GAN的原理
文章目录一、GAN基本介绍二、数学分析1. 生成器G2. 判别器D(1) 求D-max(2) 求G-min三、训练过程一、GAN基本介绍GAN是一个生成网络,他有两个网络G和DGenerator:生成图片的网络,他可以接受一个随机噪声,这里我们一般把噪声设为标准高斯分布(当然也可以是其他的噪声分布),z~N(0, 1)z~N(0, ~~1)z~N(0,
文章目录
一、GAN基本介绍
GAN是一个生成网络,他有两个网络G和D
- Generator:生成图片的网络,他可以接受一个随机噪声,这里我们一般把噪声设为标准高斯分布(当然也可以是其他的噪声分布), z ~ N ( 0 , 1 ) z~N(0, ~~1) z~N(0, 1),让 z z z通过生成网络得到 G ( z ) G(z) G(z), G ( z ) G(z) G(z)其实就是一幅图片
- Discriminator:判别网络,我们将生成器生成的图片通过判别网络进行判断,最终会得到一个标量,即 D ( G ( z ) ) D(G(z)) D(G(z)),数值越高代表图片越真实,数值低代表图片越假
GAN的主要目的就是通过将真实的图片(即数据集中的图片GT)以及通过生成器 G G G生成的图片输入到判别网络 D D D中,让判别网络无法判断出这幅图片究竟是真实的图片还是通过噪声生成的图片,当训练完成时, D ( G ( z ) ) = 0.5 D(G(z))=0.5 D(G(z))=0.5
二、数学分析
1. 生成器G
我们有一批数据,假设是一些图片,他们的数据分布是 P d a t a ( x ) P_{data}(x) Pdata(x),当然我们没有办法知道 P d a t a ( x ) P_{data}(x) Pdata(x)的具体数值,不然我们就可以直接从里面采样得到图片了,所以我们需要求解此分布,这就需要用到生成器 G G G了
首先我们从标准高斯噪声中进行采样得到 z z z,然后我们让 z z z通过生成器 G G G就可以得到一个分布记为 P G ( x ; θ ) P_{G}(x;\theta) PG(x;θ),其中 θ \theta θ是一个参数用来控制 P G P_{G} PG的分布,假设我们从真实的数据分布 P d a t a ( x ) P_{data}(x) Pdata(x)中得到一批分布 { x 1 , x 2 . . . x m } \{x_{1},x_{2}...x_{m}\} {x1,x2...xm},此时我们求一个 θ ∗ \theta^{*} θ∗来使 P G ( x ) P_{G}(x) PG(x)的取值最大,即求最大似然
θ ∗ = arg max θ Π i = 1 m P G ( x i , θ ) → arg max θ l o g Π i = 1 m P G ( x i , θ ) = arg max θ ∑ i = 1 m l o g P G ( x i , θ ) ≈ arg max θ E x ~ d a t a [ l o g P G ( x ; θ ) ] \begin{aligned} \theta^{*} & = \underset {\theta}{\operatorname {arg\,max}} \Pi_{i=1}^{m}P_{G}(x^{i}, \theta) \\ & \rightarrow \underset {\theta}{\operatorname {arg\,max}}~log \Pi_{i=1}^{m}P_{G}(x^{i}, \theta) \\ & = \underset {\theta}{\operatorname {arg\,max}}~\sum_{i=1}^{m}logP_{G}(x^{i}, \theta) \\ & \approx \underset {\theta}{\operatorname {arg\,max}}~E_{x~data}[logP_{G}(x;\theta)] \end{aligned} θ∗=θargmaxΠi=1mPG(xi,θ)→θargmax logΠi=1mPG(xi,θ)=θargmax i=1∑mlogPG(xi,θ)≈θargmax Ex~data[logPG(x;θ)]
