【NLP】LSTM实现THUCNews中文新闻分类(Pytorch)下
基于Pytorch框架实现LSTM进行中文新闻文本分类。
0.前言
上周杂事特别多,周三周四周五都在跑材料,一个LSTM写到周末才勉勉强强结束了。
代码跑起来的时候才意识到是用CPU跑的......后续改进一下。另外,更新一下项目进度,最近看了一些论文,创新点想法有点头绪了,但是实验又让我头很痛,感觉还有很多很多要学的。
2.LSTM实现中文新闻分类
2.5搭建LSTM网络
对于数据的相关处理都已经在上一篇博客完成了,接下来搭建一个LSTM网络分类器,用于对文本数据分类。
构造时,我们同样是继承nn.module类,传入的参数包括:
vocab_size:词典长度
embeddding_dim:词向量的维度(文字➡数字向量的维度)
hidden_dim:LSTM神经元个数
layer_dim:LSTM的层数
output_dim:隐藏层输出维度(分类的数量)
进行梯度下降,参数更新的过程中,输入的文本数据,首先经过self.embedding()操作,将文本数据,转换成向量,再输入进LSTM层,(从这里开始,h_c,h_n,我就不太理解了,然后r_out[:,-1:],我也不理解)返回输出,隐藏状态和单元状态,最后将输出的最后的最后一个值传如全连接层进行预测?
##搭建LSTM网络
class LSTMNet(nn.Module):
def __init__(self,vocab_size,embedding_dim,hidden_dim,layer_dim,output_dim):
super(LSTMNet,self).__init__() #继承父类的初始化方法
self.hidden_dim = hidden_dim #LSTM神经元个数
self.layer_dim = layer_dim #LSTM的层数
##对文本进行词向量处理
self.embedding = nn.Embedding(vocab_size,embedding_dim)
##LSTM+全连接层
self.lstm = nn.LSTM(embedding_dim,hidden_dim,layer_dim,batch_first=True)
#batch_first=True,batch在输入输出时都在第一维。
#数据加载器返回数据时候一般第一维都是batch,但是!pytorch的LSTM层默认输入和输出都是batch在第二维。
self.fc1 = nn.Linear(hidden_dim,output_dim)
def forward(self,x):
embeds = self.embedding(x)
r_out,(h_n,h_c) = self.lstm(embeds,None) #None:隐藏层的初始值使用零,#h_n是隐状态,h_c是单元状态
out = self.fc1(r_out[:,-1,:])
return out2.6实例化LSTM网络
这一步没啥,就是设定好我们网络需要传入的参数的值都是多少。
vocab_size = len(TEXT.vocab)
embedding_dim = 100
hidden_dim = 128
layer_dim = 1
output_dim = 10
lstmmodel = LSTMNet(vocab_size,embedding_dim,hidden_dim,layer_dim,output_dim)
print(lstmmodel)2.7LSTM网络的训练
网络定义好之后,还需要定义一个对网络进行训练的函数train_model2(),包括两部分,对训练集数据的训练+对验证集数据的训练。函数所需参数:网络模型、训练数据、验证数据、损失函数、优化器以及需要迭代的epoch数量。
(所有的我可以理解的步骤,我都将注释写在代码中)
##定义网络训练过程函数
def train_model2(model,traindataloder,valdataloader,criterion,optimizer,num_epochs=20):
##设置四个空列表用于储存损失和精度
train_loss_all = []
train_acc_all = []
val_loss_all = []
val_acc_all = []
#since = time.time()
for epoch in range(num_epochs):
print("-"*10)
print("Epoch{}/{}".format(epoch,num_epochs-1))
##每个epoch有两个阶段:训练阶段和验证阶段
train_loss = 0.0
train_corrects = 0
train_num = 0
val_loss = 0.0
val_corrects = 0
val_num = 0
##1.将模型设置为训练模式,训练后得到训练集的损失和精度
model.train()
for step,batch in enumerate(traindataloder):
textdata,target = batch.cutword[0],batch.labelcode.view(-1) #我暂时理解为每批次的cutword[0]就是该批次的文本内容,view(-1)把标签都拉成一维的了
out = model(textdata) #将文本输入到网络模型中
pre_lab = torch.argmax(out,dim=1) ##预测标签。找出这个一维向量(按行)里面最大值的索引。可以理解为,输出是一个1×10的向量,每个数值都是0-9的概率,找到概率最大的就是其预测的值
loss = criterion(out,target) ##利用输出(预测的概率最大的)和目标值(已知的标签)计算损失函数值
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()*len(target)
train_corrects += torch.sum(pre_lab == target.data)
train_num += len(target)
##计算一个epoch在训练集上的损失和精度
train_loss_all.append(train_loss/train_num)
train_acc_all.append(train_corrects.double().item()/train_num)
print("{} Train Loss:{:.4f} Train Acc:{:.4f}".format(epoch,train_loss_all[-1],train_acc_all[-1]))
##2.将模型设置为验证模式,训练后得到验证集的损失和精度
model.eval()
for step, batch in enumerate(valdataloader):
textdata, target = batch.cutword[0], batch.labelcode.view(-1)
out = model(textdata)
pre_lab = torch.argmax(out, 1) ##预测标签
