,这是两个向量做了点乘,那么向量点乘的结果应该是一个数字,而求和之后还是一个数字,所以这样想的话这个特征向量是个数而不是向量了。反过来看这个过程,注意力池化的最终结果是N个特征向量,N表示我们在局部特征编码之前选中的N个点,我们对每个点都进行了编码-池化,所有有N个向量,所以就是说对于一个点,在编码池化之后产生的实际上是一个特征向量,这个特征向量代表了这个点周围的信息,所以前面结果是数的思路必然是存在问题的,继续倒着看这个过程,一个点的最终的特征向量是求和后经过MLP得到的,MLP如果看作一个调整维度的过程,那么求和就是将中心点周围的K个点的特征向量相加,求和在公式里有体现,所以这里的点乘个人感觉应该不是正常情况下的点乘,应该是对应位置相乘,只有这样整个矩阵的大小才能对应起来。如果按照这样理解,正向的过程应该是矩阵f先利用函数g得到一个膜矩阵s,之后f中的每个向量都和s上对应行上的向量计算,计算过程每个元素都相乘,得到的依然是一个向量,这样结果拼起来仍然是一个k×2d的矩阵,在将每个向量求和,得到一个1×2d的向量,这个向量通过MLP调整,最终得到这个中心点的特征向量,对一开始的N个点都执行一次,得到了N个这样的特征向量。
这样其实最重要的两个模块就已经很清楚了,局部信息编码是扩充信息的过程,将一个点的信息变成了一个范围的点的信息,再经过注意力池化,将范围的点的信息再次整个为一个向量,也就是用一个点来代表一个范围,从而实现了对范围信息的整合。经过这两个步骤,一开始N个长度为3+d的向量显示变成了N×K×2d的向量组,之后经过注意力池化,变成N个1×d‘的向量,这些向量包含着一开始N个点周围的信息。
③扩张残块
扩张残块为什么叫这个名字我也还没理解清楚,总之看介绍这部分就说了一件事,在RandLA-Net中选择使用两轮的局部信息编码和注意力池化。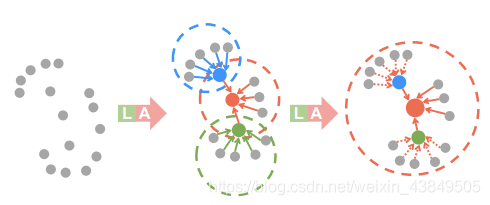
由于大的点云将大幅向下采样,因此需要显著增加每个点的感知域,这样即使一些点被删除,输入点云的几何细节也更有可能被保留。对于这段话我的理解就是需要扩充每个点的信息范围,不能只留着自己的信息,而是应该保存周围的信息,这样即使点被删除了也不会产生太大的影响。这里就用到了前面的两个步骤。
一般来说采用的轮(一次编码一次池化)数越多,最终得到的点能代表的范围信息就越大,但是轮数过多会牺牲一定的计算效率,而且容易导致过拟合,所以在RandLa-Net中使用两轮就可以了,这样就可以实现效率和效果的平衡。
四、实验
为了证明上面的过程有着足够的说服力,论文后面的第四部分是实验,用实验数据展示了RandLA-Net在不同的数据集中的效率。
首先实验检验了随机采样的效率,对比的是前面提到过的剩余五种采样方式,实验过程分别采用规模大小不同的点云数据,这样就可以比较不同采样方法在不同的规模下的效果,同时比较时间效率和GPU的内存,比较的结果如下: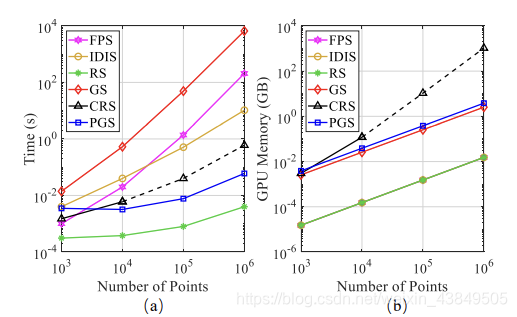