其中 x ~ d a t a x~data x~data代表了从 P d a t a ( x ) P_{data}(x) Pdata(x)取得的数据 { x 1 , x 2 . . . x m } \{x_{1},x_{2}...x_{m}\} {x1,x2...xm},接下来
θ ∗ = arg max θ ∫ x P d a t a ( x ) l o g P G ( x ; θ ) d x − ∫ x P d a t a ( x ) l o g P d a t a ( x ) d x = arg min θ ∫ x P d a t a ( x ) l o g P d a t a ( x ) d x − ∫ x P d a t a ( x ) l o g P G ( x ; θ ) d x = arg min θ ∫ x P d a t a ( x ) l o g P d a t a ( x ) P G ( x ; θ ) d x = arg min θ K L ( P d a t a ( x ) ∣ ∣ P G ( x ; θ ) ) \begin{aligned} \theta^{*} & = \underset {\theta}{\operatorname {arg\,max}} \int_{x}P_{data}(x)logP_{G}(x;\theta)dx- \int_{x}P_{data}(x)logP_{data}(x)dx \\ & =\underset {\theta}{\operatorname {arg\,min}} \int_{x}P_{data}(x)logP_{data}(x)dx- \int_{x}P_{data}(x)logP_{G}(x;\theta)dx \\ & =\underset {\theta}{\operatorname {arg\,min}} \int_{x}P_{data}(x)log\frac{P_{data}(x)}{P_{G}(x;\theta)}dx \\ & = \underset {\theta}{\operatorname {arg\,min}}~KL(P_{data}(x) || {P_{G}(x;\theta)}) \end{aligned} θ∗=θargmax∫xPdata(x)logPG(x;θ)dx−∫xPdata(x)logPdata(x)dx=θargmin∫xPdata(x)logPdata(x)dx−∫xPdata(x)logPG(x;θ)dx=θargmin∫xPdata(x)logPG(x;θ)Pdata(x)dx=θargmin KL(Pdata(x)∣∣PG(x;θ))
注意上式中减掉的 ∫ x P d a t a ( x ) l o g P d a t a ( x ) d x \int_{x}P_{data}(x)logP_{data}(x)dx ∫xPdata(x)logPdata(x)dx由于这是一个常数,所以并不影响最终的结果,通过上述我们可以得知,最大化似然其实就是给生成器 G G G找一个 θ g \theta_{g} θg使得 P G ( x ; θ ) = P d a t a ( x ) P_{G}(x;\theta) = P_{data}(x) PG(x;θ)=Pdata(x)
到这里有的人就会想,既然我们要求这两个概率接近,那我们直接在这里进行反向传播来训练 G G G不就可以了吗,当然不可以,因为我们对噪声 z z z进行随机采样时,我们并不知道哪个噪声对应哪张图片,也就是说我们并不知道 G T GT GT,因此从 P d a t a ( x ) P_{data}(x) Pdata(x)中随机取样本与 P G ( x , θ ) P_{G}(x,\theta) PG(x,θ)求距离时没有意义的,接下来我们看一看GAN是怎么做的
2. 判别器D
我们直接给出paper中的公式
min G max D V ( D , G ) = E x ~ p d a t a ( x ) [ l o g D ( x ) ] + E z ~ p z ( z ) [ l o g ( 1 − D ( G ( z ) ) ) ] \underset {G}{\operatorname {min}}~\underset {D}{\operatorname {max}} V(D,G) = E_{x~p_{data}(x)}[logD(x)] + E_{z~p_{z}(z)}[log(1-D(G(z)))] Gmin DmaxV(D,G)=Ex~pdata(x)[logD(x)]+Ez~pz(z)[log(1−D(G(z)))]