loss = criterion(out, target) ##计算损失函数值
val_loss += loss.item() * len(target)
val_corrects += torch.sum(pre_lab == target.data)
val_num += len(target)
##计算一个epoch在训练集上的损失和精度
val_loss_all.append(val_loss / val_num)
val_acc_all.append(val_corrects.double().item() / val_num)
print("{} Val Loss:{:.4f} Val Acc:{:.4f}".format(epoch, val_loss_all[-1], val_acc_all[-1]))
##用一个DataFrame将每个epoch训练和验证的损失和精度打包在一起
train_process = pd.DataFrame(
data ={"epoch":range(num_epochs),
"train_loss_all": train_loss_all,
"train_acc_all": train_acc_all,
"val_loss_all": val_loss_all,
"val_acc_all": val_acc_all})
return model,train_process2.8训练模型
我们之前对数据做了预处理、定义了LSTM网络,又定义了LSTM网络该如何进行训练,现在,设定好优化器和损失函数用什么,把定义好的参数传入我们之前定义的训练模型函数里就可以开始训练了。
##训练模型
##定义优化器
optimizer = torch.optim.Adam(lstmmodel.parameters(),lr=0.003) #学习率为0.003
loss_func = nn.CrossEntropyLoss() #使用交叉熵损失更新参数
##对模型进行迭代训练,对所有数据训练20轮
lstmmodel,train_process = train_model2(lstmmodel,train_iter,val_iter,loss_func,optimizer,num_epochs=20)我们可以新建两个画布来可视化模型的训练过程。
##可视化模型训练过程
plt.figure(figsize=(18,6))
plt.subplot(1,2,1)
plt.plot(train_process.epoch,train_process.train_loss_all,"r.-",label = "Train loss")
plt.plot(train_process.epoch,train_process.val_loss_all,"bs-",label = "Val loss")
plt.legend()
plt.xlabel("Epoch number",size = 13)
plt.ylabel("Loss value",size = 13)
plt.subplot(1,2,2)
plt.plot(train_process.epoch,train_process.train_acc_all,"r.-",label = "Train acc")
plt.plot(train_process.epoch,train_process.val_acc_all,"bs-",label = "Val acc")
plt.xlabel("Epoch number",size = 13)
plt.ylabel("Acc",size = 13)
plt.legend()
plt.show()2.9模型训练结果
就是说,CPU跑20个epoch太恼火了,但是我们也可以看到基本上在第2,3个epoch的时候,精度和损失就下降了,至于为什么两排都是Train......自然是写代码的时候,智商不在线了,复制到val的时候忘了改了。(但是,放心我po上来的代码都是改好了的)
可视化也自行尝试吧!

2.10LSTM网络预测
这一步要基于上一步网络训练好了才可以进行预测。使用测试集来评价网络的分类精度,将训练好的网络作用于测试集。
lstmmodel.eval()
test_y_all = torch.LongTensor()
pre_lab_all = torch.LongTensor()
for step,batch in enumerate(test_iter):
textdata,target = batch.cutword[0],batch.labelcode.view(-1)
out = lstmmodel(textdata)
pre_lab = torch.argmax(out,1)
test_y_all = torch.cat((test_y_all,target))#cat是拼接tensor,至于为什么要拼接,不太懂
pre_lab_all = torch.cat((pre_lab_all,pre_lab))
acc = accuracy_score(test_y_all,pre_lab_all)
print("在测试集上的预测精度为:",acc)因为之前20次实在是太多了,我就只迭代了5次,下图为迭代5次,学习率为0.03的模型预测精度结果。

2.11计算混淆矩阵并可视化
这里利用混淆矩阵来查看目标值为xx,预测结果也为xx的情况。
class_label = ["体育","娱乐","家居","房产","教育","时尚","时政","游戏","科技","财经"]
conf_mat = confusion_matrix(test_y_all,pre_lab_all)
df_cm = pd.DataFrame(conf_mat,index=class_label,columns=class_label)
heatmap = sns.heatmap(df_cm,annot=True,fmt="d",cmap="YlGnBu")
heatmap.yaxis.set_ticklabels(heatmap.yaxis.get_ticklabels(),rotation=0,ha="right",fontproperties=fonts)
heatmap.xaxis.set_ticklabels(heatmap.xaxis.get_ticklabels(),rotation=45,ha="right",fontproperties=fonts)
plt.ylabel("True label")
plt.xlabel("Predicted label")
plt.show()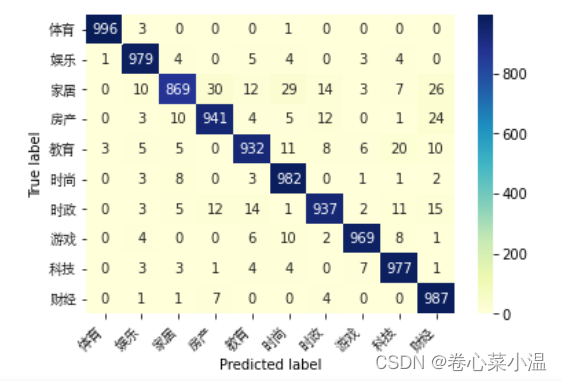
3.总结
整个实战流程:
下载数据集➡读取数据集➡数据清洗➡数据在处理并建立单词表➡定义数据加载器➡搭建LSTM网络并实例化➡定义训练过程函数并实例化➡训练网络➡利用训练好的网络进行预测。
ok!LSTM中文新闻分类到此就差不多结束了,这一周也结尾了,下午放假!这一周学习+跑材料+PPT展示,有够累的。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)