可以看出,点云规模不大的时候所有的采样方式的时间消耗都差不多,内存消耗上RS会小一些,但是其它的都差不多,也就是说规模不大的情况下,无论采用哪一种采样方式其实都差不多,都不会达到明显的壁垒。但是随着点云规模的增大,不同采样方法的差异也就体现出来了,当点云规模扩大到10^6时,可以看出像GS这种采样方式的时间消耗已经高到离谱了,这正好对应前面提到的,GS利用了FPS进行匹配,难上加难,所以时间复杂度直接拉满,而RS能够以一个增长不缓慢的速度上升。而内存消耗方面,CRS由于采用了矩阵计算,需要额外的空间,所以空间开销变大,而RS仍然可以在众多采样方式中处于一个最低的状态。从这两点完全可以证明采用随机采样的效率是优于其余采样方式的。
此外实验还检验了RandLA-Net和其它大规模点云语义分割算法的优越性,结果如下: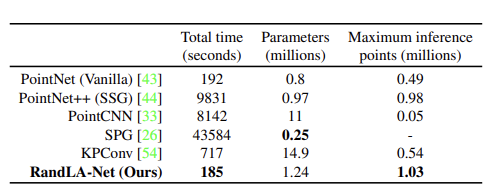
这一部分由于没有接触过其它的算法,也不是很清楚比较的第二项是个啥,所以也就一知半解。SPG在网络参数上最优,但是RandLA-Net也没有很拉夸,总时间上RandLA-Net是最优秀的,而且最大的点值也是第一,充分标明RandLA-Net是优秀的。
最后实验将RandLA-Net算法实际应用在了三个数据集上,比较了三个数据集上运行的结果。
①Semantic3D数据集
这个数据集包括15个点云数据,每个点云包括10^8个点,每个点除了3D位置信息还包含有RGB信息和密度信息。在运行算法的时候,采用mIoU和OA两个标准作为度量进行比较,最终结果为: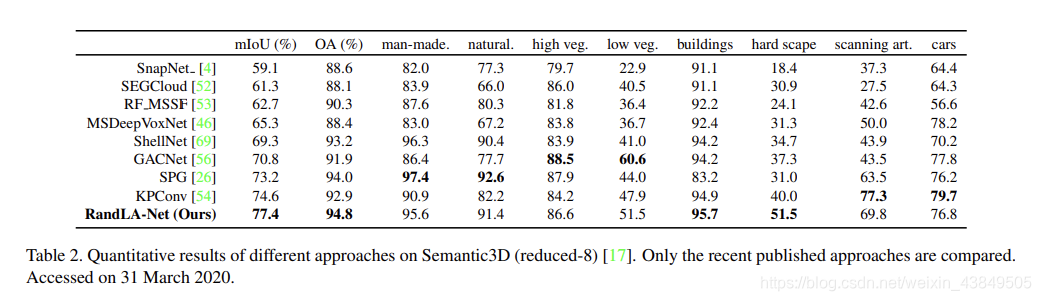
②SemanticKITTL数据集
这个数据集包含有43552个带有注解的LIDAR扫描数据,分为21个序列,其中10个序列用来训练,1个用来核验,10个用来检测,最终的比较结果为: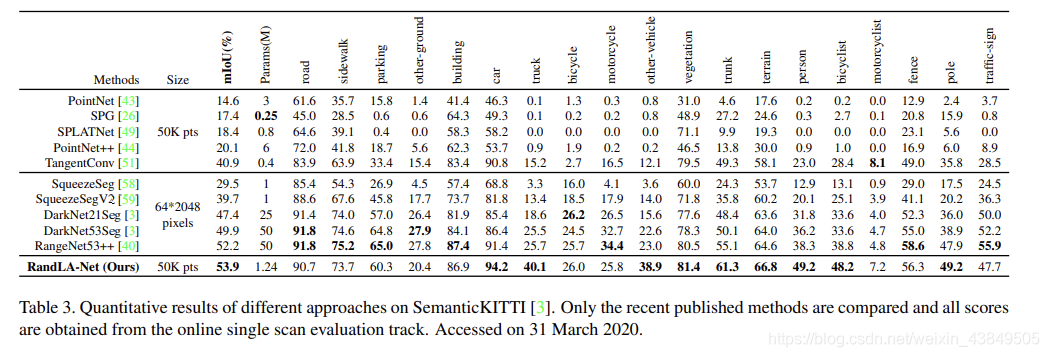
③S3DIS数据集
这个数据集由分属于6个域的271个空间组成,比较结果如下: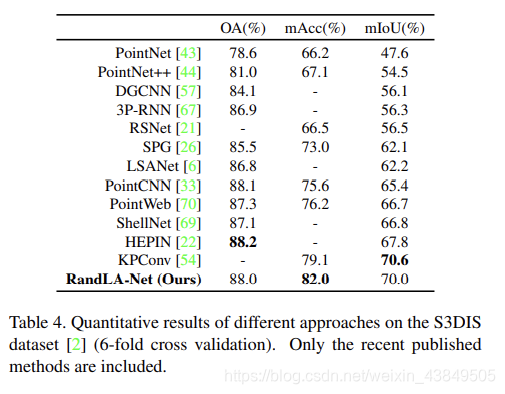
通过这些实验,充分证明了RandLA-Net算法的效率确实是优于现在其余的算法的。
五、后续
这一部分是附带在论文后面的,主要是一些论文里作为支撑的一些观点,把里面有点理解的地方在这里放一下。

这个是论文appendices部分里面叙述的整个RandLA-Net的结构,整个结构从大的层面上分分成四轮的编码解码、输入、最终语义分割以及网络的输出。这里面的一层实际上对应的是一个箭头,而不是一个方框,方框是经过一层的处理之后数据的规模。
输入部分,就是图里面最左边的点云,由N个点组成,每个点的属性数目用din表示,这个din根据数据集的不同也有所差异,但是至少都含有三维坐标系下的坐标。
数据用一个全连接层输入之后,跟着的是四组编码解码(论文里面用的是encoding layer 和 decoding layer),先看编码的部分,所谓编码,最基本的一个目的就是减小点云中点的数目并且增加单个点所包含的信息量,这里每一层编码都是一轮的随机取样加上局部特征聚合。每一层的处理都会让点的数目缩小为原来的四分之一,并且让特征向量的维度变为原来的四倍。