此时我们固定 G G G,即
max D V ( D , G ) = E x ~ p d a t a ( x ) [ l o g D ( x ) ] + E x ~ p G ( x ) [ l o g ( 1 − D ( x ) ) ] \underset {D}{\operatorname {max}} V(D,G) = E_{x~p_{data}(x)}[logD(x)] + E_{x~p_{G}(x)}[log(1-D(x))] DmaxV(D,G)=Ex~pdata(x)[logD(x)]+Ex~pG(x)[log(1−D(x))]
上式子就代表了 P G P_{G} PG与 P d a t a P_{data} Pdata之间的差异,因为第一项代表了真实的数据,显然对于真实的数据判别器 D D D要给一个很高的分数;后一项代表了噪声生成的数据,对于假的数据我们就要给一个很低的分值,所以第二项的分值要变小,但是由于 l o g log log里面是负号,所以取反就要变大。因此如果来的是真实的数据第一项变大,来的是虚假的数据第二项变大
注意:在训练过程中是先训练 1 ~ k 1~k 1~k判别器,在训练一次生成器的。在训练 D D D时,判别器是知道输入的数据是真实的(1)还是虚假的(0),因此在训练过程中 D D D会变得越来越强。即来的是真实的数据,输出会增大变为1,对于噪声数据,输出会变小变为0
(1) 求D-max
下面我们对其进行求导算出最优的 D D D
V ( D ) = E x ~ p d a t a ( x ) [ l o g D ( x ) ] + E x ~ p G ( x ) [ l o g ( 1 − D ( x ) ) ] = ∫ x P d a t a ( x ) l o g D ( x ) d x + ∫ x P G ( x ) l o g ( 1 − D ( x ) ) d x = ∫ x [ P d a t a ( x ) l o g D ( x ) + P G ( x ) l o g ( 1 − D ( x ) ) ] d x 取 f ( D ) = P d a t a ( x ) l o g D ( x ) + P G ( x ) l o g ( 1 − D ( x ) ) = a × l o g D + b × l o g ( 1 − D ) \begin{aligned} V(D) &= E_{x~p_{data}(x)}[logD(x)] + E_{x~p_{G}(x)}[log(1-D(x))] \\ & = \int_{x}P_{data}(x)logD(x)dx+ \int_{x}P_{G}(x)log(1-D(x))dx \\ & = \int_{x}[P_{data}(x)logD(x) + P_{G}(x)log(1-D(x))]dx \\ 取f(D) & = P_{data}(x)logD(x) + P_{G}(x)log(1-D(x)) \\ & = a\times logD + b\times log(1-D) \end{aligned} V(D)取f(D)=Ex~pdata(x)[logD(x)]+Ex~pG(x)[log(1−D(x))]=∫xPdata(x)logD(x)dx+∫xPG(x)log(1−D(x))dx=∫x[Pdata(x)logD(x)+PG(x)log(1−D(x))]dx=Pdata(x)logD(x)+PG(x)log(1−D(x))=a×logD+b×log(1−D)
对 f ( D ) f(D) f(D)求导
d f ( D ) d D = a × 1 D + b × 1 1 − D × ( − 1 ) = 0 a × ( 1 − D ) = b × D s o l : D = a a + b D ∗ ( x ) = P d a t a ( x ) P d a t a ( x ) + P G ( x ) \begin{aligned} & \frac{df(D)}{dD} = a\times \frac{1}{D} + b\times \frac{1}{1-D}\times (-1) = 0 \\ & a\times (1-D) = b \times D \\ & sol:~~ D = \frac{a}{a+b} \\ & D^{*}(x) = \frac{P_{data}(x)}{P_{data}(x) + P_{G}(x)} \end{aligned} dDdf(D)=a×D1+b×1−D1×(−1)=0a×(1−D)=b×Dsol: D=a+baD∗(x)=Pdata(x)+PG(x)Pdata(x)
在我们计算出 D ∗ ( x ) D^{*}(x) D∗(x)后,带入最初式 max D V ( D , G ) = E x ~ p d a t a ( x ) [ l o g D ( x ) ] + E x ~ p G ( x ) [ l o g ( 1 − D ( x ) ) ] \underset {D}{\operatorname {max}} V(D,G) = E_{x~p_{data}(x)}[logD(x)] + E_{x~p_{G}(x)}[log(1-D(x))] DmaxV(D,G)=Ex~pdata(x)[logD(x)]+Ex~pG(x)[log(1−D(x))]中得
V ( D ∗ ) = E x ~ p d a t a ( x ) [ l o g D ( x ) ] + E x ~ p G ( x ) [ l o g ( 1 − D ( x ) ) ] = ∫ x P d a t a ( x ) l o g P d a t a ( x ) P d a t a ( x ) + P G ( x ) d x + ∫ x P G ( x ) l o g ( 1 − P d a t a ( x ) P d a t a ( x ) + P G ( x ) ) d x = − 2 l o g 2 + ∫ x P d a t a ( x ) l o g P d a t a ( x ) ( P d a t a ( x ) + P G ( x ) ) 2 d x + ∫ x P G ( x ) l o g ( P G ( x ) ( P d a t a ( x ) + P G ( x ) ) 2 ) d x = − 2 l o g 2 + K L ( P d a t a ( x ) ∣ ∣ P d a t a ( x ) + P G ( x ) ) 2 ) + K L ( P G ( x ) ∣ ∣ P d a t a ( x ) + P G ( x ) ) 2 ) = − 2 l o g 2 + 2 J S D ( P d a t a ( x ) ∣ ∣ P G ( x ) ) \begin{aligned} V(D^{*}) & = E_{x~p_{data}(x)}[logD(x)] + E_{x~p_{G}(x)}[log(1-D(x))] \\ & = \int_{x}P_{data}(x)log\frac{P_{data}(x)}{P_{data}(x) + P_{G}(x)}dx+ \int_{x}P_{G}(x)log(1-\frac{P_{data}(x)}{P_{data}(x) + P_{G}(x)})dx \\ & = -2log2 + \int_{x}P_{data}(x)log\frac{P_{data}(x)}{\frac{(P_{data}(x) + P_{G}(x))}{2}}dx+ \int_{x}P_{G}(x)log(\frac{P_{G}(x)}{\frac{(P_{data}(x) + P_{G}(x))}{2}})dx \\ & = -2log2 + KL(P_{data}(x) || \frac{P_{data}(x) + P_{G}(x))}{2}) + KL(P_{G}(x) || \frac{P_{data}(x) + P_{G}(x))}{2}) \\ & = -2log2 + 2JSD(P_{data}(x) || P_{G}(x)) \\ \end{aligned} V(D∗)=Ex~pdata(x)[logD(x)]+Ex~pG(x)[log(1−D(x))]=∫xPdata(x)logPdata(x)+PG(x)Pdata(x)dx+∫xPG(x)log(1−Pdata(x)+PG(x)Pdata(x))dx=−2log2+∫xPdata(x)log2(Pdata(x)+PG(x))Pdata(x)dx+∫xPG(x)log(2(Pdata(x)+PG(x))PG(x))dx=−2log2+KL(Pdata(x)∣∣2Pdata(x)+PG(x)))+KL(PG(x)∣∣2Pdata(x)+PG(x)))=−2log2+2JSD(Pdata(x)∣∣PG(x))