在看的时候在这里产生了一点疑问,每次缩小点的数目增大特征向量的维数是怎么实现的,回看了一下前面关于局部特征编码和注意力池化的部分,也是在这里纠结了很久,后来发现是自己思路错了,这里是每一层进行一轮的随机取样和局部特征聚合,而局部特征编码和注意力池化是局部特征聚合里面的步骤,这完全是两码事,也就是说如果想实现缩小点的规模,可以在随机取样的部分进行修改,比如说可以设置随机取样的点的数目为总点数目的四分之一,而特征向量的维数增加就需要靠局部特征聚合了,从局部特征聚合的示意图可以看出,每个点的特征从输入前的d+3,经过局部特征编码变成了2d,经过注意力池化可以再经过MLP进行变化,完全可以实现维数的增加。
另外在这里还出现了一个误解,前面提到了最合适的轮数是进行两轮,而这里进行了四轮,一开始以为是我哪里看落下了,后来发现完全是自己混淆了,再次强调这里的一轮是一轮随机取样加上局部特征聚合,而前面进行两轮是在扩展残块那里,是两轮的局部特征编码和注意力池化,完全是两码事。
经过四层的编码之后,是两层的小处理,这部分在论文里并没有单独的介绍,对这部分我个人的理解是在进行调整数据。之后又是四层的解码层,对于每一层,都使用KNN算法来找出每个点的最临近点,使用最临近插值来放大数据。之后将放大后的特征地图与原来的编码后的地图进行连接。
解码完成后就可以进行最后的语义分析,利用三层的全连接层进行分析,并且还用了一层的dropout层,dropout如果没记错的话在学长发的无人驾驶原理里面提到过,是防止过拟合用的,随机丢弃一部分的节点来降低拟合程度最终防止过拟合。
最后记录一下现在对RandLA-Net的理解吧,这个算法或者说是框架是用来进行语义分析,也就是判断点云地图中哪部分是什么物体用的,这个框架的灵魂是两部分,随机取样和局部特征聚合,随机取样一改传统的取样方式在大规模点云中的效率,直接效率拉满,局部特征聚合则是为了防止随机取样将关键信息丢失所引入的一个方法,包括三个部分:局部特征编码、注意力池化和扩展残块,通过这一步将一个点的信息变为周围一些点的信息,这样就可以保留一个范围内的信息,这样在随机取样时就不至于丢失特别重要的信息。通过这两部分,构建了上面图里的框架,加上各种数据的处理,就可以通过这个框架来进行语义的分割。并且论文通过在三个数据集上的实验表明了采用这个框架确实可以提高语义分割的效率。
六、代码
最近看了一下论文对应的源代码,顺便在最后补充记录一下代码的内容。
首先代码的主要结构如下: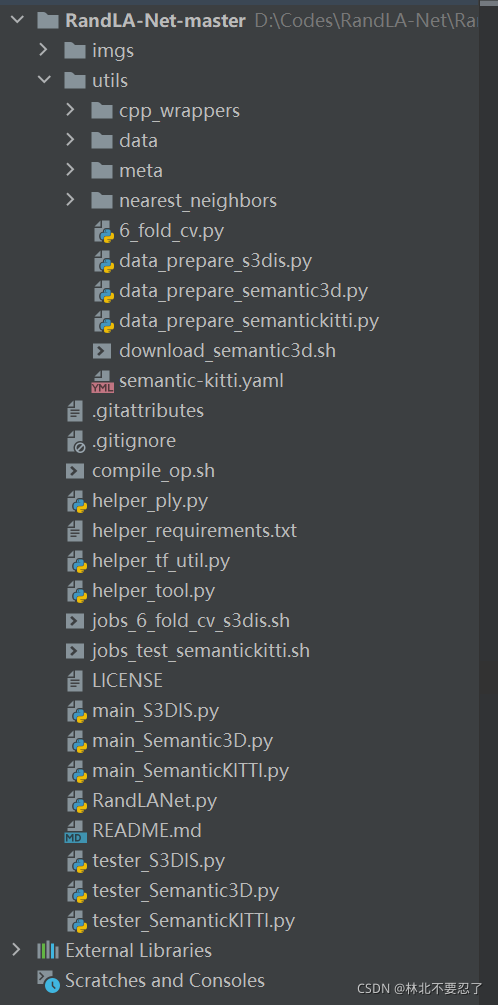
对于每个数据集都有对应的一组文件,这里就以S3DIS数据集为例,main_数据集名称.py文件是运行的主代码,对于这个数据集的完整过程都在这部分里面,这个文件里面引用了其他py文件的内容,路径中的help开头的文件就是共用的工具,RandLANet.py文件则属于算法的核心,包括网络的结构、训练的过程等内容,由于所有数据集都需要使用这部分,所以直接提取出来作为单独的一部分代码。除此之外,还有三个预处理程序和三个测试程序,分别用于数据的预处理和测试,预处理程序需要提前单独运行,而测试程序则在主程序里面调用。
根据git上面的运行过程,配置好环境之后首先运行compile_op.sh脚本文件,这一步是为了编译产生可以被其他python文件引用的so动态库文件,这一步因为产生的是so库,是不能在win上运行的,所以整个的项目如果不更改的话就只能在linux上运行。运行完compile_op.sh脚本文件之后就会在cpp_wrappers和nearest_neighbors文件夹下产生编译的动态库文件,只有这样后面的Python文件才可以正常运行。