对于一个 l n ln ln底数的Jensen–Shannon divergence取值范围为 [ 0 , l n 2 ] [0, ~ln2] [0, ln2]
(2) 求G-min
通过上式我们可以发现固定 G G G, V ( D ) V(D) V(D)的最小值为 − 2 l o g 2 -2log2 −2log2,最大值为0
我们已经得到了 max D V ( D , G ) = V ( D ∗ ) \underset {D}{\operatorname {max}} V(D,G) = V(D^{*}) DmaxV(D,G)=V(D∗),接下来求解 min G V ( D ∗ ) \underset {G}{\operatorname {min}}V(D^{*}) GminV(D∗),即
min G { − 2 l o g 2 + 2 J S D ( P d a t a ( x ) ∣ ∣ P G ( x ) ) } \underset {G}{\operatorname {min}}\{-2log2 + 2JSD(P_{data}(x) || P_{G}(x))\} Gmin{−2log2+2JSD(Pdata(x)∣∣PG(x))}
直观的可以看出当 P G ( x ) = P d a t a ( x ) P_{G}(x) = P_{data}(x) PG(x)=Pdata(x)时,能取得最小值
上面可以看出,训练 D D D的目的是让判别器能够识别那些图片是从真实样本分布中获得的,那些是通过噪声生成的,通过训练来让判别器变得更强,所以用的是 m a x D max_{D} maxD,但是训练 G G G恰恰相反,训练 G G G的目的是让生成器能够生成更加真实的图片,来“误导”判别器使其判断错误,所以用的是 m i n G min_{G} minG
通俗来讲,训练 D D D的目的是使得 D ( x ) D(x) D(x)的分布接近 D ∗ ( x ) = P d a t a ( x ) P d a t a ( x ) + P G ( x ) D^{*}(x) = \frac{P_{data}(x)}{P_{data}(x) + P_{G}(x)} D∗(x)=Pdata(x)+PG(x)Pdata(x),而训练训练 G G G的目的是使得 P G ( x ) = P d a t a ( x ) P_{G}(x) = P_{data}(x) PG(x)=Pdata(x),而我们最终的目的就是得到 P G ( x ) = P d a t a ( x ) P_{G}(x) = P_{data}(x) PG(x)=Pdata(x),所以如果想要得到一个较好的概率结果,每次训练时都应该先多训练几次 D D D(k次), G G G一般一个batch就训练一次(理解为 D D D是一个老师, G G G是一个学生,如果老师没有足够的水平(没训练好),怎么去指导学生呢),这样当最后 G G G训练好的时候, D ( x ) = 1 2 D(x)=\frac{1}{2} D(x)=21
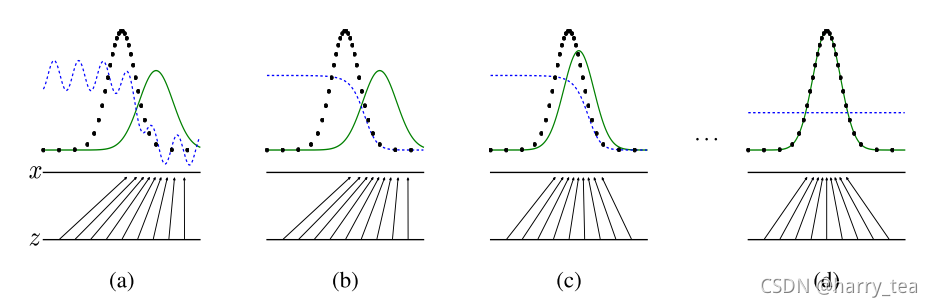
下面给出paper中的一个图,其中绿色的线代表 P G ( x ) P_{G}(x) PG(x)分布的变化,黑色的点线代表真实的概率分布 P d a t a ( x ) P_{data}(x) Pdata(x),蓝色的线代表判别器 D D D的最优解变化过程,可以发现最后变为了 1 2 \frac{1}{2} 21
三、训练过程
训练过程是交替进行的,即先训练 D D D,在训练 G G G
算法流程:
- 先用 k k k步来训练 D → θ d D\rightarrow \theta_{d} D→θd
- 在训练 G → θ g G\rightarrow \theta_{g} G→θg