之后运行data_prepare_s3dis.py文件,这个文件是对原始数据进行预处理,这里使用的数据是S3DIS数据集,也就是说需要将这个数据集下载下来放到对应的位置上,数据集大概20G,根据文件路径放置即可,运行预处理程序时如果没有放对位置会显示找不到文件的错误。预处理程序的主要功能就是将原本数据集的txt文件转换为ply文件和pkl文件,转换之后就可以节省后续查改txt文件的时间。这个程序在运行的时候会比较耗费时间,因为需要读取、修改大量的文件,运行完成后会在data文件夹下产生两个新文件夹,分别存放有ply文件和pkl文件:
运行完预处理文件之后,后面的程序对数据的读取都是利用ply文件的,ply文件存储数据而结合树结构存储了节点相关的信息,在后面索引点的代码中会更加节省时间。
之后运行的就是主代码main_S3DIS.py文件了,这部分涉及了很多tensorflow的知识,本人也是半懂不懂,后面的部分就说一下函数的功能,具体的细节实在是看起来有点困难:
①main_S3DIS.py
这个程序是使用Linux的控制台运行的,运行时运行jobs_6_fold_cv_s3dis.sh脚本文件,这个文件内部包含12条指令,采用这种方式相当于运行了12次main_S3DIS.py文件,每次都使用了不同的参数,这样用脚本去运行,就剩下了好多次输入的时间
python -B main_S3DIS.py --gpu 0 --mode train --test_area 1
python -B main_S3DIS.py --gpu 0 --mode test --test_area 1
python -B main_S3DIS.py --gpu 0 --mode train --test_area 2
python -B main_S3DIS.py --gpu 0 --mode test --test_area 2
python -B main_S3DIS.py --gpu 0 --mode train --test_area 3
python -B main_S3DIS.py --gpu 0 --mode test --test_area 3
python -B main_S3DIS.py --gpu 0 --mode train --test_area 4
python -B main_S3DIS.py --gpu 0 --mode test --test_area 4
python -B main_S3DIS.py --gpu 0 --mode train --test_area 5
python -B main_S3DIS.py --gpu 0 --mode test --test_area 5
python -B main_S3DIS.py --gpu 0 --mode train --test_area 6
python -B main_S3DIS.py --gpu 0 --mode test --test_area 6
其中,Python表示运行的是Python文件,-B表示采用-B方式从控制台运行py文件,不产生pyc或者pyo文件,后续跟着的参数会传入到主函数中,与主函数中的调用部分刚好对应。
main_S3DIS.py文件包括一个类和主函数。主函数中用argparse库通过程序向命令行输入内容,从而获得系统的信息,初始化一个S3DIS数据集对象后,根据输入的模式,进行不同的操作。如果模式是训练,则调用模型的训练函数,如果是测试,就调用模型的测试函数,其余情况下进行数据和结果的可视化。
这个文件的关键在于S3DIS类,这个类整合了对于S3DIS数据集的操作,首先init方法用于初始化对象的一些值,需要传入一个数据集的名称,利用这个名称去寻找数据。load_sub_sampled_clouds方法用于分开加载用于训练的数据和用于测试的数据,将这两种数据分开存放在两组数据结构中。get_batch_gen是非常重要的一个方法,这个方法其实对应的就是论文中随机取样的部分,口头上直接说是随机取样,但是随机也是需要有一定的方法,这个方法的部分就展示了具体的随机的过程,这里的随机其实并不是完全的随机,随机的部分在于为每个点都设置了一个随机的初始概率值,之后点云的概率用最后一个点的概率来表示,初始化的部分确实是随机的,但是后面就不是随机了,完成初始化之后,选择最小概率值点云中的最小概率的点作为中心点,为中心点附近添加噪声数据后,选择中心点附近一定数目的点,如果点云的数目不足则进行随机重复采样来补充数据,这些点称为查询点,打乱查询点,获得查询点的信息,对查询点的坐标进行平移之后,再次更新概率,距离中心点越近,概率增加越大,从而降低这些点再次被选中的概率。所以最终还是依据概率值去选择的点,并不完全是随机的。get_tf_mapping2方法用于整合、连接数据,包括位置信息、临近点信息等内容。init_input_pipeline方法用于初始化输入的信息流,相当于在初始化之后进行的一个信息输入的准备。
总的来说这个文件是整个项目整合全部的文件,这个程序中最重要的是S3DIS对象,这个对象是一个数据集对象,其中不仅包含有数据,而且包含着后续训练或者测试过程中会使用到的一些基本操作,将数据集对象作为参数传递给后续的方法,一方面节省了在后续方法中再次编写读写数据的时间,而且也让文件的功能更加清晰。
②tester_S3DIS.py
这个程序相对就简单一些,这个程序主要是用在主程序中如果输入的模式是测试时,这时需要调用这个程序中的modeltester对象来完成具体的操作。整个程序包括一个类和一个函数,没有主函数,所以这个程序就是专门准备着给别人用的。log_out函数用来输出检验信息。ModelTester类则负责具体的测速,类中包括一个初始化方法和一个测试方法,初始化方法就不再多提了,主要是测试方法,这个方法中最主要的任务就是利用测试集来检验模型的性能,测试主要还是靠之前主程序标记的测试集来进行,检测这部分预测的正确率并且计算IOU值来比较性能。
③RandLANet.py
这部分是算法的主要部分,前面的main_S3DIS.py文件是程序运行的主要负责人,而RandLANet.py就是技术骨干。这部分最主要的就是Network类,这个类包括了整个网络的结构和运行过程。