注意上述步骤中 V ( D , G ) = E x ~ p d a t a ( x ) [ l o g D ( x ) ] + E z ~ p z ( z ) [ l o g ( 1 − D ( G ( z ) ) ) ] V(D,G) = E_{x~p_{data}(x)}[logD(x)] + E_{z~p_{z}(z)}[log(1-D(G(z)))] V(D,G)=Ex~pdata(x)[logD(x)]+Ez~pz(z)[log(1−D(G(z)))] 在求第二步的时候,其实只有第二项包含了 G G G,第二步把第一项给剔除了
下面贴上一段代码来感受以下训练过程,里面取了 k = 1 k=1 k=1
"""
Train D
将噪声通过G在通过D得到值与0用BCELoss求损失-->f_loss
将真实的图片通过D得到的值与1用BCELoss求损失-->r_loss
将两个损失进行反向传播
"""
z = torch.randn(bs, z_dim).cuda() # torch.Size(bs=64, z_dim=100)
r_imgs = imgs.cuda() # torch.Size([64, 3, 64, 64])
f_imgs = G(z) # torch.Size([64, 3, 64, 64])
# label
r_label = torch.ones((bs)).cuda() # torch.Size([64])
f_label = torch.zeros((bs)).cuda() # torch.Size([64])
# dis
r_logit = D(r_imgs.detach()) # torch.Size([64])
f_logit = D(f_imgs.detach()) # torch.Size([64])
# compute loss
r_loss = criterion(r_logit, r_label)
f_loss = criterion(f_logit, f_label)
loss_D = (r_loss + f_loss) / 2
# update model
D.zero_grad()
loss_D.backward()
opt_D.step()
"""
train G
将噪声通过G在通过D得到的值与1求BCELoss-->loss
将loss进行反向传播
"""
# leaf
z = torch.randn(bs, z_dim).cuda() # torch.Size(64, 100)
f_imgs = G(z) # torch.Size([64, 3, 64, 64])
# dis
f_logit = D(f_imgs) # torch.Size([64])
# compute loss
loss_G = criterion(f_logit, r_label)
# update model
G.zero_grad()
loss_G.backward()
opt_G.step()
四、训练图形化
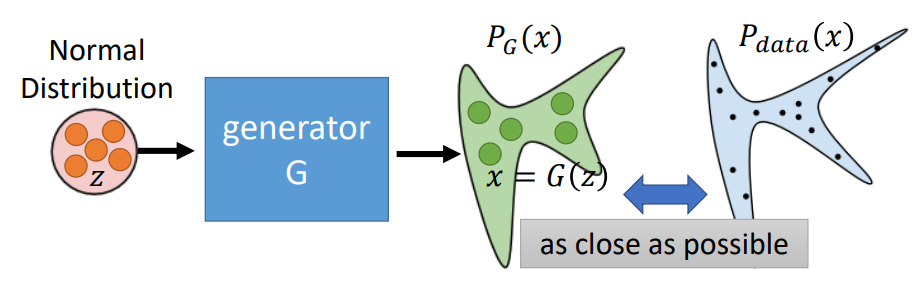
1. 整体模型图
首先给出一个GAN的整体模型图

2. D&&G交替训练
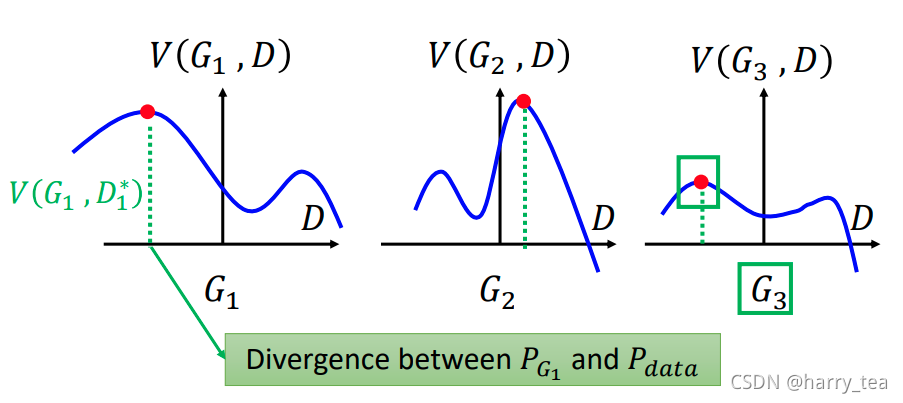
如下图所示,我们要求的是找一个 D D D使得结果最大,找一个 G G G使得结果最小
这三个图没有训练顺序,所以仅作为一个参考,也就是说我们找到一个使得 V V V最大的 D 1 ∗ D_{1}^{*} D1∗之后,在最大处通过改变 G G G使得峰顶降低
图中绿色的虚线就是 P G P_{G} PG和 P d a t a P_{data} Pdata之间的距离,训练 G G G的目的就是使得二者距离相等,就时将顶部红色的点压到横坐标上
五、存在的问题
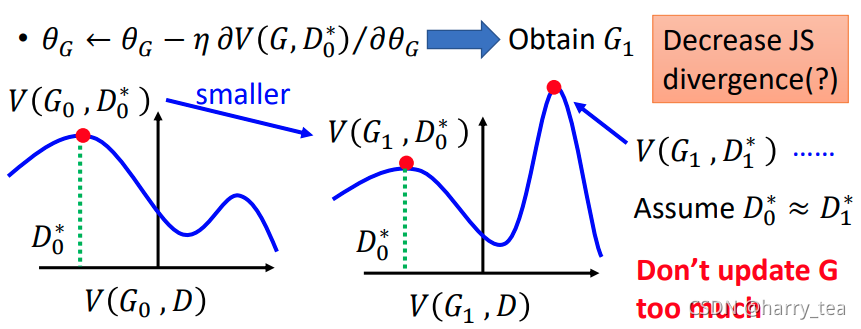
1. 为什么要训练k次D,在训练一次G
如图所示,我们训练一次 D D D,同时更新一次 G G G会出现的问题