首先是init方法,这个方法负责初始化网络的一些参数和tensorflow中的不同层的参数,从这里开始就出现了很多tensorflow的操作,在这个方法中提前初始化了很多的层的参数。之后是inference方法,这个方法是构造网络结构的关键函数,其中包括编码和解码,是组建整个网络结构的最关键的部分,其中编码部分使用的一些操作写在了nearest_interpolation方法里面。在inference方法中,调用了dilated_res_block和random_sample方法,这两个方法对应的就是论文中的扩张残差块和随机取样的部分,在具体的代码实现上,扩张残差块部分又拆出来一个building_block方法,这个方法实际上就是扩展残差块里面两组的局部信息编码和注意力池化,局部信息编码的部分单独写在了relative_pos_encoding方法里面,获得周围N个点的信息则写在了gather_neighbour方法里面,注意力池化的部分则写在了att_pooling方法里面。
除此之外,在具体使用模型对象的时候,主要是用到train方法,这个方法是训练用的函数,主要根据数据进行训练。在训练的过程中,用evaluate方法计算正确率,从而保证每次的训练都向着正确率提高的方向进行。get_loss方法用在loss层里面,如果要忽略一定类型的标签,就需要在计算之前对loss进行处理,这时就要用到这个方法。
总的来说,这个文件就是论文里面算法的代码实现,是所有数据集都需要使用到的算法,所以单独拿了出来作为一个文件,如果想要结合代码去理解论文的算法,完全可以对照着这个程序去进行。
④helper_ply.py
读取、编写PLY文件的工具,提前编写这个py文件,再在别的py文件引用一下,从而节省了再次编写的时间。
⑤helper_tf_util.py
打包一些tensorflow常用的功能。通过直接引用提前编写好的代码 在tensorflow原生代码的基础上增加一些新功能 从而让tensorflow的调取和使用都更加方便。 相当于原生canvas和改进canvas的关系 本质上还是tensorflow 但是将原本代码进行了更进一步的编写 从而可以直接调用编写的新代码,从而进一步简化了使用tensorflow的步骤和门槛。
⑥helper_tool.py
这个py文件主要是项目使用过程中共用的一些工具函数,文件里面是五个类,其中三个类是对应三个数据集的参数,比如说KNN的K值、卷积网络的层数等等。DataProcessing类是读取数据或者运行网络过程中的一些操作,包括读取数据的方法load_pc_semantic3d和load_pc_kitti,读取标签的方法load_label_semantic3d和load_label_kitti,获取文件列表的方法get_file_list,调用so库的knn算法的方法knn_search,点数不足时用来重复取样扩大数据的方法data_aug,打乱数据用的方法shuffle_idx和shuffle_list,在校验的过程中计算IOU值的方法IoU_from_confusions,预处理每个类别的点的数目返回每个类别的权重的方法get_class_weights。最后一个类plot也是一些共用方法,主要是对单独的点的一些操作,包括random_colors随机获得颜色,draw_pc和draw_pc_sem_ins方法用来可视化。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)