假设我们训练了一次找到了一个 D D D使得 V V V较大,但是不一定非常大(注意这里陈述的和图中不太一致),然后我们更新 G G G,会将此时 V V V所在的点压低,这时我们如果在更新 D D D,曲线会找到一个其他的 D ∗ D^{*} D∗和使得 V V V更大,这时的 G G G不仅没有使得 P G P_{G} PG更接近 P d a t a P_{data} Pdata,反而更远了,因此我们应该更新 k k k次 D D D以保证 D D D已经达到了一个比较优的值
用公式表示:
m a x D V ( G 0 , D 0 ) = V ( G 0 , D 0 ∗ ) a f t e r u p d a t e G : V ( G 1 , D 0 ∗ ) < V ( G 0 , D 0 ∗ ) a f t e r u p d a t e D : V ( G 1 , D 1 ∗ ) > V ( G 0 , D 0 ∗ ) \begin{aligned} max_{D}V(G_{0}, D_{0}) &= V(G_{0}, D_{0}^{*}) \\ after~~update~~G:V(G_{1}, D_{0}^{*}) &< V(G_{0}, D_{0}^{*}) \\ after~~update~~D:V(G_{1}, D_{1}^{*}) &> V(G_{0}, D_{0}^{*}) \end{aligned} maxDV(G0,D0)after update G:V(G1,D0∗)after update D:V(G1,D1∗)=V(G0,D0∗)<V(G0,D0∗)>V(G0,D0∗)
2. 优化问题
G G G的损失函数为:
max D V ( D , G ) = E x ~ p d a t a ( x ) [ l o g D ( x ) ] + E x ~ p G ( x ) [ l o g ( 1 − D ( x ) ) ] \underset {D}{\operatorname {max}} V(D,G) = E_{x~p_{data}(x)}[logD(x)] + E_{x~p_{G}(x)}[log(1-D(x))] DmaxV(D,G)=Ex~pdata(x)[logD(x)]+Ex~pG(x)[log(1−D(x))]
因为第一部分没有 G G G的信息,因此损失函数可以化简为
max D V ( D , G ) = E x ~ p G ( x ) [ l o g ( 1 − D ( x ) ) ] \underset {D}{\operatorname {max}} V(D,G) = E_{x~p_{G}(x)}[log(1-D(x))] DmaxV(D,G)=Ex~pG(x)[log(1−D(x))]
从图中可以看出 l o g ( 1 − D ( x ) ) log(1-D(x)) log(1−D(x))在最初的时候值为0(即最大值),我们要降低这个值,但是他在最初的时候梯度很小,下降的很慢但是如果改成 − l o g ( D ( x ) ) -log(D(x)) −log(D(x)),梯度很大下降的就快,所以这里做一个微小的变化,改变损失值之后,第二步的损失就完全等价于nn.BCELoss(),如下
criterion = nn.BCELoss()
'''other codes'''
loss_G = criterion(f_logit, r_label) # 括号中的取值为[0, 1]
其中r_label是1,所以二分类损失
L = 1 N ∑ i L i = 1 N ∑ i − [ y i l o g ( p i ) + ( 1 − y i ) l o g ( 1 − p i ) ] L = \frac{1}{N}\sum_{i}L_{i} = \frac{1}{N}\sum_{i}-[y_{i}log(p_{i})+(1-y_{i})log(1-p_{i})] L=N1i∑Li=N1i∑−[yilog(pi)+(1−yi)log(1−pi)]
其中 y i y_{i} yi是1,后面那部分就没了,就变成了 L = − y i l o g ( p i ) L = -y_{i}log(p_{i}) L=−yilog(pi),其中 y i = 1 y_{i} = 1 yi=1,就变成和上面的 − l o g ( D ( x ) ) -log(D(x)) −log(D(x))一模一样的式子了


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)